データベース設計のキャリアを始めたときに、おそらくこれらの間違いのいくつかを犯したことでしょう。たぶん、あなたはまだそれらを作っているか、将来的にいくつか作るでしょう。過去にさかのぼってエラーを元に戻すことはできませんが、将来の(または現在の)頭痛の種からあなたを救うことはできます。
この記事を読むと、設計とコードの問題を修正するために費やす時間を大幅に節約できる可能性があるので、詳しく見ていきましょう。エラーのリストを2つの主要なグループに分けました。非技術的です。 自然界および厳密に技術的なもの 。これらのグループは両方とも、データベース設計の重要な部分です。
明らかに、技術的なスキルがないと、何かをする方法がわかりません。これらのエラーがリストに表示されるのは当然のことです。しかし、非技術的なスキル?人々はそれらを忘れるかもしれませんが、これらのスキルは設計プロセスの非常に重要な部分でもあります。これらはコードに付加価値を与え、テクノロジーを解決する必要のある実際の問題に関連付けます。
それでは、最初に非技術的な問題から始めて、次に技術的な問題に移りましょう。
非技術的なデータベース設計エラー
#1計画が不十分
これは間違いなく非技術的な問題ですが、主要で一般的な問題です。新しいプロジェクトが始まると、私たちは皆興奮します。それに入ると、すべてが素晴らしく見えます。当初、プロジェクトはまだ空白のページであり、あなたとあなたのクライアントは、あなたとあなたの両方にとってより良い未来を創造する何かに取り組み始めることを喜んでいます。これはすべて素晴らしいことであり、素晴らしい未来はおそらく最終的な結果になるでしょう。しかし、それでも、私たちは集中し続ける必要があります。これは、私たちが重大な間違いを犯す可能性のあるプロジェクトの一部です。
座ってデータモデルを描く前に、次のことを確認する必要があります。
- クライアントが何をしているのか(つまり、このプロジェクトに関連するビジネスプランと全体像)、そしてこのプロジェクトで現在および将来に何を達成したいのかを完全に理解しています。
- ビジネスプロセスを理解し、必要に応じて、ビジネスプロセスを簡素化および改善するための提案を行う準備ができています(たとえば、効率と収入の向上、コストと労働時間の削減など)。
- クライアントの会社のデータフローを理解している。理想的には、誰がデータを操作し、誰が変更を加え、どのレポートが必要か、いつ、なぜこれらすべてが発生するかなど、すべての詳細を知っているはずです。
- クライアントが使用する言語/用語を使用できます。あなたは彼らの分野の専門家であるかもしれないしそうでないかもしれませんが、あなたのクライアントは間違いなくそうです。わからないことを説明してもらいます。また、クライアントに技術的な詳細を説明するときは、クライアントが理解している言語と用語を使用してください。
- データベースエンジンやプログラミング言語から他のツールまで、使用するテクノロジーを知っています。使用することにしたものは、解決する問題と密接に関連していますが、クライアントの好みと現在のITインフラストラクチャを含めることが重要です。
計画段階では、次の質問に対する回答を得る必要があります。
- モデルの中心となるテーブルはどれですか?おそらくそれらのいくつかがありますが、他のテーブルは通常のテーブルのいくつかになります(user_account、roleなど)。辞書とテーブル間の関係を忘れないでください。
- モデルのテーブルにはどのような名前が使用されますか?クライアントが現在使用している用語と同じように用語を維持することを忘れないでください。
- テーブルやその他のオブジェクトに名前を付けるときに適用されるルールは何ですか? (命名規則については、ポイント4を参照してください。)
- プロジェクト全体にはどのくらい時間がかかりますか?これは、スケジュールとクライアントのタイムラインの両方にとって重要です。
これらすべての答えが得られた場合にのみ、問題の最初の解決策を共有する準備が整います。そのソリューションは、完全なアプリケーションである必要はありません。短いドキュメントや、クライアントのビジネスの言語で書かれた数文でさえあるかもしれません。
適切な計画は、データモデリングに固有のものではありません。ほとんどすべてのIT(および非IT)プロジェクトに適用できます。スキップは、1)非常に小さなプロジェクトがある場合の唯一のオプションです。 2)タスクと目標が明確であり、3)あなたは本当に急いでいます。歴史的な例は、スプートニク1号の打ち上げエンジニアが、組み立てていた技術者に口頭で指示を与えることです。米国が間もなく独自の衛星を打ち上げることを計画しているというニュースのため、プロジェクトは急いでいましたが、それほど急いでいることはないと思います。
#2クライアントおよび開発者との不十分なコミュニケーション
データベース設計プロセスを開始すると、主な要件のほとんどを理解できるでしょう。いくつかは、ビジネスに関係なく非常に一般的です。ユーザーの役割とステータス。一方、モデル内の一部のテーブルは非常に具体的です。たとえば、タクシー会社のモデルを作成する場合は、車両、運転手、クライアントなどのテーブルがあります。
それでも、プロジェクトの開始時にすべてが明らかになるわけではありません。一部の要件を誤解したり、クライアントがいくつかの新しい機能を追加したり、別の方法で実行できることが表示されたり、プロセスが変更されたりする可能性があります。これらすべてがモデルの変更を引き起こします。ほとんどの変更では新しいテーブルを追加する必要がありますが、テーブルを削除または変更する場合もあります。これらのテーブルを使用するコードの記述をすでに開始している場合は、そのコードも書き直す必要があります。
予期しない変更に費やす時間を減らすには、次のことを行う必要があります。
- 開発者やクライアントと話し合い、重要なビジネス上の質問をすることを恐れないでください。始める準備ができていると思ったら、状況Xはデータベースでカバーされていますか?クライアントは現在、この方法でYを実行しています。近い将来、変化が見込まれますか? モデルに必要なものすべてを適切な方法で保存できる機能があると確信できたら、コーディングを開始できます。
- デザインに大きな変更があり、すでに多くのコードが記述されている場合は、迅速な修正を試みるべきではありません。現在の状況に関係なく、それが行われるべきだったようにそれを行います。簡単な修正で時間を節約でき、しばらくは問題なく動作する可能性がありますが、後で実際の悪夢に変わる可能性があります。
- 今は問題ないと思うが、後で問題になる可能性がある場合は、無視しないでください。その領域を分析し、システムの品質とパフォーマンスが向上する場合は変更を実装します。少し時間がかかりますが、より良い製品を提供し、よりよく眠ることができます。
潜在的な問題が発生したときにデータモデルに変更を加えないようにしようとした場合、または適切に行うのではなく迅速な修正を選択した場合は、遅かれ早かれその費用を支払うことになります。
また、プロジェクト全体を通して、クライアントや開発者と連絡を取り合ってください。前回のディスカッション以降に変更が加えられているかどうかを常に確認してください。
#3ドキュメントが不十分または欠落している
私たちのほとんどにとって、ドキュメントはプロジェクトの最後にあります。よく整理されていれば、おそらく途中で物事を文書化しており、すべてをまとめるだけで済みます。しかし正直なところ、通常はそうではありません。ドキュメントの作成は、プロジェクトが終了する直前、およびそのデータモデルを精神的に完了した直後に行われます!
文書化が不十分なプロジェクトに支払われる価格はかなり高くなる可能性があり、すべてを適切に文書化するために支払う価格の数倍になります。プロジェクトを終了してから数か月後にバグを見つけたと想像してみてください。適切に文書化していないため、どこから始めればよいかわかりません。
作業中は、コメントを書くことを忘れないでください。追加の説明が必要なものはすべて説明し、基本的にはいつか役立つと思うものをすべて書き留めます。その追加情報が必要かどうか、いつ必要になるかはわかりません。
技術的なデータベース設計の間違い
#4命名規則を使用しない
プロジェクトがどのくらい続くか、データモデルに複数の人が取り組んでいるかどうかはわかりません。データモデルに本当に近づいた時点がありますが、実際にはまだ描画を開始していません。これは、モデル、データベース、および一般的なアプリケーションでオブジェクトに名前を付ける方法を決定するのが賢明な場合です。モデリングする前に、次のことを知っておく必要があります。
- テーブル名は単数形ですか、それとも複数形ですか?
- 名前を使用してテーブルをグループ化しますか? (たとえば、すべてのクライアント関連のテーブルには「client_」が含まれ、すべてのタスク関連のテーブルには「task_」が含まれます)
- 大文字と小文字を使用しますか、それとも小文字だけを使用しますか?
- ID列にはどのような名前を使用しますか? (ほとんどの場合、「id」になります。)
- 外部キーにどのように名前を付けますか? (ほとんどの場合、「id_」と参照されるテーブルの名前です。)
以下に示すように、命名規則を使用しないモデルの一部を、命名規則を使用する同じ部分と比較します。
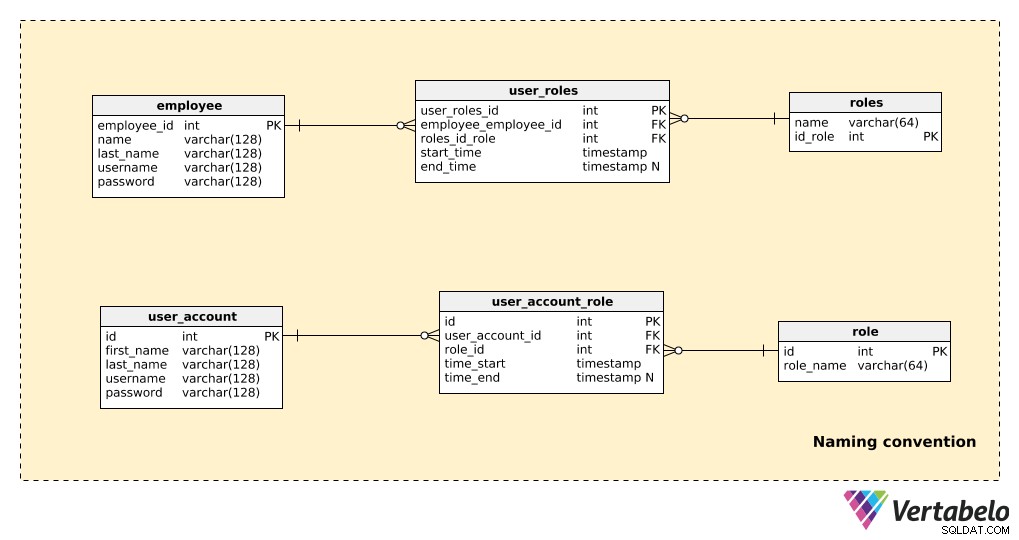
ここにはテーブルがいくつかありますが、どちらのモデルが読みやすいかは明らかです。注意:
- どちらのモデルも「機能」するため、技術面で問題はありません。
- 非命名規則の例(上の3つの表)では、読みやすさに大きな影響を与えることがいくつかあります。表名に単数形と複数形の両方を使用する。標準化されていない主キー名(
employees_id、id_role);異なるテーブルの属性は同じ名前を共有します(たとえば、名前は「employee」と「roles」テーブル)。
ここで、モデルに数百のテーブルが含まれている場合に作成される混乱を想像してみてください。たぶん私たちはそのようなモデルで作業することができますが(私たちがそれを自分で作成した場合)、誰かが私たちの後にそれで作業しなければならない場合、私たちは誰かを非常に不運にするでしょう。
名前に関する将来の問題を回避するために、SQLの予約語、特殊文字、またはスペースを使用しないでください。
したがって、名前の作成を開始する前に、使用した命名規則を説明する簡単なドキュメント(おそらく数ページの長さ)を作成してください。これにより、モデル全体の読みやすさが向上し、将来の作業が簡素化されます。
命名規則の詳細については、次の2つの記事を参照してください。
- データベースモデリングの命名規則
- SQLServerの命名規則に関する感情に訴えない論理的考察
#5正規化の問題
正規化はデータベース設計の重要な部分です。すべてのデータベースは、少なくとも3NFに正規化する必要があります(主キーが定義され、列はアトミックであり、繰り返しグループ、部分的な依存関係、または推移的な依存関係はありません)。これにより、データの重複が減り、参照整合性が確保されます。
この記事で正規化の詳細を読むことができます。つまり、リレーショナルデータベースモデルについて話すときはいつでも、正規化されたデータベースについて話します。データベースが正規化されていない場合、データの整合性に関連する多くの問題が発生します。
場合によっては、データベースを非正規化する必要があります。これを行う場合は、本当に正当な理由があります。データベースの非正規化について詳しくは、こちらをご覧ください。
#6 Entity-Attribute-Value(EAV)モデルの使用
EAVはentity-attribute-valueの略です。この構造を使用して、モデル内のあらゆるものに関する追加データを格納できます。一例を見てみましょう。
いくつかの追加の顧客属性を保存するとします。 「customer 」テーブルは私たちのエンティティ、「attribute 」テーブルは明らかに私たちの属性であり、「attribute_value 」テーブルには、その顧客のその属性の値が含まれています。
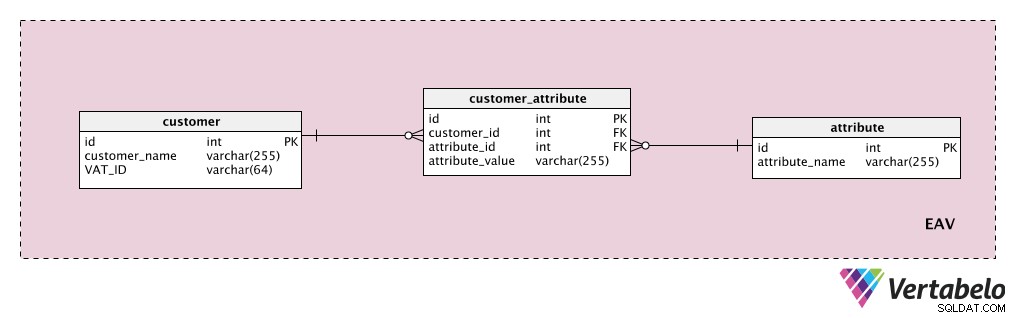
まず、顧客に割り当てることができるすべての可能なプロパティのリストを含む辞書を追加します。これは「attribute " テーブル。 「customervalue」、「contact details」、「additionalinfo」などのプロパティを含めることができます。「customer_attribute 」テーブルには、各顧客のすべての属性と値のリストが含まれています。顧客ごとに、顧客が持っている属性のレコードのみがあり、「attribute_value その属性の場合は」。
これは本当に素晴らしいように思えるかもしれません。これにより、新しいプロパティを簡単に追加できるようになります(「customer_attribute " テーブル)。したがって、データベースに変更を加えることは避けます。あまりにも良すぎて真実ではありません。
そしてそれは良すぎる。モデルには必要なデータが保存されますが、そのようなデータの操作ははるかに複雑です。これには、単純なSELECTクエリの記述から、顧客に関連するすべての値の取得、値の挿入、更新、削除まで、ほとんどすべてが含まれます。
つまり、EAV構造は避ける必要があります。使用する必要がある場合は、本当に必要であると100%確信している場合にのみ使用してください。
#7 GUID/UUIDを主キーとして使用する
GUID(Globally Unique Identifier)は、RFC 4122で定義されているルールに従って生成された128ビットの数値です。UUID(Universally Unique Identifiers)とも呼ばれます。 GUIDの主な利点は、それが一意であることです。同じGUIDを2回ヒットする可能性はほとんどありません。したがって、GUIDは主キー列の優れた候補のように見えます。しかし、そうではありません。
主キーの一般的なルールは、autoincrementプロパティが「yes」に設定された整数列を使用することです。これにより、データが順番に主キーに追加され、最適なパフォーマンスが提供されます。シーケンシャルキーまたはタイムスタンプがないと、どのデータが最初に挿入されたかを知る方法はありません。この問題は、UNIQUEの実世界の値(VAT IDなど)を使用する場合にも発生します。それらはUNIQUE値を保持しますが、適切な主キーにはなりません。代わりにそれらを代替キーとして使用してください。
もう1つの注意: 私は、主キーとして単一列の自動生成された整数属性を使用することを好みます。これは間違いなくベストプラクティスです。複合主キーの使用は避けることをお勧めします。
#8不十分なインデックス作成
インデックスはデータベースを操作する上で非常に重要な部分ですが、インデックスの詳細な説明はこの記事の範囲外です。幸い、インデックスに関連する記事がすでにいくつかありますので、詳細を確認してください:- データベースインデックスとは何ですか?
- インデックスのすべて:非常に基本的な
- インデックスのすべてパート2:MySQLインデックスの構造とパフォーマンス
短いバージョンでは、必要になると思われる場所にインデックスを追加することをお勧めします。特定の場所にインデックスを追加するとパフォーマンスが向上することがわかった場合は、データベースの運用後にそれらを追加することもできます。
#9冗長データ
冗長なデータは、通常、どのモデルでも避ける必要があります。追加のディスクスペースを使用するだけでなく、データの整合性の問題が発生する可能性が大幅に高まります。何かを冗長にする必要がある場合は、元のデータと「コピー」が常に一貫した状態になるように注意する必要があります。実際、冗長データが望ましい状況がいくつかあります。
- 場合によっては、特定のアクションに優先順位を割り当てる必要があります。これを実現するには、複雑な計算を実行する必要があります。これらの計算は多くのテーブルを使用し、多くのリソースを消費する可能性があります。このような場合、これらの計算を営業時間外に実行することをお勧めします(したがって、勤務時間中のパフォーマンスの問題を回避します)。このようにすれば、その計算値を保存して、後で再計算せずに使用できます。もちろん、値は冗長です。ただし、パフォーマンスで得られるものは、失うもの(ハードドライブの空き容量)よりも大幅に多くなります。
- データベース内にレポートデータの小さなセットを保存することもあります。たとえば、1日の終わりに、その日に行った電話の数、成功した販売の数などを保存します。レポートデータは、頻繁に使用する必要がある場合にのみ、この方法で保存する必要があります。繰り返しになりますが、ハードドライブのスペースが少し失われますが、データの再計算やレポートデータベースへの接続(ある場合)は避けます。
ほとんどの場合、次の理由で冗長データを使用しないでください。
- 同じデータをデータベースに複数回保存すると、データの整合性に影響を与える可能性があります。クライアントの名前を2つの異なる場所に保存する場合は、両方の場所に同時に変更(挿入/更新/削除)を行う必要があります。これにより、最も単純な操作であっても、必要なコードが複雑になります。
- いくつかの集計数を運用データベースに保存することはできますが、これは本当に必要な場合にのみ行う必要があります。運用データベースは、レポートデータを格納するためのものではなく、これら2つを混在させることは一般的に悪い習慣です。レポートを作成する人は、運用タスクに取り組んでいるユーザーと同じリソースを使用する必要があります。レポートクエリは通常、より複雑で、パフォーマンスに影響を与える可能性があります。したがって、運用データベースとレポートデータベースを分離する必要があります。
今度はあなたの番です
この記事を読むことで、いくつかの新しい洞察が得られ、データモデリングのベストプラクティスに従うように促されることを願っています。彼らはあなたにいくらかの時間を節約するでしょう!
この記事に記載されている問題のいずれかを経験しましたか?重要なことを見逃したと思いますか?それとも、リストから何かを削除する必要があると思いますか?以下のコメントで教えてください。