中央値を計算する最速の方法は、SQL Server 2012 OFFSETを使用します ORDER BYの拡張 句。すぐに実行すると、次に速いソリューションは、すべてのバージョンで機能する(ネストされている可能性のある)動的カーソルを使用します。この記事では、2012年以前の一般的なROW_NUMBERについて説明します。 中央値計算の問題を解決して、パフォーマンスが低下する理由と、それを高速化するために何ができるかを確認します。
単一中央値検定
このテストのサンプルデータは、単一の1,000万行のテーブル(Aaron Bertrandの元の記事から複製)で構成されています。
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); オフセットソリューション
ベンチマークを設定するために、PeterLarssonによって作成されたSQLServer 2012(またはそれ以降)のOFFSETソリューションを次に示します。
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
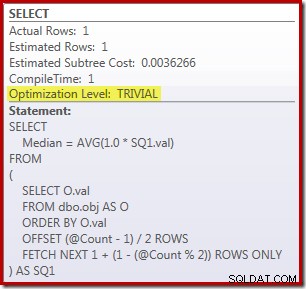
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); テーブル内の行をカウントするクエリはコメント化され、ハードコードされた値に置き換えられて、コアコードのパフォーマンスに集中します。ウォームキャッシュと実行プランの収集をオフにすると、このクエリは910ミリ秒実行されます 私のテストマシンでは平均して。実行計画を以下に示します。

ちなみに、この適度に複雑なクエリが簡単な計画の対象となるのは興味深いことです。
ROW_NUMBERソリューション
SQL Server 2008 R2以前を実行しているシステムの場合、代替ソリューションの最高のパフォーマンスは、前述のように動的カーソルを使用します。それをオプションとして考えることができない(または望まない)場合は、2012年のOFFSETをエミュレートすることを考えるのが自然です。 ROW_NUMBERを使用した実行プラン 。
基本的な考え方は、適切な順序で行に番号を付けてから、中央値を計算するために必要な1つまたは2つの行だけをフィルタリングすることです。 TransactSQLでこれを記述する方法はいくつかあります。すべての重要な要素をキャプチャするコンパクトバージョンは次のとおりです。
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
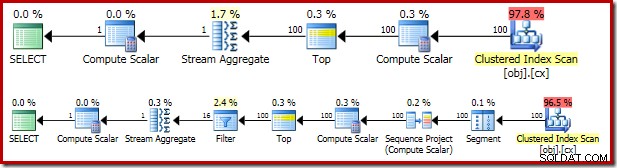
結果の実行プランは、OFFSETと非常によく似ています。 バージョン:

それぞれのプランオペレーターを順番に見て、それらを完全に理解することは価値があります:
- このプランでは、セグメント演算子は冗長です。
ROW_NUMBERの場合に必要になります ランキング関数にはPARTITION BYがありました 条項ですが、そうではありません。それでも、それは最終計画に残っています。 - シーケンスプロジェクトは、計算された行番号を行のストリームに追加します。
- Compute Scalarは、
valを暗黙的に変換する必要性に関連する式を定義します 列を数値に変換して、定数リテラル1.0で乗算できるようにします クエリで。この計算は、後のオペレーター(たまたまStream Aggregate)が必要になるまで延期されます。この実行時の最適化は、暗黙の変換がStream Aggregateによって処理される2つの行に対してのみ実行され、ComputeScalarに示される5,000,001行に対しては実行されないことを意味します。 - Top演算子は、クエリオプティマイザによって導入されます。せいぜい最初の
(@Count + 2) / 2のみを認識します クエリには行が必要です。TOP ... ORDER BYを追加することもできます サブクエリでこれを明示的にしますが、この最適化により、これはほとんど不要になります。 - フィルターは
WHEREの条件を実装します 節、中央値を計算するために必要な2つの「中央」行を除くすべてを除外します(導入されたTopもこの条件に基づいています)。 - StreamAggregateは
SUMを計算します およびCOUNT2つの中央値の行の。 - 最後のComputeScalarは、合計とカウントから平均を計算します。
生のパフォーマンス
OFFSETとの比較 計画では、追加のセグメント、シーケンスプロジェクト、およびフィルター演算子がパフォーマンスに悪影響を与えると予想される場合があります。 推定を比較するのに少し時間をかける価値があります 2つの計画の費用:
OFFSET プランの推定コストは0.0036266 ROW_NUMBER 計画は0.0036744と見積もられています ユニット。これらは非常に少数であり、2つの間にほとんど違いはありません。
したがって、ROW_NUMBERが驚くべきことかもしれません。 クエリは実際には4000ミリ秒実行されます 平均して、910ミリ秒と比較して OFFSETの平均 解決。この増加の一部は、追加のプランオペレーターのオーバーヘッドによって確実に説明できますが、4倍は過剰に思えます。それにはもっとあるに違いありません。
上記の両方の推定計画のカーディナリティ推定がかなり絶望的に間違っていることにも気づいたかもしれません。これは、行数の制限として変数を参照する式を持つTop演算子の効果によるものです。クエリオプティマイザはコンパイル時に変数の内容を確認できないため、デフォルトの100行の推測に頼ります。どちらのプランも、実際には実行時に5,000,001行に遭遇します。
これはすべて非常に興味深いものですが、ROW_NUMBERの理由を直接説明しているわけではありません。 クエリはOFFSETの4倍以上遅い バージョン。結局のところ、100行のカーディナリティの見積もりはどちらの場合も同じように間違っています。
ROW_NUMBERソリューションのパフォーマンスの向上
前回の記事では、グループ化された中央値OFFSETのパフォーマンスがどのようになっているかを見ました。 PAGLOCKを追加するだけで、テストをほぼ2倍にすることができます。 ヒント。このヒントは、行の粒度で共有ロックを取得および解放するというストレージエンジンの通常の決定を上書きします(予想されるカーディナリティが低いため)。
さらに注意として、PAGLOCK 単一の中央値OFFSETではヒントは不要でした 行レベルの共有ロックをスキップできる個別の内部最適化によるテスト。その結果、ページレベルで取得されるインテント共有ロックの数は少なくなります。
ROW_NUMBERが予想される場合があります 同じ内部最適化の恩恵を受ける単一の中央値ソリューションですが、そうではありません。 ROW_NUMBER中のロックアクティビティの監視 クエリが実行されると、50万を超える個別の行レベルの共有ロックが表示されます 取られて解放されます。
これで、問題が何であるかがわかったので、以前と同じ方法でロックのパフォーマンスを向上させることができます。つまり、PAGLOCKを使用します。 粒度のヒントをロックするか、文書化されたトレースフラグ4138を使用してカーディナリティの推定値を増やします。
トレースフラグを使用して「行の目標」を無効にすることは、いくつかの理由で満足のいく解決策ではありません。まず、SQL Server2008R2以降でのみ有効です。 OFFSETをお勧めします SQL Server 2012のソリューションであるため、これにより、トレースフラグの修正がSQL Server2008R2のみに効果的に制限されます。次に、トレースフラグを適用するには、プランガイドを介して適用されない限り、管理者レベルの権限が必要です。 3番目の理由は、クエリ全体の行の目標を無効にすると、特により複雑な計画では、他の望ましくない影響が生じる可能性があることです。
対照的に、PAGLOCK ヒントは効果的であり、特別な権限がなくてもSQL Serverのすべてのバージョンで利用でき、粒度をロックする以外に大きな副作用はありません。
PAGLOCKを適用する ROW_NUMBERへのヒント クエリによりパフォーマンスが劇的に向上します:4000ミリ秒から 〜 1500ミリ秒:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
1500ミリ秒 結果はまだ910ミリ秒よりも大幅に遅いです OFFSETの場合 解決策ですが、少なくとも今は同じ球場にあります。残りのパフォーマンスの違いは、単に実行プランの余分な作業によるものです:

OFFSETで 計画では、500万行がトップまで処理されます(前述のように、Compute Scalarで定義された式は延期されます)。 ROW_NUMBER内 計画では、同じ数の行をセグメント、シーケンスプロジェクト、トップ、およびフィルターで処理する必要があります。