RANK、DENSE_RANK、およびROW_NUMBER関数は、増加する整数値を取得するために使用されます。それらは、ORDERBY句によって課される条件に基づく値で始まります。これらの関数はすべて、正しく機能するためにORDERBY句が必要です。パーティション化されたデータの場合、整数カウンターはパーティションごとに1にリセットされます。
この記事では、RANK、DENSE_RANK、およびROW_NUMBER関数について詳しく説明しますが、その前に、データベースが完全にバックアップされていない限り、これらの関数を使用できるダミーデータを作成しましょう。
ダミーデータの準備
次のスクリプトを実行して、ShowRoomというデータベースを作成し、Carsというテーブル(車のランダムな15のレコードを含む)を含めます。
CREATE Database ShowRoom; GO USE ShowRoom; CREATE TABLE Cars ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) USE ShowRoom INSERT INTO Cars VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 1500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 5000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200), (11, 'Atlas', 'Volkswagen', 5000), (12, '110', 'Bugatti', 8000), (13, 'Landcruiser', 'Toyota', 3000), (14, 'Civic', 'Honda', 1800), (15, 'Accord', 'Honda', 2000)
RANK関数
RANK関数は、ORDERBY句の条件に基づいてランク付けされた行を取得するために使用されます。たとえば、3番目にパワーが高い車の名前を検索する場合は、RANK関数を使用できます。
RANK関数の動作を見てみましょう:
SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS PowerRank FROM Cars
上記のスクリプトは、Carsテーブル内のすべてのレコードを検索してランク付けし、電力の降順でそれらを並べ替えます。出力は次のようになります:
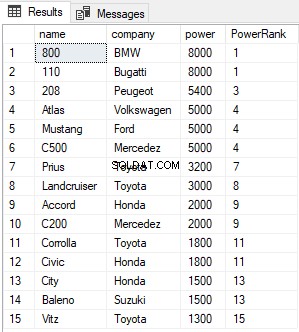
上記の表のPowerRank列には、パワーの降順で並べ替えられた車のRANKが含まれています。 RANK関数の興味深い点は、ORDER BY列の値の前のN個のレコード間に同点がある場合、RANK関数はカウンターをインクリメントする前に次のN-1個の位置をスキップすることです。たとえば、上記の結果では、1行目と2行目の間の累乗列の値が同点であるため、RANK関数は次の(2-1 =1)1つのレコードをスキップし、3行目に直接ジャンプします。
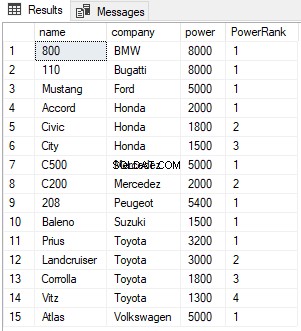
RANK関数は、PARTITIONBY句と組み合わせて使用できます。その場合、新しいパーティションごとにランクがリセットされます。次のスクリプトを見てください:
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
上記のスクリプトでは、結果を会社の列で分割しています。これで、各企業について、以下に示すように、RANKが1にリセットされます。
DENSE_RANK関数
DENSE_RANK関数はRANK関数に似ていますが、先行するレコードのランク間に同点がある場合、DENSE_RANK関数はランクをスキップしません。次のスクリプトを見てください。
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
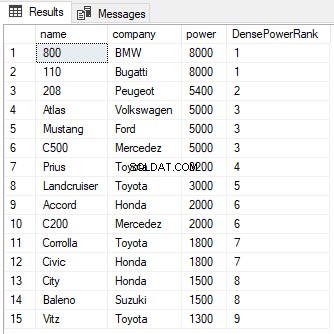
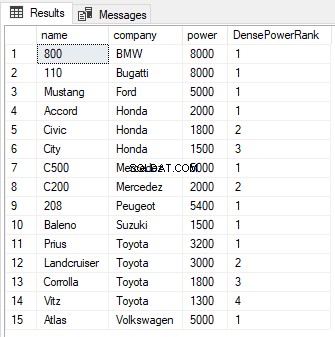
出力から、最初の2行のランクが同点であるにもかかわらず、次のランクはスキップされず、3ではなく2の値が割り当てられていることがわかります。RANK関数と同様に、PARTITIONBY句は次のことができます。以下に示すように、DENSE_RANK関数でも使用できます。
SELECT name,company, power, DENSE_RANK() OVER(PARTITION BY company ORDER BY power DESC) AS DensePowerRank FROM Cars
ROW_NUMBER関数
RANK関数およびDENSE_RANK関数とは異なり、ROW_NUMBER関数は、1から始まるソートされたレコードの行番号を返すだけです。たとえば、ORDER BY列の最初の2つのレコードのRANK関数とDENSE_RANK関数が等しい場合、両方に1が割り当てられます。彼らのRANKとDENSE_RANKとして。ただし、ROW_NUMBER関数は、これらの行が等しく考慮されているという事実を考慮せずに、それらの行に値1と2を割り当てます。次のスクリプトを実行して、ROW_NUMBER関数の動作を確認します。
SELECT name,company, power, ROW_NUMBER() OVER(ORDER BY power DESC) AS RowRank FROM Cars
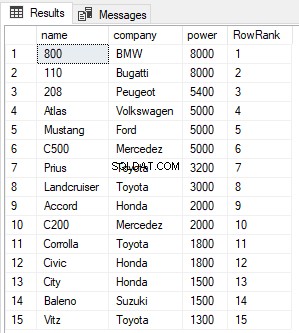
出力から、ROW_NUMBER関数は、値に関係なく、各レコードに新しい行番号を割り当てるだけであることがわかります。
PARTITION BY句は、以下に示すようにROW_NUMBER関数でも使用できます。
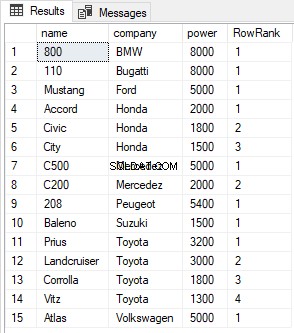
SELECT name, company, power, ROW_NUMBER() OVER(PARTITION BY company ORDER BY power DESC) AS RowRank FROM Cars
出力は次のようになります:
RANK、DENSE_RANK、およびROW_NUMBER関数の類似点
RANK、DENSE_RANK、およびROW_NUMBER関数には、次の類似点があります。
1-これらはすべてorderby句が必要です。
2-すべては、ベース値が1の増加する整数を返します。
3- PARTITION BY句と組み合わせると、これらの関数はすべて、これまで見てきたように、返された整数値を1にリセットします。
4- ORDER BY句で使用される列に重複する値がない場合、これらは関数は同じ出力を返します。
最後のポイントを説明するために、Power列に重複する値がないShowRoomデータベースに新しいテーブルCar1を作成しましょう。次のスクリプトを実行します。
USE ShowRoom; CREATE TABLE Cars1 ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) INSERT INTO Cars1 VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 2500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 4000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200) The cars1 table has no duplicate values. Now let’s execute the RANK, DENSE_RANK and ROW_NUMBER functions on the Cars1 table ORDER BY power column. Execute the following script: SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars1
出力は次のようになります:
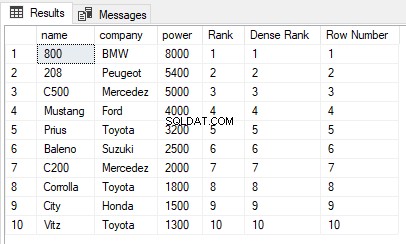
ORDER BY句で使用されているpower列に重複する値がないことがわかります。したがって、RANK、DENSE_RANK、およびROW_NUMBER関数の出力は同じです。
RANK、DENSE_RANK、ROW_NUMBER関数の違い
RANK、DENSE_RANK、およびROW_NUMBER関数の唯一の違いは、ORDER BY句で使用されている列に重複する値がある場合です。
ShowRoomデータベースのCarsテーブルに戻ると、多くの値が含まれていることがわかります。値が重複しています。電力順に並べられたCars1テーブルのRANK、DENSE_RANK、およびROW_NUMBERを見つけてみましょう。次のスクリプトを実行します:
SELECT name、company、power、
RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars
出力は次のようになります:
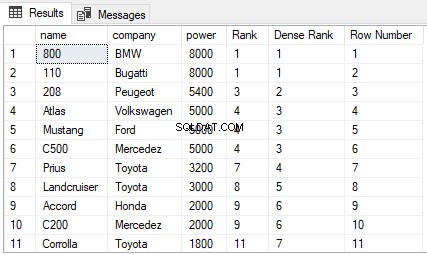
出力から、前のNランクの間に同点がある場合、RANK関数が次のN-1ランクをスキップすることがわかります。一方、DENSE_RANK関数は、ランク間に同点がある場合、ランクをスキップしません。最後に、ROW_NUMBER関数はランキングとは関係ありません。ソートされたレコードの行番号を返すだけです。 ORDER BY句で使用される列に重複するレコードがある場合でも、ROW_NUMBER関数は重複する値を返しません。代わりに、重複する値に関係なく、増分を継続します。
便利なリンク:
ROW_NUMBER()、RANK()、およびDENSE_RANK()関数の詳細については、AhmadYaseenによる素晴らしい記事をお読みください。
SQL Serverで行をランク付けするメソッド:ROW_NUMBER()、RANK()、DENSE_RANK()、およびNTILE()