[パート1|パート2|パート3|パート4]
MERGE ステートメント(SQL Server 2008で導入)を使用すると、INSERTを組み合わせて実行できます。 、UPDATE 、およびDELETE 単一のステートメントを使用した操作。 MERGEのハロウィーン保護の問題 ほとんどは個々の操作の要件の組み合わせですが、いくつかの重要な違いと、MERGEにのみ適用されるいくつかの興味深い最適化があります。 。
MERGEによるハロウィーンの問題の回避
パート2のデモとステージングの例をもう一度見てみましょう。
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
);
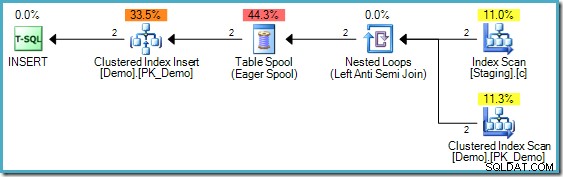
覚えているかもしれませんが、この例はINSERTを示すために使用されました 挿入ターゲットテーブルがSELECTでも参照されている場合は、HalloweenProtectionが必要です クエリの一部(EXISTS この場合の条項)。 INSERTの正しい動作 上記のステートメントは、両方を追加しようとすることです 1234の値であり、その結果、PRIMARY KEYで失敗します 違反。相分離なしの場合、INSERT 誤って1つの値を追加し、エラーがスローされることなく完了します。
INSERT実行プラン
上記のコードには、パート2で使用したコードとの違いが1つあります。ステージングテーブルに非クラスター化インデックスが追加されました。 INSERT 実行計画まだ ただし、ハロウィーン保護が必要です:
MERGE実行プラン
ここで、MERGEを使用して表現された同じ論理挿入を試してください 構文:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey);
構文に慣れていない場合は、SomeKey値のステージングテーブルとデモテーブルの行を比較するロジックがあります。ターゲット(デモ)テーブルに一致する行が見つからない場合は、新しい行を挿入します。これは、前のINSERT...WHERE NOT EXISTSとまったく同じセマンティクスを持っています もちろん、コード。ただし、実行計画はまったく異なります。
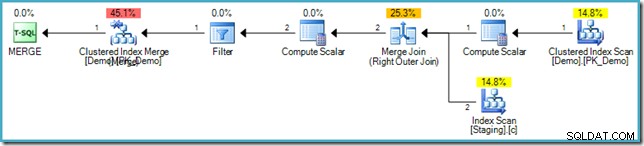
この計画には熱心なテーブルスプールがないことに注意してください。それにもかかわらず、クエリは正しいエラーメッセージを生成します。 SQLServerがMERGEを実行する方法を見つけたようです SQL標準で要求される論理的な相分離を尊重しながら、繰り返し計画します。
穴埋めの最適化
適切な状況では、SQLServerオプティマイザーはMERGEを認識できます。 ステートメントは穴埋めです 、これは、ステートメントがターゲットテーブルのキーに既存のギャップがある場合にのみ行を追加するという別の言い方です。
この最適化を適用するために、WHEN NOT MATCHED BY TARGETで使用される値 句は正確に必要です ONと一致する USINGの一部 句。また、ターゲットテーブルには一意のキーが必要です(PRIMARY KEYが満たす要件 この場合)。これらの要件が満たされている場合、MERGE ステートメントは、ハロウィーンの問題からの保護を必要としません。
もちろん、MERGE ステートメントは論理的に 多かれ少なかれ穴埋め 元のINSERT...WHERE NOT EXISTSより 構文。違いは、オプティマイザーがMERGEの実装を完全に制御できることです。 一方、INSERT 構文では、クエリのより広いセマンティクスについて推論する必要があります。人間はINSERTを簡単に確認できます は穴埋めでもありますが、オプティマイザーは私たちと同じように物事を考えていません。
完全一致を説明するため 私が言及した要件では、次のクエリ構文を検討してください。これはありません 穴埋めの最適化の恩恵を受けます。その結果、熱心なテーブルスプールによって提供される完全なハロウィーン保護が実現します:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1);

唯一の違いは、VALUESでの1による乗算です。 句–クエリのロジックを変更しないが、穴埋めの最適化が適用されるのを防ぐのに十分なもの。
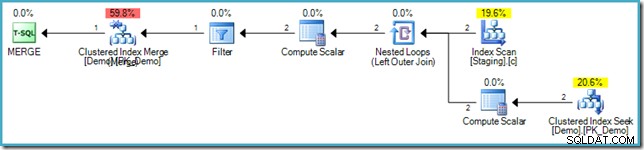
ネストされたループによる穴埋め
前の例では、オプティマイザはマージ結合を使用してテーブルを結合することを選択しました。ネストされたループの結合が選択されている場合は、穴埋めの最適化も適用できますが、これには、ソーステーブルでの追加の一意性の保証と、結合の内側でのインデックスシークが必要です。これが実際に動作していることを確認するには、既存のステージングデータをクリアし、非クラスター化インデックスに一意性を追加して、MERGEを試してください。 もう一度:
-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); 結果の実行プランは、ネストされたループの結合とターゲットテーブルへの内側のシークを使用して、ハロウィーン保護を回避するために穴埋めの最適化を再び使用します。
不要なインデックストラバーサルの回避
穴埋めの最適化が適用される場合、エンジンはさらに最適化を適用することもできます。 読み取り中、現在のインデックス位置を記憶できます。 ターゲットテーブル(一度に1行を処理することを忘れないでください)を使用し、挿入場所を見つけるためにbツリーを検索する代わりに、挿入を実行するときにその情報を再利用します。その理由は、現在の読み取り位置は、新しい行が挿入されるのと同じページにある可能性が非常に高いためです。行が実際にこのページに属していることを確認するのは非常に高速です。これは、現在そこに格納されている最低キーと最高キーのみをチェックする必要があるためです。
実行プランがキャッシュから取得される場合、Eager Table Spoolを排除し、行ごとのインデックスナビゲーションを保存することで、OLTPワークロードに大きなメリットをもたらすことができます。 MERGEのコンパイルコスト ステートメントはINSERTよりもかなり高くなります 、UPDATE およびDELETE したがって、計画の再利用は重要な考慮事項です。また、ページの分割を避けて、ページに新しい行を収容するのに十分な空きスペースがあることを確認することも役立ちます。これは通常、通常のインデックスのメンテナンスと適切なFILLFACTORの割り当てによって実現されます。 。
MERGEが原因で、通常は比較的小さな変更が多数含まれるOLTPワークロードについて説明します。 ステートメントごとに多数の行が処理される場合、最適化は適切な選択ではない可能性があります。最小限のログのINSERTsなどの他の最適化 現在、穴埋めと組み合わせることはできません。いつものように、期待されるメリットを確実に実現するには、パフォーマンス特性をベンチマークする必要があります。
MERGEの穴埋めの最適化 追加のMERGEを使用して、挿入を更新および削除と組み合わせることができます 条項;データを変更する各操作は、ハロウィーンの問題について個別に評価されます。
参加の回避
ここで説明する最終的な最適化は、MERGEに適用できます。 ステートメントには、更新および削除操作と穴埋め挿入が含まれ、ターゲットテーブルには一意のクラスター化インデックスがあります。次の例は、一般的なMERGEを示しています。 一致しない行が挿入され、追加の条件に応じて一致する行が更新または削除されるパターン:
CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90);
MERGE 必要なすべての変更を行うために必要なステートメントは非常にコンパクトです:
MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
実行計画は非常に驚くべきものです:

ハロウィーン保護はなく、ソーステーブルとターゲットテーブル間の結合もありません。また、クラスター化インデックスの挿入演算子の後にクラスター化インデックスが同じテーブルにマージされることはめったにありません。これは、プランの再利用性が高く、適切なインデックス付けを備えたOLTPワークロードを対象としたもう1つの最適化です。
アイデアは、ソーステーブルから行を読み取り、すぐにそれをターゲットに挿入しようとすることです。キー違反が発生した場合、エラーは抑制され、挿入演算子は検出された競合する行を出力し、その行は通常どおりマージプラン演算子を使用して更新または削除操作のために処理されます。
元の挿入が成功した場合(キー違反なし)、処理はソースからの次の行に進みます(マージ演算子は更新と削除のみを処理します)。この最適化は主にMERGEにメリットをもたらします ほとんどのソース行が挿入になるクエリ。繰り返しになりますが、個別のステートメントを使用するよりもパフォーマンスを向上させるには、注意深いベンチマークが必要です。
概要
MERGE ステートメントは、いくつかのユニークな最適化の機会を提供します。適切な状況では、同等のINSERTと比較して、明示的なハロウィーン保護を追加する必要がなくなります。 操作、またはおそらくINSERTの組み合わせ 、UPDATE 、およびDELETE ステートメント。追加のMERGE -特定の最適化により、新しい行の挿入位置を見つけるために通常必要となるインデックスbツリートラバーサルを回避でき、ソーステーブルとターゲットテーブルを完全に結合する必要も回避できます。
このシリーズの最後のパートでは、クエリオプティマイザーがハロウィーン保護の必要性についてどのように理由付けているかを確認し、データを変更する実行プランにEagerTableSpoolsを追加する必要性を回避するために採用できるいくつかのトリックを特定します。
[パート1|パート2|パート3|パート4]