サポートするインデックスは、ウィンドウ関数を含むT-SQLクエリを最適化するときに、クエリプランで明示的な並べ替えの必要性を回避するのに役立つ可能性があります。 サポートインデックス つまり、ウィンドウのパーティション分割と順序付けの要素をインデックスキーとして使用し、クエリにインデックスに含まれる列として表示される残りの列を使用します。私はよくこのようなインデックスパターンをPOCと呼びます partitioningの頭字語としてのインデックス 、注文 およびカバー 。当然、パーティション化または順序付け要素がウィンドウ関数に表示されない場合は、その部分をインデックス定義から省略します。
しかし、順序付けのニーズが異なる複数のウィンドウ関数を含むクエリについてはどうでしょうか。同様に、ウィンドウ関数以外のクエリの他の要素でも、プレゼンテーションのORDER BY句など、プランで順序付けられた入力データを配置する必要がある場合はどうなりますか?これらの結果、計画のさまざまな部分で入力データをさまざまな順序で処理する必要が生じる可能性があります。
このような状況では、通常、プランで明示的な並べ替えが避けられないことを受け入れます。クエリ内の式の構文上の配置が数に影響する場合があります。 プランで取得する明示的なソート演算子。いくつかの基本的なヒントに従うことで、明示的な並べ替え演算子の数を減らすことができます。もちろん、これはクエリのパフォーマンスに大きな影響を与える可能性があります。
デモの環境
私の例では、サンプルデータベースPerformanceV5を使用します。ここからソースコードをダウンロードして、このデータベースを作成してデータを取り込むことができます。
行ストアでバッチモードを使用できるSQLServer2019Developerですべての例を実行しました。
この記事では、プランで追加の明示的な並べ替えアクティビティを必要とせずに、順序付けられた入力データに依存するプランでのウィンドウ関数の計算の可能性に関係するヒントに焦点を当てたいと思います。これは、オプティマイザがウィンドウ関数のシリアルまたはパラレル行モード処理を使用する場合、およびシリアルバッチモードのウィンドウ集計演算子を使用する場合に関連します。
SQL Serverは現在、並列バッチモードのウィンドウ集約演算子の前に、並列順序を保持する入力の効率的な組み合わせをサポートしていません。したがって、並列バッチモードのウィンドウ集計演算子を使用するには、入力がすでに事前注文されている場合でも、オプティマイザは中間の並列バッチモードの並べ替え演算子を挿入する必要があります。
簡単にするために、この記事に示されているすべての例で並列処理を防ぐことができます。すべてのクエリにヒントを追加する必要がなく、サーバー全体の構成オプションを設定せずにこれを実現するには、データベーススコープの構成オプションMAXDOPを設定できます。 1へ 、そのように:
USE PerformanceV5; ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;
この記事の例のテストが終了したら、忘れずに0に戻してください。最後にお知らせします。
または、文書化されていないDBCC OPTIMIZER_WHATIFを使用して、セッションレベルでの並列処理を防ぐことができます。 コマンド、そのように:
DBCC OPTIMIZER_WHATIF(CPUs, 1);
完了時にオプションをリセットするには、CPUの数として値0を指定してオプションを再度呼び出します。
並列処理を無効にしてこの記事のすべての例を試し終わったら、並列処理を有効にして、すべての例をもう一度試し、どのような変更があるかを確認することをお勧めします。
ヒント1と2
ヒントを始める前に、まず、supp class ="border indent shadowortingindex。
を利用するように設計されたウィンドウ関数を使用した簡単な例を見てみましょう。次のクエリについて考えてみます。これをクエリ1と呼びます。
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1 FROM dbo.Orders;
例が考案されているという事実について心配する必要はありません。注文IDの現在の合計を計算するビジネス上の理由はありません。このテーブルは、100万行の適切なサイズであり、現在の合計の計算を適用するような一般的なウィンドウ関数を使用した簡単な例を示したいと思いました。
POCインデックススキームに従って、クエリをサポートする次のインデックスを作成します。
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);
このクエリの計画を図1に示します。
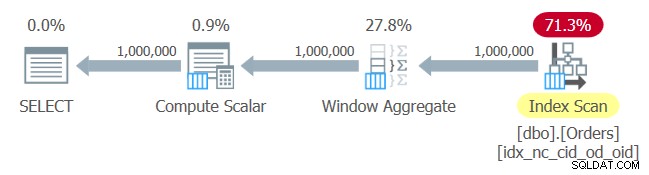 図1:クエリ1の計画
図1:クエリ1の計画
ここに驚きはありません。このプランでは、作成したばかりのインデックスのインデックス順序スキャンが適用され、明示的な並べ替えを必要とせずに、順序付けされたデータがWindowAggregateオペレーターに提供されます。
次に、次のクエリについて考えます。これには、順序付けのニーズが異なる複数のウィンドウ関数と、プレゼンテーションのORDERBY句が含まれます。
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3 FROM dbo.Orders ORDER BY custid, orderid;
このクエリをクエリ2と呼びます。このクエリの計画を図2に示します。
 図2:クエリ2の計画
図2:クエリ2の計画
プランには4つのソート演算子があることに注意してください。
さまざまなウィンドウ関数とプレゼンテーションの順序付けのニーズを分析すると、3つの異なる順序付けのニーズがあることがわかります。
- custid、orderdate、orderid
- orderid
- custid、orderid
それらの1つ(上記のリストの最初)が以前に作成したインデックスでサポートできる場合、プランには2つの種類しか表示されないことが予想されます。では、なぜ計画には4つの種類があるのでしょうか。 SQL Serverは、並べ替えを最小限に抑えるために、計画内の関数の処理順序を再配置することで、あまり洗練されようとはしていないようです。プラン内の関数を、クエリに表示される順序で処理します。少なくとも、それぞれの個別の注文ニーズが最初に発生する場合はそうですが、これについては後ほど詳しく説明します。
次の2つの簡単な方法を適用することで、計画の一部の種類の必要性を取り除くことができます。
ヒント1:クエリで一部のウィンドウ関数をサポートするインデックスがある場合は、最初にそれらを指定します。
ヒント2:クエリに、クエリでのプレゼンテーションの順序と同じ順序が必要なウィンドウ関数が含まれている場合は、それらの関数を最後に指定します。
これらのヒントに従って、クエリ内のウィンドウ関数の表示順序を次のように並べ替えます。
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders ORDER BY custid, orderid;
このクエリをクエリ3と呼びます。このクエリの計画を図3に示します。
 図3:クエリ3の計画
図3:クエリ3の計画
ご覧のとおり、プランには2種類しかありません。
ヒント3
SQL Serverは、計画内の並べ替えを最小限に抑えるために、ウィンドウ関数の処理順序を高度に調整しようとはしていません。ただし、特定の単純な再配置が可能です。クエリ内の出現順序に基づいてウィンドウ関数をスキャンし、新しい個別の順序付けの必要性を検出するたびに、同じ順序付けの必要性を持つ追加のウィンドウ関数を探し、それらが見つかった場合は、最初の出現と一緒にグループ化します。場合によっては、同じ演算子を使用して複数のウィンドウ関数を計算することもできます。
例として次のクエリを考えてみましょう。
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2 FROM dbo.Orders ORDER BY custid, orderid;
このクエリをクエリ4と呼びます。このクエリの計画を図4に示します。
 図4:クエリ4の計画
図4:クエリ4の計画
同じ順序付けのニーズを持つウィンドウ関数は、クエリでグループ化されません。ただし、計画にはまだ2種類しかありません。これは、プランの処理順序の観点から重要なのは、それぞれの個別の順序付けのニーズが最初に発生するためです。これは私を3番目のヒントに導きます。
ヒント3:個別の注文ニーズが最初に発生する場合は、必ずヒント1と2に従ってください。隣接していない場合でも、同じ順序付けのニーズの後続の発生が識別され、最初の発生と一緒にグループ化されます。
ヒント4と5
ウィンドウ化された計算の結果の列を、出力で特定の左から右の順序で返したいとします。しかし、順序がプランの並べ替えを最小化する順序と同じでない場合はどうなりますか?
たとえば、出力の左から右への列の順序(列の順序:他の列、sum2、sum1、sum3)に関して、クエリ2で生成された結果と同じ結果が必要であるが、クエリ3(列の順序:他の列、sum1、sum3、sum2)で取得したものと同じプランで、4つではなく2つの並べ替えを取得しました。
4番目のヒントに精通している場合、これは完全に実行可能です。
ヒント4:前述の推奨事項は、CTEやビューなどの名前付きテーブル式内であっても、外部クエリが列をとは異なる順序で返す場合でも、コード内のウィンドウ関数の出現順序に適用されます。名前付きテーブル式。したがって、出力で特定の順序で列を返す必要があり、プランの並べ替えを最小化するという点で最適な順序とは異なる場合は、名前付きテーブル式内の出現順序に関するヒントに従って、列を返します。目的の出力順序で外部クエリに入力します。
次のクエリ(クエリ5と呼びます)は、この手法を示しています。
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; このクエリの計画を図5に示します。
 図5:クエリ5の計画
図5:クエリ5の計画
クエリ2のように、出力の列の順序が他のcols、sum2、sum1、sum3であるにもかかわらず、プランでは2つの並べ替えしか取得できません。
名前付きテーブル式を使用したこのトリックの注意点の1つは、テーブル式の列が外部クエリによって参照されていない場合、それらはプランから除外されるため、カウントされないことです。
次のクエリについて考えてみます。これをクエリ6と呼びます。
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid; ここでは、すべてのテーブル式の列が外部クエリによって参照されるため、最適化は、テーブル式内の各順序付けのニーズの最初の個別の発生に基づいて行われます。
- max1:custid、orderdate、orderid
- max3:orderid
- max2:custid、orderid
これにより、図6に示すように、2種類のみのプランが作成されます。
 図6:クエリ6の計画
図6:クエリ6の計画
次に、次のように、max2、max1、max3、avg2、avg1、およびavg3への参照を削除して、外部クエリのみを変更します。
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; このクエリをクエリ7と呼びます。テーブル式のmax1、max3、max2、avg1、avg3、およびavg2の計算は、外部クエリとは無関係であるため、除外されます。外部クエリに関連するテーブル式のウィンドウ関数を含む残りの計算は、sum2、sum1、およびsum3の計算です。残念ながら、ソートを最小化するという観点から、これらはテーブル式に最適な順序で表示されません。図7に示すように、このクエリの計画からわかるように、4つの種類があります。
 図7:クエリ7の計画
図7:クエリ7の計画
外側のクエリでは参照しない列が内側のクエリに含まれる可能性が低いと思われる場合は、ビューを考えてください。ビューをクエリするたびに、列の異なるサブセットに関心がある場合があります。これを念頭に置いて、5番目のヒントは計画の種類を減らすのに役立つ可能性があります。
ヒント5:CTEやビューなどの名前付きテーブル式の内部クエリで、同じ順序のニーズを持つすべてのウィンドウ関数をグループ化し、関数のグループの順序でヒント1と2に従います。>
次のコードは、この推奨事項に基づいてビューを実装します。
CREATE OR ALTER VIEW dbo.MyView AS SELECT orderid, orderdate, custid, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2, SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders; GO
次に、ウィンドウ化された結果列sum2、sum1、sum3のみをこの順序で要求するビューをクエリします。
SELECT orderid, orderdate, custid, sum2, sum1, sum3 FROM dbo.MyView ORDER BY custid, orderid;
このクエリをクエリ8と呼びます。図8に示すように、2種類のプランしかありません。
 図8:クエリ8の計画
図8:クエリ8の計画
ヒント6
複数の異なる順序付けが必要な複数のウィンドウ関数を含むクエリがある場合、一般的な知識は、インデックスを介して事前に順序付けされたデータでそれらの1つのみをサポートできるということです。これは、すべてのウィンドウ関数にそれぞれのサポートインデックスがある場合でも当てはまります。
これを実演させてください。インデックスidx_nc_cid_od_oidを作成したときのことを思い出してください。これは、次の式など、custid、orderdate、orderidで並べ替えられたデータを必要とするウィンドウ関数をサポートできます。
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)
このウィンドウ関数に加えて、同じクエリで次のウィンドウ関数も必要であるとします。
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)
このウィンドウ関数は、次のインデックスの恩恵を受けます:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);
次のクエリ(クエリ9と呼びます)は、両方のウィンドウ関数を呼び出します。
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders;
このクエリの計画を図9に示します。
 図9:クエリ9の計画
図9:クエリ9の計画
自分のマシンでこのクエリの次の時間統計を取得し、結果はSSMSで破棄されます:
CPU time = 3234 ms, elapsed time = 3354 ms.
前に説明したように、SQL Serverは、ウィンドウ化された式をクエリに表示される順序でスキャンし、インデックスidx_nc_cid_od_oidの順序付きスキャンで最初の式をサポートできることを示します。ただし、次に、2番目のウィンドウ関数が必要とするようにデータを並べ替えるために、並べ替え演算子をプランに追加します。これは、プランにNlogNスケーリングがあることを意味します。 2番目のウィンドウ関数をサポートするためにインデックスidx_nc_cid_oidを使用することは考慮されていません。あなたはおそらくそれができないと思っているでしょうが、箱の外で少し考えてみてください。それぞれのインデックス順序に基づいて各ウィンドウ関数を計算し、結果を結合することはできませんか?理論的には可能であり、データのサイズ、インデックスの可用性、および利用可能なその他のリソースによっては、結合バージョンの方が優れている場合があります。 SQL Serverはこのアプローチを考慮していませんが、次のように自分で結合を記述して実装できます。
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid; このクエリをクエリ10と呼びます。このクエリの計画を図10に示します。
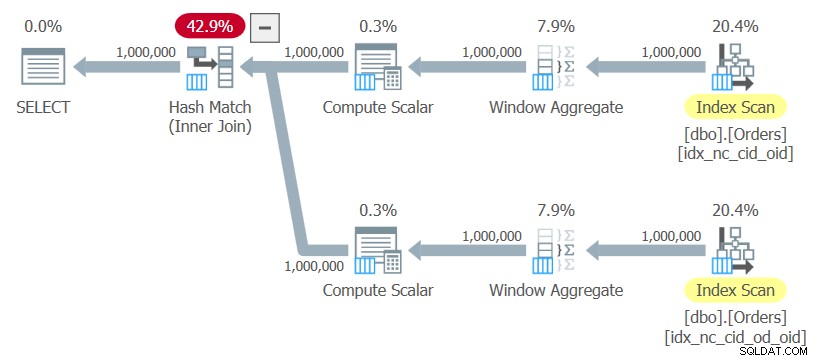 図10:クエリ10の計画
図10:クエリ10の計画
この計画では、明示的な並べ替えを一切行わずに2つのインデックスの順序付きスキャンを使用し、ウィンドウ関数を計算し、ハッシュ結合を使用して結果を結合します。このプランは、NlogNスケーリングの前のプランと比較して直線的にスケーリングします。
自分のマシンでこのクエリについて次の時間統計を取得します(ここでも結果はSSMSで破棄されます):
CPU time = 1000 ms, elapsed time = 1100 ms.
要約すると、これが6番目のヒントです。
ヒント6:複数の異なる順序付けが必要な複数のウィンドウ関数があり、それらすべてをインデックスでサポートできる場合は、結合バージョンを試して、そのパフォーマンスを結合なしのクエリと比較してください。
クリーンアップ
データベーススコープの構成オプションMAXDOPを1に設定して並列処理を無効にした場合は、0に設定して並列処理を再度有効にします。
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
文書化されていないセッションオプションDBCCOPTIMIZER_WHATIFをCPUオプションを1に設定して使用した場合は、0に設定して並列処理を再度有効にします。
DBCC OPTIMIZER_WHATIF(CPUs, 0);
必要に応じて、並列処理を有効にしてすべての例を再試行できます。
次のコードを使用して、作成した新しいインデックスをクリーンアップします。
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders; DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;
そして、ビューを削除するための次のコード:
DROP VIEW IF EXISTS dbo.MyView;
並べ替えの数を最小限に抑えるためのヒントに従ってください
ウィンドウ関数は、順序付けられた入力データを処理する必要があります。インデックス付けは、プラン内の並べ替えを排除するのに役立ちますが、通常は1つの明確な順序付けの必要性に対してのみです。複数の注文が必要なクエリは、通常、プランに何らかのものが含まれます。ただし、特定のヒントに従うことで、必要な並べ替えの数を最小限に抑えることができます。この記事で言及したヒントの概要は次のとおりです。
- ヒント1: クエリで一部のウィンドウ関数をサポートするインデックスがある場合は、最初にそれらを指定します。
- ヒント2: クエリに、クエリでのプレゼンテーションの順序と同じ順序が必要なウィンドウ関数が含まれる場合は、それらの関数を最後に指定します。
- ヒント3: それぞれの個別の注文ニーズが最初に発生する場合は、必ずヒント1と2に従ってください。隣接していない場合でも、同じ順序付けのニーズの後続の発生が識別され、最初の発生と一緒にグループ化されます。
- ヒント4: 前述の推奨事項は、CTEやビューなどの名前付きテーブル式内であっても、外部クエリが名前付きテーブル式とは異なる順序で列を返す場合でも、コード内のウィンドウ関数の出現順序に適用されます。したがって、出力で特定の順序で列を返す必要があり、プランの並べ替えを最小化するという点で最適な順序とは異なる場合は、名前付きテーブル式内の出現順序に関するヒントに従って、列を返します。目的の出力順序で外部クエリに。
- ヒント5: CTEやビューなどの名前付きテーブル式の内部クエリで、同じ順序のニーズを持つすべてのウィンドウ関数をグループ化し、関数のグループの順序でヒント1と2に従います。
- ヒント6: 複数の異なる順序付けが必要な複数のウィンドウ関数があり、それらすべてをインデックスでサポートできる場合は、結合バージョンを試して、そのパフォーマンスを結合なしのクエリと比較してください。