この記事では、PeterLarssonの魅力的な需要と供給のマッチングに対するソリューションについて引き続き取り上げます。ソリューションを送ってくれたLuca、Kamil Kosno、Daniel Brown、Brian Walker、Joe Obbish、Rainer Hoffmann、Paul White、Charlie、PeterLarssonに改めて感謝します。
先月、古典的な述語ベースの区間交差テストを使用して、区間交差に基づくソリューションについて説明しました。そのソリューションをクラシック交差点と呼びます。 。従来の間隔交差アプローチでは、2次スケーリング(N ^ 2)の計画が作成されます。 100Kから400K行の範囲のサンプル入力に対してパフォーマンスが低いことを示しました。 400K行の入力に対してソリューションが完了するまでに931秒かかりました。今月は、先月のソリューションと、その拡張性とパフォーマンスが非常に悪い理由を簡単に説明することから始めます。次に、区間交差テストの改訂に基づくアプローチを紹介します。このアプローチは、Luca、Kamil、そしておそらくDanielによっても使用され、はるかに優れたパフォーマンスとスケーリングを備えたソリューションを可能にします。そのソリューションを改訂された交差点と呼びます 。
従来の交差点テストの問題
先月の解決策を簡単に思い出してみましょう。
入力dbo.Auctionsテーブルで次のインデックスを使用して、需要と供給の間隔を生成する現在の合計の計算をサポートしました。
-- Index to support solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Enable batch-mode Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
次のコードには、従来のインターバル交差点アプローチを実装する完全なソリューションがあります。
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
CREATE UNIQUE CLUSTERED INDEX idx_cl_ES_ID ON #Supply(EndSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S WITH (FORCESEEK)
ON D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply; このコードは、需要と供給の間隔を計算し、それらを#Demandおよび#Supplyと呼ばれる一時テーブルに書き込むことから始まります。次に、コードは#Supplyにクラスター化されたインデックスを作成し、EndSupplyを先頭キーとして、交差テストを可能な限りサポートします。最後に、コードは#Supplyと#Demandを結合し、従来の間隔交差テストに基づく次の結合述語を使用して、交差する間隔の重複するセグメントとして取引を識別します。
D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply
このソリューションの計画を図1に示します。
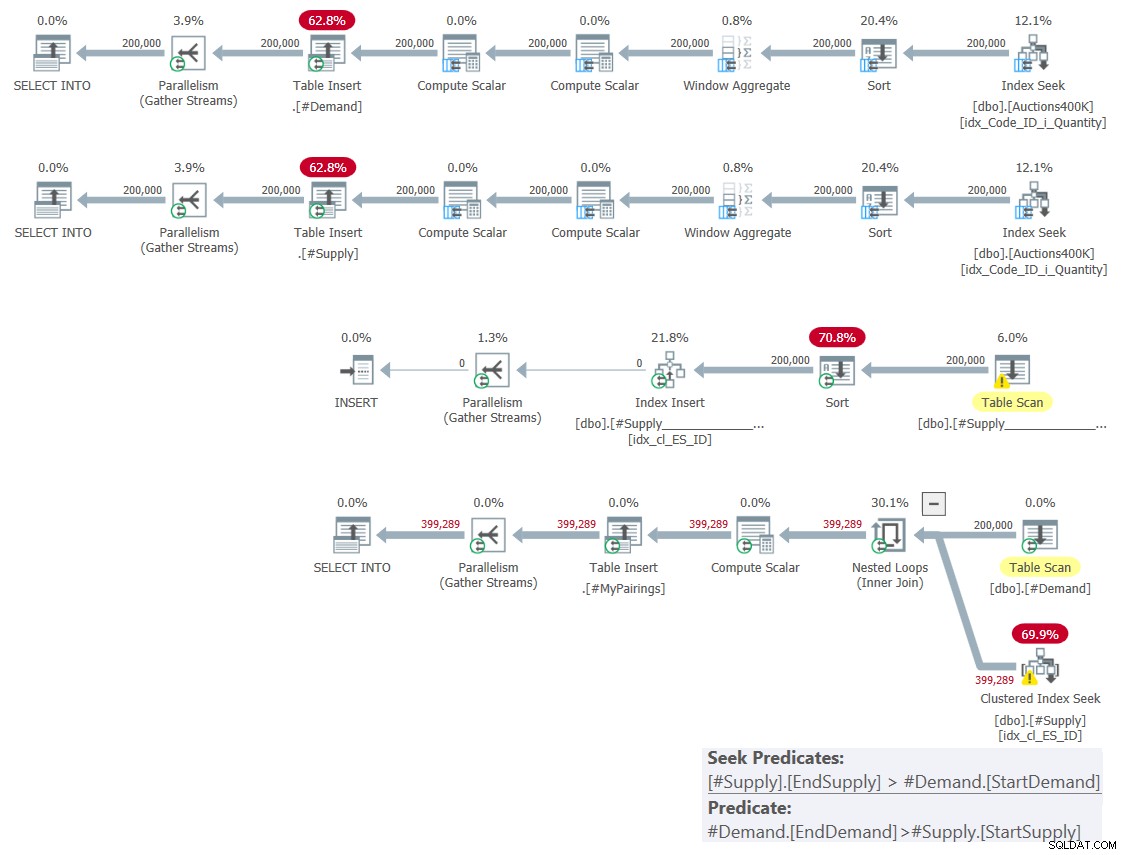 図1:従来の交差点に基づくソリューションのクエリプラン
図1:従来の交差点に基づくソリューションのクエリプラン
先月説明したように、関係する2つの範囲述語のうち、1つだけがインデックスシーク操作の一部としてシーク述語として使用できますが、もう1つは残差述語として適用する必要があります。これは、図1の最後のクエリの計画ではっきりとわかります。そのため、テーブルの1つに1つのインデックスを作成するだけで済みました。また、FORCESEEKヒントを使用して作成したインデックスでシークの使用を強制しました。そうしないと、オプティマイザはそのインデックスを無視し、インデックススプール演算子を使用して独自のインデックスを作成することになります。
インデックスシークは、シーク述語に基づいて、一方の行(この場合は#Demand)の行ごとに、もう一方の側(この場合は#Supply)の行の平均半分にアクセスする必要があるため、このプランは2次の複雑さを持っています。残差述語を適用することによる最終一致。
この計画が2次の複雑さを持っている理由がまだ不明な場合は、図2に示すように、作業の視覚的な描写が役立つ可能性があります。
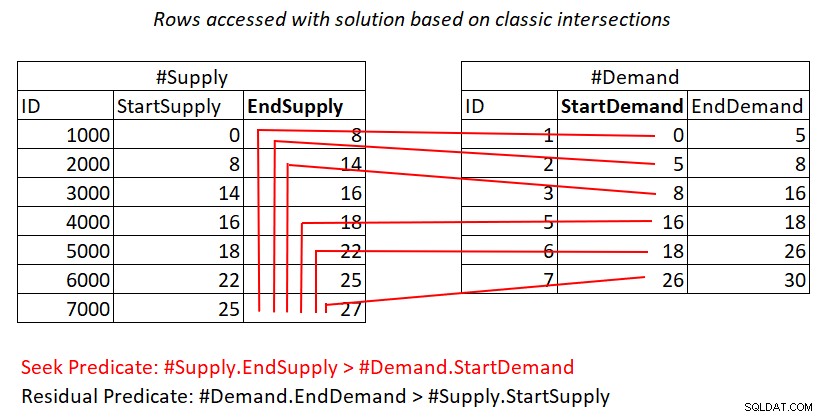 図2:従来の交差点に基づくソリューションを使用した作業の図>
図2:従来の交差点に基づくソリューションを使用した作業の図>
この図は、最後のクエリの計画でネストされたループの結合によって行われた作業を表しています。 #Demandヒープは結合の外部入力であり、#Supplyのクラスター化されたインデックス(EndSupplyを先頭キーとして)は内部入力です。赤い線は、#Supplyのインデックスの#Demandの行ごとに実行されるインデックスシークアクティビティと、インデックスリーフの範囲スキャンの一部としてアクセスする行を表しています。 #Demandの非常に低いStartDemand値に向けて、範囲スキャンは#Supplyのすべての行の近くにアクセスする必要があります。 #Demandの非常に高いStartDemand値に向けて、範囲スキャンは#Supplyのゼロに近い行にアクセスする必要があります。平均して、範囲スキャンは、需要のある行ごとに#Supplyの行の約半分にアクセスする必要があります。 D個の需要行とS個の供給行の場合、アクセスされる行数はD + D * S/2です。これは、一致する行に到達するためのシークのコストに追加されます。たとえば、dbo.Auctionsを200,000の需要行と200,000の供給行で埋める場合、これは、ネストされたループの結合が200,000の需要行+ 200,000 * 200,000 / 2の供給行にアクセスすること、または200,000 + 200,000 ^ 2/2=20,000,200,000の行にアクセスすることを意味します。ここで行われている供給行の再スキャンがたくさんあります!
区間交差点のアイデアに固執したいが、良いパフォーマンスを得たい場合は、行われる作業の量を減らす方法を考え出す必要があります。
彼のソリューションでは、JoeObbishが最大間隔の長さに基づいて間隔をバケット化しました。このようにして、彼は、結合が処理し、バッチ処理に依存するために必要な行数を減らすことができました。彼は、古典的な間隔交差テストを最終フィルターとして使用しました。 Joeのソリューションは、最大間隔の長さがそれほど長くない限りうまく機能しますが、最大間隔の長さが長くなると、ソリューションの実行時間が長くなります。
では、他に何ができるでしょうか…?
改訂された交差点テスト
Luca、Kamil、そしておそらくDaniel(Webサイトのフォーマットのために、彼の投稿されたソリューションについて不明確な部分があったので、推測しなければなりませんでした)は、インデックス作成のはるかに優れた利用を可能にする改訂された間隔交差テストを使用しました。
それらの交差テストは、2つの述語(OR演算子で区切られた述語)の論理和です:
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply >= D.StartDemand AND S.StartSupply < D.EndDemand)
英語では、需要開始区切り文字が供給間隔と包括的かつ排他的な方法で交差します(開始を含み、終了を除く)。または、供給開始区切り文字が、包括的かつ排他的な方法で需要間隔と交差します。 2つの述語を互いに素な(大文字と小文字が重ならない)が、すべての大文字と小文字を完全にカバーできるようにするには、たとえば、次のように=演算子をどちらか一方だけに留めます。
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand)
この改訂された区間交差テストは非常に洞察に満ちています。各述部は、潜在的に効率的にインデックスを使用できます。述語1を検討してください:
D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
StartDemandを先頭キーとして#Demandでカバーするインデックスを作成すると仮定すると、図3に示す作業を適用して、ネストされたループを結合できる可能性があります。
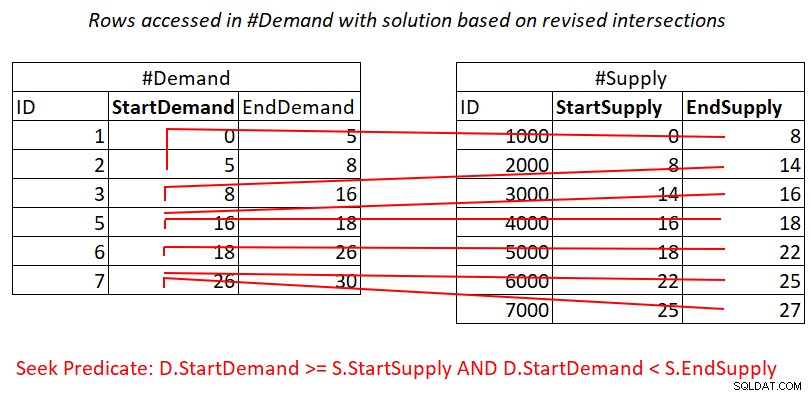
図3:述語の処理に必要な理論的作業の図1
はい、#Supplyの行ごとの#Demandインデックスでシークの料金を支払いますが、インデックスリーフアクセスの範囲スキャンは、行のサブセットをほとんどばらばらにします。行の再スキャンはありません!
状況は述語2と似ています:
S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
StartSupplyを先頭キーとして#Supplyにカバーインデックスを作成すると仮定すると、図4に示す作業を適用して、ネストされたループを結合できる可能性があります。
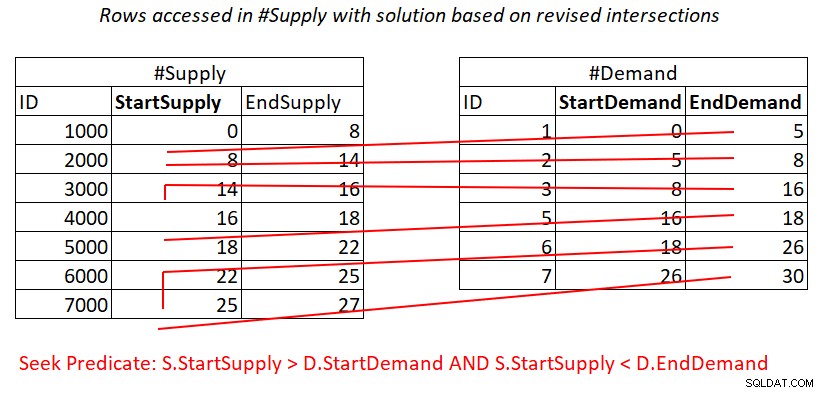
図4:述語の処理に必要な理論的作業の図2
また、ここでは、#Demandの行ごとに#Supplyインデックスでシークの料金を支払います。次に、インデックスリーフの範囲スキャンにより、行のサブセットがほとんどばらばらになります。繰り返しますが、行の再スキャンはありません!
Dの需要行とSの供給行を想定すると、作業は次のように記述できます。
Number of index seek operations: D + S Number of rows accessed: 2D + 2S
おそらく、ここでのコストの最大の部分は、シークに関連するI/Oコストです。ただし、作業のこの部分には、従来の間隔交差クエリの2次スケーリングと比較して線形スケーリングがあります。
もちろん、一時テーブルでのインデックス作成の予備コストを考慮する必要があります。これには、関連する並べ替えのためにn log nのスケーリングがありますが、この部分は両方のソリューションの予備部分として支払います。
この理論を実践してみましょう。まず、#Demandと#supplyの一時テーブルに需要と供給の間隔(従来の間隔の交差点と同じ)を入力し、サポートするインデックスを作成します。
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID); 一時テーブルにデータを入力してインデックスを作成する計画を図5に示します。
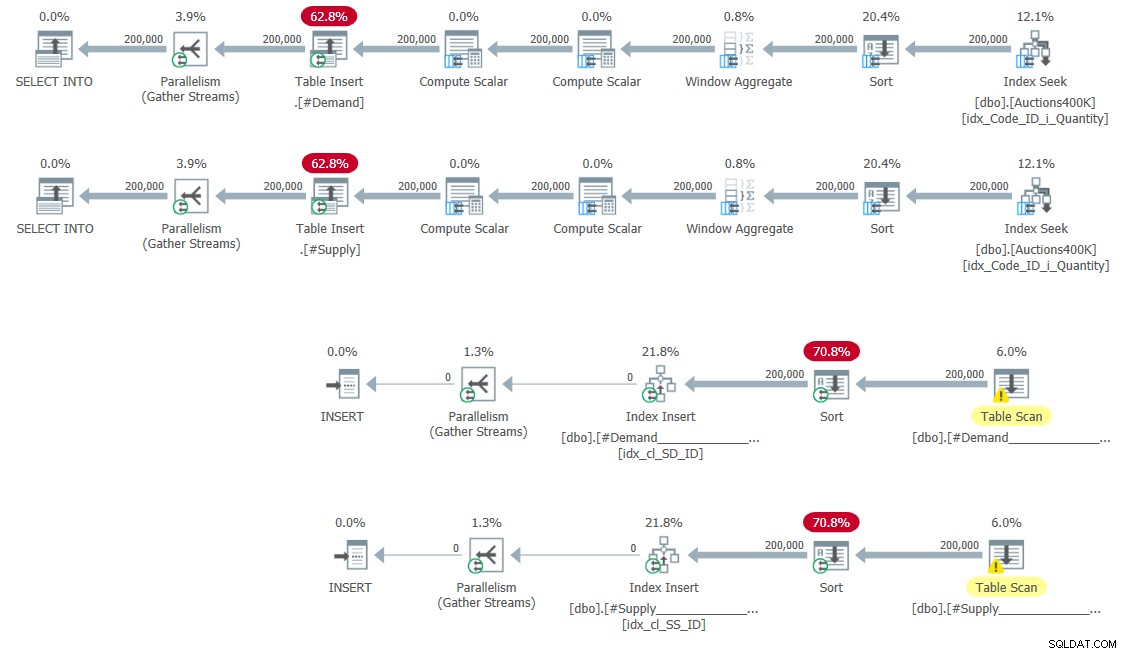
図5:一時テーブルにデータを入力して作成するためのクエリプランインデックス
ここに驚きはありません。
最後のクエリに移ります。次のように、前述の2つの述語の論理和を使用して単一のクエリを使用したくなる場合があります。
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON (D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand); このクエリの計画を図6に示します。
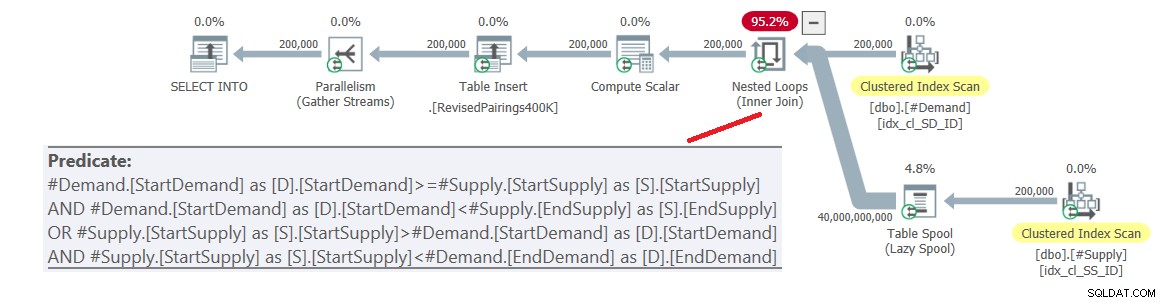
図6:改訂された交差点を使用した最終クエリのクエリプランテスト、1を試してください
問題は、オプティマイザがこのロジックを2つの別々のアクティビティに分割する方法を知らないことです。それぞれが異なる述語を処理し、それぞれのインデックスを効率的に利用します。したがって、最終的には、すべての述語を残余述語として適用して、両側の完全なデカルト積になります。 200,000の需要行と200,000の供給行がある場合、結合は40,000,000,000行を処理します。
Luca、Kamil、そしておそらくDanielが使用した洞察に満ちたトリックは、ロジックを2つのクエリに分割し、それらの結果を統合することでした。ここで、2つの互いに素な述語を使用することが重要になります。 UNIONの代わりにUNIONALL演算子を使用して、重複を探すという不必要なコストを回避できます。このアプローチを実装するクエリは次のとおりです。
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; このクエリの計画を図7に示します。
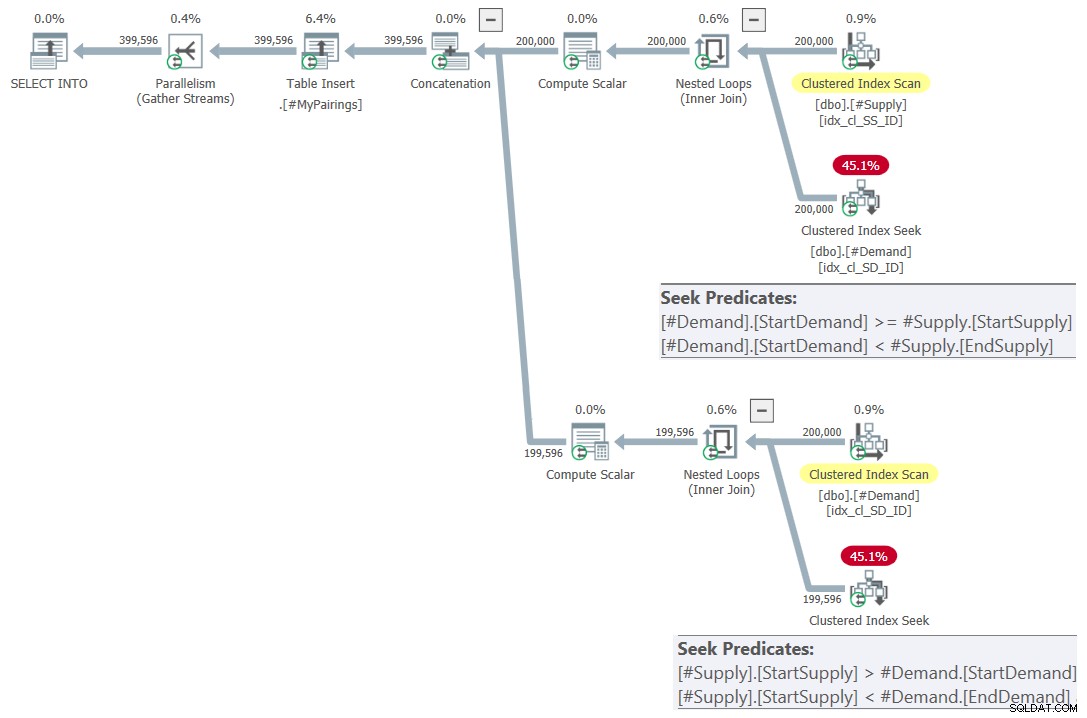
図7:改訂された交差点を使用した最終クエリのクエリプランテスト、2を試してください
これはただ美しいです!ではない?そして、それはとても美しいので、一時テーブルの作成、インデックス作成、最終的なクエリを含む、ゼロからのソリューション全体を次に示します。
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; 前述のように、このソリューションを改訂された交差点と呼びます。 。
カミルのソリューション
Luca、Kamil、Danielのソリューションの中で、Kamilが最速でした。カミルの完全なソリューションは次のとおりです。
SET NOCOUNT ON;
DROP TABLE IF EXISTS #supply, #demand;
GO
CREATE TABLE #demand
(
DemandID INT NOT NULL,
DemandQuantity DECIMAL(19, 6) NOT NULL,
QuantityFromDemand DECIMAL(19, 6) NOT NULL,
QuantityToDemand DECIMAL(19, 6) NOT NULL
);
CREATE TABLE #supply
(
SupplyID INT NOT NULL,
QuantityFromSupply DECIMAL(19, 6) NOT NULL,
QuantityToSupply DECIMAL(19,6) NOT NULL
);
WITH demand AS
(
SELECT
a.ID AS DemandID,
a.Quantity AS DemandQuantity,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromDemand,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToDemand
FROM dbo.Auctions AS a WHERE Code = 'D'
)
INSERT INTO #demand
(
DemandID,
DemandQuantity,
QuantityFromDemand,
QuantityToDemand
)
SELECT
d.DemandID,
d.DemandQuantity,
d.QuantityFromDemand,
d.QuantityToDemand
FROM demand AS d;
WITH supply AS
(
SELECT
a.ID AS SupplyID,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromSupply,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToSupply
FROM dbo.Auctions AS a WHERE Code = 'S'
)
INSERT INTO #supply
(
SupplyID,
QuantityFromSupply,
QuantityToSupply
)
SELECT
s.SupplyID,
s.QuantityFromSupply,
s.QuantityToSupply
FROM supply AS s;
CREATE UNIQUE INDEX ix_1 ON #demand(QuantityFromDemand)
INCLUDE(DemandID, DemandQuantity, QuantityToDemand);
CREATE UNIQUE INDEX ix_1 ON #supply(QuantityFromSupply)
INCLUDE(SupplyID, QuantityToSupply);
CREATE NONCLUSTERED COLUMNSTORE INDEX nci ON #demand(DemandID)
WHERE DemandID is null;
DROP TABLE IF EXISTS #myPairings;
CREATE TABLE #myPairings
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
INSERT INTO #myPairings(DemandID, SupplyID, TradeQuantity)
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 end
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #demand AS d
INNER JOIN #supply AS s
ON (d.QuantityFromDemand < s.QuantityToSupply
AND s.QuantityFromSupply <= d.QuantityFromDemand)
UNION ALL
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 END
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #supply AS s
INNER JOIN #demand AS d
ON (s.QuantityFromSupply < d.QuantityToDemand
AND d.QuantityFromDemand < s.QuantityFromSupply); ご覧のとおり、これは私がカバーした修正された交差点ソリューションに非常に近いものです。
カミルのソリューションの最終的なクエリの計画を図8に示します。
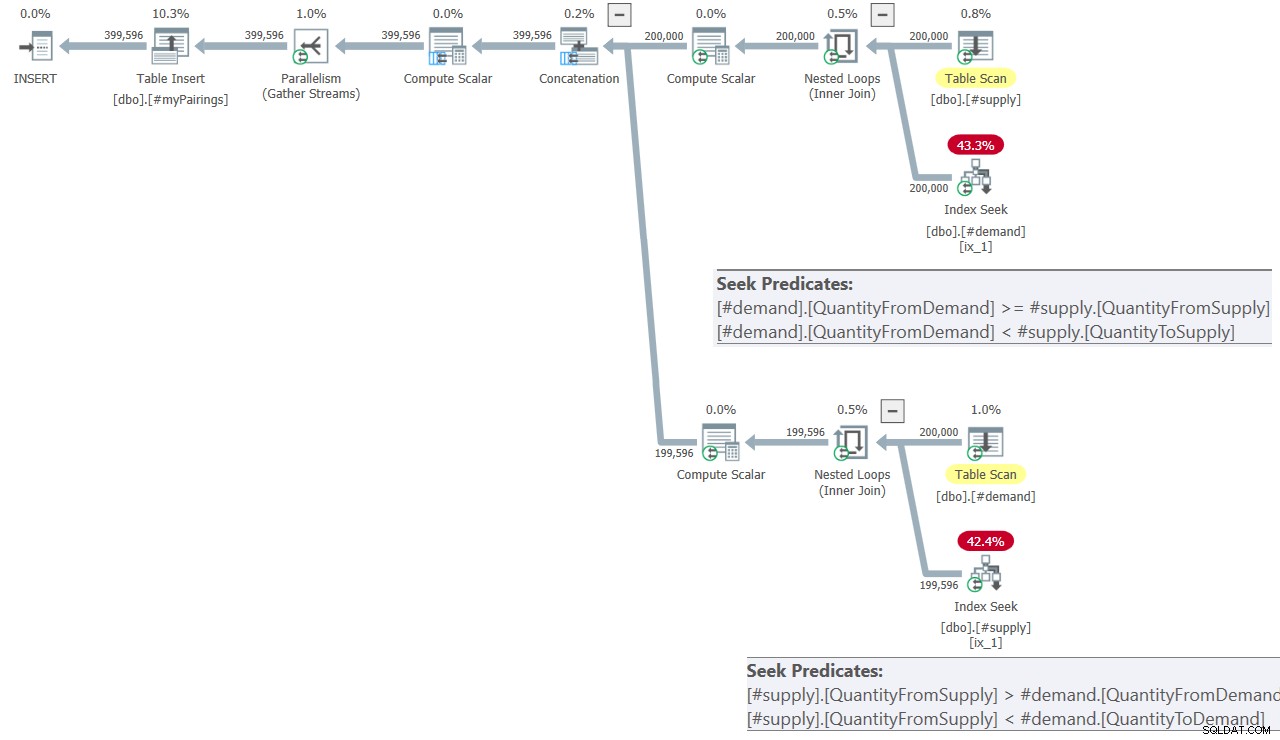
図8:カミルのソリューションでの最終クエリのクエリプラン
計画は、前に図7に示したものと非常によく似ています。
パフォーマンステスト
従来の交差点ソリューションは、400K行の入力に対して完了するのに931秒かかったことを思い出してください。 15分です!同じ入力に対して完了するのに約12秒かかったカーソルソリューションよりもはるかに悪いです。図9は、この記事で説明した新しいソリューションを含むパフォーマンスの数値です。
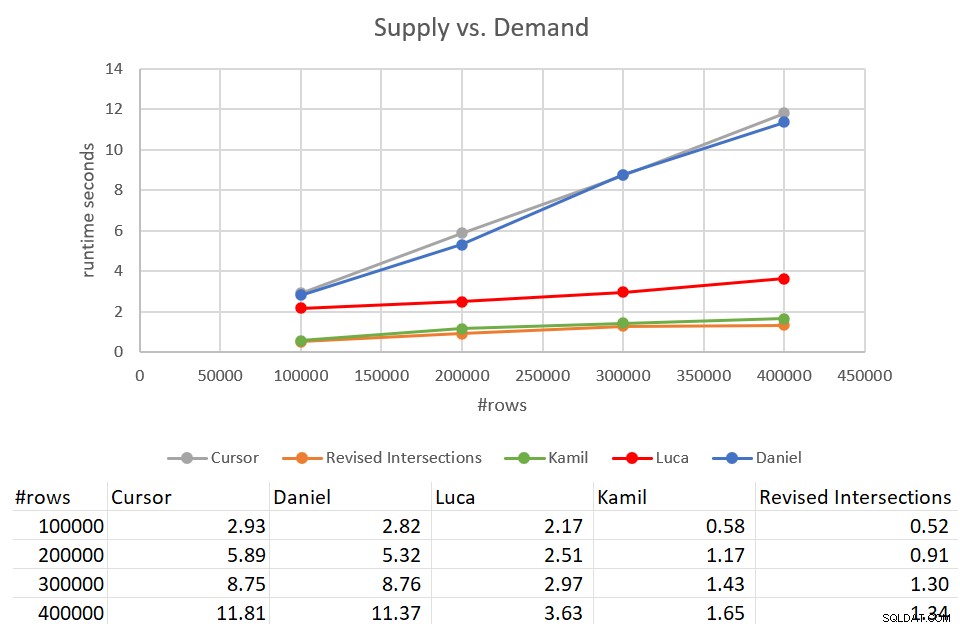
ご覧のとおり、Kamilのソリューションと同様の改訂された交差点ソリューションは、400K行の入力に対して完了するのに約1.5秒かかりました。これは、元のカーソルベースのソリューションと比較してかなり適切な改善です。これらのソリューションの主な欠点は、I/Oコストです。行ごとのシークでは、400K行の入力に対して、これらのソリューションは135万回を超える読み取りを実行します。ただし、実行時間とスケーリングが良好であることを考えると、完全に許容できるコストと見なすこともできます。
次は何ですか?
供給と需要のマッチングの課題を解決する最初の試みは、古典的な間隔交差テストに依存し、2次スケーリングを使用したパフォーマンスの低い計画を取得しました。カーソルベースのソリューションよりもはるかに悪いです。 Luca、Kamil、およびDanielからの洞察に基づいて、改訂された区間交差テストを使用して、2番目の試みは、インデックス作成を効率的に利用し、カーソルベースのソリューションよりも優れたパフォーマンスを発揮する大幅な改善でした。ただし、このソリューションにはかなりのI/Oコストがかかります。来月は、追加のソリューションを引き続き検討します。
[ジャンプ先:元のチャレンジ|ソリューション:パート1 |パート2|パート3]