このシリーズの最初の部分で述べたように、明示的にパラメーター化する方がよい理由の1つは、パラメーターのデータ型を完全に制御できるようにすることです。単純なパラメーター化には、この領域に多くの癖があり、パラメーター化されたプランが予想よりも多くキャッシュされたり、パラメーター化されていないバージョンと比較して異なる結果が見つかる可能性があります。
SQLServerが単純なパラメーター化を適用する場合 アドホックステートメントに対して、置換パラメーターのデータ型を推測します。推測の理由については、シリーズの後半で説明します。
とりあえず、SQL Server 2019CU14でStackOverflow2010データベースを使用したいくつかの例を見てみましょう。データベースの互換性は150に設定され、並列処理のコストしきい値は50に設定されて、現時点では並列処理を回避します。
ALTER DATABASE SCOPED CONFIGURATION
CLEAR PROCEDURE_CACHE;
GO
SELECT U.DisplayName
FROM dbo.Users AS U
WHERE U.Reputation = 252;
GO
SELECT U.DisplayName
FROM dbo.Users AS U
WHERE U.Reputation = 25221;
GO
SELECT U.DisplayName
FROM dbo.Users AS U
WHERE U.Reputation = 252552; これらのステートメントにより、6つのキャッシュされたプラン、3つのアドホック および3つの準備済み :
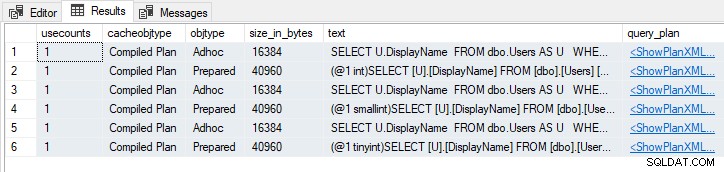
準備済みのさまざまなパラメータデータ型に注意してください 計画。
各データ型がどのように推測されるかの詳細は複雑であり、文書化が不完全です。開始点として、SQL Serverは値のテキスト表現から基本タイプを推測し、互換性のある最小のサブタイプを使用します。
引用符または小数点のない数値の文字列の場合、SQLServerはtinyintから選択します 、smallint 、およびinteger 。 integerの範囲を超えるそのような数値の場合 、SQLServerはnumericを使用します 可能な限り最小の精度で。たとえば、数値2,147,483,648は、numeric(10,0)と入力されます。 。 bigint typeは、サーバー側のパラメーター化には使用されません。この段落では、前の例で選択したデータ型について説明します。
数字の文字列with 小数点はnumericとして解釈されます 、提供された値を含むのに十分な大きさの精度とスケールで。通貨記号が前に付いた文字列は、moneyとして解釈されます。 。科学的記数法の文字列はfloatに変換されます 。 smallmoney およびreal タイプは採用されていません。
datetime およびuniqueidentifer 型は、自然な文字列形式から推測することはできません。 datetimeを取得するには またはuniqueidentifier パラメータタイプの場合、リテラル値はODBCエスケープ形式で指定する必要があります。例:{d '1901-01-01'} 、{ts '1900-01-01 12:34:56.790'} 、または{guid 'F85C72AB-15F7-49E9-A949-273C55A6C393'} 。それ以外の場合は、目的の日付またはUUIDリテラルが文字列として入力されます。 datetime以外の日付と時刻のタイプ 使用されていません。
一般的な文字列およびバイナリリテラルは、varchar(8000)として入力されます。 、nvarchar(4000) 、またはvarbinary(8000) 必要に応じて、リテラルが8000バイトを超えない限り、その場合はmax バリアントが使用されます。このスキームは、特定の長さを使用することによって生じるキャッシュの汚染と低レベルの再利用を回避するのに役立ちます。
CASTを使用することはできません またはCONVERT このシリーズの後半で詳しく説明する理由で、パラメータのデータ型を設定します。次のセクションにこの例があります。
強制的なパラメータ化については説明しません このシリーズでは、データ型推論のルールについて言及したいと思います。その場合、単純なパラメーター化と比較していくつかの重要な違いがあります。 。強制的なパラメーター化はSQLServer2005まで追加されなかったため、Microsoftは単純なパラメーター化からいくつかの教訓を取り入れることができました。 経験があり、下位互換性の問題についてあまり心配する必要はありませんでした。
小数点付きの数値およびintegerの範囲を超える整数の場合 、推論された型ルールは、プランの再利用とキャッシュの汚染に関して特別な問題を提示します。
小数を使用した次のクエリについて考えてみます。
ALTER DATABASE SCOPED CONFIGURATION
CLEAR PROCEDURE_CACHE;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
SomeValue decimal(19,8) NOT NULL
);
GO
SELECT
T.SomeValue
FROM dbo.Test AS T
WHERE
T.SomeValue >= 987.65432
AND T.SomeValue < 123456.789;
このクエリは、単純なパラメータ化の対象となります 。 SQL Serverは、提供された値を含めることができるパラメーターに対して最小の精度とスケールを選択します。これは、numeric(8,5)を選択することを意味します 987.65432の場合 およびnumeric(9,3) 123456.789の場合 :
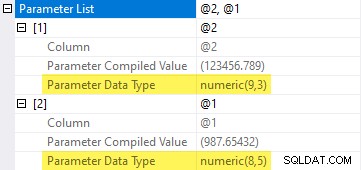
これらの推測されたタイプは、decimal(19,8)と一致しません 列のタイプであるため、パラメータ周辺の変換が実行プランに表示されます:
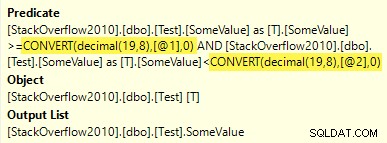
これらの変換は、この特定の場合の実行時のわずかな非効率を表すだけです。他の状況では、列のデータ型とパラメーターの推定型の不一致により、インデックスシークが妨げられたり、SQLServerが動的シークを作成するために追加の作業を行う必要が生じたりする場合があります。
結果の実行プランが妥当であると思われる場合でも、カーディナリティ推定に対するタイプの不一致の影響により、タイプの不一致がプランの品質に影響を与える可能性があります。一致するデータ型を使用し、式から派生した型に注意を払うことが常に最善です。
現在のプランの主な問題は、キャッシュされたプランのマッチングに影響を与える特定の推測されたタイプであり、したがって再利用されます。同じ一般的な形式のクエリをさらにいくつか実行してみましょう:
SELECT
T.SomeValue
FROM dbo.Test AS T
WHERE
T.SomeValue >= 98.76
AND T.SomeValue < 123.4567;
GO
SELECT
T.SomeValue
FROM dbo.Test AS T
WHERE
T.SomeValue >= 1.2
AND T.SomeValue < 1234.56789;
GO 次に、プランキャッシュを確認します。
SELECT
CP.usecounts,
CP.objtype,
ST.[text]
FROM sys.dm_exec_cached_plans AS CP
CROSS APPLY sys.dm_exec_sql_text (CP.plan_handle) AS ST
WHERE
ST.[text] NOT LIKE '%dm_exec_cached_plans%'
AND ST.[text] LIKE '%SomeValue%Test%'
ORDER BY
CP.objtype ASC; AdHocが表示されます および準備済み 送信した各クエリのステートメント:
 個別のプリペアドステートメント
個別のプリペアドステートメント
パラメータ化されたテキストは同じですが、パラメータのデータ型が異なるため、個別のプランがキャッシュされ、プランの再利用は行われません。
スケールまたは精度のさまざまな組み合わせでクエリを送信し続ける場合は、新しい準備済み プランは毎回作成され、キャッシュされます。各パラメータの推定タイプは列のデータ型によって制限されないため、送信された数値リテラルによっては、キャッシュされたプランの数が膨大になる可能性があることに注意してください。 numeric(1,0)からの組み合わせの数 numeric(38,38)へ 複数のパラメータについて考える前に、すでに大きいです。
この問題は、明示的なパラメータ化を使用する場合には発生しません。理想的には、パラメータが比較される列と同じデータ型を選択します。
ALTER DATABASE SCOPED CONFIGURATION
CLEAR PROCEDURE_CACHE;
GO
DECLARE
@stmt nvarchar(4000) =
N'SELECT T.SomeValue FROM dbo.Test AS T WHERE T.SomeValue >= @P1 AND T.SomeValue < @P2;',
@params nvarchar(4000) =
N'@P1 numeric(19,8), @P2 numeric(19,8)';
EXECUTE sys.sp_executesql
@stmt,
@params,
@P1 = 987.65432,
@P2 = 123456.789;
EXECUTE sys.sp_executesql
@stmt,
@params,
@P1 = 98.76,
@P2 = 123.4567;
EXECUTE sys.sp_executesql
@stmt,
@params,
@P1 = 1.2,
@P2 = 1234.56789; 明示的なパラメーター化を使用すると、プランキャッシュクエリには、キャッシュされ、3回使用され、型変換が不要な1つのプランのみが表示されます。
 明示的なパラメーター化
明示的なパラメーター化
最後に、decimalを使用しました およびnumeric このセクションでは同じ意味で。それらは技術的に 同義語であり、同等に動作することが文書化されていますが、さまざまなタイプ。これは通常の場合ですが、常にそうであるとは限りません:
-- Raises error 8120: -- Column 'dbo.Test.SomeValue' is invalid in the select list -- because it is not contained in either an aggregate function -- or the GROUP BY clause. SELECT CONVERT(decimal(19,8), T.SomeValue) FROM dbo.Test AS T GROUP BY CONVERT(numeric(19,8), T.SomeValue);
これはおそらく小さなパーサーのバグですが、一貫性を保つことにはメリットがあります(記事を書いていて、興味深い例外を指摘したい場合を除きます)。
ドキュメントに記載されている例に基づいて、もう1つ対処したいエッジケースがありますが、もう少し詳しく(そしておそらく正確に):
-- The dbo.LinkTypes table contains two rows -- Uses simple parameterization SELECT r = CONVERT(float, 1./ 7) FROM dbo.LinkTypes AS LT; -- No simple parameterization due to -- constant-constant comparison SELECT r = CONVERT(float, 1./ 7) FROM dbo.LinkTypes AS LT WHERE 1 = 1;
文書化されているように、結果は異なります:
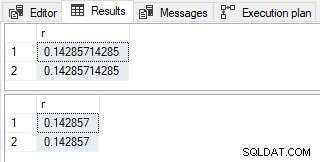
単純なパラメータ化の場合 発生すると、SQLServerは両方のリテラル値をパラメーター化します。 1. 値はnumeric(1,0)として入力されます 予想通り。やや一貫性がない、7 integerと入力されます (tinyintではありません )。型推論のルールは、さまざまなチームによって時間の経過とともに構築されてきました。レガシーコードの破損を回避するための動作が維持されます。
次のステップには、/が含まれます 算術演算子。 SQL Serverは、分割を実行する前に互換性のあるタイプを必要とします。与えられたnumeric (decimal )は、integerよりも高いデータ型の優先順位を持っています 、integer numericに変換されます 。
SQL Serverは、integerを暗黙的に変換する必要があります numericへ 。しかし、どの精度とスケールを使用するのでしょうか?答えは、SQL Serverが他の状況で行うように、元のリテラルに基づくことができますが、常にnumeric(10)を使用します。 ここ。
numeric(1,0)を除算した結果のデータ型 numeric(10,0)による 別のによって決定されます 精度、スケール、および長さに関するドキュメントに記載されている一連のルール。結果の精度とスケールの数式に数値を代入すると、次のようになります。
- 結果の精度:
- p1 – s1 + s2 + max(6、s1 + p2 + 1)
- =1 – 0 + 0 + max(6、0 + 10 + 1)
- =1 + max(6、11)
- =1 + 11
- = 12
- 結果スケール:
- max(6、s1 + p2 + 1)
- =max(6、0 + 10 + 1)
- =max(6、11)
- = 11
1. / 7 したがって、numeric(12, 11) 。次に、この値はfloatに変換されます 要求に応じて、0.14285714285として表示されます (小数点以下11桁)
単純なパラメータ化が実行されていない場合、1. リテラルはnumeric(1,0)と入力されます 従来通り。 7 最初はintegerと入力されます また、前に見たように。主な違いはinteger numeric(1,0)に変換されます 、したがって、除算演算子には、操作する一般的なタイプがあります。これは、値7を含めることができる最小の精度とスケールです。 。使用される単純なパラメーター化を覚えておいてくださいnumeric(10,0) ここ。
numeric(1,0)を除算するための精度とスケールの数式 numeric(1,0)による 結果のデータ型をnumeric(7,6)にします :
- 結果の精度:
- p1 – s1 + s2 + max(6、s1 + p2 + 1)
- =1 – 0 + 0 + max(6、0 + 1 + 1)
- =1 + max(6、2)
- =1 + 6
- = 7
- 結果スケール:
- max(6、s1 + p2 + 1)
- =max(6、0 + 1 + 1)
- =max(6、2)
- = 6
floatへの最終変換後 、表示される結果は0.142857です。 (小数点以下6桁)
したがって、結果で観察された違いは、暫定的なタイプの派生(numeric(12,11))によるものです。 対numeric(7,6) )floatへの最終的な変換ではなく 。
さらに証拠が必要な場合は、floatへの変換 責任を負いません。次のことを考慮してください。
-- Simple parameterization SELECT r = CONVERT(decimal(13,12), 1. / 7) FROM dbo.LinkTypes AS LT; -- No simple parameterization SELECT r = CONVERT(decimal(13,12), 1. / 7) FROM dbo.LinkTypes AS LT OPTION (MAXDOP 1);
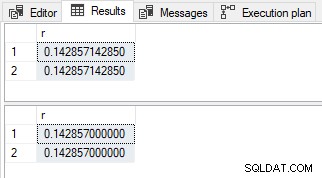 小数の結果
小数の結果
結果は、以前と同様に値とスケールが異なります。
このセクションでは、単純なパラメータ化によるデータ型の推論と変換のすべての癖について説明しているわけではありません。 どうにかして。前に述べたように、可能な限り、既知のデータ型で明示的なパラメータを使用することをお勧めします。
このシリーズの次のパートでは、単純なパラメータ化について説明します。 実行計画に影響します。