実行計画は、重要なクエリのパフォーマンスを向上させる方法を特定するのに役立つ豊富な情報源を提供します。人々は、潜在的なデータアクセスパスの最適化を特定する方法として、大規模なスキャンやルックアップなどを探すことがよくあります。これらの問題は、多くの場合、新しいインデックスを作成するか、既存のインデックスをより多くの列を含めて拡張することで、すばやく解決できます。
実行後のプランを使用して、プランオペレーター間で実際の行数と予想される行数を比較することもできます。これらが大幅に分散していることがわかった場合、既存の統計を更新するか、新しい統計オブジェクトを作成するか、計算列の統計を利用するか、複雑なクエリをより複雑でないコンポーネントに分割することで、オプティマイザーにより良い統計情報を提供することができます。パーツ。
それ以外にも、プラン内の高価な操作、特に並べ替えやハッシュなどのメモリを消費する操作を確認できます。インデックスの変更により、並べ替えを回避できる場合があります。また、特定の目的の順序を保持するプランを優先する構文を使用してクエリをリファクタリングする必要がある場合もあります。
これらのパフォーマンス調整手法をすべて適用した後でも、パフォーマンスが十分でない場合があります。考えられる次のステップは、計画全体についてもう少し考えることです。 。これは、一歩下がって、クエリオプティマイザによって選択された全体的な戦略を理解し、アルゴリズムの改善を特定できるかどうかを確認することを意味します。
この記事では、適度に大きなデータセットで一意の列値を見つけるという簡単な問題の例を使用して、この後者のタイプの分析について説明します。類似の実際の問題でよくあることですが、対象の列には、テーブルの行数と比較して、一意の値が比較的少なくなります。この分析には、サンプルデータの作成と、個別の値のクエリ自体の記述という2つの部分があります。
サンプルデータの作成
考えられる最も単純な例を提供するために、テストテーブルにはクラスター化インデックスを持つ単一の列があります(この列は重複する値を保持するため、インデックスを一意と宣言することはできません):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
空中からいくつかの数値を選択するために、1,000万行をロードすることを選択します 合計で、千の異なる値に均等に分布します 。このようなデータを生成する一般的な手法は、いくつかのシステムテーブルを相互結合し、ROW_NUMBERを適用することです。 働き。また、モジュロ演算子を使用して、生成される数値を目的の個別の値に制限します。
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); そのクエリの推定実行プランは次のとおりです(必要に応じて画像をクリックして拡大します):

これには約30秒かかります ラップトップでサンプルデータを作成します。それは決して長い時間ではありませんが、このプロセスをより効率的にするために私たちが何をすることができるかを考えることは依然として興味深いです…
計画分析
まず、計画の各操作の目的を理解することから始めます。
セグメント演算子の右側にある実行プランのセクションは、システムテーブルを相互結合することによる行の製造に関係しています。

ウィンドウ関数にPARTITION BYがあった場合に備えて、Segment演算子があります。 句。ここではそうではありませんが、とにかくクエリプランに含まれています。 Sequence Projectオペレーターは行番号を生成し、Topはプランの出力を1,000万行に制限します。

Compute Scalarは、モジュロ関数を適用する式を定義し、結果に1を追加します。

PlanExplorerの[Expressions]タブを使用して、SequenceProjectとComputeScalarの式ラベルがどのように関連しているかを確認できます。

これにより、この計画のフローをより完全に把握できます。シーケンスプロジェクトは行に番号を付け、式Expr1050にラベルを付けます。; Compute Scalarは、モジュロ計算とプラス1計算の結果にExpr1052というラベルを付けます。 。 ComputeScalar式の暗黙の変換にも注意してください。宛先テーブルの列は整数型ですが、ROW_NUMBER 関数はbigintを生成するため、変換を絞り込む必要があります。
プランの次の演算子はソートです。クエリオプティマイザのコスト見積もりによると、これは最もコストのかかる操作であると予想されます(88.1%見積もり ):

クエリには明示的な順序付けの要件がないため、このプランが並べ替えを備えている理由はすぐにはわかりません。ソートがプランに追加され、行がクラスター化インデックスの挿入演算子にクラスター化インデックスの順序で確実に到着するようになります。これにより、順次書き込みが促進され、ページ分割が回避され、ログが最小限に抑えられるINSERTの前提条件の1つになります。 操作。
これらはすべて潜在的に良いものですが、ソート自体はかなり高価です。実際、実行後(「実際の」)実行プランを確認すると、Sortも実行時にメモリを使い果たし、物理的な tempdbに流出する必要があったことがわかります。 ディスク:

ソートスピルは、推定行数が正確に正しいにもかかわらず、クエリに要求されたすべてのメモリが付与されているにもかかわらず発生します(ルートINSERTのプランプロパティに表示されます)。 ノード):

並べ替えの流出は、IO_COMPLETIONの存在によっても示されます Plan Explorer PROの待機統計タブで待機します:

最後に、この計画分析セクションでは、DML Request Sortに注目してください。 Clustered Index Insert演算子のプロパティがtrueに設定されています:

このフラグは、オプティマイザがインデックスキーの並べ替え順序で行を提供するために、挿入の下のサブツリーを必要とすることを示します(したがって、問題のある並べ替え演算子が必要です)。
並べ替えの回避
理由がわかったので 並べ替えが表示されたら、それを削除するとどうなるかをテストできます。クエリを書き直してオプティマイザーを「だまし」、挿入される行が少なくなると考える方法はありますが(したがって、並べ替えは価値がありません)、直接並べ替えを回避する簡単な方法(実験目的のみ)は、文書化されていないトレースフラグを使用することです。 8795。これにより、DML Request Sortが設定されます。 プロパティをfalseに設定すると、クラスター化されたキーの順序でクラスター化インデックスの挿入に行が到達する必要がなくなります。
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); 新しい実行後のクエリプランは次のとおりです(画像をクリックすると拡大します):

並べ替え演算子はなくなりましたが、新しいクエリは50秒以上実行されます (30秒と比較して 前)。これにはいくつかの理由があります。まず、最小限にログに記録される挿入の可能性が失われます。これは、これらがソートされたデータを必要とするためです(DML Request Sort =true)。次に、挿入中に多数の「不良」ページ分割が発生します。直感に反しているように思われる場合は、ROW_NUMBER 関数は行に順番に番号を付けます。モジュロ演算子の効果は、1〜1000の繰り返しシーケンスをクラスター化インデックス挿入に提示することです。
サポートされていないトレースフラグを使用する代わりに、T-SQLトリックを使用して予想される行数を減らし、並べ替えを回避する場合にも、同じ基本的な問題が発生します。
ソートIIの回避
計画全体を見ると、明示的な並べ替えを回避する方法で行を生成したいのは明らかですが、それでも最小限のロギングと不適切なページ分割回避のメリットを享受できます。簡単に言えば、行をクラスター化されたキーの順序で表示するが、並べ替えは行わないプランが必要です。
この新しい洞察を武器に、クエリを別の方法で表現できます。次のクエリは、1から1000までの各数値と、10,000行で設定されたクロス結合を生成して、必要な程度の重複を生成します。アイデアは、「1」の番号が付けられた10,000行、次に「2」の番号が付けられた10,000行などを表す挿入セットを生成することです。
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; 残念ながら、オプティマイザーはまだソート付きのプランを作成します:

ここでのオプティマイザーの防御については、多くのことを言う必要はありません。これは単なる計画です。 10,000行を生成し、1から1000までの番号の行を相互結合することを選択しました。これにより、番号の自然な順序を維持できないため、並べ替えを回避できません。
並べ替えの回避–最後に!
オプティマイザーが見逃した戦略は、1〜1000最初の数値を取ることです。 、および各番号を10,000行でクロス結合します(各番号の10,000コピーを順番に作成します)。予想される計画では、順序を保持するネストされたループのクロス結合を使用して、並べ替えを回避します。 外側の入力の行の数。
FORCE ORDERを使用して、オプティマイザーにクエリで指定された順序で派生テーブルにアクセスさせることで、この結果を達成できます。 クエリのヒント:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); 最後に、私たちが求めていた計画を取得します:
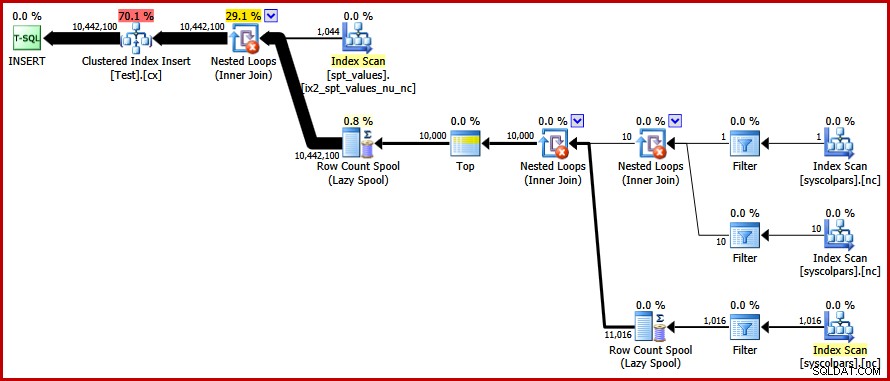
このプランでは、明示的な並べ替えを回避しながら、「不正な」ページ分割を回避し、クラスター化インデックスへの最小限のログ挿入を有効にします(データベースがFULLを使用していない場合) リカバリーモデル)。約9秒で1,000万行すべてを読み込みます 私のラップトップ(単一の7200 rpm SATAスピニングディスクを使用)。これは、30〜50秒で大幅な効率の向上を表しています。 書き換え前の経過時間。
明確な値を見つける
これでサンプルデータが作成されたので、テーブル内の個別の値を見つけるためのクエリの作成に注意を向けることができます。この要件をT-SQLで表現する自然な方法は、次のとおりです。
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
ご想像のとおり、実行計画は非常に単純です。

これには約2900ミリ秒かかります 私のマシンで実行するには、 43,406が必要です 論理読み取り:

MAXDOP (1)を削除する クエリヒントは並列プランを生成します:

これは約1500ミリ秒で完了します (ただし、8,764ミリ秒のCPU時間が消費されます)、および 43,804 論理読み取り:

GROUP BYを使用した場合も、同じ計画とパフォーマンスの結果が得られます DISTINCTの代わりに 。
より優れたアルゴリズム
上記のクエリプランは、ベーステーブルからすべての値を読み取り、StreamAggregateを介してそれらを処理します。タスク全体を考えると、明確な値が比較的少ないことがわかっている場合、1,000万行すべてをスキャンするのは非効率的です。
より良い戦略は、テーブル内の単一の最小値を見つけてから、次に高い値を見つけるというように、値がなくなるまで続けることです。重要なことに、このアプローチは、すべての行をスキャンするのではなく、インデックスをシングルトンで検索するのに役立ちます。
このアイデアは、アンカー部分が最も低いを見つける再帰CTEを使用して、単一のクエリで実装できます。 個別の値の場合、再帰部分は次の個別の値を検索します。このクエリを作成する最初の試みは次のとおりです。
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); 残念ながら、その構文はコンパイルされません:

わかりました。集計関数は許可されていません。 MINを使用する代わりに 、TOP (1)を使用して同じロジックを記述できます ORDER BYを使用 :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

まだ喜びはありません。
再帰部分を書き直して、必要な順序で候補行に番号を付けてから、「1」の番号が付けられた行をフィルタリングすることで、これらの制限を回避できることがわかりました。これは少し遠回りに見えるかもしれませんが、ロジックはまったく同じです:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); このクエリは実行します コンパイルして、次の実行後プランを作成します。

実行プランの再帰部分のTop演算子に注意してください(強調表示されています)。 T-SQLのTOPを記述できません 再帰共通テーブル式の再帰部分にありますが、オプティマイザがそれを使用できないという意味ではありません。オプティマイザは、「1」の番号が付けられた行を見つけるためにチェックする必要がある行数に関する推論に基づいて、トップを導入します。
この(非並列)計画のパフォーマンスは、StreamAggregateアプローチよりもはるかに優れています。約50ミリ秒で完了します 、 3007 以前の最高の1500msと比較した、ソーステーブルに対する論理読み取り(およびスプールワークテーブルから読み取られた6001行) (DOP 8で8764ミリ秒のCPU時間)および 43,804 論理読み取り:


結論
個々のクエリプラン要素を独自に検討することで、クエリパフォーマンスの飛躍的な進歩を達成できるとは限りません。場合によっては、実行計画全体の背後にある戦略を分析してから、より効率的なアルゴリズムと実装を見つけるために水平思考を行う必要があります。