更新:2016年第2四半期 :以下で説明するIRI Workbenchのデータ検出メニューグループのデータベースプロファイリングウィザードに加えて、IRIは、マルチソースデータ変換とデータクラスライブラリによる保護のためのフィールドルールの適用を可能にする堅牢なデータ分類を導入しました。 2018年第2四半期の更新 :IRIは、スキーマ全体のパターン検索ウィザードも導入して、複数のテーブルで正規表現またはリテラル値に一致するPIIを一度に検索します。19年第2四半期の更新 :IRIは、スキーマ間/スキーマ内データクラス検索も提供するようになりました およびユーザーIRIFieldShieldまたはVoracityのマスキング。また、IRIはこの記事を公開して、以下のDBプロファイリング結果がSplunkでどのように表示されるかを示しています。
今日のビジネスのより多くの側面からより多くのデータが収集されているため、これらのコレクションの品質、量、セキュリティを確保するには、そのコンテンツと性質を簡単に認識することが不可欠です。データプロファイリングは、リポジトリ内のデータの分析、分類、クレンジング、統合、マスク、レポート作成に役立つ重要な検出プロセスです。
ダークで構造化されたデータ検出(およびメタデータ定義)ウィザードに加えて、EclipseのクロスDB E-Rダイアグラムに加えて、IRI Workbenchの新しいクロスDBプロファイリングツールを使用すると、ユーザーはデータベースデータの構造と完全性を調べて、それを検証できます。適切なデータが適切な場所に保存されています。この記事では、このツールを調べて、テーブル値の検索結果と統計メタデータをどのように提供するかを示します。
データベースプロファイラーにアクセスするには、データソースエクスプローラーでアクセスするテーブルに移動します。テーブルを右クリックして、IRIオプションの上にマウスを置きます。表示されるメニューで、[新しいデータベースプロファイル]を選択します 。
ウィザードの最初のページで、ジョブの場所と宛先を設定し、プロファイルレポートの出力を.csvまたは.txtファイル、あるいはその両方として選択します。
- .csv形式は、新しいテーブルやデータベースへのインポートに役立ちますが、
- .txt形式は事前にフォーマットされたレポートであり、結果をすばやく確認するのに役立ちます。
統計プロファイリング情報
ウィザードの次の部分は、2つのテーブルとともに表示されます。
- 一番上のテーブルは、データベース内のすべてのテーブルのリストであり、ウィザードを起動したテーブルがデフォルトで強調表示されています。
- このチェックボックスを使用すると、データベース内のすべてのテーブルと行をワンクリックでスキャンできます。

- 下の表にはプロファイリングオプションが表示され、その後にオプションの実行を選択した強調表示された表の列が表示されます。

表示およびプロファイルするリスト内の任意のテーブルをクリックします。オプションマトリックスは、選択したテーブルの列を表すように自動的に変更されます。表示オプションを処理する方法はいくつかあります。
- すべてのオプションについて、[すべて]というラベルの付いた表の上部のチェックボックスをクリックすると、すべてのメタデータが報告されます。
- 基本オプション(カウントと値)の場合のみ、[基本]というラベルの付いたチェックボックスをオンにします。
- 長さオプションのみ(値の長さ)の場合は、[長さ]というラベルの付いたチェックボックスをオンにします。
テーブルに多数の列があり、それらすべてに同じオプションを選択する場合は、オプション名自体をクリックすると、すべての列でそのオプションが選択されます。オプション内の列の選択を解除できます。
すべての設定が完了したら、[完了]をクリックします その後、プロファイルが生成されます。
表現検索
オプションテーブルでのユニークな選択は-ExpressionSearch-です。このオプションを使用すると、さまざまな検索オプションに対して列を検索できます。これらのオプションは次のとおりです。
- 正規表現(パターン検索)。これにより、値が検索パターンの形式と一致する回数が検出され、カウントされます。
- ファジー文字列。このオプションを使用すると、入力した文字列に類似した文字列を検索したり、検索条件を選択または指定したりできます。
- 値ファイル。このオプションを使用すると、文字列をセットファイル内のすべての文字列と比較し、一致する各文字列をカウントできます。
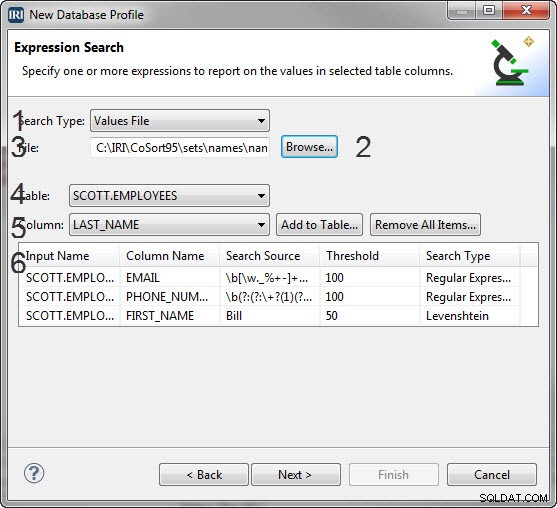
式検索ページには6つの重要なセクションがあります
- 実行する検索の種類を選択するための[検索の種類]コンボボックス。
- 選択した検索タイプに応じて変化するオプショングループ
- 正規表現:2つのボタンがあります。既存の正規表現を参照するbrowse、および新しい正規表現の作成を可能にするCreate…。
- あいまい文字列:あいまい検索のしきい値(文字列が一致と見なされるために必要な距離)を指定するカウントボックスと、使用するあいまい検索アルゴリズムを選択するためのコンボボックスがあります。
- 値ファイル:[参照...]ボタンがあり、値検索に使用する設定ファイルを検索できます。
- 検索用のデータを入力するテキストボックス。
- 式検索を適用できるテーブルのドロップダウンリスト。
- 式検索を適用できる列のドロップダウンリスト。
- プロファイラーによって実行される、作成した検索を一覧表示する表。
正規表現フィルターを作成するには:
- 検索タイプの組み合わせから、正規表現を選択します 。
- [参照]をクリックします (保存された式のライブラリ)に移動するか、[作成]をクリックします 列の値の検索に使用する正規表現を指定します。
- [テーブル]メニューで、フィルタリングする列を含むテーブルを選択します。
- [列]メニューで、正規表現を適用する列を選択します。
- [テーブルに追加]をクリックします 、および下の表に、フィルタを構成するファイル名、列名、検索ソース、しきい値、正規表現ラベルを含むアイテムが表示されます。
- フィルターを追加する列ごとに、このプロセスを繰り返します。列が多すぎてこのプロセスを実用化できない場合でも、代わりにこのウィザードを使用して、複数の列とテーブルを自動的にスキャンし、データベーススキーマ全体でパターンに一致するデータを取得できます。
あいまい文字列検索を作成するには:
- 検索タイプの組み合わせから、あいまいな文字列を選択します 。
- 検索に使用する文字列を入力します。
- 返す結果の数を選択します(このオプションは、あいまい検索が選択されている場合に表示されます)。
- 使用するあいまい検索タイプを選択します(このオプションは、あいまい文字列が選択されている場合に表示されます)。
- [テーブル]メニューで、あいまい検索する列を含むファイルを選択します。
- [列]メニューで、あいまい検索を実行する列を選択します。
- [テーブルに追加]をクリックします 、および下の表に、ファイル名、列名、検索ソース、しきい値、および実行するあいまい検索の検索タイプを含む項目が表示されます。
- あいまい文字列検索を実行する列ごとに、このプロセスを繰り返します。
値ファイル検索を作成するには:
- [検索タイプ]コンボから、[値ファイル]を選択します 。
- [参照]をクリックします 列がチェックされるセットファイルを選択します。
- [テーブル]メニューで、フィルタリングする列を含むテーブルを選択します。
- [列]メニューで、正規表現を適用する列を選択します。
- [テーブルに追加]をクリックします 、および下の表に、フィルタを構成するファイル名、列名、検索ソース、しきい値、および値リストの検索ラベルを含むアイテムが表示されます。
参照整合性チェック
オプションテーブルのもう1つの選択肢は、-参照整合性のチェック-です。このオプションを使用すると、プロファイラーは1つ以上の列を別の列と比較し、列に参照整合性があるかどうかを判断できます。この機能を使用するには、列の[-参照整合性をチェック]チェックボックスをオンにして、参照整合性を比較します。 [次へ]ボタンがアクティブになり、参照整合性チェックのパラメーターを指定できるようになります(詳細については以下を参照してください)。
いずれかの列に対して[参照整合性のチェック]オプションを選択した場合は、[次へ]をクリックします。 参照整合性チェックページに移動します。このページには次の機能があります。
- 2つのコンボボックス。1つは主キーが含まれるテーブルを選択するためのもので、もう1つは主キー列を指定するためのものです。
- 2つのコンボボックス。1つは外部キーが含まれるテーブルを選択し、もう1つは外部キー列を指定します。主キーと比較するために外部キーのリストに外部キーを追加するためのボタンもあります。
- [整合性チェックの作成]ボタンをクリックして、プライマリ列と外部列を下のリストに追加します。
- プロファイラーによって実行されるすべての参照整合性チェックを格納するリスト。

参照整合性チェックを作成するには:
- 主キー列の下のテーブルコンボボックスで、主キーが含まれているテーブルを選択します。
- [主キー列]の下の列コンボボックスで、主キーを選択します。
- 外部キー列の下のテーブルコンボボックスで、外部キーが含まれているテーブルを選択します。
- 外部キー列の下の列コンボボックスで、外部キーを選択します。
- [外部キーリストに追加]ボタンをクリックします…
- 主キーに対してチェックする外部キーごとに手順3〜5を繰り返します
- [整合性チェックの作成]ボタンをクリックします…
- 参照整合性チェックを実行するたびに、上記のプロセスを繰り返します。
サンプルプロファイル出力

LibreOfficeに表示される.csv/EditPadLiteに表示される.txt