この投稿は、行の目標に関する一連の記事の一部です。ここで最初の部分を見つけることができます:
- パート1:行の目標の設定と特定
TOPを使用することは比較的よく知られています またはFAST n クエリヒントは、実行プランで行の目標を設定できます(行の目標とその原因について復習する必要がある場合は、実行プランでの行の目標の設定と識別を参照してください)。 TOPの場合よりも多少可能性は低いですが、半結合(および反結合)が行の目標も導入できることはあまり一般的ではありません。 、FAST 、およびSET ROWCOUNT 。
この記事は、セミジョインがオプティマイザーの行ゴールロジックを呼び出すタイミングと理由を理解するのに役立ちます。
半参加
半結合は、少なくとも1つある場合、1つの結合入力(A)から行を返します。 他の結合入力(B)の一致する行。
セミジョインと通常のジョインの本質的な違いは次のとおりです。
- 半結合は、入力Aから各行を返すか、返さないかのいずれかです。行の重複は発生しません。
- 結合述部に複数の一致がある場合、通常の結合は行を複製します。
- 半結合は、入力Aから列のみを返すように定義されています。
- 通常の結合は、いずれか(または両方)の結合入力から列を返す場合があります。
T-SQLは現在、FROM A SEMI JOIN B ON A.x = B.yのような直接構文をサポートしていません。 、したがって、EXISTSのような間接形式を使用する必要があります 、SOME/ANY (同等の省略形のINを含む 同等性の比較のために)、INTERSECTを設定します 。
上記の半結合の説明は、一致する行を見つけることに関心があるため、行の目標の適用を自然に示唆しています。 Bでは、そのようなすべての行ではありません 。それでも、T-SQLで表現された論理半結合は、いくつかの理由で行ゴールを使用した実行プランにつながらない場合があります。これについては次に解凍します。
変換と簡素化
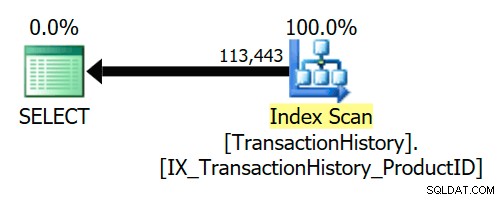
論理セミ結合は、クエリのコンパイルおよび最適化中に簡略化されるか、別のものに置き換えられる場合があります。以下のAdventureWorksの例は、信頼できる外部キー関係のために、半結合が完全に削除されていることを示しています。
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID IN
(
SELECT P.ProductID
FROM Production.Product AS P
);
外部キーは、Productを保証します 行は、履歴行ごとに常に存在します。その結果、実行プランはTransactionHistoryにのみアクセスします テーブル:
より一般的な例は、半結合を内部結合に変換できる場合に見られます。例:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.ProductInventory AS INV
WHERE INV.ProductID = P.ProductID
);
実行プランは、オプティマイザーが集約(INV.ProductIDでのグループ化)を導入したことを示しています )内部結合がProductのみを返すことができるようにするため 行を1回、またはまったく行わない(半結合のセマンティクスを保持するために必要な場合):
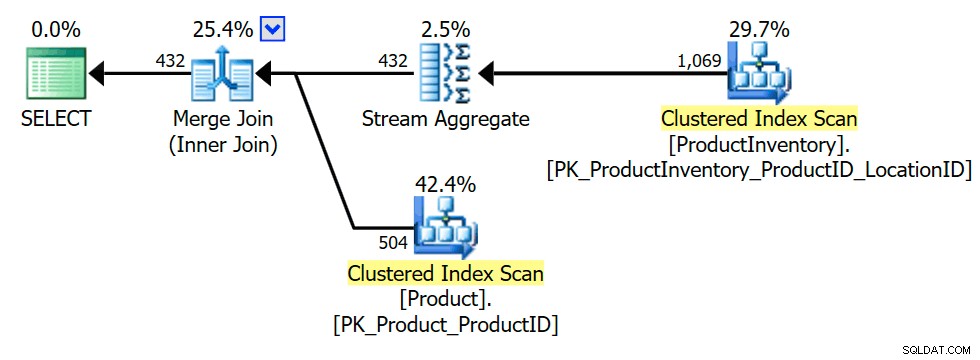
オプティマイザーは、セミジョインよりもインナーエクイジョインの方が多くのトリックを知っているため、内部結合への変換が早期に検討され、最適化の機会が増える可能性があります。当然のことながら、最終的な計画の選択は、検討された代替案の中から依然としてコストベースの決定です。
初期の最適化
T-SQLには直接のSEMI JOINがありませんが 構文では、オプティマイザは半結合についてすべてネイティブに認識しており、それらを直接操作できます。一般的な回避策の半結合構文は、クエリコンパイルプロセスの早い段階で「実際の」内部半結合に変換されます(些細な計画でさえ考慮されるかなり前に)。
2つの主な回避策の構文グループはEXISTS/INTERSECTです。 、およびANY/SOME/IN 。 EXISTS およびINTERSECT ケースが異なるのは、後者に暗黙のDISTINCTが付属しているという点だけです。 (投影されたすべての列でのグループ化)。両方のEXISTS およびINTERSECT EXISTSとして解析されます 相関サブクエリを使用します。 ANY/SOME/IN 表現はすべて、いくつかの操作として解釈されます。オプティマイザーアクティビティに関する情報を[SSMSメッセージ]タブに送信する、文書化されていないいくつかのトレースフラグを使用して、この最適化アクティビティを早期に調査できます。
たとえば、これまで使用してきた半結合は、INを使用して記述することもできます。 :
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.ProductID IN /* or = ANY/SOME */
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); オプティマイザの入力ツリーは次のとおりです。

スカラー演算子ScaOp_SomeComp SOMEです 上記の比較。 INであるため、2は同等性テストのコードです。 = SOMEと同等です 。興味がある場合は、それぞれ(<、=、<=、>、!=、> =)比較演算子を表す1から6までのコードがあります。
EXISTSに戻る 半結合を間接的に表現するために私が最も頻繁に使用する構文:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); オプティマイザの入力ツリーは次のとおりです。

そのツリーは、クエリテキストのかなり直接的な翻訳です。ただし、SELECT * すでに定数整数値1の射影に置き換えられています(テキストの最後から2行目を参照)。
オプティマイザが次に行うことは、ルール RemoveSubqInSel を使用して、リレーショナル選択(=フィルタ)のサブクエリをアンネストすることです。 。オプティマイザはサブクエリを直接操作できないため、常にこれを実行します。結果は適用です (別名、相関結合または横方向結合):

(同じサブクエリ削除ルールは、SOMEに対して同じ出力を生成します 入力ツリーも)。
次のステップは、 ApplyHandler を使用して、通常の結合として適用を書き直すことです。 ルールファミリー。これは、オプティマイザーが常に実行しようとすることです。これは、適用よりも結合の探索ルールが多いためです。すべての適用を結合として書き直すことができるわけではありませんが、現在の例は単純で成功しています:

結合のタイプはセミのままであることに注意してください。実際、これは、T-SQLが次のような構文をサポートしている場合にすぐに取得するツリーとまったく同じです。
SELECT P.ProductID
FROM Production.Product AS P
LEFT SEMI JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID; このようにクエリをより直接的に表現できるといいですね。とにかく、興味のある読者は、T-SQLでこの半結合を記述する他の論理的に同等の方法を使用して、上記の単純化アクティビティを検討することをお勧めします。
この段階での重要なポイントは、オプティマイザーが常にサブクエリを削除することです。 、それらを適用に置き換えます。次に、適切な計画を見つける可能性を最大化するために、通常の結合として適用を書き直そうとします。些細な計画でさえ考慮される前に、前述のすべてが行われることを忘れないでください。コストベースの最適化中に、オプティマイザーは結合変換を適用に戻すことも検討する場合があります。
ハッシュアンドマージセミジョイン
SQL Serverには、論理半結合に使用できる3つの主要な物理実装オプションがあります。等結合述語が存在する限り、ハッシュ結合とマージ結合を使用できます。どちらも左セミ結合モードと右セミ結合モードで動作できます。ネストされたループ結合は、左(右ではない)半結合のみをサポートしますが、等結合述部は必要ありません。サンプルクエリのハッシュとマージの物理オプションを見てみましょう(今回はセットが交差するように記述されています):
SELECT P.ProductID FROM Production.Product AS P INTERSECT SELECT TH.ProductID FROM Production.TransactionHistory AS TH;
オプティマイザーは、このクエリの(左/右)と(ハッシュ/マージ)の半結合の4つの組み合わせすべての計画を見つけることができます:
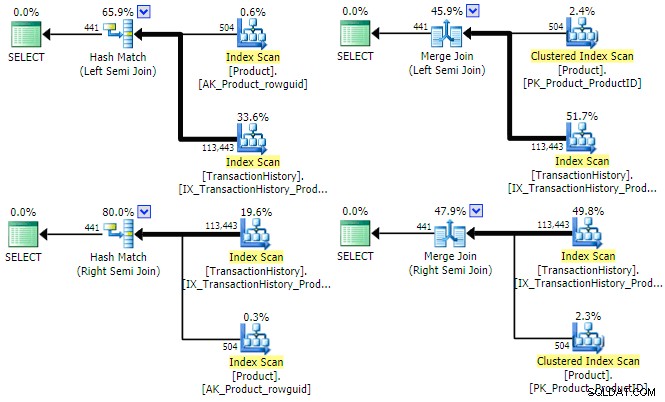
オプティマイザが各結合タイプに対して左と右の両方の半結合を考慮する理由を簡単に説明する価値があります。ハッシュ半結合の場合、主なコストの考慮事項は、ハッシュテーブルの推定サイズです。これは、最初は常に左側(上部)の入力です。マージ半結合の場合、各入力のプロパティによって、ワークテーブルとの1対多または効率の低い多対多のマージを使用するかどうかが決まります。
上記の実行計画から、行の目標を設定しても半結合のハッシュもマージもメリットがないことが明らかな場合があります。 。両方の結合タイプは、常に結合自体で結合述語をテストし、両方の入力からのすべての行を消費して完全な結果セットを返すことを目的としています。これは、一般にハッシュ結合とマージ結合のパフォーマンスの最適化が存在しないということではありません。たとえば、どちらもビットマップを利用して、結合に到達する行の数を減らすことができます。むしろ、重要なのは、どちらの入力の行の目標も、ハッシュまたはマージの半結合をより効率的にしないということです。
ネストされたループと半結合の適用
残りの物理結合タイプはネストされたループであり、通常の(相関のない)ネストされたループと適用の2つの種類があります。 ネストされたループ(相関とも呼ばれます または横 参加)。
通常のネストされたループの結合は、結合述語が結合で評価されるという点で、ハッシュおよびマージ結合に似ています。前と同じように、これはどちらの入力にも行の目標を設定することに価値がないことを意味します。左側(上部)の入力は常に最終的に完全に消費され、内部の入力では、述語が結合でテストされるまで行が結合するかどうかがわからないため、優先する行を決定する方法がありません。 。
対照的に、ネストされたループの適用結合には、1つ以上の外部参照があります (相関パラメーター)結合時に、結合述部がプッシュダウンされます 結合の内側(下)側。これは、行ゴールの有用なアプリケーションの機会を作成します。半結合では、結合入力Aの現在の行と一致する結合入力Bの行の存在を確認するだけでよいことを思い出してください(ネストされたループの結合戦略について考えてみてください)。
つまり、適用の各反復で、プッシュダウンされた結合述語を使用して、最初の一致が見つかるとすぐに入力Bの表示を停止できます。これはまさに、行の目標が適している種類のことです。最初のn個の一致する行をすばやく返すように最適化された計画の一部を生成します(n = 1 ここに)。
もちろん、状況に応じて、行の目標は良いことでも悪いことでもあります。その点で、セミジョイン行の目標について特別なことは何もありません。半結合の内側が単一の単純なテーブルアクセス、おそらく複数テーブル結合よりも複雑である状況を考えてみてください。行の目標を設定すると、オプティマイザーがその特定のサブツリーに対してのみ効率的なナビゲーション戦略を選択するのに役立ちます。 、ネストされたループ結合とインデックスシークを介して半結合を満たす最初の一致する行を検索します。行の目標がない場合、オプティマイザーは当然、ハッシュを選択するか、結合を並べ替えでマージして、可能なすべての行を返すための予想コストを最小限に抑えることができます。ここには、検索条件に一致する行が実際に存在することを期待して、通常、半結合を作成するという仮定があることに注意してください。これは私には十分に公正な仮定のようです。
とにかく、この段階での重要なポイントは次のとおりです。適用するのはのみ ネストされたループの結合には行の目標があります オプティマイザーによって適用されます(ただし、ネストされたループの結合を適用するための行の目標は、行の目標がそれがない場合の見積もりよりも小さい場合にのみ追加されます)。次に、これらすべてを明確にするために、いくつかの実例を見ていきます。
ネストされたループの半結合の例
次のスクリプトは、2つのヒープ一時テーブルを作成します。 1つ目は1から20までの数字です。もう1つは、最初の表に各番号のコピーが10個あります:
DROP TABLE IF EXISTS #E1, #E2;
CREATE TABLE #E1 (c1 integer NULL);
CREATE TABLE #E2 (c1 integer NULL);
INSERT #E1 (c1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 20;
INSERT #E2 (c1)
SELECT
(SV.number % 20) + 1
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 200; インデックスがなく、行数が比較的少ない場合、オプティマイザーは、次の半結合クエリに対して(ハッシュまたはマージではなく)ネストされたループの実装を選択します。文書化されていないトレースフラグを使用すると、オプティマイザの出力ツリーと行の目標情報を確認できます。
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
推定実行プランは、テーブル#E2のフルスキャンごとに200行の半結合ネストループ結合を特徴としています。 。ループを20回繰り返すと、合計で4,000行の見積もりが得られます。
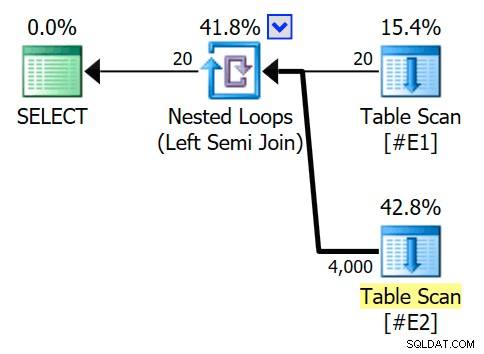
ネストされたループ演算子のプロパティは、述語が結合時に適用されることを示しています。 これは、相関のないネストされたループの結合であることを意味します :
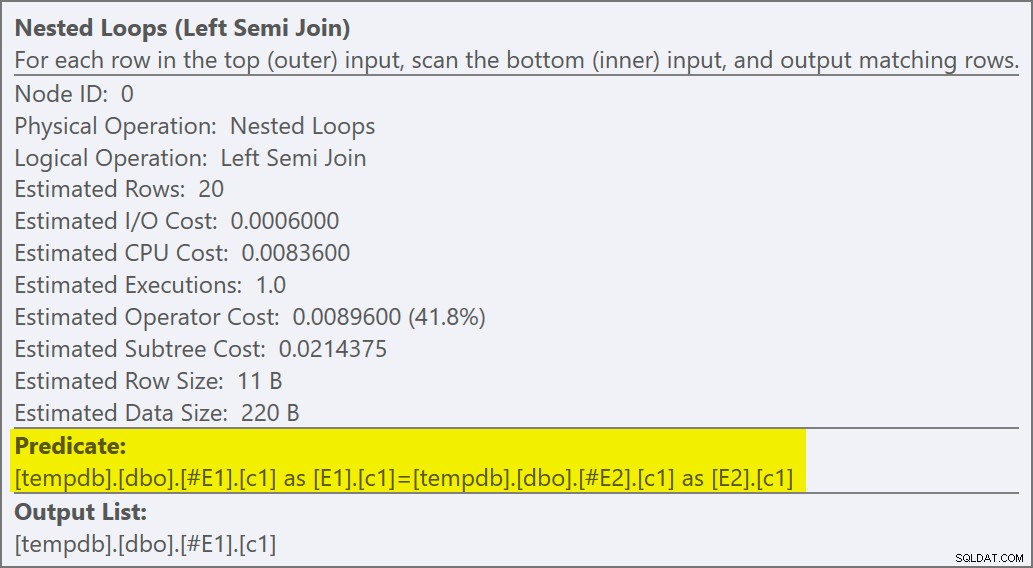
トレースフラグの出力([SSMSメッセージ]タブ)には、ネストされたループの半結合が表示され、行の目標はありません(RowGoal 0):

このおもちゃのクエリの実行後の計画では、テーブル#E2から読み取られた合計4,000行が表示されないことに注意してください。ネストされたループの半結合(相関しているかどうかに関係なく)は、現在の外側の行の最初の一致が検出されるとすぐに、(反復ごとに)内側の行の検索を停止します。現在、各反復で#E2のヒープスキャンから検出される行の順序は非決定的であるため(反復ごとに異なる場合があります)、原則として 一致する行が可能な限り遅く検出された場合(または、一致する行がない場合はまったく検出されない場合)、ほとんどすべての行を各反復でテストできます。
たとえば、行が毎回同じ順序(「挿入順序」など)でスキャンされるランタイム実装を想定すると、このおもちゃの例でスキャンされる行の総数は、最初の反復で20行、1行になります。 2回目の反復では2行、3回目の反復では2行というように、合計20 + 1 + 2 +(…)+ 19=210行になります。実際、この合計を観察する可能性は非常に高く、他の何よりも単純なデモンストレーションコードの制限について詳しく説明しています。順序付けされていないアクセスメソッドから返される行の順序に依存することはできません。トップレベルのORDER BYがなくても、クエリからの明らかに順序付けられた出力に依存することができます。 条項。
セミジョインを適用
ここで、より大きなテーブルに非クラスター化インデックスを作成し(オプティマイザーが半結合の適用を選択するように促すため)、クエリを再実行します:
CREATE NONCLUSTERED INDEX nc1 ON #E2 (c1);
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612); 実行プランは、インデックスシークごとに1行(および以前と同様に20回の反復)の適用半結合を備えています。
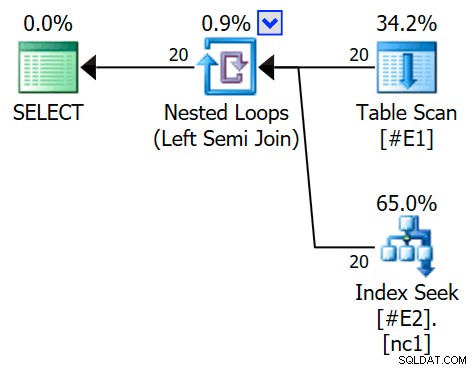
セミジョインを適用であることがわかります 結合プロパティには外部参照が表示されるためです 結合述語ではなく:
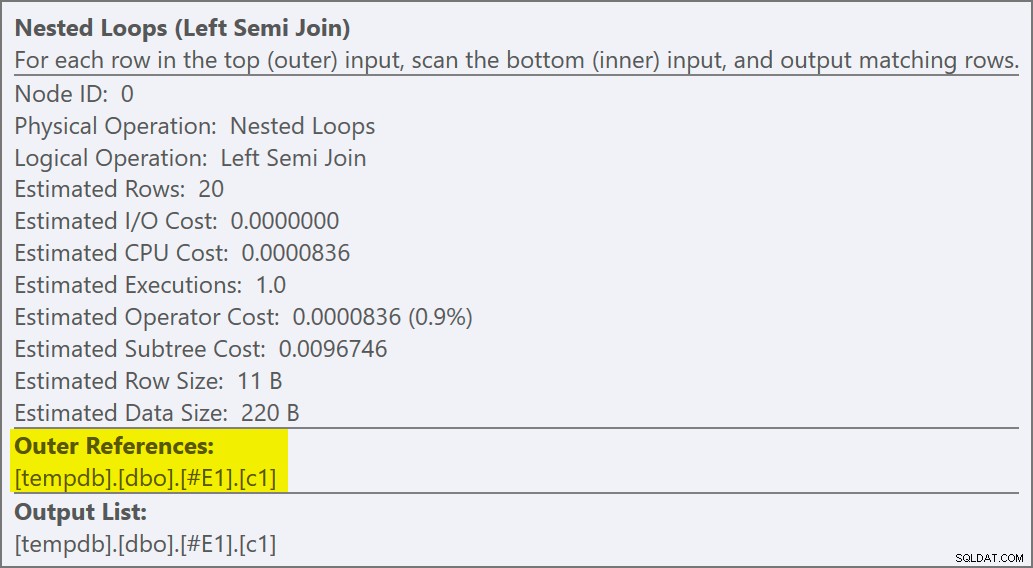
結合述語がプッシュダウンされました 適用の内側で、新しいインデックスに一致します:
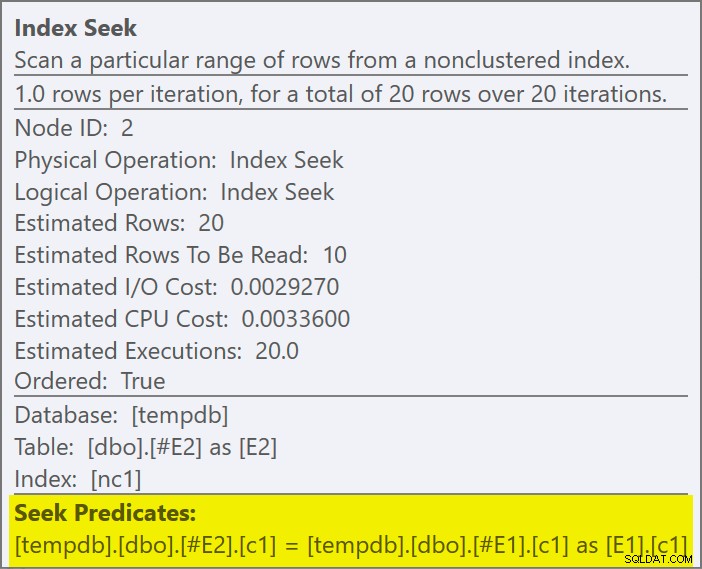
各値がそのテーブルで10回複製されているにもかかわらず、各シークは1行を返すことが期待されます。これは行の目標の効果です 。行の目標は、 EstimateRowsWithoutRowGoalを公開するSQLServerビルドで簡単に識別できます。 計画属性(執筆時点ではSQL Server 2017 CU3)。 Plan Explorerの今後のバージョンでは、これは関連するオペレーターのツールチップにも表示されます:

トレースフラグの出力は次のとおりです。
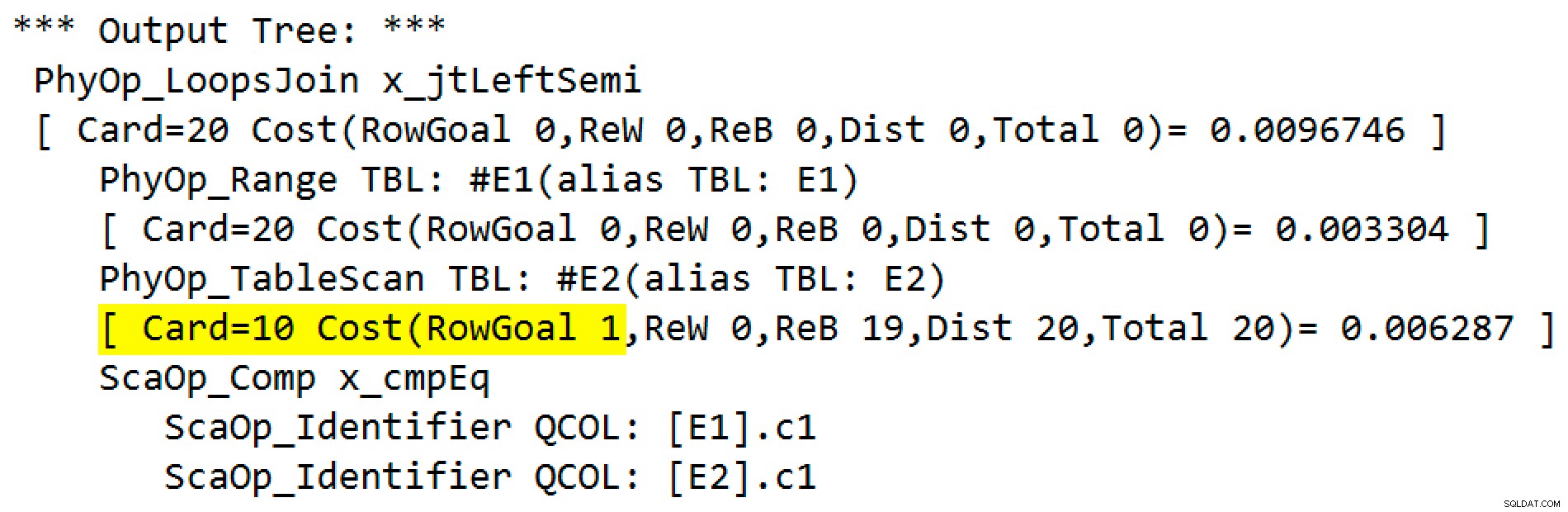
物理演算子は、ループ結合から左半結合モードで実行される適用に変更されました。テーブル#E2へのアクセス 行ゴール1を取得しました(行ゴールのないカーディナリティは10として表示されます)。この場合、行の目標は大きな問題ではありません。これは、シークごとに推定10行を取得するコストが、1行の場合よりもはるかに高くないためです。このクエリの行の目標を無効にする(トレースフラグ4138またはDISABLE_OPTIMIZER_ROWGOALを使用) クエリヒント)は計画の形を変えません。
それにもかかわらず、より現実的なクエリでは、内側の行の目標によるコスト削減が、競合する実装オプション間の違いを生む可能性があります。たとえば、行の目標を無効にすると、オプティマイザが代わりにハッシュを選択するか、半結合をマージするか、クエリで考慮される他の多くのオプションのいずれかを選択する可能性があります。他に何もないとしても、ここでの行の目標は、最初の一致が見つかるとすぐに半結合の適用が内側の検索を停止し、次の外側の行に移動するという事実を正確に反映しています。
テーブル#E2に重複が作成されていることに注意してください そのため、半結合行の適用目標(1)は、通常の推定値(10、統計密度情報から)よりも低くなります。重複がなかった場合、各シークの行の見積もりは#E2になります また、1行になるため、1行の目標は適用されません(これに関する一般的なルールを覚えておいてください)
行の目標と上位
実行プランがSQLServer2017 CU3より前の行の目標の存在をまったく示していないことを考えると、行の目標のような非表示のプロパティではなく、明示的なTop演算子を使用してこの最適化を実装する方が明確だったと思うかもしれません。アイデアは、結合自体に行の目標を設定するのではなく、適用セミ/アンチ結合の内側にトップ(1)演算子を配置することです。
このようにTop演算子を使用することは、前例がまったくないわけではありません。たとえば、ゼロ以外のSET ROWCOUNTの場合、データ変更実行プランで見られる行数トップと呼ばれる特別なバージョンのトップがすでに存在します。 有効です(SQL Server 2017では引き続き許可されていますが、この特定の使用法は2005年以降廃止されていることに注意してください)。行数topの実装は、実際の行数制限が有効であるかどうかに関係なく、実行プランでtop演算子が常にTop(0)として表示されるという点で少し不格好です。
半結合行の適用の目標を明示的なTop(1)演算子に置き換えることができなかったという説得力のある理由はありません。とはいえ、優先する理由はいくつかあります。 そうしないでください:
- 明示的なTop(1)を追加するには、行の目標(他の目的ですでに使用されている)を追加するよりも、オプティマイザーのコーディング作業とテストが必要です。
- Topは関係演算子ではありません。オプティマイザは、それについて推論するためのサポートをほとんど持っていません。これは、クエリプランの一部を変換するオプティマイザの機能を制限することにより、プランの品質に悪影響を与える可能性があります。アグリゲート、ユニオン、フィルター、および結合を移動します。
- セミジョインの適用実装とトップの間に緊密な結合が導入されます。特殊なケースと密結合は、バグを導入し、将来の変更をより困難にし、エラーが発生しやすいようにするための優れた方法です。
- トップ(1)は論理的に冗長であり、行ゴールの副作用のためにのみ存在します。
その最後のポイントは、例を挙げて拡張する価値があります:
SELECT
P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
);
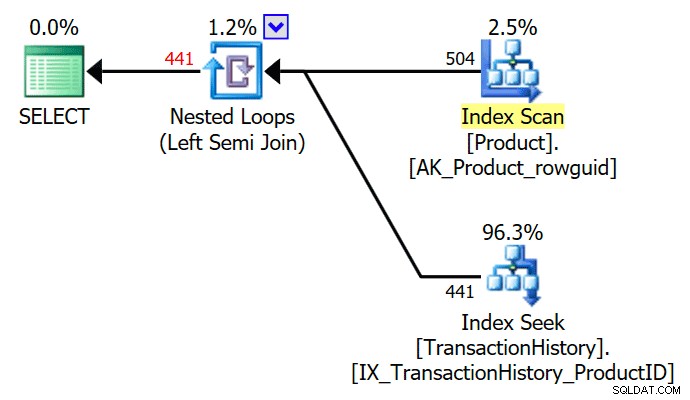
TOP (1) 既存のサブクエリでは、オプティマイザによって単純化され、単純な半結合実行プランが提供されます。
オプティマイザーは、冗長なDISTINCTを削除することもできます またはGROUP BY サブクエリで。以下はすべて、上記と同じ計画を作成します。
-- Redundant DISTINCT
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
);
-- Redundant GROUP BY
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
GROUP BY TH.ProductID
);
-- Redundant DISTINCT TOP (1)
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); まとめと最終的な考え
適用のみ ネストされたループの半結合では、オプティマイザーによって行の目標を設定できます。これは、結合述語を結合からプッシュダウンする唯一の結合タイプであり、一致の存在を早期にテストできるようにします。 。相関のないネストされたループは、ほとんどありません*半結合します 行の目標を設定し、ハッシュまたはマージの半結合も行いません。ネストされたループの適用は、外部参照の存在によって、相関のないネストされたループの結合と区別できます。 (述語の代わりに)ネストされたループで、applyの演算子を結合します。
最終的な実行プランでアプライセミジョインが表示される可能性は、初期の最適化アクティビティに多少依存します。直接的なT-SQL構文がないため、半結合を間接的な用語で表現する必要があります。これらはサブクエリを含む論理ツリーに解析され、初期のオプティマイザアクティビティは適用に変換され、可能な場合は相関のない半結合に変換されます。
この単純化アクティビティは、論理半結合が適用または通常の半結合としてコストベースのオプティマイザに提示されるかどうかを決定します。論理的な適用として提示された場合 セミジョインの場合、CBOは、ネストされたループを物理的に適用することを特徴とする最終的な実行プランを作成することはほぼ確実です(したがって、行の目標を設定します)。相関のないセミジョインが提示された場合、CBOは 適用への変換を検討してください(またはそうでない場合もあります)。計画の最終的な選択は、通常どおり一連のコストベースの決定です。
すべての行の目標と同様に、半結合の行の目標は、パフォーマンスにとって良いことでも悪いことでもあります。セミジョインを適用すると行の目標が設定されることを知っていると、問題が発生した場合に、少なくとも人々が原因を認識して対処するのに役立ちます。解決策は、常に(または通常でも)クエリの行の目標を無効にすることではありません。インデックス作成(および/またはクエリ)の改善は、最初に一致する行を見つけるための効率的な方法を提供するために行われることがよくあります。
アンチセミジョインについては別の記事で取り上げ、行の目標シリーズを続けます。
*例外は、結合述語のない、相関のないネストされたループの半結合です(珍しい光景)。これは行の目標を設定します。