実稼働環境で発生する可能性のあるすべての問題を回避するための完全なシステム、ハードウェア、またはトポロジーはありません。これらの課題を克服するには、アプリケーション、インフラストラクチャ、およびビジネス要件に従って構成された効果的なDRP(災害復旧計画)が必要です。このような状況で成功するための鍵は、常に問題を修正または回復できる速度です。
このブログでは、最も一般的なPostgreSQLの障害シナリオを見て、問題を解決または対処する方法を示します。また、ClusterControlがオンラインに戻るのにどのように役立つかについても見ていきます
一般的な障害シナリオを理解するには、最初に一般的なPostgreSQLトポロジから始める必要があります。これは、レプリカが接続されているPostgreSQLプライマリノードに接続されている任意のアプリケーションです。
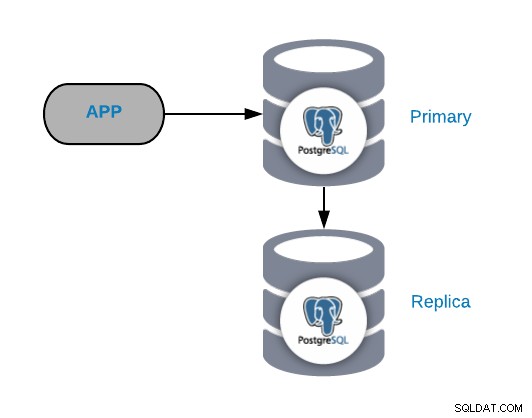
ノードまたはロードバランサーを追加することで、このトポロジをいつでも改善または拡張できます。 、ただし、これが作業を開始する基本的なトポロジです。
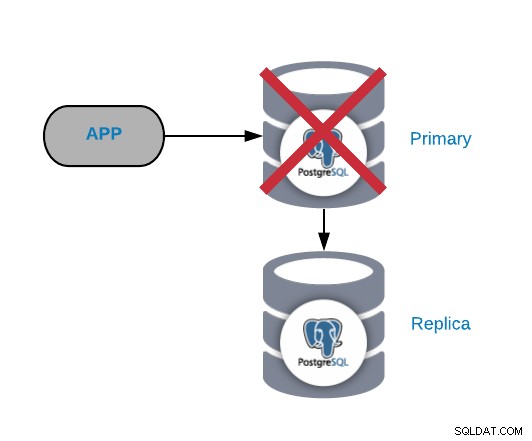
これは、次の場合にできるだけ早く修正する必要があるため、最も重大な障害の1つです。システムをオンラインに保ちたいのです。このタイプの障害の場合、何らかの自動フェイルオーバーメカニズムを導入することが重要です。失敗した後、問題の理由を調べることができます。フェイルオーバープロセスの後、障害が発生したプライマリノードがまだプライマリノードであるとは考えていないことを確認します。これは、書き込み時にデータの不整合を回避するためです。
この種の問題の最も一般的な原因は、オペレーティングシステムの障害、ハードウェアの障害、またはディスクの障害です。いずれの場合も、データベースとオペレーティングシステムのログを確認して理由を見つける必要があります。
この問題の最速の解決策は、フェイルオーバータスクを実行してダウンタイムを短縮することです。レプリカをプロモートするには、スレーブデータベースノードでpg_ctl Promoteコマンドを使用できます。次に、新しいプライマリノードへのアプリケーション。この最後のタスクでは、アプリケーションとデータベースノードの間にロードバランサーを実装して、障害が発生した場合にアプリケーション側からの変更を回避できます。また、ノードの障害を検出し、トラフィックをロードバランサーに送信する代わりに、新しいプライマリノードにトラフィックを送信するようにロードバランサーを構成することもできます。
フェイルオーバープロセスの後、システムが再び機能していることを確認したら、問題を調査できます。常に少なくとも1つのスレーブノードを機能させ続けることをお勧めします。したがって、新しいプライマリ障害が発生した場合は、フェイルオーバータスクを再度実行できます。
PostgreSQLレプリカノードの障害
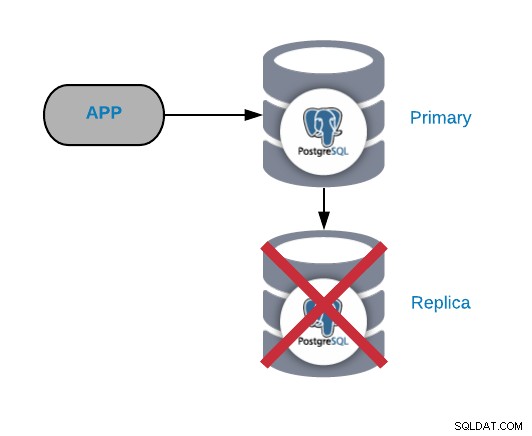
これは通常、重大な問題ではありません( 1つのレプリカであり、読み取り本番トラフィックの送信に使用していません)。プライマリノードで問題が発生していて、レプリカが最新でない場合は、実際に重大な問題が発生します。レポートやビッグデータの目的でレプリカを使用している場合は、とにかくすぐに修正することをお勧めします。
この種の問題の最も一般的な原因は、プライマリノード、オペレーティングシステムの障害、ハードウェアの障害、またはディスクの障害で見られたものと同じです。データベースとオペレーティングシステムのログを確認する必要があります。理由を見つけるために。
レプリカなしでシステムを動作させ続けることはお勧めしません。障害が発生した場合、オンラインにすばやく戻る方法がないためです。スレーブが1つしかない場合は、問題をできるだけ早く解決する必要があります。最速の方法は、新しいレプリカを最初から作成することです。このためには、一貫性のあるバックアップを取り、それをスレーブノードに復元してから、このスレーブノードとプライマリノード間のレプリケーションを構成する必要があります。
失敗の理由を知りたい場合は、別のサーバーを使用して新しいレプリカを作成し、古いレプリカを調べてそれを見つける必要があります。このタスクを完了したら、古いレプリカを再構成して、両方を将来のフェイルオーバーオプションとして機能させ続けることもできます。
レプリカをレポートまたはビッグデータの目的で使用している場合は、新しいアドレスに接続するためにIPアドレスを変更する必要があります。前の場合と同様に、この変更を回避する1つの方法は、各サーバーのステータスを認識するロードバランサーを使用して、必要に応じてレプリカを追加/削除できるようにすることです。
PostgreSQLレプリケーションの失敗
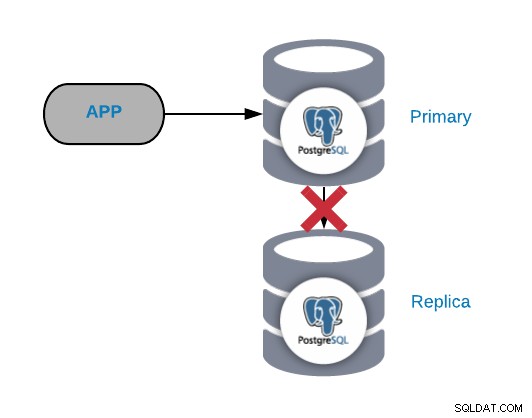
一般に、この種の問題はネットワークまたは構成が原因で発生します問題。これは、プライマリノードでのWAL(ログ先行書き込み)の損失と、PostgreSQLがレプリケーションを管理する方法に関連しています。
重要なトラフィックがある場合は、チェックポイントを頻繁に実行しているか、WALSを数分間しか保存していません。ネットワークの問題がある場合、それを解決する時間はほとんどありません。 WALは、送信してレプリカに適用する前に削除されます。
レプリカが機能し続けるために必要なWALが削除された場合は、再構築する必要があるため、このタスクを回避するには、データベース構成を確認してwal_keep_segments(保持するWALSの量)を増やす必要があります。 pg_xlogディレクトリ)またはmax_wal_senders(同時に実行されているWAL送信者プロセスの最大数)パラメータ。
もう1つの推奨オプションは、archive_modeをオンに構成し、パラメーターarchive_commandを使用してWALファイルを別のパスに送信することです。このように、PostgreSQLが制限に達してWALファイルを削除した場合でも、とにかく別のパスに配置されます。
PostgreSQLデータの破損/データの不整合/偶発的な削除

これは、DBAにとって悪夢であり、おそらく最も複雑な問題です。問題の広がり具合に応じて修正されました。
データがこれらの問題のいくつかの影響を受ける場合、それを修正する最も一般的な方法(そしておそらく唯一の方法)は、バックアップを復元することです。そのため、バックアップは災害復旧計画の基本的な形式であり、物理的に異なる場所に少なくとも3つのバックアップを保存することをお勧めします。ベストプラクティスでは、バックアップファイルの1つをデータベースサーバーにローカルに保存し(リカバリを高速化するため)、もう1つを集中バックアップサーバーに保存し、最後のファイルをクラウドに保存する必要があります。
完全/増分/差分PITR互換バックアップを組み合わせて作成し、目標復旧時点を短縮することもできます。
ClusterControlを使用したPostgreSQL障害の管理
これらの一般的なPostgreSQL障害シナリオを確認したので、集中型データベース管理システムからPostgreSQLデータベースを管理した場合にどうなるかを見てみましょう。障害が発生した場合に、問題を迅速かつ簡単に修正する方法、ASAPに到達するという点で優れています。
ClusterControlは、上記のほとんどのPostgreSQLタスクの自動化を提供します。すべて一元化されたユーザーフレンドリーな方法で。このシステムを使用すると、手動で時間と労力を要するものを簡単に構成できます。ここで、PostgreSQLの障害シナリオに関連する主な機能のいくつかを確認します。
PostgreSQLクラスターのデプロイ/インポート
ClusterControlインターフェースに入ったら、最初に行うことは、新しいクラスターをデプロイするか、既存のクラスターをインポートすることです。展開を実行するには、[データベースクラスターの展開]オプションを選択し、表示される指示に従います。
PostgreSQLクラスターのスケーリング
クラスターアクションに移動し、[レプリケーションスレーブの追加]を選択すると、新しいレプリカを最初から作成するか、既存のPostgreSQLデータベースをレプリカとして追加できます。このようにして、新しいレプリカを数分で実行でき、必要な数のレプリカを追加できます。ロードバランサー(ClusterControlでも実装できます)を使用して、読み取りトラフィックをそれらの間で分散します。
PostgreSQL自動フェイルオーバー
ClusterControlは、レプリケーション設定のフェイルオーバーを管理します。マスターの障害を検出し、最新のデータを持つスレーブを新しいマスターとして昇格させます。また、残りのスレーブを自動的にフェイルオーバーして、新しいマスターから複製します。クライアント接続に関しては、タスクにHAProxyとKeepalivedの2つのツールを利用します。
HAProxyは、1つの発信元から1つ以上の宛先にトラフィックを分散し、タスクの特定のルールやプロトコルを定義できるロードバランサーです。いずれかの宛先が応答を停止すると、オフラインとしてマークされ、トラフィックは使用可能な宛先の1つに送信されます。これにより、トラフィックがアクセスできない宛先に送信されたり、有効な宛先に転送されてこの情報が失われたりするのを防ぐことができます。
Keepalivedを使用すると、サーバーのアクティブ/パッシブグループ内に仮想IPを構成できます。この仮想IPは、アクティブな「メイン」サーバーに割り当てられます。このサーバーに障害が発生した場合、IPはパッシブであることが判明した「セカンダリ」サーバーに自動的に移行され、システムに対して透過的な方法で同じIPを引き続き使用できるようになります。
PostgreSQLロードバランサーの追加
クラスターアクションに移動し、[ロードバランサーの追加]を選択すると(またはクラスタービューから[管理]-> [ロードバランサー]に移動)、データベーストポロジにロードバランサーを追加できます。
PostgreSQLバックアップ
3つの異なるバックアップ方法、pgdump、pg_basebackup、またはpgBackRestから選択できます。バックアップを保存する場所(データベースサーバー、ClusterControlサーバー、またはクラウド)、圧縮レベル、必要な暗号化、および保持期間を指定することもできます。
PostgreSQLの監視とアラート
アクションを実行する前に、何が起こっているかを知る必要があるため、データベースクラスターを監視する必要があります。 ClusterControlを使用すると、サーバーをリアルタイムで監視できます。 CPU、ネットワーク、ディスク、RAM、IOPSなどの基本データと、PostgreSQLインスタンスから収集されたデータベース固有のメトリックを含むグラフがあります。データベースクエリは、クエリモニターからも表示できます。
ClusterControlからの監視を有効にするのと同じ方法で、クラスター内のイベントを通知するアラートを設定することもできます。これらのアラートは構成可能であり、必要に応じてパーソナライズできます。
最終的には、全員がPostgreSQLの問題と障害に対処する必要があります。また、この問題を回避することはできないため、できるだけ早く修正してシステムを稼働させ続ける必要があります。また、ClusterControlを使用するとこれらの問題にどのように役立つかについても説明しました。すべて単一のユーザーフレンドリーなプラットフォームから。
これらは、PostgreSQLの最も一般的な障害シナリオの一部であると私たちが考えたものです。あなた自身の経験とそれをどのように修正したかについて聞いてみたいです。