前回の投稿では、少量の場合、メモリ最適化TVPが一般的なクエリパターンに大幅なパフォーマンス上の利点をもたらすことができることを示しました。
少し高いスケールでテストするために、SalesOrderDetailEnlargedのコピーを作成しました Jonathan Kehayias(ブログ| @SQLPoolBoy)によるこのスクリプトのおかげで、約5,000,000行に拡張したテーブル。
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
また、このテーブルの3つのメモリ内バージョンを作成しました。それぞれ、バケット数が異なります(「スイートスポット」の釣り)– 16,384、131,072、および1,048,576。 (より丸い数値を使用することもできますが、とにかく2の次の累乗に切り上げられます。)例:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
前の例(256)からバケットサイズを変更したことに注意してください。テーブルを作成するときは、バケットサイズの「スイートスポット」を選択する必要があります。ポイントルックアップのハッシュインデックスを最適化する必要があります。つまり、各バケットの行をできるだけ少なくして、できるだけ多くのバケットが必要です。もちろん、最大500万個のバケットを作成する場合(この場合、おそらくあまり良い例ではないため、最大500万個の値の一意の組み合わせがあります)、メモリ使用率とガベージコレクションのトレードオフに対処する必要があります。ただし、最大500万の一意の値を256個のバケットに詰め込もうとすると、いくつかの問題も発生します。いずれにせよ、この議論はこの投稿の私のテストの範囲をはるかに超えています。
標準テーブルに対してテストするために、以前のテストと同様のストアドプロシージャを作成しました。
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO したがって、最初に、たとえば1,000行がテーブル変数に挿入され、次にプロシージャを実行するための計画を確認します。
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
今回は、どちらの場合も、オプティマイザーがベーステーブルに対してクラスター化インデックスシークを選択し、ネストされたループがTVPに対して結合していることがわかります。一部の原価計算指標は異なりますが、それ以外の点では計画は非常に似ています:
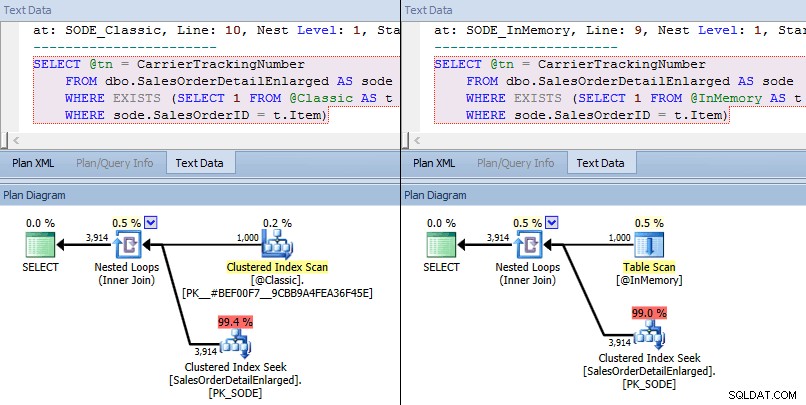 インメモリTVPと従来のTVPの大規模な同様の計画>
インメモリTVPと従来のTVPの大規模な同様の計画>
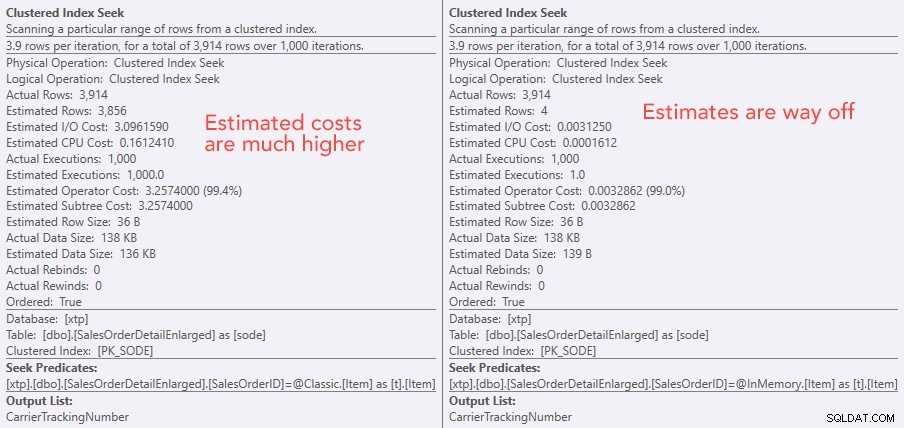 シークオペレーターのコストの比較–左側がクラシック、右側がインメモリ
シークオペレーターのコストの比較–左側がクラシック、右側がインメモリ
コストの絶対値により、従来のTVPはインメモリTVPよりもはるかに効率が悪いように見えます。しかし、これが実際に当てはまるのではないかと思ったので(特に、右側の推定実行数の数値が疑わしいと思われたため)、もちろん、いくつかのテストを実行しました。プロシージャに送信する100、1,000、および2,000の値を確認することにしました。
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
パフォーマンスの結果は、ポイントルックアップの数が多い場合、インメモリTVPを使用すると収穫逓減がわずかに減少し、毎回わずかに遅くなることを示しています。
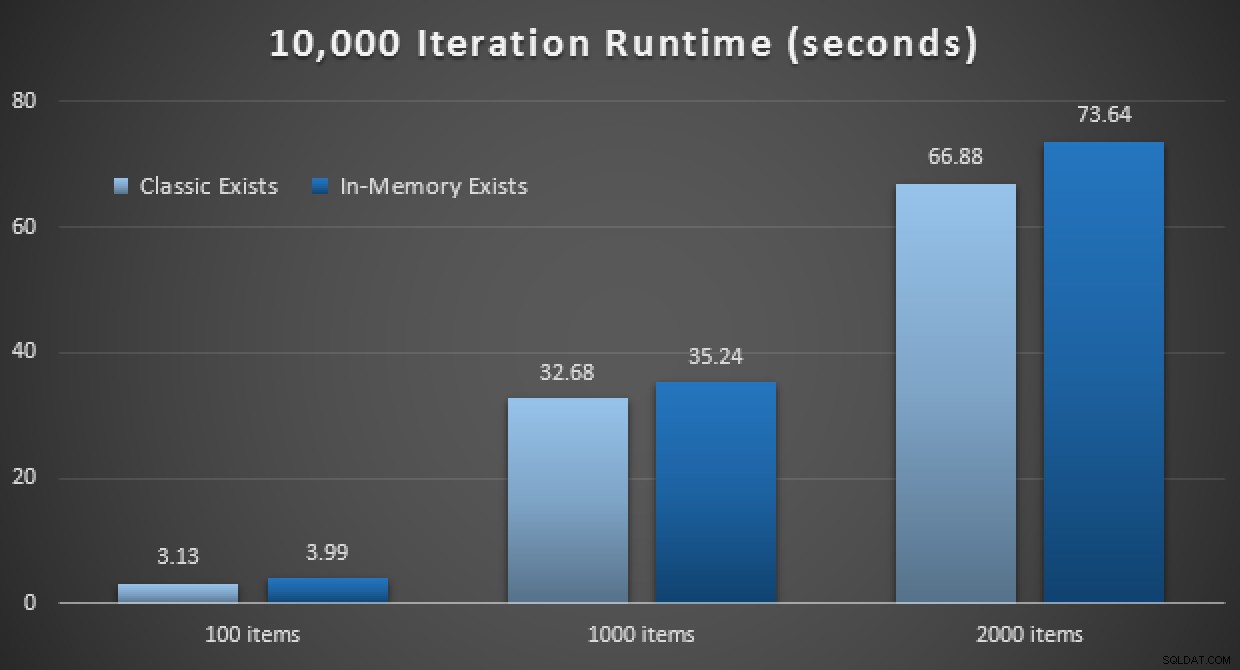
したがって、以前の投稿から得た印象とは異なり、メモリ内TVPを使用することが必ずしもすべての場合に有益であるとは限りません。
以前、ネイティブにコンパイルされたストアドプロシージャとインメモリテーブルを、インメモリTVPと組み合わせて調べました。これはここで違いを生むことができますか?ネタバレ:絶対にありません。このような3つの手順を作成しました:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO 別のネタバレ:反復回数10,000でこれらの9つのテストを実行できませんでした–時間がかかりすぎました。代わりに、ループして各手順を10回実行し、その一連のテストを10回実行して、平均を取りました。結果は次のとおりです。
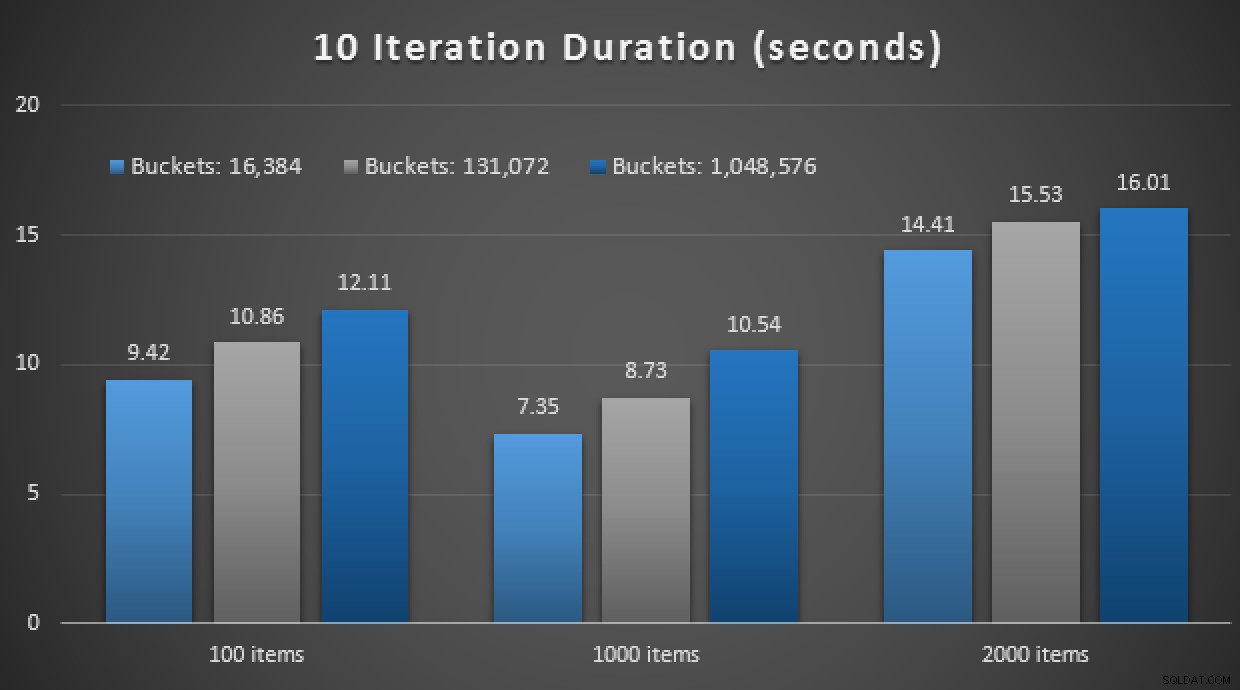
メモリ内TVPを使用し、ネイティブにコンパイルされたストアドを使用した10回の実行の結果手順
全体として、この実験はかなり残念でした。ディスク上のテーブルを使用して、違いの大きさを見るだけで、平均的なストアドプロシージャの呼び出しは平均0.0036秒で完了しました。ただし、すべてがメモリ内テクノロジを使用している場合、平均のストアドプロシージャ呼び出しは1.1662秒でした。 痛い 。全体的なデモに不適切なユースケースを選択した可能性が高いですが、当時は直感的な「最初の試み」のようでした。
結論
このシナリオを回避するためにテストすることはまだたくさんあり、フォローするブログ投稿がもっとあります。インメモリTVPの大規模な最適な使用例はまだ特定していませんが、この投稿が、ある場合には解決策が最適であるように見えても、それが同等に適用可能であると想定するのは決して安全ではないことを思い出させてくれることを願っています。さまざまなシナリオに。これはまさにインメモリOLTPへのアプローチ方法です。本番環境に実装する前に絶対に検証する必要がある一連のユースケースを含むソリューションとして。