データベースを設計する際に留意すべき点はたくさんあり、私たちが学んだ貴重なヒントやコツをすべて覚えている人はほとんどいません。それでは、データベース設計のヒントとベストプラクティスを特徴とするいくつかのオンラインリソースを見てみましょう。データベース設計の経験に基づいて、提示されたアイデアについて自分の意見を共有します。
明らかに、この記事は完全なリストではありませんが、私はさまざまな情報源を確認してコメントしようとしました。うまくいけば、あなたのニーズと目標に最も適した情報が見つかるでしょう。
ちなみに、データベース設計の実践に関連する多くの記事に例がほとんどないことに驚いた。エラーと間違いに関する記事のために私がレビューしたオンラインリソースは、それらの割合が高かった。例は要点を伝えるために非常に重要であるため、この欠如は欠点です。
経験豊富なデザイナーのためのデータベースのヒント
まず、高度なデータベース設計のヒントとベストプラクティスを特徴とするソースから始めましょう。これらは、すでにデータモデリングに取り組んでいて、しばらくの間働いている設計者向けです。一部の記事はより中級レベルを対象としていますが、高度な概念について説明している場合は、このリストに含めました。
データベースガイドライン(RDBMS / SQL)
by Steve Djajasaputra | SOA、Java、ソフトウェア開発– BlogSpot | 2013年1月16日
Djajasaputra氏からのこの記事は非常に印象的です。彼は、スキーマ、インデックス、およびビューに関する多数のヒントをリストしています。彼はまた、非常に詳細な命名規則を提供しています。そして彼の秘訣は続く(そして続く)。幅は印象的ですが、例はほとんどありません。彼の論点のいくつかは議論の余地があると考えられるかもしれませんが、全体としてこれは非常に堅実なプレゼンテーションです。
特に、彼が自然対人工(つまり、代理または生成された)主キーの使用について正確なルールを与えていることに感銘を受けました。彼はこれを素晴らしくシンプルに保ち、意味があるので自然キーを好むべきだと指定しています。彼はまた、人工キーを最適に使用するためのガイドラインを提供します。具体的には、自然キーが一意でない場合、または自然キーの値を変更する必要がある場合です。彼自身の言葉で:
自然キーの方が意味があり、重複を避けるため(既存の列を再利用する)、最初に自然キーを使用することをお勧めします。ただし、人工キーが必要な場合があります。自然キーが一意でない場合(名前など)、または値を変更する必要がある場合です。彼のヒントのリストは非常に長いので、それらすべてを覚えているとは想像できません。ただし、データベースの設計、パフォーマンス、ストアドプロシージャ、およびバージョン管理に取り組んでいるときに、各セクションを参照できます。 Oracleを使用している、またはOracleをサポートすることを計画している場合に役立つ、Oracle固有のポイントに関するセクションもあります。
全体として、これは非常に価値のある包括的なリソースです。
データベース設計を改善するための9つのヒント
by Jeffrey Edison | Vertabeloブログ| 2015年9月22日
ここで少し自己宣伝をします。
より良いデータベース設計のための9つのヒントのこの記事は、デザイナーおよびアーキテクトとしての私の経験に基づいています。また、データベース設計に関する他の人のベストプラクティスを調査することで、追加の洞察を見つけました。
私のリストは、データモデルを操作するときに発生する可能性のある主な問題のいくつかを表しています。少なくとも私の見解では、それが最も役立つので、プロジェクトのライフサイクル中に発生する順序で(重要性や発生頻度ではなく)ヒントを整理しました。読者は、プロジェクトのライフサイクルを通じて、このベストプラクティスのチェックリストに従うことができます。
記事から:
アル・カポネ(または第8代米国大統領の息子であるジョン・ヴァン・ビューレン)を言い換えると、「早くテストし、頻繁にテストする」。このようにして、継続的インテグレーションのパスをたどります。開発の初期段階でテストすることで、時間と費用を節約できます。データベースのテストでは、本番環境をシミュレートすることを目標にする必要があります。「データベースの1日」です。どのくらいの量が期待できますか?どのようなユーザーインタラクションが発生する可能性がありますか?境界ケースは処理されていますか?これらのヒントに注意を払うことで、データベースがより適切に設計され、より堅牢になることがわかりました。これらのアクティビティはどれも膨大な時間はかかりませんが、それぞれがデータモデルの品質に多大な影響を与える可能性があります。
私のヒントのリストが中級および上級のデザイナーに役立つことを願っています。
20データベース設計のベストプラクティス
by Cagdas Basaraner |コードバランス– BlogSpot | 2011年7月24日
Basaraner氏は、20のデータベース設計のベストプラクティスの興味深いリストを提示してくれます。もし彼がこれらのいくつかをグループ化していたなら、私はそれを好んだでしょう。たとえば、最初の4つの項目はすべて、「適切な命名規則を使用する」でカバーできます。
さらに、彼は、すべてのテーブルの主キーとして合成の生成された(整数)IDを使用することがベストプラクティスであると述べています。実際、これはまだ議論の対象であり、賛成と反対の議論があります。彼のベストプラクティスのいくつかは、「…ミッション評論家[原文のまま]データベースシステムの場合、ディザスタリカバリとセキュリティサービスを使用する…」のように非常に一般的です。私はこの点に同意しませんが、非常に高レベルです。
プラス面として、この記事は、オブジェクトリレーショナルマッピング(ORM)フレームワークの使用について言及した数少ない記事の1つでした。一部のコメント提供者は、ヒントの言い回しに同意しませんでしたが、少なくともORMフレームワークの使用について言及されています:
アプリケーションコードが十分に大きい場合は、ORM(オブジェクトリレーショナルマッピング)フレームワーク(つまり、Hibernate、iBatis ...)を使用します。 ORMフレームワークのパフォーマンスの問題は、詳細な構成パラメーターによって処理できます。それでも、このリストは改善された可能性があります。 一部にのみ固有のポイントを明確に特定する必要があります データベース管理システム(SQL Serverなど)。パフォーマンス、ヒューリスティック、またはデザインに時間を費やすことの重要性に関する正確な統計 メンテナンスではなく および再設計 良かったでしょう。さらに多くの例も必要でしたが、それはこれらの記事のほとんどの問題です。
SQL Serverを使用している場合、ORMフレームワークの使用を検討している場合、または長くて詳細な記事ではなく、ヒントの箇条書きリストが必要な場合は、この記事が最適です。
(注:この記事は、CodeBuild、Java Code Geeks、DZoneなどの他のいくつかのサイトにも掲載されています。)
データベースデザインエッセンシャル。絶対にやらなければならない10のこと
by Michelle A. Poolet | SQL Server Pro | 2011年3月1日
Poolet氏のヒントの一部は非常に標準的であり、他の多くのリソースで見つけることができますが、いくつかのかなり珍しい点もあります。彼女の一般的なポイントの中で、彼女はサブタイプとスーパータイプ(私が強く同意する)の使用を促進しています。これはオブジェクト指向の設計を反映しており、開発者が簡単に理解できるためです。彼女の記事から:
CDM以降のデザインにスーパータイプとサブタイプのエンティティを含めることを恐れないでください。サブタイプは、スーパータイプの分類またはカテゴリを表します…エンティティを分類するのに複数の単語またはフレーズが必要な場合、エンティティはサブタイプとして表されます。
カテゴリに独自の寿命があり、カテゴリの外観と動作を説明する個別の属性と、他のエンティティとの個別の関係がある場合は、スーパータイプ/サブタイプ構造を呼び出すときが来ました。 。そうしないと、データとデータ収集を推進するビジネスルールを完全に理解できなくなります。
彼女のコメントのいくつかは、コメントが実際には一般的な問題である場合でも、MSSQLServerに具体的に言及しています。 Poolet氏が指摘する主なポイントの1つは、SQLServer固有の「ストアドプロシージャとしてデータベースのデータにアクセスするコードを格納する」ことです。
これは、SQLServerなどの単一のデータベース管理システムのサポートのみを計画している場合は問題ありません。しかし、移植可能な実装の場合、これは良いアドバイスではありません。一般に、私は、異なるストアドプロシージャ言語をサポートする少なくとも2つの管理システムへの移植性を考慮して設計しています。したがって、私はこの慣行を避けます。
この記事は、SQL Server向けに開発し、(国際的なシステムではなく)米国市場に焦点を当てている人々に最も役立ちます。しかし、海外に住むアメリカ人として、彼女の例のいくつかは少し「アメリカ中心」であることに気づきました。たとえば、非アメリカ人は Zip + 4が何であるかを理解していない可能性があります ドメインは、したがって、このドメインがNOTNULL特性を持つ必要がある理由を理解していません。
これを説明するために、私は両方のアメリカ人以外の住所のデータモデルを作成しました。データモデルでは、エンティティを複数のアドレスにリンクする必要があると想定します。たとえば、1つは請求用、もう1つは配送用です。最初の住所は支払い方法に関連付けられます。この場合、住所は、その支払いを承認する権利を確認するために使用されます。配送先住所は、明らかに、注文が配送される場所です。
顧客注文データベースモデルの一部としてアメリカの住所を作成しましょう。 (注:これは完全なモデルではありませんが、製品の注文を保存する例です。)
Wise Coders Solutionsは、家番号と通りの名前に別々のフィールドを定義し、これらのフィールドをNOTNULLとして設定することをお勧めします。これにより、家番号と通りの名前がない住所は許可されません。しかし、私書箱を使用する人はどうでしょうか。彼らの住所は通常「私書箱123」と書かれています。私書箱番号を家番号、「私書箱」を通りの名前として強制する必要がありますか?そうは思いません。
代わりに、「住所行1」と「住所行2」のフォームを使用します。フィールド名に数字を使用することに反対する人もいますが、私にとってこれはかなり明白な解決策です。また、国際決済で一般的な最大フィールド長(35文字と70文字)を定義しました。
米国と米国以外のデザインの両方に国内の地域のフィールドがありますが、米国のデザインでは2文字の州の略語を含める必要があることに注意してください。また、米国の設計では他の国の住所は許可されていないことに注意してください。
データベースのグローバルな使用法について懸念がある場合は、設計段階でグローバルに考える必要があります。私たちのデータベースは、私たちのアプリケーションの多国籍使用のために準備されていますか?
不十分なデータウェアハウス設計から学んだ教訓
by Michelle A. Poolet | SQL Server Pro | 2009年6月15日
この記事では、データウェアハウス(DWH)とその設計および実装の問題のいくつかを見ていきます。 SQL Serverに少し焦点が当てられていますが、これはデータウェアハウジングとビジネスインテリジェンスの設計に関するかなり正統な概要です。賛同を得てユーザーフレンドリーなインターフェースを作成することは、最も役立つヒントではないかもしれませんが、私はそれらに同意しません。それらがDWH設計の一部であるとは思わないだけです。
Poolet氏は、extract-transform-load(ETL)プロセスは、データ品質チェックを実行し、データ品質の許容基準が得られるまでデータを「クリーン」にする可能性があると述べています。私の意見では、これは、ソースシステムから抽出された情報を適切にミラーリングしないデータウェアハウスを作成するリスクがあります。データクリーニングは、ソースシステムで実行する必要があります。 ETLは、データウェアハウスにロードできるようにデータのみを変換する必要があります。
ポジティブなことに、再利用可能なETLルーチンをリサイクルまたは作成することの推奨は非常に関連性があります。また、スケーラビリティについては、Pooletさんにも同意します。リスク管理とコンプライアンス、特にサーベンスオクスリー法に関する彼女のコメントは非常に具体的であるように思われます。これらは彼女の事業分野から来ていると思います。
最後に、彼女は、OLAP(オンライン分析処理)設計中のディメンション、ファクトテーブル、およびスキーマの選択に関連するポイントの優れたチェックリストを持っています。これらは、データベース設計プロセス中に非常に関連しているように見えます。このリストをもっと長くして、詳細や例を追加したかったのですが、これらの実用的なヒントが含まれていることを嬉しく思います。
私が従う11の重要なデータベース設計ルール
by Shivprasad Koirala |コードプロジェクト| 2014年2月25日
この記事の冒頭にある賢明で明確なアドバイスが本当に好きです。 「アプリケーションの性質を検討する」や「データを論理的な部分に分割する」などの概念が的を射ています。これらは、データモデルを作成するときに重要な助けになります。コイララ氏が言うように:
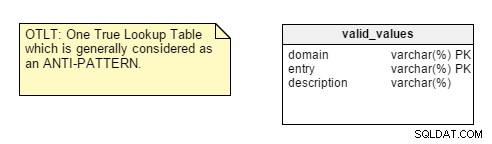
データベース設計を開始するとき、最初に分析するのは、設計対象のアプリケーションの性質であり、トランザクションか分析かです。多くの開発者は、デフォルトで、アプリケーションの性質を考慮せずに正規化ルールを適用し、後でパフォーマンスとカスタマイズの問題に取り組むことになります。しかし、私を納得させない点がいくつかあります。たとえば、名前と値のペアを1つのテーブルに一元化するとします。このOneTrueLookup Table(OTLT)の設計については議論がありますが、一般的には、設計の悪い習慣または少なくともアンチパターンと見なされます。私は反OTLTグループの側にいます。これらの表には多くの問題があります。この方法と同等に、単一の列挙子を使用してすべての可能な定数のすべての可能な値を表すというソフトウェア開発のアナロジーを採用する場合があります。
念のために言っておきますが、OTLTテーブルは通常、次のようになり、複数のドメインからのエントリが同じテーブルにスローされます。私は反OTLTグループに同意します。これらの表には多くの問題があります。
さらに、「区切り文字で区切られたデータを監視する」など、少し難解な点もあります。これは有効なポイントですが、新しいデータモデルを作成するときに私が通常考えるポイントではありません。
Koirala氏には、他のベストプラクティスリストには一般的に記載されていないOLAP設計項目がいくつかあります。彼が次元と事実の設計を含めることは有用かもしれませんが、初心者の設計者にとっても危険である可能性があります。
この記事は、最初からより高度なデータモデリングに移行する場合に役立ちます。これは、将来のモデルの分析的性質とトランザクション的性質を検討するのに役立ちます。
ビッグデータ:5つの簡単なデータベース設計パフォーマンスのヒント
by Dave Beulke | davebeulke.com | 2013年3月19日

Beulke氏の記事では、パフォーマンスに重点を置いた設計のヒントについて説明しています。彼は、適切な正規化をチェックする方法を示しています。多すぎても少なすぎてもいけません。 (過度の正規化はデータベースのパフォーマンスに悪影響を及ぼします。)
また、データベースアクセスごとにビジネスキーから生成された行IDに変換することを避けたい場合は、生成された主キーではなく自然なビジネスキーを使用することをお勧めします。
適切な命名基準と列タイプを使用することも良いアドバイスです。 null許容列の乱用についてのポイントは正しいです。すべての列をnull許容として作成するのは間違いですが、特定のビジネス機能では、列をnull許容として定義する必要がある場合があります。著者自身の言葉で:
すべての列はNULL可能ですか?データベース列の定義内で、ビジネスアプリケーション用に、適切なデータドメイン、範囲、および値を分析、評価、およびプロトタイプ化する必要があります。パフォーマンスとアプリケーションロジックには、適切なデフォルト値、限られた範囲の値、および常に値が最適です。 NULL可能列は、データが不明であるか、まだ値がない場合にのみ有効です。誰かの死亡日データは、すでに死亡していない限り不明であるため、NULL可能列の典型的な例です。データベース設計が既知のデータを表し、最小限のNULL可能列のみを使用していることを確認してください。Beulke氏のヒントは、多少独創的ではないとしても、すべて非常に堅実です。もっとビッグデータアイテム、つまり記事のタイトルが欲しかったのです。結局、記事の深さと幅の両方が不足していると感じ、ポイントを明確にする例がありませんでした。ただし、彼は正規化と自然キーに関連する貴重なアドバイスを提供しています。
10データベース設計のベストプラクティス
by Ann All |今日のエンタープライズアプリ| 2014年7月15日
10のデータベース設計のベストプラクティスは、実際には一連のスライドとして提示されています。 Ms. Allには、MichaelBlahaなどの経験豊富な開発者からの情報が含まれています。彼はあなたのベストプラクティスとパターンの再利用を奨励しています。これらは理解され、証明されており、その点で、最初から作成する必要のあるデータモデルよりも望ましいです。オールさんの記事から:
たとえば、私はデータベースをリバースエンジニアリングすることがよくあります。これは、置き換えるアプリケーションのデータベースと、関連するアプリケーションのデータベースです。これらの既存のデータベースには、多くの場合、利用可能なデータモデルがありません。ただし、データモデルはデータベーススキーマに暗黙的に含まれており、データベースのリバースエンジニアリング手法を使用して少なくとも部分的に抽出できます。 …頻繁に発生し、最初から再作成する必要のない、実証済みのデータ表現があります。これは短いスライドショーであり、データモデルの設計者は、自分たちの共感を呼ぶヒントをすばやくスキャンして収集できます。私にとって、再利用のヒントは私のお気に入りの1つです。
データベースのベストプラクティス
by Cunningham&Cunningham、Inc.
これらのベストプラクティスは、最初は問題なく開始されましたが、その後、いくつかの厄介な問題が発生しました。提供されたアドバイスが常に適切であるとは確信していません。
良い面としては、常に自動生成された代理キーを使用したり、ストアドプロシージャを使用または回避したりするなど、物議を醸す「ベストプラクティス」についての非常に優れた説明があります。例として:
以前の著者は次のように書いています。「一般に、意味のあるPrimaryKeysは避けてください。名前は一意ではなく、社会保障番号などの多くの一見一意の識別子は、実際のデータの信頼性の問題のため、実際には一意ではありません。」つまり、これは、ドメインベースのLogicalKeyではなく、常に自動生成された(通常は数値の)SurrogateKeyを使用することをお勧めします。これは複雑な問題に対するかなり適切な答えですが、多くの場合に十分であり、少なくともPrimaryKeyがまったくない場合よりも望ましい方法です。(著者のメモ:Googleでこれらの2つの文を検索したときに、この「前の著者」を見つけることができませんでした。)
また、自動キーとドメインキーの議論の両側の主な議論に関する要約記事へのリンクが提供されています。
一方、「オペレーティングシステム、データ、および異なる物理ディスクへのログオンを分割する」および「RAIDを使用する」ためのヒントは少し難解でした。誤解しないでください。これは状況によってはおそらく適切なアドバイスですが、トップ20リストには含めません。
データベース設計のヒント
ワイズコーダーによる
このコレクションには、トランザクションをできるだけ早く終了することを推奨するなど、いくつかのユニークで興味深いヒントがあります。
ただし、ここにあるすべての設計のヒントに完全には同意しません。例:
値が「アクティブ」、「非アクティブ」、「アイドル」のフィールド「ステータス」を想定します。値を完全な名前として保存することもできますが、これは非効率的です。たとえば、可能な値「a」、「i」、「d」を使用して列挙型またはchar(1)を格納すると、データベースで使用するスペースが少なくなります。控えめに言っても、これは物議を醸しています–他の情報源は、このような「秘密のコード」を採用することを推奨していません。代わりに、別のテーブルを使用してこれらのステータスコードを保存してください。
さらに、パフォーマンスのヒントに関連する統計には疑問があり、記事には例がありません。
ポジティブなことに、これは中級のデータベースモデラーがアクセスできるはずのヒントの短いリストです。
データベース設計者を始めるためのリソース
それでは、データベース設計を始めたばかりの人のために、いくつかの記事を見てみましょう。
Web開発における優れたデータベース設計の基本
by Kayla Knight | Onextrapixel.com | 2011年3月17日
ここでは、機能からモデリングツールに至るまでのアドバイスを使用して、もう少し高度な方法を学びます。
ナイトさんがデータベース設計の概要を説明してくれます。彼女の記事は、Web開発用のデータベースに重点を置いているため興味深いものです。それでも、彼女のポイントはかなり普遍的であり、多くの状況でデータベース設計に適用できます。
この記事は、データベースだけでなく、機能について広く考えるように依頼することから始まります。
データベースの外側を考えてください。 ウェブサイトが何をする必要があるかについて考えてみてください。たとえば、メンバーシップWebサイトが必要な場合、最初の本能は、各ユーザーが保存する必要のあるすべてのデータについて考え始めることかもしれません。忘れてください、それは後でです。むしろ、ユーザーとその情報をデータベースに保存する必要があることを書き留めてください。他に何がありますか?それらのメンバーはサイトで何をする必要がありますか?彼らは投稿をしたり、ファイルや写真をアップロードしたり、メッセージを送信したりしますか?次に、データベースには、ファイル/写真、投稿、およびメッセージ用の場所が必要になります。そこから、ナイトさんは読者をデータベース設計ツールとプロセスに含まれるステップに連れて行きます。彼女の記事には、例と他のリソースへのリンクが記載されています。
この記事は、初心者のデータベースデザイナーにとって素晴らしい入門書になると思います。また、 Geek Girl’sでもうまく機能するはずです。 シリーズ。
データベース設計のヒントを探る
by Doug Lowe |ダミーの場合
ロウ氏の「ダミー」リストは、基本的な設計のヒントの幅広いシリーズです。これらの多くは他の場所で見つけることができますが、1か所にまとめておくと便利です。ストアドプロシージャの使用を推奨する場合を除いて、ユニークなものや非常に物議を醸すものはありません。複数のDBMシステムのデータモデルの移植性について非常に懸念しているため、私は常にこの強力な声明に疑問を投げかけています。
ロウ氏の常識的なヒントの1つは次のとおりです。
CustomerTypeのような名前のフィールドは避けてください。フィールドの値は、小売のRや卸売のWなど、データベースの他の場所で定義されていないいくつかの定数の1つです。現在、これら2つのタイプの顧客しかない場合がありますが、アプリケーションのニーズは将来変更される可能性があり、3番目の顧客タイプが必要になります。これらの推奨事項は、SQLServerを使用する場合に最も適切です。
5つの簡単なデータベース設計のヒント
by Lamont Adams | TechRepublic | 2001年6月25日
このリソースのキーワードは「シンプル」です。この情報は、他の記事で、より多くの説明と例とともに見つけることができます。
ただし、「ユーザーのキーを奪う」というアダムズ氏のアドバイスは興味深い点であり、他の場所ではめったに言及されていません。彼は続けます:
テーブルのキーとして使用する1つまたは複数のフィールドを決定するときは、ユーザーが編集するフィールドを常に考慮してください。通常、ユーザーが編集可能なフィールドをキーとして選択することはお勧めできません。Adams氏の意味は、キーとして使用するフィールドを決定するときに、フィールドを編集するためのユーザーの潜在的な要件を考慮する必要があるということです。合成/生成されたキーなどの代替案についてもっと説明したかったのですが、コンセプトは良いです。
私は最後の点に同意しませんでした。彼は、設計するテーブルごとに「ファッジファクター」を推奨しています。
「完成した」データベースに重要な情報のフィールドがないことを発見したり、通知を受けたりすることほど悪いことはありません。私が働いていたある会社では、これは非常に一般的な出来事であり、「データベースのフリーズ」を「データベースのスラッシュ」と呼び始めました。私の考えでは、これは基本的に「最後にいくつかのテキストフィールドを追加すること」です。これは、アダムズ氏の他のヒントのいくつか、特にビジネスニーズの理解と意味のある名前の使用に関するヒントと矛盾しているようです。これらの余分なファッジフィールドは、単に「extra1」または「extra2」のようなものと呼ばれます。彼らのビジネスニーズは何ですか?そして、これらの意味のある名前はどうですか?私は彼のデザインのヒントのほとんどが好きですが、この「ファッジファクター」は私が固執するものではありません。
データベース設計:佳作
明らかに、データベース設計のヒントとベストプラクティスを説明する他の記事があります。次のリンクで追加の資料を見つけることができます:
リレーショナルデータベースの設計:ベストプラクティス入門書| DigitalEthosによる| 2012年12月24日
データベーススキーマ設計のベストプラクティス(初心者)|ジム・マーフィー2011年3月28日
ITのベストプラクティス:データベース設計|ネブラスカ大学リンカーン校
オンラインデータベース設計リソース:どこに行きますか?
前述のように、このリストは、インターネット上のすべてのデータベース設計記事を網羅的に調査することを意図したものではありません。むしろ、有用であると思われる記事や、役立つと思われる特定の焦点を持っている記事をいくつか特定しました。
追加の記事をお気軽にお勧めください。