Kevin Kline(@kekline)と私は最近クエリチューニングウェビナーを開催しました(実際にはシリーズの1つです)。そして、SQL Serverが次のように指示する、欠落しているインデックスを作成する傾向があります。 良いこと™ 。これらの欠落しているインデックスについては、Database Engine Tuning Advisor(DTA)、欠落しているインデックスDMV、またはManagementStudioまたはPlanExplorerに表示される実行プラン(すべてまったく同じ場所からの情報を中継するだけです)から知ることができます:
>
このインデックスを盲目的に作成する場合の問題は、SQL Serverが特定のクエリ(または少数のクエリ)に役立つと判断したが、残りのワークロードを完全かつ一方的に無視することです。ご存知のとおり、インデックスは「無料」ではありません。生のストレージとDML操作に必要なメンテナンスの両方でインデックスの料金を支払います。書き込みが多いワークロードでは、特にそのクエリが頻繁に実行されない場合に、単一のクエリをわずかに効率的にするのに役立つインデックスを追加することはほとんど意味がありません。このような場合、全体的なワークロードを理解し、クエリを効率的にすることと、インデックスのメンテナンスの観点からあまりお金をかけないことのバランスをとることが非常に重要になる場合があります。
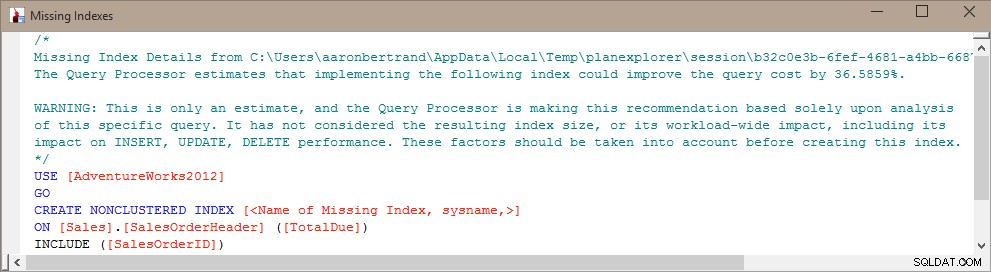
したがって、私が持っていたアイデアは、欠落しているインデックスDMV、インデックス使用統計DMV、およびクエリプランに関する情報からの情報を「マッシュアップ」して、現在存在するバランスのタイプと、インデックスの追加が全体的にどのように機能するかを判断することでした。
インデックスがありません
まず、SQLServerが現在提案している欠落しているインデックスを確認できます。
SELECT d.[object_id], s = OBJECT_SCHEMA_NAME(d.[object_id]), o = OBJECT_NAME(d.[object_id]), d.equality_columns, d.inequality_columns, d.included_columns, s.unique_compiles, s.user_seeks, s.last_user_seek, s.user_scans, s.last_user_scan INTO #candidates FROM sys.dm_db_missing_index_details AS d INNER JOIN sys.dm_db_missing_index_groups AS g ON d.index_handle = g.index_handle INNER JOIN sys.dm_db_missing_index_group_stats AS s ON g.index_group_handle = s.group_handle WHERE d.database_id = DB_ID() AND OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0;
これは、インデックスで役立つテーブルと列、使用されたコンパイル/シーク/スキャンの数、および潜在的なインデックスごとにそのようなイベントが最後に発生した日時を示しています。 s.avg_total_user_costのような列を含めることもできます およびs.avg_user_impact これらの数値を使用して優先順位を付けたい場合。
運用の計画
次に、欠落しているインデックスによって識別されたオブジェクトに対してキャッシュしたすべてのプランで使用されている操作を見てみましょう。
CREATE TABLE #planops
(
o INT,
i INT,
h VARBINARY(64),
uc INT,
Scan_Ops INT,
Seek_Ops INT,
Update_Ops INT
);
DECLARE @sql NVARCHAR(MAX) = N'';
SELECT @sql += N'
UNION ALL SELECT o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
FROM
(
SELECT o = ' + RTRIM([object_id]) + ',
i = ' + RTRIM(index_id) +',
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Scan'''''
+ ' or @LogicalOp = ''''Clustered Index Scan'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Seek_Ops = p.query_plan.value(''count(//RelOp[@LogicalOp = ''''Index Seek'''''
+ ' or @LogicalOp = ''''Clustered Index Seek'''']/*/'
+ 'Object[@Index=''''' + QUOTENAME(name) + '''''])'', ''int''),
Update_Ops = p.query_plan.value(''count(//Update/Object[@Index='''''
+ QUOTENAME(name) + '''''])'', ''int'')
FROM sys.dm_exec_cached_plans AS pl
CROSS APPLY sys.dm_exec_query_plan(pl.plan_handle) AS p
WHERE p.dbid = DB_ID()
AND p.query_plan IS NOT NULL
) AS x
WHERE Scan_Ops + Seek_Ops + Update_Ops > 0'
FROM sys.indexes AS i
WHERE i.index_id > 0
AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = i.[object_id]);
SET @sql = ';WITH xmlnamespaces (DEFAULT '
+ 'N''https://schemas.microsoft.com/sqlserver/2004/07/showplan'')
' + STUFF(@sql, 1, 16, '');
INSERT #planops EXEC sp_executesql @sql; dba.SEの友人であるMikaelErikssonは、次の2つのクエリを提案しました。これらのクエリは、大規模なシステムでは、上記でまとめたXML / UNIONクエリよりもはるかに優れているため、最初にそれらを試すことができます。彼の最後のコメントは、「当然のことながら、XMLの削減がパフォーマンスにとって良いことであることに気づきました。:)」というものでした。
-- alternative #1
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o,i,h,uc,Scan_Ops,Seek_Ops,Update_Ops
from
(
select o = i.object_id,
i = i.index_id,
h = pl.plan_handle,
uc = pl.usecounts,
Scan_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Scan", "Clustered Index Scan")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Seek_Ops = p.query_plan.value('count(//RelOp[@LogicalOp
= ("Index Seek", "Clustered Index Seek")]/*/Object[@Index = sql:column("i2.name")])', 'int'),
Update_Ops = p.query_plan.value('count(//Update/Object[@Index = sql:column("i2.name")])', 'int')
from sys.indexes as i
cross apply (select quotename(i.name) as name) as i2
cross apply sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
where exists (select 1 from #candidates as c where c.[object_id] = i.[object_id])
and p.query_plan.exist('//Object[@Index = sql:column("i2.name")]') = 1
and p.[dbid] = db_id()
and i.index_id > 0
) as T
where Scan_Ops + Seek_Ops + Update_Ops > 0;
-- alternative #2
with xmlnamespaces (default 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
insert #planops
select o = coalesce(T1.o, T2.o),
i = coalesce(T1.i, T2.i),
h = coalesce(T1.h, T2.h),
uc = coalesce(T1.uc, T2.uc),
Scan_Ops = isnull(T1.Scan_Ops, 0),
Seek_Ops = isnull(T1.Seek_Ops, 0),
Update_Ops = isnull(T2.Update_Ops, 0)
from
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Scan_Ops = sum(case when t.LogicalOp in ('Index Scan', 'Clustered Index Scan') then 1 else 0 end),
Seek_Ops = sum(case when t.LogicalOp in ('Index Seek', 'Clustered Index Seek') then 1 else 0 end)
from (
select
r.n.value('@LogicalOp', 'varchar(100)') as LogicalOp,
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//RelOp') as r(n)
cross apply r.n.nodes('*/Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where t.LogicalOp in ('Index Scan', 'Clustered Index Scan', 'Index Seek', 'Clustered Index Seek')
and exists (select 1 from #candidates as c where c.object_id = i.object_id)
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T1
full outer join
(
select o = i.object_id,
i = i.index_id,
h = t.plan_handle,
uc = t.usecounts,
Update_Ops = count(*)
from (
select
o.n.value('@Index', 'sysname') as IndexName,
pl.plan_handle,
pl.usecounts
from sys.dm_exec_cached_plans as pl
cross apply sys.dm_exec_query_plan(pl.plan_handle) AS p
cross apply p.query_plan.nodes('//Update') as r(n)
cross apply r.n.nodes('Object') as o(n)
where p.dbid = db_id()
and p.query_plan is not null
) as t
inner join sys.indexes as i
on t.IndexName = quotename(i.name)
where exists
(
select 1 from #candidates as c where c.[object_id] = i.[object_id]
)
and i.index_id > 0
group by i.object_id,
i.index_id,
t.plan_handle,
t.usecounts
) as T2
on T1.o = T2.o and
T1.i = T2.i and
T1.h = T2.h and
T1.uc = T2.uc;
今#planopsに plan_handleの値がたくさんあるテーブル これにより、有用なインデックスが不足していると識別されたオブジェクトに対して、実行中の個々の計画のそれぞれを調査することができます。今はそのために使用するつもりはありませんが、これを次のように簡単に相互参照できます:
SELECT OBJECT_SCHEMA_NAME(po.o), OBJECT_NAME(po.o), po.uc,po.Scan_Ops,po.Seek_Ops,po.Update_Ops, p.query_plan FROM #planops AS po CROSS APPLY sys.dm_exec_query_plan(po.h) AS p;
これで、出力プランのいずれかをクリックして、オブジェクトに対して現在何を行っているかを確認できます。プランには、同じテーブル上の異なるインデックスを参照する複数の演算子が含まれる可能性があるため、一部のプランは繰り返されることに注意してください。
インデックス使用統計
次に、インデックスの使用統計を見てみましょう。これにより、候補テーブル(特に更新)に対して現在実行されている実際のアクティビティの量を確認できます。
SELECT [object_id], index_id, user_seeks, user_scans, user_lookups, user_updates INTO #indexusage FROM sys.dm_db_index_usage_stats AS s WHERE database_id = DB_ID() AND EXISTS (SELECT 1 FROM #candidates WHERE [object_id] = s.[object_id]);
インデックス使用統計がそれらのインデックスが更新されたことを示している場合でも、キャッシュ内のプランが特定のインデックスの更新を示しているものがほとんどないか、まったくない場合でも、気にしないでください。これは、更新プランが現在キャッシュにないことを意味します。これは、さまざまな理由で発生する可能性があります。たとえば、非常に読み取りが多いワークロードであり、古くなっているか、すべてが単一である可能性があります。使用してoptimize for ad hoc workloads 有効になっています。
すべてをまとめる
次のクエリは、提案された欠落しているインデックスごとに、インデックスが支援した可能性のある読み取りの数、既存のインデックスに対して現在キャプチャされている書き込みと読み取りの数、それらの比率、に関連付けられているプランの数を示します。そのオブジェクト、およびそれらのプランの合計使用数:
;WITH x AS
(
SELECT
c.[object_id],
potential_read_ops = SUM(c.user_seeks + c.user_scans),
[write_ops] = SUM(iu.user_updates),
[read_ops] = SUM(iu.user_scans + iu.user_seeks + iu.user_lookups),
[write:read ratio] = CONVERT(DECIMAL(18,2), SUM(iu.user_updates)*1.0 /
SUM(iu.user_scans + iu.user_seeks + iu.user_lookups)),
current_plan_count = po.h,
current_plan_use_count = po.uc
FROM
#candidates AS c
LEFT OUTER JOIN
#indexusage AS iu
ON c.[object_id] = iu.[object_id]
LEFT OUTER JOIN
(
SELECT o, h = COUNT(h), uc = SUM(uc)
FROM #planops GROUP BY o
) AS po
ON c.[object_id] = po.o
GROUP BY c.[object_id], po.h, po.uc
)
SELECT [object] = QUOTENAME(c.s) + '.' + QUOTENAME(c.o),
c.equality_columns,
c.inequality_columns,
c.included_columns,
x.potential_read_ops,
x.write_ops,
x.read_ops,
x.[write:read ratio],
x.current_plan_count,
x.current_plan_use_count
FROM #candidates AS c
INNER JOIN x
ON c.[object_id] = x.[object_id]
ORDER BY x.[write:read ratio];
これらのインデックスに対する書き込み:読み取りの比率がすでに> 1(または> 10!)である場合、この比率を増やすことしかできないインデックスを盲目的に作成する前に、一時停止する理由があると思います。 potential_read_opsの数 示されているが、数が大きくなるにつれてそれを相殺する可能性があります。 potential_read_opsの場合 数が非常に少ないため、他の指標を調査する前に、推奨事項を完全に無視することをお勧めします。そのため、WHEREを追加できます。 それらの推奨事項の一部を除外する句。
いくつかのメモ:
- これらは読み取りと書き込みの操作であり、8Kページの読み取りと書き込みを個別に測定するものではありません。
- 比率と比較は主に教育的なものです。 10,000,000の書き込み操作がすべて単一の行に影響を与えたのに対し、10の読み取り操作は大幅に大きな影響を与えた可能性があります。これは大まかなガイドラインとして意図されたものであり、読み取り操作と書き込み操作の重みがほぼ同じであることを前提としています。
- これらのクエリの一部にわずかなバリエーションを使用して、SQL Serverが推奨している欠落しているインデックス以外に、現在のインデックスのうち無駄なものがいくつあるかを確認することもできます。このオンラインについては、Paul Randal(@PaulRandal)によるこの投稿を含め、たくさんのアイデアがあります。
いくつかのツールが作成するように指示したインデックスを追加することを決定する前に、システムの動作についてより多くの洞察を得るためのいくつかのアイデアが得られることを願っています。これを1つの大規模なクエリとして作成することもできますが、必要に応じて、個々のパーツで調査するためのうさぎの穴がいくつか得られると思います。
その他の注意事項
また、これを拡張して、現在のサイズメトリック、テーブルの幅、現在の行数(および将来の成長に関する予測)をキャプチャすることもできます。これにより、新しいインデックスが占めるスペースの量を把握できます。これは、環境によっては問題になる可能性があります。これは将来の投稿で扱う可能性があります。
もちろん、これらのメトリックは稼働時間が指示する場合にのみ役立つことを覚えておく必要があります。 DMVは再起動後にクリアされるため(場合によっては、他の混乱の少ないシナリオで)、この情報が長期間にわたって役立つと思われる場合は、定期的なスナップショットを作成することを検討してください。