最近、友人のErlandSommarskogから新しい島のチャレンジを紹介されました。これは、公開データベースフォーラムからの質問に基づいています。主にウィンドウ関数を使用するよく知られた手法を使用する場合、課題自体の処理は複雑ではありません。ただし、これらの手法では、サポートインデックスが存在するにもかかわらず、明示的な並べ替えが必要です。これは、ソリューションのスケーラビリティと応答時間に影響します。課題が好きで、私は計画内の明示的な並べ替え演算子の数を最小限に抑える、またはさらに良いことに、それらの必要性を完全に排除するための解決策を見つけることに着手しました。そして、私はそのような解決策を見つけました。
まず、チャレンジの一般化された形式を提示します。次に、既知の手法に基づく2つのソリューションを示し、次に新しいソリューションを示します。最後に、さまざまなソリューションのパフォーマンスを比較します。
鉱山を実装する前に解決策を見つけることをお勧めします。
課題
アーランドの元々の島々の挑戦の一般化された形を提示します。
次のコードを使用して、T1というテーブルを作成し、サンプルデータの小さなセットをそのテーブルに入力します。
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.T1
CREATE TABLE dbo.T1
(
grp VARCHAR(10) NOT NULL,
ord INT NOT NULL,
val VARCHAR(10) NOT NULL,
CONSTRAINT PK_T1 PRIMARY KEY(grp, ord)
);
GO
INSERT INTO dbo.T1(grp, ord, val) VALUES
('Group A', 1002, 'Y'),
('Group A', 1003, 'Y'),
('Group A', 1005, 'Y'),
('Group A', 1007, 'N'),
('Group A', 1011, 'N'),
('Group A', 1013, 'N'),
('Group A', 1017, 'Y'),
('Group A', 1019, 'Y'),
('Group A', 1023, 'N'),
('Group A', 1029, 'N'),
('Group B', 1001, 'X'),
('Group B', 1002, 'X'),
('Group B', 1003, 'Z'),
('Group B', 1005, 'Z'),
('Group B', 1008, 'Z'),
('Group B', 1013, 'Z'),
('Group B', 1021, 'Y'),
('Group B', 1034, 'Y'); 課題は次のとおりです。
列grpに基づくパーティション分割と、列ordに基づく順序付けを想定して、val列の同じ値を持つ行の各連続グループ内で1から始まる連続する行番号を計算します。以下は、特定のサンプルデータの小さなセットに対する望ましい結果です。
grp ord val seqno -------- ----- ---- ------ Group A 1002 Y 1 Group A 1003 Y 2 Group A 1005 Y 3 Group A 1007 N 1 Group A 1011 N 2 Group A 1013 N 3 Group A 1017 Y 1 Group A 1019 Y 2 Group A 1023 N 1 Group A 1029 N 2 Group B 1001 X 1 Group B 1002 X 2 Group B 1003 Z 1 Group B 1005 Z 2 Group B 1008 Z 3 Group B 1013 Z 4 Group B 1021 Y 1 Group B 1034 Y 2
複合キー(grp、ord)に基づく主キー制約の定義に注意してください。これにより、同じキーに基づくクラスター化インデックスが作成されます。このインデックスは、grpで分割され、ordで並べ替えられたウィンドウ関数をサポートする可能性があります。
ソリューションのパフォーマンスをテストするには、テーブルに大量のサンプルデータを入力する必要があります。次のコードを使用して、ヘルパー関数GetNumsを作成します。
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO グループ数、グループあたりの行数、および個別の値の数を表すパラメーターを必要に応じて変更した後、次のコードを使用してT1にデータを入力します。
DECLARE
@numgroups AS INT = 1000,
@rowspergroup AS INT = 10000, -- test with 1000 to 10000 here
@uniquevalues AS INT = 5;
ALTER TABLE dbo.T1 DROP CONSTRAINT PK_T1;
TRUNCATE TABLE dbo.T1;
INSERT INTO dbo.T1 WITH(TABLOCK) (grp, ord, val)
SELECT
CAST(G.n AS VARCHAR(10)) AS grp,
CAST(R.n AS INT) AS ord,
CAST(ABS(CHECKSUM(NEWID())) % @uniquevalues + 1 AS VARCHAR(10)) AS val
FROM dbo.GetNums(1, @numgroups) AS G
CROSS JOIN dbo.GetNums(1, @rowspergroup) AS R;
ALTER TABLE dbo.T1 ADD CONSTRAINT PK_T1 PRIMARY KEY CLUSTERED(grp, ord);
パフォーマンステストでは、テーブルに1,000のグループ、グループごとに1,000〜10,000行(つまり、1M〜1,000万行)、および5つの異なる値を入力しました。 SELECT INTOを使用しました 結果を一時テーブルに書き込むステートメント。
私のテストマシンには4つの論理CPUがあり、SQL Server2019Enterpriseを実行しています。
行ストアでバッチモードをサポートするように設計された環境を使用していると仮定します。たとえば、私のようなSQL Server 2019 Enterpriseエディションを使用するか、テーブルにダミーの列ストアインデックスを作成することで間接的に使用します。
計画で明示的に並べ替えることなく効率的な解決策を考え出すことができた場合は、追加のポイントを覚えておいてください。頑張ってください!
ウィンドウ関数の最適化にソート演算子は必要ですか?
ソリューションについて説明する前に、最適化の背景について少し説明します。これにより、後でクエリプランに表示される内容がよりわかりやすくなります。
私たちのような島のタスクを解決するための最も一般的な手法は、集約および/またはランク付けウィンドウ関数のいくつかの組み合わせを使用することを含みます。 SQL Serverは、一連の古い行モード演算子(Segment、Sequence Project、Segment、Window Spool、Stream Aggregate)、または新しい、通常はより効率的なバッチモードのWindow Aggregate演算子を使用して、このようなウィンドウ関数を処理できます。
どちらの場合も、ウィンドウ関数の計算を処理するオペレーターは、ウィンドウのパーティション分割要素と順序付け要素によって順序付けられたデータを取り込む必要があります。サポートするインデックスがない場合は、当然、SQLServerはプランにSort演算子を導入する必要があります。たとえば、ソリューションに複数のウィンドウ関数があり、パーティション分割と順序付けの一意の組み合わせが複数ある場合は、プランで明示的な並べ替えを行う必要があります。しかし、パーティショニングと順序付けの一意の組み合わせとサポートインデックスが1つしかない場合はどうなりますか?
古い行モードの方法では、シリアルモードとパラレルモードの両方で明示的な並べ替え演算子を必要とせずに、インデックスから取り込まれた事前に順序付けられたデータに依存できます。新しいバッチモード演算子は、古い行モード最適化の非効率性の多くを排除し、バッチモード処理の固有の利点を備えています。ただし、現在の並列実装では、サポートインデックスが存在する場合でも、中間バッチモードの並列ソート演算子が必要です。そのシリアル実装のみが、Sort演算子なしでインデックスの順序に依存できます。これは、オプティマイザがウィンドウ関数を処理するための戦略を選択する必要がある場合、サポートするインデックスがあると仮定すると、通常、次の4つのオプションのいずれかになります。
- 行モード、シリアル、並べ替えなし
- 行モード、並列、並べ替えなし
- バッチモード、シリアル、並べ替えなし
- バッチモード、並列、並べ替え
もちろん、並列処理とバッチモードの前提条件が満たされていると仮定して、計画コストが最も低くなる方が選択されます。通常、オプティマイザーが並列プランを正当化するには、並列処理の利点がスレッド同期などの余分な作業を上回る必要があります。上記のオプション4では、並列処理の利点は、並列処理に関連する通常の追加作業に加えて、追加の並べ替えを上回る必要があります。
私たちの課題に対するさまざまな解決策を試しているときに、オプティマイザーが上記のオプション2を選択した場合がありました。行モード方式にはいくつかの非効率性が伴うという事実にもかかわらず、並列処理とソートなしの利点により、代替案よりも低コストの計画が得られたため、これを選択しました。これらのケースのいくつかでは、ヒントを使用してシリアルプランを強制すると、上記のオプション3が発生し、パフォーマンスが向上しました。
この背景を念頭に置いて、解決策を見てみましょう。計画での明示的な並べ替えを免れることができない島のタスクの既知の手法に依存する2つのソリューションから始めます。
既知の手法に基づくソリューション1
以下は、私たちの課題に対する最初の解決策です。これは、しばらくの間知られている手法に基づいています。
WITH C AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) -
ROW_NUMBER() OVER(PARTITION BY grp, val ORDER BY ord) AS island
FROM dbo.T1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, val, island ORDER BY ord) AS seqno
FROM C; これを既知のソリューション1と呼びます。
Cと呼ばれるCTEは、2つの行番号を計算するクエリに基づいています。最初の(これをrn1と呼びます)はgrpで分割され、ordで並べ替えられます。 2番目(これをrn2と呼びます)は、grpとvalで分割され、ordで並べ替えられます。 rn1には同じvalの異なるグループ間にギャップがあり、rn2にはギャップがないため、rn1とrn2(アイランドと呼ばれる列)の違いは、同じgrpおよびval値を持つすべての行の一意の定数値です。以下は、個別の列として返されない2行の数値計算の結果を含む、内部クエリの結果です。
grp ord val rn1 rn2 island -------- ----- ---- ---- ---- ------- Group A 1002 Y 1 1 0 Group A 1003 Y 2 2 0 Group A 1005 Y 3 3 0 Group A 1007 N 4 1 3 Group A 1011 N 5 2 3 Group A 1013 N 6 3 3 Group A 1017 Y 7 4 3 Group A 1019 Y 8 5 3 Group A 1023 N 9 4 5 Group A 1029 N 10 5 5 Group B 1001 X 1 1 0 Group B 1002 X 2 2 0 Group B 1003 Z 3 1 2 Group B 1005 Z 4 2 2 Group B 1008 Z 5 3 2 Group B 1013 Z 6 4 2 Group B 1021 Y 7 1 6 Group B 1034 Y 8 2 6
外側のクエリで行うべきことは、ROW_NUMBER関数を使用して結果列seqnoを計算し、grp、val、islandで分割し、ordで並べ替えて、目的の結果を生成することです。
上記の出力のように、同じパーティション内の異なるval値に対して同じアイランド値を取得できることに注意してください。これが、grpとislandだけではなく、grp、val、islandをウィンドウのパーティション要素として使用することが重要である理由です。
同様に、島ごとにデータをグループ化し、グループ集計を計算する必要がある島タスクを処理している場合は、行をgrp、val、および島ごとにグループ化します。しかし、これは私たちの挑戦には当てはまりません。ここでは、島ごとに独立して行番号を計算するだけのタスクがありました。
図1は、テーブルに1,000万行を入力した後、自分のマシンでこのソリューションに対して取得したデフォルトの計画です。
 図1:既知のソリューション1の並列計画
図1:既知のソリューション1の並列計画
rn1の計算は、インデックスの順序に依存できます。そのため、オプティマイザーは、これに対してソートなし+並列行モード戦略を選択しました(計画の最初のセグメントおよびシーケンスプロジェクトオペレーター)。 rn2とseqnoの両方の計算では、パーティション化要素と順序付け要素の独自の組み合わせが使用されるため、使用する戦略に関係なく、明示的な並べ替えは避けられません。そのため、オプティマイザーは両方にソート+並列バッチモード戦略を選択しました。この計画には、2つの明示的な並べ替え演算子が含まれます。
私のパフォーマンステストでは、このソリューションを完了するのに100万行に対して3.68秒、1000万行に対して43.1秒かかりました。
前述のように、シリアルプランを強制することによってもすべてのソリューションをテストしました(MAXDOP 1ヒントを使用)。このソリューションのシリアルプランを図1に示します。
 図2:既知のソリューション1のシリアルプラン
図2:既知のソリューション1のシリアルプラン
予想どおり、今回もrn1の計算では、先行するソート演算子なしでバッチモード戦略が使用されますが、プランには、後続の行番号計算用に2つのソート演算子があります。シリアルプランは、テストしたすべての入力サイズで、マシンのパラレルプランよりもパフォーマンスが悪く、100万行で4.54秒、10M行で61.5秒かかりました。
既知の手法2に基づくソリューション
ここで紹介する2番目のソリューションは、数年前にPaulWhiteから学んだ島の検出のための優れた手法に基づいています。以下は、この手法に基づく完全なソリューションコードです。
WITH C1 AS
(
SELECT *,
CASE
WHEN val = LAG(val) OVER(PARTITION BY grp ORDER BY ord) THEN 0
ELSE 1
END AS isstart
FROM dbo.T1
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS island
FROM C1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, island ORDER BY ord) AS seqno
FROM C2; このソリューションを既知のソリューション2と呼びます。
CTE C1計算を定義するクエリは、CASE式とLAGウィンドウ関数(grpで分割され、ordで順序付けられている)を使用して、isstartという結果列を計算します。この列の値は、現在のval値が前の値と同じ場合は0、それ以外の場合は1です。つまり、行が島の最初の場合は1、それ以外の場合は0です。
以下は、C1を定義するクエリの出力です:
grp ord val isstart -------- ----- ---- -------- Group A 1002 Y 1 Group A 1003 Y 0 Group A 1005 Y 0 Group A 1007 N 1 Group A 1011 N 0 Group A 1013 N 0 Group A 1017 Y 1 Group A 1019 Y 0 Group A 1023 N 1 Group A 1029 N 0 Group B 1001 X 1 Group B 1002 X 0 Group B 1003 Z 1 Group B 1005 Z 0 Group B 1008 Z 0 Group B 1013 Z 0 Group B 1021 Y 1 Group B 1034 Y 0
島の検出に関する限り、魔法はCTEC2で発生します。それを定義するクエリは、isstart列に適用されたSUMウィンドウ関数(これもgrpによって分割され、ordによって順序付けられます)を使用してアイランド識別子を計算します。アイランド識別子を持つ結果列は、アイランドと呼ばれます。各パーティション内で、最初の島に1つ、2番目の島に2つ、というように続きます。したがって、列grpとislandの組み合わせは島の識別子であり、関連する場合は島ごとのグループ化を含む島のタスクで使用できます。
以下は、C2を定義するクエリの出力です。
grp ord val isstart island -------- ----- ---- -------- ------- Group A 1002 Y 1 1 Group A 1003 Y 0 1 Group A 1005 Y 0 1 Group A 1007 N 1 2 Group A 1011 N 0 2 Group A 1013 N 0 2 Group A 1017 Y 1 3 Group A 1019 Y 0 3 Group A 1023 N 1 4 Group A 1029 N 0 4 Group B 1001 X 1 1 Group B 1002 X 0 1 Group B 1003 Z 1 2 Group B 1005 Z 0 2 Group B 1008 Z 0 2 Group B 1013 Z 0 2 Group B 1021 Y 1 3 Group B 1034 Y 0 3
最後に、外部クエリは、ROW_NUMBER関数を使用して目的の結果列seqnoを計算し、grpとislandで分割し、ordで並べ替えます。要素の分割と順序付けのこの組み合わせは、前のウィンドウ関数で使用されていたものとは異なることに注意してください。最初の2つのウィンドウ関数の計算はインデックスの順序に依存する可能性がありますが、最後の関数は依存できません。
図3は、このソリューションで得たデフォルトの計画です。
 図3:既知のソリューション2の並列計画
図3:既知のソリューション2の並列計画
計画からわかるように、最初の2つのウィンドウ関数の計算では、並べ替えなし+並列行モードの戦略が使用され、最後の関数の計算では、並べ替え+並列バッチモードの戦略が使用されます。
このソリューションで得た実行時間は、100万行に対して2.57秒から、1000万行に対して46.2秒の範囲でした。
シリアル処理を強制すると、図4に示す計画が得られました。
 図4:既知のソリューション2のシリアルプラン
図4:既知のソリューション2のシリアルプラン
予想どおり、今回はすべてのウィンドウ関数の計算がバッチモード戦略に依存しています。最初の2つは並べ替えの前になく、最後の2つは並べ替えありです。並列プランとシリアルプランの両方に、1つの明示的なソート演算子が含まれていました。シリアルプランは、テストした入力サイズのマシンでのパラレルプランよりもパフォーマンスが優れていました。強制シリアルプランで取得した実行時間は、100万行に対して1.75秒から、1000万行に対して21.7秒の範囲でした。
新しい技術に基づく解決策
アーランドがプライベートフォーラムでこの課題を紹介したとき、人々は明示的な並べ替えなしで計画で最適化されたクエリでそれを解決する可能性に懐疑的でした。やる気を起こさせるために聞く必要があるのはそれだけです。だから、これが私が思いついたものです:
WITH C1 AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) AS rn,
LAG(val) OVER(PARTITION BY grp ORDER BY ord) AS prev
FROM dbo.T1
),
C2 AS
(
SELECT *,
MAX(CASE WHEN val = prev THEN NULL ELSE rn END)
OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS firstrn
FROM C1
)
SELECT grp, ord, val, rn - firstrn + 1 AS seqno
FROM C2; このソリューションは、LAG、ROW_NUMBER、MAXの3つのウィンドウ関数を使用します。ここで重要なのは、3つすべてがgrpのパーティション分割と順序付けに基づいており、サポートするインデックスキーの順序と一致していることです。
CTE C1を定義するクエリは、ROW_NUMBER関数を使用して行番号(rn列)を計算し、LAG関数を使用して前のval値(前の列)を返します。
C1を定義するクエリの出力は次のとおりです:
grp ord val rn prev -------- ----- ---- --- ----- Group A 1002 Y 1 NULL Group A 1003 Y 2 Y Group A 1005 Y 3 Y Group A 1007 N 4 Y Group A 1011 N 5 N Group A 1013 N 6 N Group A 1017 Y 7 N Group A 1019 Y 8 Y Group A 1023 N 9 Y Group A 1029 N 10 N Group B 1001 X 1 NULL Group B 1002 X 2 X Group B 1003 Z 3 X Group B 1005 Z 4 Z Group B 1008 Z 5 Z Group B 1013 Z 6 Z Group B 1021 Y 7 Z Group B 1034 Y 8 Y
valとprevが同じ場合は、島の最初の行ではないことに注意してください。そうでない場合は、そうではありません。
このロジックに基づいて、CTE C2を定義するクエリは、行がアイランドの最初の場合はrnを返し、それ以外の場合はNULLを返すCASE式を使用します。次に、コードはMAXウィンドウ関数をCASE式の結果に適用し、島の最初のrn(最初の列)を返します。
CASE式の出力を含む、C2を定義するクエリの出力は次のとおりです。
grp ord val rn prev CASE firstrn -------- ----- ---- --- ----- ----- -------- Group A 1002 Y 1 NULL 1 1 Group A 1003 Y 2 Y NULL 1 Group A 1005 Y 3 Y NULL 1 Group A 1007 N 4 Y 4 4 Group A 1011 N 5 N NULL 4 Group A 1013 N 6 N NULL 4 Group A 1017 Y 7 N 7 7 Group A 1019 Y 8 Y NULL 7 Group A 1023 N 9 Y 9 9 Group A 1029 N 10 N NULL 9 Group B 1001 X 1 NULL 1 1 Group B 1002 X 2 X NULL 1 Group B 1003 Z 3 X 3 3 Group B 1005 Z 4 Z NULL 3 Group B 1008 Z 5 Z NULL 3 Group B 1013 Z 6 Z NULL 3 Group B 1021 Y 7 Z 7 7 Group B 1034 Y 8 Y NULL 7
外側のクエリに残されているのは、目的の結果列seqnoをrnマイナスfirstrnプラス1として計算することです。
図5は、SELECT INTOステートメントを使用してテストし、結果を一時テーブルに書き込んだときに、このソリューションに対して取得したデフォルトの並列プランを示しています。
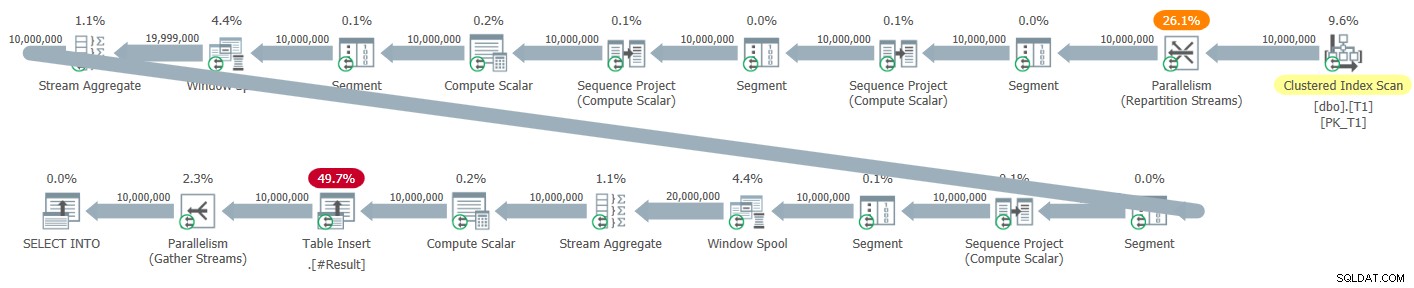 図5:新しいソリューションの並行計画
図5:新しいソリューションの並行計画
このプランには明示的なソート演算子はありません。ただし、3つのウィンドウ関数はすべて、並べ替えなし+並列行モード戦略を使用して計算されるため、バッチ処理の利点が失われています。並列プランでこのソリューションで得た実行時間は、100万行に対して2.47秒、1000万行に対して41.4秒の範囲でした。
ここでは、特にマシンに多くのCPUが搭載されていない場合に、バッチ処理を使用したシリアルプランのパフォーマンスが大幅に向上する可能性が非常に高くなります。 4つの論理CPUを搭載したマシンに対してソリューションをテストしていることを思い出してください。図6は、シリアル処理を強制するときにこのソリューションで得た計画です。
 図6:新しいソリューションのシリアルプラン
図6:新しいソリューションのシリアルプラン
3つのウィンドウ関数はすべて、ソートなし+シリアルバッチモード戦略を使用します。そして、その結果は非常に印象的です。このソリューションの実行時間は、100万行に対して0.5秒、1000万行に対して5.49秒の範囲でした。このソリューションについても興味深いのは、SELECT INTOステートメントではなく通常のSELECTステートメント(結果は破棄される)としてテストする場合、SQLServerはデフォルトでシリアルプランを選択したことです。他の2つのソリューションでは、デフォルトでSELECTとSELECTINTOの両方で並列プランを取得しました。
完全なパフォーマンステストの結果については、次のセクションを参照してください。
パフォーマンスの比較
3つのソリューションをテストするために使用したコードは次のとおりです。もちろん、シリアルプランをテストするためのMAXDOP1ヒントのコメントを外します。
-- Test Known Solution 1
DROP TABLE IF EXISTS #Result;
WITH C AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) -
ROW_NUMBER() OVER(PARTITION BY grp, val ORDER BY ord) AS island
FROM dbo.T1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, val, island ORDER BY ord) AS seqno
INTO #Result
FROM C
/* OPTION(MAXDOP 1) */; -- uncomment for serial test
GO
-- Test Known Solution 2
DROP TABLE IF EXISTS #Result;
WITH C1 AS
(
SELECT *,
CASE
WHEN val = LAG(val) OVER(PARTITION BY grp ORDER BY ord) THEN 0
ELSE 1
END AS isstart
FROM dbo.T1
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS island
FROM C1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, island ORDER BY ord) AS seqno
INTO #Result
FROM C2
/* OPTION(MAXDOP 1) */;
GO
-- Test New Solution
DROP TABLE IF EXISTS #Result;
WITH C1 AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) AS rn,
LAG(val) OVER(PARTITION BY grp ORDER BY ord) AS prev
FROM dbo.T1
),
C2 AS
(
SELECT *,
MAX(CASE WHEN val = prev THEN NULL ELSE rn END)
OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS firstrn
FROM C1
)
SELECT grp, ord, val, rn - firstrn + 1 AS seqno
INTO #Result
FROM C2
/* OPTION(MAXDOP 1) */; 図7は、さまざまな入力サイズに対するすべてのソリューションの並列プランと直列プランの両方の実行時間を示しています。
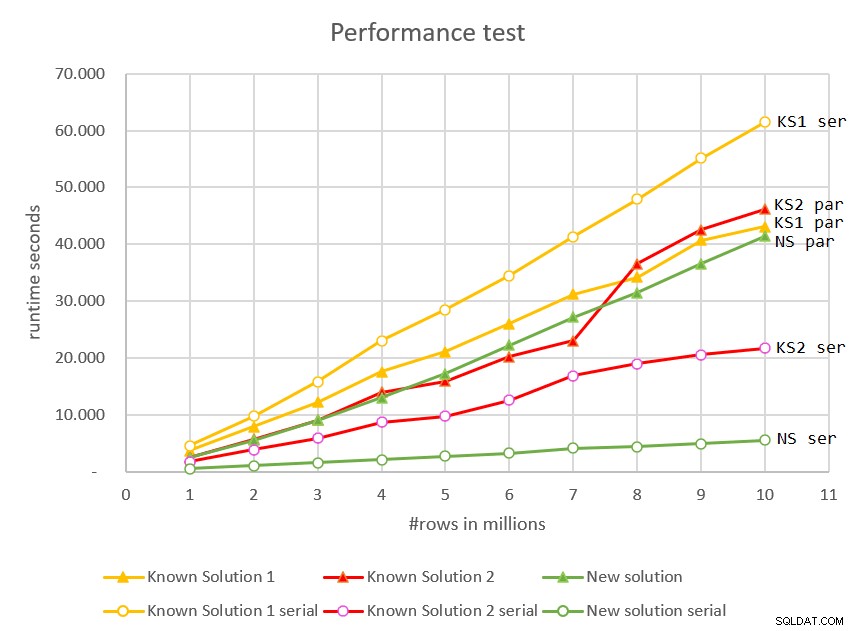 図7:パフォーマンスの比較
図7:パフォーマンスの比較
シリアルモードを使用する新しいソリューションは、明らかに勝者です。優れたパフォーマンス、線形スケーリング、および即時応答時間を備えています。
結論
島のタスクは、実際の生活では非常に一般的です。それらの多くは、島の識別と島ごとのデータのグループ化の両方を伴います。この記事の焦点となったアーランドの島々の課題は、グループ化を伴わず、代わりに各島の行を行番号で順序付けするため、もう少しユニークです。
島を特定するための既知の手法に基づいた2つのソリューションを紹介しました。両方の問題は、明示的な並べ替えを含む計画が作成されることです。これは、ソリューションのパフォーマンス、スケーラビリティ、および応答時間に悪影響を及ぼします。また、ソートをまったく行わないプランを実現する新しい手法も紹介しました。ソートなし+シリアルバッチモード戦略を使用するこのソリューションのシリアルプランは、優れたパフォーマンス、線形スケーリング、および即時応答時間を備えています。残念ながら、少なくとも今のところ、ウィンドウ関数を処理するためのソートなし+並列バッチモード戦略はありません。