クエリの実行中に取得および解放されたロックの種類と数は、待機やブロックが発生しない場合でも、パフォーマンスに驚くべき影響を与える可能性があります(デフォルトの読み取りコミットなどのロック分離レベルを使用する場合)。実行計画には、実行中のロックアクティビティの量を示す情報がないため、過度のロックがパフォーマンスの問題を引き起こしている場合は、特定が困難になります。
SQL Serverでのあまり知られていないロック動作を調べるために、中央値の計算に関する前回の投稿のクエリとサンプルデータを再利用します。その投稿で、OFFSET グループ化された中央値ソリューションには、明示的なPAGLOCKが必要でした ネストされたカーソルにひどく失われないようにするためのロックのヒント 解決策なので、その理由を詳しく見ていきましょう。
オフセットグループ化中央値ソリューション
グループ化された中央値検定は、AaronBertrandの以前の記事のサンプルデータを再利用しました。以下のスクリプトは、100人の架空の営業担当者ごとに1万件のレコードで構成される、この100万行の設定を再現しています。
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
SQL Server 2012(およびそれ以降)のOFFSET Peter Larssonによって作成されたソリューションは次のとおりです(ロックのヒントなし):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); 実行後の計画の重要な部分を以下に示します。

必要なすべてのデータがメモリにある場合、このクエリは580ミリ秒で実行されます 私のラップトップ(SQL Server 2014 Service Pack 1を実行している)で平均して。このクエリのパフォーマンスは、320ミリ秒に改善できます。 適用サブクエリのSalesテーブルにページ粒度ロックヒントを追加するだけです:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); 実行プランは変更されていません(もちろん、showplan XMLのロックヒントテキストは別として):
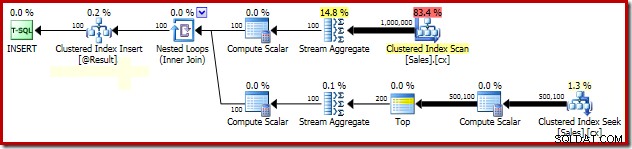
グループ化された中央値ロック分析
PAGLOCKによるパフォーマンスの劇的な向上の説明 ヒントは、少なくとも最初は非常に単純です。
このクエリの実行中にロックアクティビティを手動で監視すると、ページロックの粒度のヒントがないと、SQLServerは50万行レベルのロックを取得して解放することがわかります。 クラスター化されたインデックスを探している間。責任を問われることはありません。この多くのロックを取得して解放するだけで、このクエリの実行にかなりのオーバーヘッドが追加されます。ページレベルのロックをリクエストすると、ロックアクティビティが大幅に減少し、パフォーマンスが大幅に向上します。
この特定のプランのロックパフォーマンスの問題は、上記のプランのクラスター化されたインデックスシークに限定されます。クラスタ化インデックスのフルスキャン(各営業担当者に存在する行数の計算に使用)は、ページレベルのロックを自動的に使用します。これは興味深い点です。 SQL Serverエンジンの詳細なロック動作は、Books Onlineにはあまり文書化されていませんが、SQL Serverチームのさまざまなメンバーが、無制限のスキャンがページの取得を開始する傾向があるという事実を含め、長年にわたっていくつかの一般的な意見を述べています。ロックしますが、小規模な操作は行ロックから始まる傾向があります。
クエリオプティマイザは、カーディナリティの見積もり、分離レベルの内部ヒント、ロックの粒度など、ストレージエンジンで利用できる情報を提供します。これらの情報は、内部最適化を安全に適用できます。繰り返しますが、これらの詳細はBooksOnlineに文書化されていません。最終的に、ストレージエンジンはさまざまな情報を使用して、実行時に必要なロックと、それらを取得する粒度を決定します。
補足として、デフォルトのロック読み取りコミット済みトランザクション分離レベルで実行されるクエリについて話していることを思い出してください。この場合、粒度のヒントなしで取得された行ロックはテーブルロックにエスカレートしないことに注意してください。これは、読み取りコミット時の通常の動作は、次のロックを取得する直前に前のロックを解放することであるためです。つまり、特定の時点で保持されるのは、単一の共有行ロック(関連する上位レベルのインテント共有ロック)のみです。同時に保持される行ロックの数がしきい値に達することはないため、ロックのエスカレーションは試行されません。
オフセット単一中央値ソリューション
単一の中央値計算のパフォーマンステストでは、アーロンの以前の記事から再現された、異なるサンプルデータのセットが使用されます。以下のスクリプトは、1,000万行の疑似乱数データを含むテーブルを作成します。
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
OFFSET 解決策は次のとおりです:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); 実行後の計画は次のとおりです。

このクエリは910ミリ秒で実行されます 私のテストマシンでは平均して。 PAGLOCKの場合、パフォーマンスは変わりません ヒントが追加されましたが、その理由はあなたが考えていることではありません…
シングルメディアンロッキング分析
クラスター化されたインデックススキャンにより、ストレージエンジンがページレベルの共有ロックを選択することを期待している可能性があります。これは、PAGLOCKの理由を説明しています。 ヒントは効果がありません。実際、このクエリの実行中に取得されたロックを監視すると、共有ロック(S)がまったく取得されていないことがわかります。任意の粒度で 。取得されるロックは、オブジェクトおよびページレベルでのインテント共有(IS)のみです。
この動作の説明は2つの部分に分かれています。最初に気付くのは、クラスター化インデックススキャンが実行プランのトップ演算子の下にあることです。これは、実行前(推定)計画に示されているように、カーディナリティの推定に重要な影響を及ぼします。

OFFSET およびFETCH クエリの句は式と変数を参照するため、クエリオプティマイザは実行時に必要となる行数を推測します。 Topの標準的な推測は100行です。もちろんこれはひどい推測ですが、ストレージエンジンを説得して、ページレベルではなく行の粒度でロックするように説得するだけで十分です。
文書化されたトレースフラグ4138を使用してTop演算子の「行ゴール」効果を無効にすると、スキャンでの推定行数は1,000万に変更されます(これはまだ間違っていますが、反対方向です)。これは、ストレージエンジンのロック粒度の決定を変更するのに十分であり、ページレベルの共有ロック(インテント共有ロックではないことに注意してください)が取得されます。
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); トレースフラグ4138で作成された推定実行プランは次のとおりです。

主な例に戻ると、推測された行の目標による100行の推定は、ストレージエンジンが行レベルでロックすることを選択することを意味します。ただし、テーブルおよびページレベルでのみインテント共有(IS)ロックを監視します。これらの高レベルのロックは、行レベルの共有(S)ロックが表示された場合はごく普通のことですが、どこに行きましたか?
答えは、ストレージエンジンには、特定の状況で行レベルの共有ロックをスキップできる別の最適化が含まれているということです。この最適化を適用しても、上位レベルのインテント共有ロックは引き続き取得されます。
要約すると、単一中央値クエリの場合:
-
OFFSETでの変数と式の使用 句は、オプティマイザがカーディナリティを推測することを意味します。 - 見積もりが低いということは、ストレージエンジンが行レベルのロック戦略を決定することを意味します。
- 内部最適化とは、実行時に行レベルのSロックがスキップされ、ページおよびオブジェクトレベルのISロックのみが残ることを意味します。
単一の中央値クエリには、グループ化された中央値と同じ行ロックパフォーマンスの問題がありましたが(クエリオプティマイザーの不正確な見積もりのため)、別のストレージエンジンの最適化によって保存され、インテント共有ページとテーブルロックのみが取得されました実行時。
グループ化された中央値検定の再検討
グループ化された中央値検定のクラスター化インデックスシークが、行レベルの共有ロックをスキップするために同じストレージエンジンの最適化を利用しなかったのはなぜか疑問に思われるかもしれません。なぜこれほど多くの共有行ロックが使用され、PAGLOCKが作成されたのですか。 ヒントが必要ですか?
簡単に言うと、この最適化はINSERT...SELECTでは使用できません。 クエリ。 SELECTを実行すると 単独で(つまり、結果をテーブルに書き込まずに)、PAGLOCKなしで ヒント、行ロックスキップの最適化は 適用:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
テーブルレベルとページレベルのインテント共有(IS)ロックのみが使用され、パフォーマンスはPAGLOCKを使用した場合と同じレベルに向上します。 ヒント。もちろん、この動作はドキュメントには記載されておらず、いつでも変更される可能性があります。それでも、知っておくのは良いことです。
また、不思議に思うかもしれませんが、この場合、行の目標が無効になっている場合でも、シークでの推定行数が少なすぎるため(適用の反復ごと)、トレースフラグ4138はストレージエンジンのロック粒度の選択に影響を与えません。
クエリのパフォーマンスについて結論を出す前に、実行中に取得しているロックの数とタイプを確認してください。 SQL Serverは通常、「適切な」粒度を選択しますが、パフォーマンスに劇的な影響を与えることもあり、問題が発生する場合があります。