この記事は、T-SQLのバグ、落とし穴、およびベストプラクティスに関するシリーズの第5部です。以前は、決定論、サブクエリ、結合、およびウィンドウ処理について説明しました。今月は、ピボットとアンピボットについて説明します。 Erland Sommarskog、Aaron Bertrand、Alejandro Mesa、Umachandar Jayachandran(UC)、Fabiano Neves Amorim、Milos Radivojevic、Simon Sabin、Adam Machanic、Thomas Grohser、Chan Ming Man、PaulWhiteに提案を共有していただきありがとうございます。
私の例では、TSQLV5というサンプルデータベースを使用します。このデータベースを作成してデータを取り込むスクリプトはここにあり、そのER図はここにあります。
PIVOTによる暗黙のグループ化
T-SQLを使用してデータをピボットする場合は、グループ化されたクエリとCASE式を使用する標準ソリューション、または独自のPIVOTテーブル演算子を使用します。 PIVOT演算子の主な利点は、コードが短くなる傾向があることです。ただし、この演算子にはいくつかの欠点があります。その中には、コードにバグが発生する可能性のある固有の設計トラップがあります。ここでは、トラップ、潜在的なバグ、およびバグを防ぐためのベストプラクティスについて説明します。また、バグを回避するのに役立つ方法でPIVOT演算子の構文を拡張するための提案についても説明します。
データをピボットする場合、ソリューションには3つのステップがあり、3つの要素が関連付けられています。
- grouping /onrows要素に基づくグループ化
- Spreading /oncols要素に基づくSpread
- 集計/データ要素に基づいて集計
PIVOT演算子の構文は次のとおりです。
SELECT <select_list>
FROM <source_table>
PIVOT( <aggregate_function>(<aggregate_col>)
FOR <spread_col> IN(<target_cols>) ) AS <alias>; PIVOT演算子の設計では、集約要素と拡散要素を明示的に指定する必要がありますが、SQLServerでは削除によってグループ化要素を暗黙的に把握できます。 PIVOTオペレーターへの入力として提供されるソーステーブルに表示される列は、暗黙的にグループ化要素になります。
たとえば、TSQLV5サンプルデータベースのSales.Ordersテーブルをクエリするとします。行に荷送人ID、列に出荷年、および荷送人ごとの注文数と年を集計として返したいとします。
多くの人は、PIVOT演算子の構文を理解するのに苦労しており、これにより、多くの場合、不要な要素によってデータがグループ化されます。タスクの例として、グループ化要素が暗黙的に決定されていることに気づかず、次のクエリを思いついたとします。
SELECT shipperid, [2017], [2018], [2019] FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shippedyear IN([2017], [2018], [2019]) ) AS P;
データには荷送人が3つだけ存在し、荷送人IDは1、2、3です。したがって、結果には3つの行しか表示されないはずです。ただし、実際のクエリ出力にはさらに多くの行が表示されます:
shipperid 2017 2018 2019 ----------- ----------- ----------- ----------- 3 1 0 0 1 1 0 0 2 1 0 0 1 1 0 0 2 1 0 0 2 1 0 0 2 1 0 0 3 1 0 0 2 1 0 0 3 1 0 0 ... 3 0 1 0 3 0 1 0 3 0 1 0 1 0 1 0 3 0 1 0 1 0 1 0 3 0 1 0 3 0 1 0 3 0 1 0 1 0 1 0 ... 3 0 0 1 1 0 0 1 2 0 0 1 1 0 0 1 2 0 0 1 1 0 0 1 3 0 0 1 3 0 0 1 2 0 1 0 ... (830 rows affected)
どうしたの?
図1に示すクエリプランを見ると、コードのバグを理解するのに役立つ手がかりを見つけることができます。
 図1:暗黙的なグループ化を使用したピボットクエリの計画
図1:暗黙的なグループ化を使用したピボットクエリの計画
クエリでVALUES句を指定してCROSSAPPLY演算子を使用すると、混乱しないようにしてください。これは、ソースのshippeddate列に基づいて結果列shippedyearを計算するためだけに行われ、プランの最初のComputeScalarオペレーターによって処理されます。
PIVOTオペレーターへの入力テーブルには、Sales.Ordersテーブルのすべての列と、shippedyearの結果列が含まれます。前述のように、SQL Serverは、集計(shippeddate)要素と拡散(shippedyear)要素として指定しなかったものに基づいて削除することにより、グループ化要素を暗黙的に決定します。おそらく、shipperid列がSELECTリストに表示されるため、グループ化列であると直感的に予想していましたが、計画でわかるように、実際には、の主キー列であるorderidを含むはるかに長い列のリストが得られました。ソーステーブル。これは、荷送人ごとに行を取得するのではなく、注文ごとに行を取得することを意味します。 SELECTリストでは、shipperid、[2017]、[2018]、[2019]の列のみを指定したため、残りは表示されないため、混乱が生じます。しかし、残りは暗黙のグループ化に参加しました。
PIVOT演算子の構文が、grouping /onrows要素を明示的に示すことができる句をサポートしている場合は素晴らしいかもしれません。このようなもの:
SELECT <select_list>
FROM <source_table>
PIVOT( <aggregate_function>(<aggregate_col>)
FOR <spread_col> IN(<target_cols>)
ON ROWS <grouping_cols> ) AS <alias>; この構文に基づいて、次のコードを使用してタスクを処理します。
SELECT shipperid, [2017], [2018], [2019]
FROM Sales.Orders
CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear)
PIVOT( COUNT(shippeddate)
FOR shippedyear IN([2017], [2018], [2019])
ON ROWS shipperid ) AS P; ここで、PIVOT演算子の構文を改善するための提案を含むフィードバック項目を見つけることができます。この改善を壊さない変更にするために、この句をオプションにすることができます。デフォルトは既存の動作です。 PIVOT演算子の構文をより動的にし、複数の集計をサポートすることにより、構文を改善するための他の提案があります。
それまでの間、バグを回避するのに役立つベストプラクティスがあります。 CTEや派生テーブルなどのテーブル式を使用して、ピボット操作に関与する必要がある3つの要素のみを投影し、テーブル式をPIVOTオペレーターへの入力として使用します。このようにして、グループ化要素を完全に制御します。このベストプラクティスに従った一般的な構文は次のとおりです。
WITH <CTE_name> AS
(
SELECT <group_cols>, <spread_col>, <aggregate_col>
FROM <source_table>
)
SELECT <select_list>
FROM <CTE_name>
PIVOT( <aggregate_function>(<aggregate_col>)
FOR <spread_col> IN(<target_cols>) ) AS <alias>; 私たちのタスクに適用するには、次のコードを使用します:
WITH C AS
(
SELECT shipperid, YEAR(shippeddate) AS shippedyear, shippeddate
FROM Sales.Orders
)
SELECT shipperid, [2017], [2018], [2019]
FROM C
PIVOT( COUNT(shippeddate)
FOR shippedyear IN([2017], [2018], [2019]) ) AS P; 今回は、期待どおりに3つの結果行のみが表示されます。
shipperid 2017 2018 2019 ----------- ----------- ----------- ----------- 3 51 125 73 1 36 130 79 2 56 143 116
もう1つのオプションは、次のように、グループ化されたクエリとCASE式を使用してピボットするための古くて古典的な標準ソリューションを使用することです。
SELECT shipperid, COUNT(CASE WHEN shippedyear = 2017 THEN 1 END) AS [2017], COUNT(CASE WHEN shippedyear = 2018 THEN 1 END) AS [2018], COUNT(CASE WHEN shippedyear = 2019 THEN 1 END) AS [2019] FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) WHERE shippeddate IS NOT NULL GROUP BY shipperid;
この構文では、3つのピボットステップすべてとそれに関連する要素をコード内で明示的にする必要があります。ただし、拡散値が多数ある場合、この構文は冗長になる傾向があります。このような場合、人々はしばしばPIVOT演算子を使用することを好みます。
UNPIVOTを使用したNULLの暗黙的な削除
この記事の次の項目は、バグというよりは落とし穴です。これは、独自のT-SQL UNPIVOT演算子と関係があります。これにより、データを列の状態から行の状態にピボット解除できます。
サンプルデータとしてCustOrdersというテーブルを使用します。次のコードを使用して、このテーブルを作成、入力、クエリして、その内容を表示します。
DROP TABLE IF EXISTS dbo.CustOrders;
GO
WITH C AS
(
SELECT custid, YEAR(orderdate) AS orderyearyear, val
FROM Sales.OrderValues
)
SELECT custid, [2017], [2018], [2019]
INTO dbo.CustOrders
FROM C
PIVOT( SUM(val)
FOR orderyearyear IN([2017], [2018], [2019]) ) AS P;
SELECT * FROM dbo.CustOrders; このコードは次の出力を生成します:
custid 2017 2018 2019 ------- ---------- ---------- ---------- 1 NULL 2022.50 2250.50 2 88.80 799.75 514.40 3 403.20 5960.78 660.00 4 1379.00 6406.90 5604.75 5 4324.40 13849.02 6754.16 6 NULL 1079.80 2160.00 7 9986.20 7817.88 730.00 8 982.00 3026.85 224.00 9 4074.28 11208.36 6680.61 10 1832.80 7630.25 11338.56 11 479.40 3179.50 2431.00 12 NULL 238.00 1576.80 13 100.80 NULL NULL 14 1674.22 6516.40 4158.26 15 2169.00 1128.00 513.75 16 NULL 787.60 931.50 17 533.60 420.00 2809.61 18 268.80 487.00 860.10 19 950.00 4514.35 9296.69 20 15568.07 48096.27 41210.65 ...
このテーブルは、顧客および年ごとの合計注文値を保持します。 NULLは、顧客が対象年に注文活動を行わなかった場合を表します。
CustOrdersテーブルからデータのピボットを解除し、顧客および年ごとの行を返し、valという結果列に現在の顧客および年の合計注文値を保持するとします。ピボットを解除するタスクには、通常、次の3つの要素が含まれます。
- ピボットを解除する既存のソース列の名前:この場合は[2017]、[2018]、[2019]
- ソース列名を保持するターゲット列に割り当てる名前:この場合はorderyear
- ソース列の値を保持するターゲット列に割り当てる名前:この場合はval
UNPIVOT演算子を使用してピボット解除タスクを処理する場合は、最初に上記の3つの要素を理解してから、次の構文を使用します。
SELECT <table_cols except source_cols>, <names_col>, <values_col> FROM <source_table> UNPIVOT( <values_col> FOR <names_col> IN(<source_cols>) ) AS <alias>;
私たちのタスクに適用するには、次のクエリを使用します:
SELECT custid, orderyear, val FROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
このクエリは次の出力を生成します:
custid orderyear val ------- ---------- ---------- 1 2018 2022.50 1 2019 2250.50 2 2017 88.80 2 2018 799.75 2 2019 514.40 3 2017 403.20 3 2018 5960.78 3 2019 660.00 4 2017 1379.00 4 2018 6406.90 4 2019 5604.75 5 2017 4324.40 5 2018 13849.02 5 2019 6754.16 6 2018 1079.80 6 2019 2160.00 7 2017 9986.20 7 2018 7817.88 7 2019 730.00 ...
ソースデータとクエリ結果を見て、何が欠けているかに気づきましたか?
UNPIVOT演算子の設計には、値の列にNULL(この場合はval)が含まれる結果行の暗黙的な削除が含まれます。図2に示すこのクエリの実行プランを見ると、フィルター演算子がval列(プランのExpr1007)にNULLが含まれる行を削除していることがわかります。
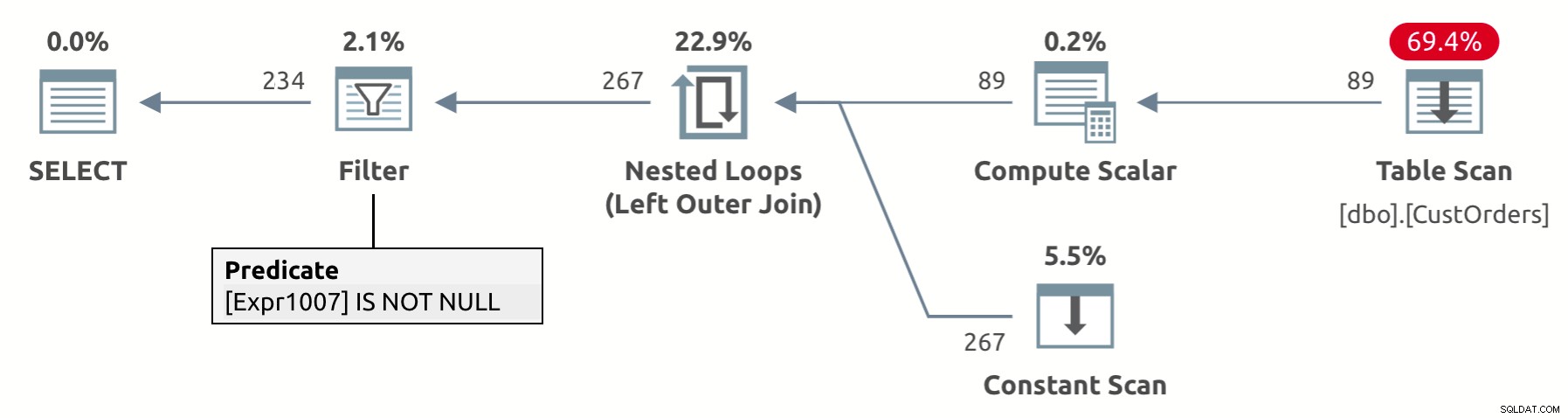 図2:NULLを暗黙的に削除するピボット解除クエリの計画
図2:NULLを暗黙的に削除するピボット解除クエリの計画
この動作が望ましい場合もあります。その場合、特別なことをする必要はありません。問題は、行をNULLのままにしておきたい場合があることです。落とし穴は、NULLを保持したいが、UNPIVOT演算子がNULLを削除するように設計されていることに気付かない場合です。
UNPIVOT演算子に、NULLを削除するか保持するかを指定できるオプションの句があり、前者が下位互換性のデフォルトである場合は、すばらしい可能性があります。この構文がどのように見えるかの例を次に示します。
SELECT <table_cols except source_cols>, <names_col>, <values_col>
FROM <source_table>
UNPIVOT( <values_col> FOR <names_col> IN(<source_cols>)
[REMOVE NULLS | KEEP NULLS] ) AS <alias>; NULLを保持したい場合は、この構文に基づいて、次のクエリを使用します。
SELECT custid, orderyear, val FROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) KEEP NULLS ) AS U;
UNPIVOT演算子の構文をこのように改善するための提案を含むフィードバック項目は、ここにあります。
それまでの間、行をNULLのままにしておきたい場合は、回避策を考え出す必要があります。 UNPIVOT演算子の使用を主張する場合は、2つの手順を適用する必要があります。最初のステップでは、ISNULLまたはCOALESCE関数を使用するクエリに基づいてテーブル式を定義し、ピボットされていないすべての列のNULLを、通常はデータに表示できない値(この場合は-1)に置き換えます。 2番目のステップでは、値列に対する外部クエリでNULLIF関数を使用して、-1をNULLに置き換えます。完全なソリューションコードは次のとおりです。
WITH C AS
(
SELECT custid,
ISNULL([2017], -1.0) AS [2017],
ISNULL([2018], -1.0) AS [2018],
ISNULL([2019], -1.0) AS [2019]
FROM dbo.CustOrders
)
SELECT custid, orderyear, NULLIF(val, -1.0) AS val
FROM C UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U; このクエリの出力は、val列にNULLが含まれる行が保持されることを示しています。
custid orderyear val ------- ---------- ---------- 1 2017 NULL 1 2018 2022.50 1 2019 2250.50 2 2017 88.80 2 2018 799.75 2 2019 514.40 3 2017 403.20 3 2018 5960.78 3 2019 660.00 4 2017 1379.00 4 2018 6406.90 4 2019 5604.75 5 2017 4324.40 5 2018 13849.02 5 2019 6754.16 6 2017 NULL 6 2018 1079.80 6 2019 2160.00 7 2017 9986.20 7 2018 7817.88 7 2019 730.00 ...
このアプローチは、特にピボットを解除する列が多数ある場合は扱いにくいです。
別のソリューションでは、APPLY演算子とVALUES句の組み合わせを使用します。ピボットされていない列ごとに行を作成します。1つの列はターゲット名の列(この場合はorderyear)を表し、もう1つの列はターゲット値の列(この場合はval)を表します。名前の列には定数年を指定し、値の列には関連する相関ソース列を指定します。完全なソリューションコードは次のとおりです。
SELECT custid, orderyear, val
FROM dbo.CustOrders
CROSS APPLY ( VALUES(2017, [2017]),
(2018, [2018]),
(2019, [2019]) ) AS A(orderyear, val); ここでの良い点は、val列にNULLが含まれる行を削除することに関心がない限り、特別なことをする必要がないことです。 NULLSを含む行を削除する暗黙の手順はここにはありません。さらに、val列のエイリアスはFROM句の一部として作成されるため、WHERE句にアクセスできます。したがって、NULLの削除に関心がある場合は、次のように、values列のエイリアスと直接対話することにより、WHERE句でそれについて明示することができます。
SELECT custid, orderyear, val
FROM dbo.CustOrders
CROSS APPLY ( VALUES(2017, [2017]),
(2018, [2018]),
(2019, [2019]) ) AS A(orderyear, val)
WHERE val IS NOT NULL; 重要なのは、この構文により、NULLを保持するか削除するかを制御できるということです。別の点では、UNPIVOT演算子よりも柔軟性があり、valやqtyなどの複数のピボットされていないメジャーを処理できます。ただし、この記事で焦点を当てたのはNULLに関連する落とし穴だったため、この側面については説明しませんでした。
結論
PIVOTおよびUNPIVOT演算子の設計により、コードにバグや落とし穴が生じることがあります。 PIVOT演算子の構文では、グループ化要素を明示的に示すことはできません。これに気付いていない場合は、望ましくないグループ化要素になってしまう可能性があります。ベストプラクティスとして、PIVOT演算子への入力としてテーブル式を使用することをお勧めします。これが、グループ化要素を明示的に制御する理由です。
UNPIVOT演算子の構文では、結果値の列にNULLが含まれる行を削除するか保持するかを制御できません。回避策として、ISNULLおよびNULLIF関数を使用した厄介なソリューション、またはAPPLY演算子とVALUES句に基づくソリューションのいずれかを使用します。
また、PIVOT演算子とUNPIVOT演算子を改善するための提案とともに、演算子とその要素の動作を制御するためのより明確なオプションを備えた2つのフィードバック項目についても言及しました。