この記事では、需要と供給を一致させるための解決策を引き続き模索します。ソリューションを送信してくれたLuca、Kamil Kosno、Daniel Brown、Brian Walker、Joe Obbish、Rainer Hoffmann、Paul White、Charlie、Ian、PeterLarssonに感謝します。
先月、従来のアプローチと比較して修正されたインターバル交差点アプローチに基づくソリューションについて説明しました。これらのソリューションの中で最速のものは、カミル、ルカ、ダニエルのアイデアを組み合わせたものです。これは、2つのクエリをばらばらの引数可能な述語で統合しました。 400K行の入力に対してソリューションが完了するまでに1.34秒かかりました。従来のインターバル交差点アプローチに基づくソリューションが同じ入力に対して完了するのに931秒かかったことを考えると、これはそれほど粗雑ではありません。また、ジョーが古典的な間隔交差アプローチに依存するが、最大の間隔の長さに基づいて間隔をバケット化することによってマッチングロジックを最適化する優れたソリューションを思いついたことを思い出してください。同じ400K行の入力で、Joeのソリューションが完了するまでに0.9秒かかりました。このソリューションで注意が必要なのは、最大間隔の長さが長くなるとパフォーマンスが低下することです。
今月は、Kamil / Luca / Daniel Revised Intersectionsソリューションよりも高速で、区間の長さに中立な魅力的なソリューションを検討します。この記事のソリューションは、Brian Walker、Ian、Peter Larsson、Paul White、および私によって作成されました。
この記事のすべてのソリューションを、100K、200K、300K、および400K行で、次のインデックスを使用してオークション入力テーブルに対してテストしました。
-- Index to support solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Enable batch-mode Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
ソリューションの背後にあるロジックを説明するときは、オークションテーブルに次の小さなサンプルデータのセットが入力されていると仮定します。
ID Code Quantity ----------- ---- --------- 1 D 5.000000 2 D 3.000000 3 D 8.000000 5 D 2.000000 6 D 8.000000 7 D 4.000000 8 D 2.000000 1000 S 8.000000 2000 S 6.000000 3000 S 2.000000 4000 S 2.000000 5000 S 4.000000 6000 S 3.000000 7000 S 2.000000
このサンプルデータの望ましい結果は次のとおりです。
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
ブライアンウォーカーのソリューション
外部結合はSQLクエリソリューションでかなり一般的に使用されますが、これらを使用する場合は、片側結合を使用します。外部結合について教えるとき、完全な外部結合の実際の使用例の例を尋ねる質問をよく受けますが、それほど多くはありません。ブライアンのソリューションは、完全外部結合の実際の使用例の美しい例です。
ブライアンの完全なソリューションコードは次のとおりです。
DROP TABLE IF EXISTS #MyPairings;
CREATE TABLE #MyPairings
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19,06) NOT NULL
);
WITH D AS
(
SELECT A.ID,
SUM(A.Quantity) OVER (PARTITION BY A.Code
ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running
FROM dbo.Auctions AS A
WHERE A.Code = 'D'
),
S AS
(
SELECT A.ID,
SUM(A.Quantity) OVER (PARTITION BY A.Code
ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Running
FROM dbo.Auctions AS A
WHERE A.Code = 'S'
),
W AS
(
SELECT D.ID AS DemandID, S.ID AS SupplyID, ISNULL(D.Running, S.Running) AS Running
FROM D
FULL JOIN S
ON D.Running = S.Running
),
Z AS
(
SELECT
CASE
WHEN W.DemandID IS NOT NULL THEN W.DemandID
ELSE MIN(W.DemandID) OVER (ORDER BY W.Running
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
END AS DemandID,
CASE
WHEN W.SupplyID IS NOT NULL THEN W.SupplyID
ELSE MIN(W.SupplyID) OVER (ORDER BY W.Running
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING)
END AS SupplyID,
W.Running
FROM W
)
INSERT #MyPairings( DemandID, SupplyID, TradeQuantity )
SELECT Z.DemandID, Z.SupplyID,
Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) AS TradeQuantity
FROM Z
WHERE Z.DemandID IS NOT NULL
AND Z.SupplyID IS NOT NULL; わかりやすくするために、CTEを使用した派生テーブルのブライアンの元々の使用法を改訂しました。
CTE Dは、D.Runningと呼ばれる結果列で現在の総需要量を計算し、CTE Sは、S.Runningと呼ばれる結果列で現在の総供給量を計算します。次に、CTE Wは、D.RunningとS.Runningを照合して、DとSの間で完全外部結合を実行し、D.RunningとS.Runningの最初の非NULLをW.Runningとして返します。実行順にWからすべての行をクエリした場合に得られる結果は次のとおりです。
DemandID SupplyID Running ----------- ----------- ---------- 1 NULL 5.000000 2 1000 8.000000 NULL 2000 14.000000 3 3000 16.000000 5 4000 18.000000 NULL 5000 22.000000 NULL 6000 25.000000 6 NULL 26.000000 NULL 7000 27.000000 7 NULL 30.000000 8 NULL 32.000000
需要と供給の現在の合計を比較する述語に基づいて完全な外部結合を使用するというアイデアは、天才のストロークです!この結果のほとんどの行(この場合は最初の9行)は、少し余分な計算が欠落している結果のペアを表しています。いずれかの種類の末尾にNULLIDがある行は、一致できないエントリを表します。この場合、最後の2行は、供給エントリと一致できない需要エントリを表します。したがって、ここに残っているのは、結果のペアのDemandID、SupplyID、TradeQuantityを計算し、一致しないエントリを除外することです。
結果のDemandIDとSupplyIDを計算するロジックは、CTE Zで次のように実行されます(実行によるWでの順序付けを想定):
- DemandID:DemandIDがNULLでない場合はDemandID、それ以外の場合は現在の行から始まる最小のDemandID
- SupplyID:SupplyIDがNULLでない場合は、SupplyID、それ以外の場合は、現在の行から始まる最小のSupplyID
Zをクエリし、実行して行を並べ替えると、次のような結果が得られます。
DemandID SupplyID Running ----------- ----------- ---------- 1 1000 5.000000 2 1000 8.000000 3 2000 14.000000 3 3000 16.000000 5 4000 18.000000 6 5000 22.000000 6 6000 25.000000 6 7000 26.000000 7 7000 27.000000 7 NULL 30.000000 8 NULL 32.000000
外部クエリは、DemandIDとSupplyIDの両方がNULLでないことを確認することにより、他の種類のエントリと一致できない1つの種類のエントリを表すZから行を除外します。結果のペアリングの取引量は、LAG関数を使用して、現在のランニング値から前のランニング値を引いたものとして計算されます。
#MyPairingsテーブルに書き込まれる内容は次のとおりです。これは、望ましい結果です。
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
このソリューションの計画を図1に示します。
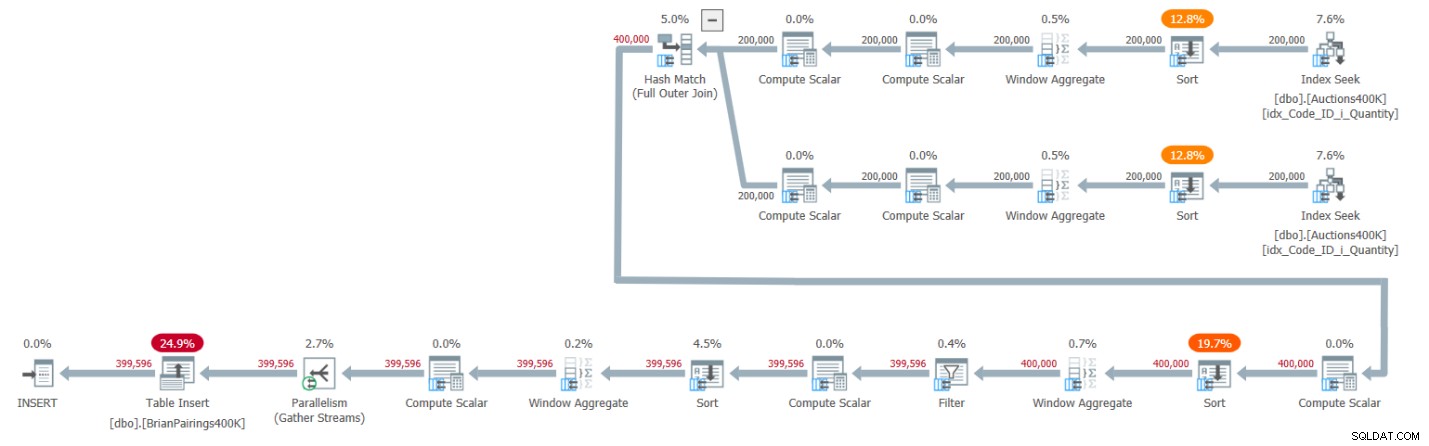 図1:ブライアンのソリューションのクエリプラン
図1:ブライアンのソリューションのクエリプラン
計画の上位2つのブランチは、それぞれがサポートインデックスからそれぞれのエントリを取得した後、バッチモードのWindowAggregate演算子を使用して需要と供給の現在の合計を計算します。シリーズの以前の記事で説明したように、インデックスにはすでにWindow Aggregate演算子が必要とするように順序付けられた行があるため、明示的なSort演算子は必要ないと思われます。ただし、SQL Serverは現在、並列バッチモードのWindow Aggregate演算子の前に、並列順序保持インデックス操作の効率的な組み合わせをサポートしていません。その結果、明示的な並列Sort演算子が各並列WindowAggregate演算子の前にあります。
このプランでは、バッチモードのハッシュ結合を使用して完全な外部結合を処理します。このプランでは、明示的な並べ替え演算子が前に付いた2つの追加のバッチモードウィンドウ集計演算子を使用して、MINおよびLAGウィンドウ関数を計算します。
これはかなり効率的な計画です!
100Kから400K行の範囲の入力サイズに対して、このソリューションで得られた実行時間(秒単位)は次のとおりです。
100K: 0.368 200K: 0.845 300K: 1.255 400K: 1.315
Itzikのソリューション
課題の次の解決策は、それを解決するための私の試みの1つです。完全なソリューションコードは次のとおりです。
DROP TABLE IF EXISTS #MyPairings;
WITH C1 AS
(
SELECT *,
SUM(Quantity)
OVER(PARTITION BY Code
ORDER BY ID
ROWS UNBOUNDED PRECEDING) AS SumQty
FROM dbo.Auctions
),
C2 AS
(
SELECT *,
SUM(Quantity * CASE Code WHEN 'D' THEN -1 WHEN 'S' THEN 1 END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS StockLevel,
LAG(SumQty, 1, 0.0) OVER(ORDER BY SumQty, Code) AS PrevSumQty,
MAX(CASE WHEN Code = 'D' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS PrevDemandID,
MAX(CASE WHEN Code = 'S' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS UNBOUNDED PRECEDING) AS PrevSupplyID,
MIN(CASE WHEN Code = 'D' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS NextDemandID,
MIN(CASE WHEN Code = 'S' THEN ID END)
OVER(ORDER BY SumQty, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS NextSupplyID
FROM C1
),
C3 AS
(
SELECT *,
CASE Code
WHEN 'D' THEN ID
WHEN 'S' THEN
CASE WHEN StockLevel > 0 THEN NextDemandID ELSE PrevDemandID END
END AS DemandID,
CASE Code
WHEN 'S' THEN ID
WHEN 'D' THEN
CASE WHEN StockLevel <= 0 THEN NextSupplyID ELSE PrevSupplyID END
END AS SupplyID,
SumQty - PrevSumQty AS TradeQuantity
FROM C2
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM C3
WHERE TradeQuantity > 0.0
AND DemandID IS NOT NULL
AND SupplyID IS NOT NULL; CTE C1はAuctionsテーブルにクエリを実行し、ウィンドウ関数を使用して現在の総需要と供給量を計算し、結果列SumQtyを呼び出します。
CTE C2はC1にクエリを実行し、SumQtyとコードの順序に基づくウィンドウ関数を使用していくつかの属性を計算します。
- StockLevel:各エントリを処理した後の現在の在庫レベル。これは、需要数量に負の符号を割り当て、供給数量に正の符号を割り当て、それらの数量を現在のエントリまで合計することによって計算されます。
- PrevSumQty:前の行のSumQty値。
- PrevDemandID:最後のNULL以外のデマンドID。
- PrevSupplyID:最後のNULL以外のサプライID。
- NextDemandID:次のNULL以外のデマンドID。
- NextSupplyID:次のNULL以外のサプライID。
SumQtyとCodeで並べ替えられたC2の内容は次のとおりです。
ID Code Quantity SumQty StockLevel PrevSumQty PrevDemandID PrevSupplyID NextDemandID NextSupplyID ----- ---- --------- ---------- ----------- ----------- ------------ ------------ ------------ ------------ 1 D 5.000000 5.000000 -5.000000 0.000000 1 NULL 1 1000 2 D 3.000000 8.000000 -8.000000 5.000000 2 NULL 2 1000 1000 S 8.000000 8.000000 0.000000 8.000000 2 1000 3 1000 2000 S 6.000000 14.000000 6.000000 8.000000 2 2000 3 2000 3 D 8.000000 16.000000 -2.000000 14.000000 3 2000 3 3000 3000 S 2.000000 16.000000 0.000000 16.000000 3 3000 5 3000 5 D 2.000000 18.000000 -2.000000 16.000000 5 3000 5 4000 4000 S 2.000000 18.000000 0.000000 18.000000 5 4000 6 4000 5000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 5000 6000 S 3.000000 25.000000 7.000000 22.000000 5 6000 6 6000 6 D 8.000000 26.000000 -1.000000 25.000000 6 6000 6 7000 7000 S 2.000000 27.000000 1.000000 26.000000 6 7000 7 7000 7 D 4.000000 30.000000 -3.000000 27.000000 7 7000 7 NULL 8 D 2.000000 32.000000 -5.000000 30.000000 8 7000 8 NULL
CTE C3はC2にクエリを実行し、結果のペアリングのDemandID、SupplyID、およびTradeQuantityを計算してから、余分な行を削除します。
結果のC3.DemandID列は次のように計算されます:
- 現在のエントリがデマンドエントリの場合は、DemandIDを返します。
- 現在のエントリが供給エントリであり、現在の在庫レベルが正の場合、NextDemandIDを返します。
- 現在のエントリが供給エントリであり、現在の在庫レベルが正でない場合は、PrevDemandIDを返します。
結果のC3.SupplyID列は次のように計算されます:
- 現在のエントリが供給エントリの場合は、SupplyIDを返します。
- 現在のエントリが需要エントリであり、現在の在庫レベルが正でない場合は、NextSupplyIDを返します。
- 現在のエントリが需要エントリであり、現在の在庫レベルが正の場合、PrevSupplyIDを返します。
結果のTradeQuantityは、現在の行のSumQtyからPrevSumQtyを引いたものとして計算されます。
C3の結果に関連する列の内容は次のとおりです。
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 2 1000 0.000000 3 2000 6.000000 3 3000 2.000000 3 3000 0.000000 5 4000 2.000000 5 4000 0.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 NULL 3.000000 8 NULL 2.000000
外部クエリに残されているのは、C3から余分な行を除外することです。これには2つのケースが含まれます:
- 両方の種類の累計が同じである場合、供給エントリの取引数量はゼロになります。順序はSumQtyとCodeに基づいているため、現在の合計が同じ場合、需要エントリが供給エントリの前に表示されることに注意してください。
- ある種類の末尾のエントリで、他の種類のエントリと一致させることはできません。このようなエントリは、DemandIDがNULLまたはSupplyIDがNULLであるC3の行で表されます。
このソリューションの計画を図2に示します。
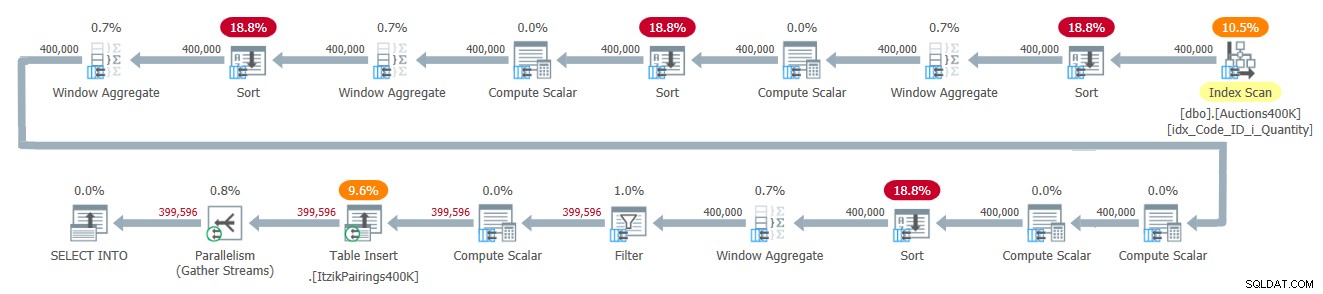 図2:Itzikのソリューションのクエリプラン
図2:Itzikのソリューションのクエリプラン
このプランでは、入力データに1つのパスを適用し、4つのバッチモードのWindow Aggregate演算子を使用して、さまざまなウィンドウ計算を処理します。ここでは避けられないのはそのうちの2つだけですが、すべてのWindowAggregate演算子の前に明示的なSort演算子があります。他の2つは、並列バッチモードのWindow Aggregate演算子の現在の実装と関係があり、並列順序保持入力に依存することはできません。この理由によるソート演算子を確認する簡単な方法は、シリアルプランを強制し、どのソート演算子が消えるかを確認することです。このソリューションでシリアルプランを強制すると、1番目と3番目の並べ替え演算子が消えます。
このソリューションで得た実行時間(秒単位)は次のとおりです。
100K: 0.246 200K: 0.427 300K: 0.616 400K: 0.841>
イアンのソリューション
イアンのソリューションは短く効率的です。完全なソリューションコードは次のとおりです。
DROP TABLE IF EXISTS #MyPairings;
WITH A AS (
SELECT *,
SUM(Quantity) OVER (PARTITION BY Code
ORDER BY ID
ROWS UNBOUNDED PRECEDING) AS CumulativeQuantity
FROM dbo.Auctions
), B AS (
SELECT CumulativeQuantity,
CumulativeQuantity
- LAG(CumulativeQuantity, 1, 0)
OVER (ORDER BY CumulativeQuantity) AS TradeQuantity,
MAX(CASE WHEN Code = 'D' THEN ID END) AS DemandID,
MAX(CASE WHEN Code = 'S' THEN ID END) AS SupplyID
FROM A
GROUP BY CumulativeQuantity, ID/ID -- bogus grouping to improve row estimate
-- (rows count of Auctions instead of 2 rows)
), C AS (
-- fill in NULLs with next supply / demand
-- FIRST_VALUE(ID) IGNORE NULLS OVER ...
-- would be better, but this will work because the IDs are in CumulativeQuantity order
SELECT
MIN(DemandID) OVER (ORDER BY CumulativeQuantity
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID,
MIN(SupplyID) OVER (ORDER BY CumulativeQuantity
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS SupplyID,
TradeQuantity
FROM B
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM C
WHERE SupplyID IS NOT NULL -- trim unfulfilled demands
AND DemandID IS NOT NULL; -- trim unused supplies CTE Aのコードは、Auctionsテーブルにクエリを実行し、ウィンドウ関数を使用して現在の総需要と供給量を計算し、結果列にCumulativeQuantityという名前を付けます。
CTEBのコードはCTEAにクエリを実行し、CumulativeQuantityによって行をグループ化します。このグループ化は、需要と供給の現在の合計に基づいて、ブライアンの外部結合と同様の効果を実現します。 Ianはまた、推定中のグループ化の元のカーディナリティを改善するために、ダミー式ID/IDをグループ化セットに追加しました。私のマシンでは、これにより、シリアルプランではなくパラレルプランが使用されるようになりました。
SELECTリストでは、コードは、MAX集計とCASE式を使用して、グループ内のそれぞれのエントリタイプのIDを取得することにより、DemandIDとSupplyIDを計算します。 IDがグループに存在しない場合、結果はNULLになります。このコードは、TradeQuantityという結果列を、LAGウィンドウ関数を使用して取得した現在の累積数量から前の累積数量を引いたものとして計算します。
Bの内容は次のとおりです。
CumulativeQuantity TradeQuantity DemandId SupplyId ------------------- -------------- --------- --------- 5.000000 5.000000 1 NULL 8.000000 3.000000 2 1000 14.000000 6.000000 NULL 2000 16.000000 2.000000 3 3000 18.000000 2.000000 5 4000 22.000000 4.000000 NULL 5000 25.000000 3.000000 NULL 6000 26.000000 1.000000 6 NULL 27.000000 1.000000 NULL 7000 30.000000 3.000000 7 NULL 32.000000 2.000000 8 NULL>
次に、CTECのコードはCTEBにクエリを実行し、現在の行とバインドされていないフォローの間のフレームROWSでMINウィンドウ関数を使用して、NULLの需要と供給IDに次の非NULLの需要と供給IDを入力します。
Cの内容は次のとおりです:
DemandID SupplyID TradeQuantity --------- --------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 NULL 3.000000 8 NULL 2.000000
Cに対する外部クエリによって処理される最後のステップは、他の種類のエントリと一致できない1つの種類のエントリを削除することです。これは、SupplyIDがNULLまたはDemandIDがNULLのいずれかの行を除外することによって行われます。
このソリューションの計画を図3に示します。
 図3:Ianのソリューションのクエリプラン
図3:Ianのソリューションのクエリプラン
このプランは、入力データの1回のスキャンを実行し、3つの並列バッチモードウィンドウ集計演算子を使用してさまざまなウィンドウ関数を計算します。これらはすべて、並列ソート演算子が前に付きます。シリアルプランを強制することで確認できるため、そのうちの2つは避けられません。この計画では、ハッシュ集計演算子を使用して、CTEBでのグループ化と集計も処理します。
このソリューションで得た実行時間(秒単位)は次のとおりです。
100K: 0.214 200K: 0.363 300K: 0.546 400K: 0.701
PeterLarssonのソリューション
Peter Larssonのソリューションは、驚くほど短く、甘く、非常に効率的です。 Peterの完全なソリューションコードは次のとおりです。
DROP TABLE IF EXISTS #MyPairings;
WITH cteSource(ID, Code, RunningQuantity)
AS
(
SELECT ID, Code,
SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID) AS RunningQuantity
FROM dbo.Auctions
)
SELECT DemandID, SupplyID, TradeQuantity
INTO #MyPairings
FROM (
SELECT
MIN(CASE WHEN Code = 'D' THEN ID ELSE 2147483648 END)
OVER (ORDER BY RunningQuantity, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS DemandID,
MIN(CASE WHEN Code = 'S' THEN ID ELSE 2147483648 END)
OVER (ORDER BY RunningQuantity, Code
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS SupplyID,
RunningQuantity
- COALESCE(LAG(RunningQuantity) OVER (ORDER BY RunningQuantity, Code), 0.0)
AS TradeQuantity
FROM cteSource
) AS d
WHERE DemandID < 2147483648
AND SupplyID < 2147483648
AND TradeQuantity > 0.0; CTE cteSourceはAuctionsテーブルにクエリを実行し、ウィンドウ関数を使用して現在の総需要と供給量を計算し、結果列RunningQuantityを呼び出します。
派生テーブルdを定義するコードは、cteSourceにクエリを実行し、結果のペアのDemandID、SupplyID、およびTradeQuantityを計算してから、余分な行を削除します。これらの計算で使用されるすべてのウィンドウ関数は、RunningQuantityとコードの順序に基づいています。
結果列d.DemandIDは、現在のIDから始まる最小需要IDとして計算されます。見つからない場合は、2147483648として計算されます。
結果列d.SupplyIDは、現在の供給IDから始まる最小供給IDとして計算され、見つからない場合は2147483648として計算されます。
結果のTradeQuantityは、現在の行のRunningQuantity値から前の行のRunningQuantity値を引いたものとして計算されます。
dの内容は次のとおりです:
DemandID SupplyID TradeQuantity --------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 1000 0.000000 3 2000 6.000000 3 3000 2.000000 5 3000 0.000000 5 4000 2.000000 6 4000 0.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000 7 2147483648 3.000000 8 2147483648 2.000000
外側のクエリに残されているのは、dから余分な行を除外することです。これらは、取引数量がゼロである場合、またはある種類のエントリが他の種類のエントリ(ID 2147483648)と一致しない場合です。
このソリューションの計画を図4に示します。
 図4:Peterのソリューションのクエリプラン
図4:Peterのソリューションのクエリプラン
Ianの計画と同様に、Peterの計画は、入力データの1回のスキャンに依存し、3つの並列バッチモードウィンドウ集計演算子を使用してさまざまなウィンドウ関数を計算します。すべての前に並列Sort演算子があります。シリアルプランを強制することで確認できるため、そのうちの2つは避けられません。 Peterの計画では、Ianの計画のようにグループ化された集計演算子は必要ありません。
このような短い解決策を可能にしたPeterの重要な洞察は、いずれかの種類の関連するエントリについて、もう一方の種類の一致するIDが常に後で表示されるという認識でした(RunningQuantityとコードの順序に基づく)。ピーターの解決策を見た後、私は自分の中で物事を複雑にしすぎたように感じました!
このソリューションで得た実行時間(秒単位)は次のとおりです。
100K: 0.197 200K: 0.412 300K: 0.558 400K: 0.696
ポールホワイトのソリューション
最後のソリューションはPaulWhiteによって作成されました。完全なソリューションコードは次のとおりです。
DROP TABLE IF EXISTS #MyPairings;
CREATE TABLE #MyPairings
(
DemandID integer NOT NULL,
SupplyID integer NOT NULL,
TradeQuantity decimal(19, 6) NOT NULL
);
GO
INSERT #MyPairings
WITH (TABLOCK)
(
DemandID,
SupplyID,
TradeQuantity
)
SELECT
Q3.DemandID,
Q3.SupplyID,
Q3.TradeQuantity
FROM
(
SELECT
Q2.DemandID,
Q2.SupplyID,
TradeQuantity =
-- Interval overlap
CASE
WHEN Q2.Code = 'S' THEN
CASE
WHEN Q2.CumDemand >= Q2.IntEnd THEN Q2.IntLength
WHEN Q2.CumDemand > Q2.IntStart THEN Q2.CumDemand - Q2.IntStart
ELSE 0.0
END
WHEN Q2.Code = 'D' THEN
CASE
WHEN Q2.CumSupply >= Q2.IntEnd THEN Q2.IntLength
WHEN Q2.CumSupply > Q2.IntStart THEN Q2.CumSupply - Q2.IntStart
ELSE 0.0
END
END
FROM
(
SELECT
Q1.Code,
Q1.IntStart,
Q1.IntEnd,
Q1.IntLength,
DemandID = MAX(IIF(Q1.Code = 'D', Q1.ID, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
SupplyID = MAX(IIF(Q1.Code = 'S', Q1.ID, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
CumSupply = SUM(IIF(Q1.Code = 'S', Q1.IntLength, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING),
CumDemand = SUM(IIF(Q1.Code = 'D', Q1.IntLength, 0)) OVER (
ORDER BY Q1.IntStart, Q1.ID
ROWS UNBOUNDED PRECEDING)
FROM
(
-- Demand intervals
SELECT
A.ID,
A.Code,
IntStart = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING) - A.Quantity,
IntEnd = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING),
IntLength = A.Quantity
FROM dbo.Auctions AS A
WHERE
A.Code = 'D'
UNION ALL
-- Supply intervals
SELECT
A.ID,
A.Code,
IntStart = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING) - A.Quantity,
IntEnd = SUM(A.Quantity) OVER (
ORDER BY A.ID
ROWS UNBOUNDED PRECEDING),
IntLength = A.Quantity
FROM dbo.Auctions AS A
WHERE
A.Code = 'S'
) AS Q1
) AS Q2
) AS Q3
WHERE
Q3.TradeQuantity > 0; 派生テーブルQ1を定義するコードは、2つの別々のクエリを使用して、現在の合計に基づいて需要と供給の間隔を計算し、2つを統合します。コードは、間隔ごとに、開始(IntStart)、終了(IntEnd)、および長さ(IntLength)を計算します。 IntStartとIDで並べ替えられたQ1の内容は次のとおりです。
ID Code IntStart IntEnd IntLength ----- ---- ---------- ---------- ---------- 1 D 0.000000 5.000000 5.000000 1000 S 0.000000 8.000000 8.000000 2 D 5.000000 8.000000 3.000000 3 D 8.000000 16.000000 8.000000 2000 S 8.000000 14.000000 6.000000 3000 S 14.000000 16.000000 2.000000 5 D 16.000000 18.000000 2.000000 4000 S 16.000000 18.000000 2.000000 6 D 18.000000 26.000000 8.000000 5000 S 18.000000 22.000000 4.000000 6000 S 22.000000 25.000000 3.000000 7000 S 25.000000 27.000000 2.000000 7 D 26.000000 30.000000 4.000000 8 D 30.000000 32.000000 2.000000
派生テーブルQ2を定義するコードはQ1を照会し、DemandID、SupplyID、CumSupply、およびCumDemandと呼ばれる結果列を計算します。このコードで使用されるすべてのウィンドウ関数は、IntStartとIDの順序、およびフレームROWS UNBOUNDED PRECEDING(現在までのすべての行)に基づいています。
DemandIDは、現在の行までの最大デマンドIDであり、存在しない場合は0です。
SupplyIDは、現在の行までの最大供給ID、または存在しない場合は0です。
CumSupplyは、現在の行までの累積供給量(供給間隔の長さ)です。
CumDemandは、現在の行までの累積需要量(需要間隔の長さ)です。
Q2の内容は次のとおりです。
Code IntStart IntEnd IntLength DemandID SupplyID CumSupply CumDemand ---- ---------- ---------- ---------- --------- --------- ---------- ---------- D 0.000000 5.000000 5.000000 1 0 0.000000 5.000000 S 0.000000 8.000000 8.000000 1 1000 8.000000 5.000000 D 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000 D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000 S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000 S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000 D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000 S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000 D 18.000000 26.000000 8.000000 6 4000 18.000000 26.000000 S 18.000000 22.000000 4.000000 6 5000 22.000000 26.000000 S 22.000000 25.000000 3.000000 6 6000 25.000000 26.000000 S 25.000000 27.000000 2.000000 6 7000 27.000000 26.000000 D 26.000000 30.000000 4.000000 7 7000 27.000000 30.000000 D 30.000000 32.000000 2.000000 8 7000 27.000000 32.000000
Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
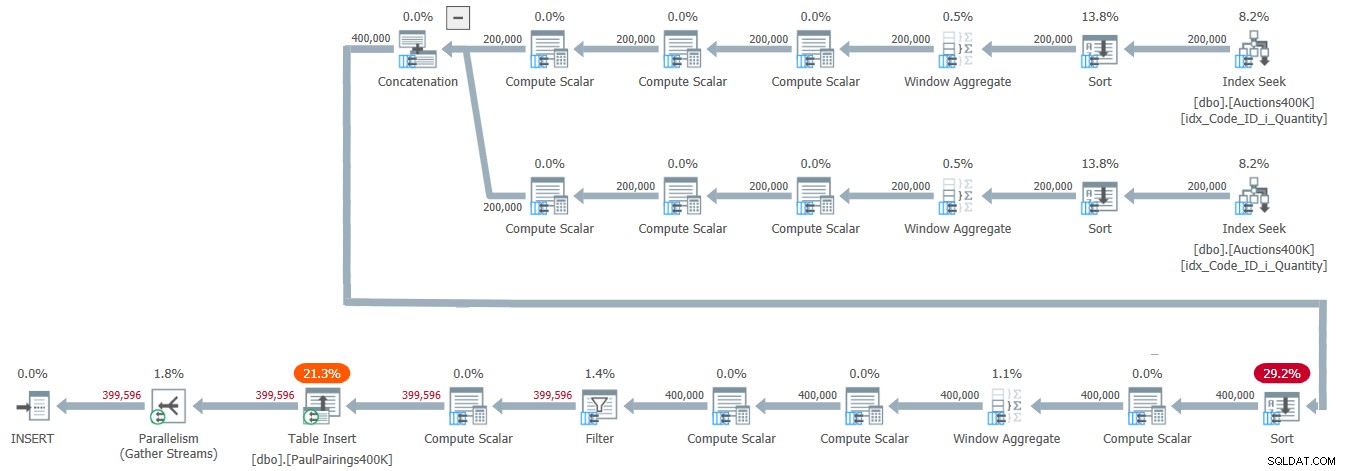 Figure 5:Query plan for Paul’s solution
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K: 0.187 200K: 0.331 300K: 0.369 400K: 0.425
These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
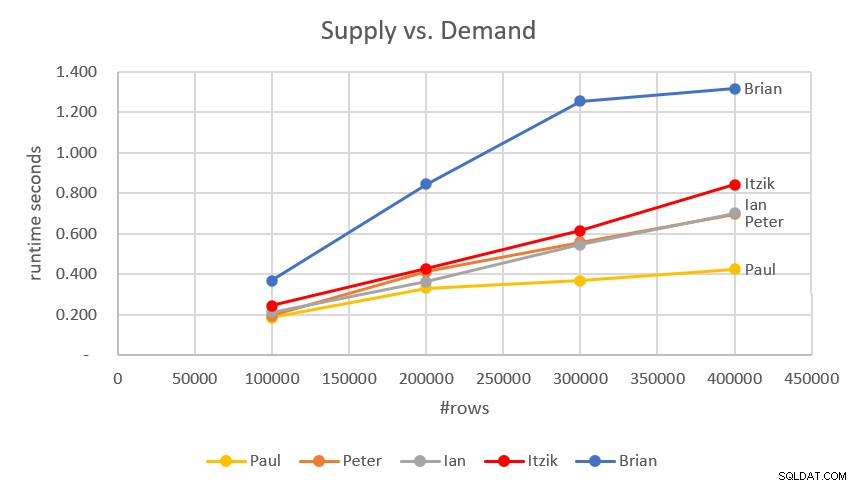 Figure 6:Performance comparison
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
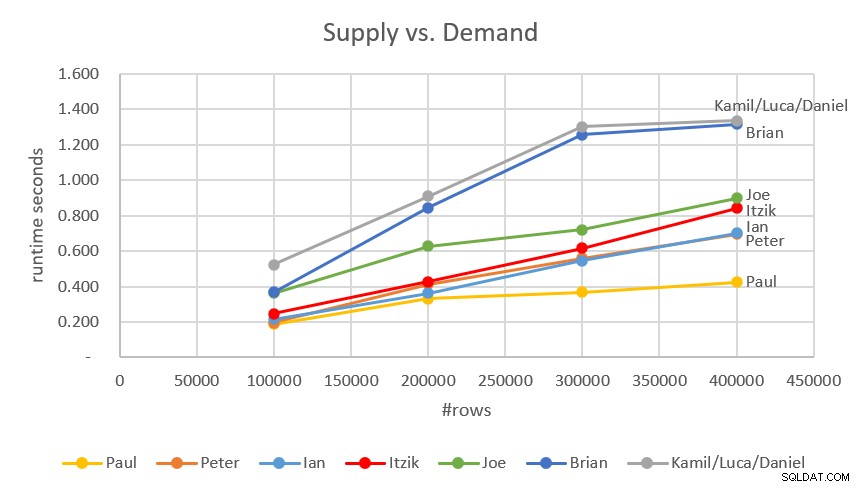 Figure 7:Performance comparison including earlier solutions
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
結論
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]