中央値の簡単な定義は次のとおりです。
中央値は、ソートされた数値リストの中央値です。それを少し具体化するために、次の手順を使用して数値のリストの中央値を見つけることができます。
- 番号を並べ替えます(昇順または降順、どちらでも構いません)。
- ソートされたリストの中央値(位置別)は中央値です。
- 「等しく中間」の数値が2つある場合、中央値は2つの中間値の平均です。
Aaron Bertrandは、SQLServerの中央値を計算するいくつかの方法を以前にパフォーマンステストしました。
- 中央値を計算する最も速い方法は何ですか?
- グループ化された中央値に最適なアプローチ
Rob Farleyは最近、2012年以前のインストールを目的とした別のアプローチを追加しました:
- SQL2012より前のメディアン
この記事では、動的カーソルを使用する新しい方法を紹介します。
2012OFFSET-FETCHメソッド
まず、PeterLarssonによって作成された最高のパフォーマンスの実装を見ていきます。 SQL Server 2012 OFFSETを使用します ORDER BYの拡張 中央値を計算するために必要な1つまたは2つの中央の行を効率的に見つけるための句。
オフセット単一中央値
アーロンの最初の記事では、1,000万行を超える単一の中央値の計算をテストしました:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
OFFSETを使用したPeterLarssonのソリューション 拡張子は:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); 上記のコードは、テーブルの行をカウントした結果をハードコードします。中央値を計算するためにテストされたすべてのメソッドは、中央値の行番号を計算するためにこのカウントを必要とするため、一定のコストになります。行カウント操作をタイミングから外すと、1つの考えられる変動の原因を回避できます。
OFFSETの実行プラン 解決策を以下に示します:

Topオペレーターは、不要な行をすばやくスキップして、中央値を計算するために必要な1行または2行だけをStreamAggregateに渡します。ウォームキャッシュと実行プランコレクションをオフにして実行すると、このクエリは910ミリ秒実行されます 私のラップトップで平均して。これは、1.73GHzで動作するInteli7 740QMプロセッサを搭載し、Turboを無効にしたマシンです(一貫性を保つため)。
オフセットグループ化中央値
アーロンの2番目の記事では、100人の営業担当者ごとに1万のエントリを持つ100万行の販売テーブルを使用して、グループごとの中央値を計算するパフォーマンスをテストしました。
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
繰り返しになりますが、最高のパフォーマンスを発揮するソリューションは OFFSETを使用します :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); 実行計画の重要な部分を以下に示します。

計画の一番上の行は、各営業担当者のグループ行数を見つけることに関係しています。下の行は、単一グループの中央値ソリューションで見られるのと同じ計画要素を使用して、各営業担当者の中央値を計算します。ウォームキャッシュをオフにして実行プランをオフにすると、このクエリは320ミリ秒で実行されます。 私のラップトップでは平均して。
動的カーソルの使用
中央値を計算するためにカーソルを使用することを考えるのはおかしなことに思えるかもしれません。 Transact SQLカーソルは、低速で非効率的であるという(ほとんどの場合、当然の)評判があります。また、動的カーソルは最悪のタイプのカーソルであるとよく考えられます。これらのポイントは状況によっては有効ですが、常に有効であるとは限りません。
Transact SQLカーソルは、一度に1行の処理に制限されているため、多数の行をフェッチして処理する必要がある場合は、実際に処理が遅くなる可能性があります。ただし、中央値の計算には当てはまりません。必要なのは、1つまたは2つの中間値を効率的に見つけてフェッチすることだけです。 。これから説明するように、動的カーソルはこのタスクに非常に適しています。
単一中央値動的カーソル
単一の中央値計算の動的カーソルソリューションは、次の手順で構成されています。
- アイテムの順序付きリストの上に動的なスクロール可能なカーソルを作成します。
- 最初の中央値の行の位置を計算します。
-
FETCH RELATIVEを使用してカーソルの位置を変更します 。 - 中央値を計算するために2番目の行が必要かどうかを決定します。
- そうでない場合は、単一の中央値をすぐに返します。
- それ以外の場合は、
FETCH NEXTを使用して2番目の値をフェッチします 。 - 2つの値の平均を計算して、戻ります。
そのリストが、この記事の冒頭で示した中央値を見つけるための簡単な手順をどれほど厳密に反映しているかに注目してください。完全なTransactSQLコードの実装を以下に示します。
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
FETCH RELATIVEの実行プラン ステートメントは、中央値の計算に必要な最初の行に動的カーソルを効率的に再配置することを示しています。
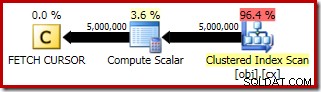
FETCH NEXTの計画 (これらのテストのように、2番目の中央の行がある場合にのみ必要です)は、カーソルの保存された位置からの単一行のフェッチです:
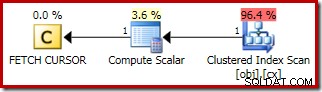
ここで動的カーソルを使用する利点は次のとおりです。
- セット全体をトラバースすることを回避します(中央値の行が見つかった後、読み取りは停止します)。と
- tempdbではデータの一時的なコピーは作成されません 、静的カーソルまたはキーセットカーソルの場合と同様です。
FAST_FORWARDは指定できないことに注意してください FETCH RELATIVE をサポートするにはカーソルをスクロール可能にする必要があるため、ここにカーソルを置きます(静的または動的なプランの選択はオプティマイザーに任せます)。 。とにかく、ここではダイナミックが最適です。
ウォームキャッシュと実行プランコレクションをオフにして実行すると、このクエリは930ミリ秒実行されます 私のテストマシンでは平均して。これは910ミリ秒より少し遅いです OFFSETの場合 解決策ですが、動的カーソルはAaronとRobがテストした他の方法よりも大幅に高速であり、SQL Server 2012(またはそれ以降)を必要としません。
ここでは、2012年以前の他の方法のテストを繰り返すつもりはありませんが、パフォーマンスギャップのサイズの例として、次の行番号付けソリューションには1550ミリ秒かかります。 平均して(70%遅い):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

グループ化された中央値動的カーソルテスト
グループ化された中央値を計算するために、単一中央値動的カーソルソリューションを拡張するのは簡単です。一貫性を保つために、ネストされたカーソルを使用します(はい、本当に):
- 営業担当者と行数の上に静的カーソルを開きます。
- 毎回新しい動的カーソルを使用して、各人の中央値を計算します。
- 各結果をテーブル変数に保存します。
コードを以下に示します:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); そのセット内のすべての行がタッチされるため、外側のカーソルは意図的に静的になります(また、基になるクエリのグループ化操作のため、動的カーソルは使用できません)。今回の実行計画には、特に目新しいものや興味深いものはありません。
面白いのはパフォーマンスです。内部動的カーソルの作成と割り当て解除が繰り返されているにもかかわらず、このソリューションはテストデータセットで非常にうまく機能します。ウォームキャッシュと実行プランをオフにすると、カーソルスクリプトは330ミリ秒で完了します。 私のテストマシンでは平均して。これも320ミリ秒よりも少し遅いです OFFSETによって記録されます グループ化された中央値ですが、アーロンとロブの記事に記載されている他の標準的なソリューションを大幅に上回っています。
繰り返しになりますが、他の2012年以外の方法とのパフォーマンスのギャップの例として、次の行番号付けソリューションが485ミリ秒実行されます。 私のテストリグの平均(50%悪い):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

結果の概要
単一中央値検定では、動的カーソルが930ミリ秒実行されました 対910ミリ秒 OFFSETの場合 メソッド。
グループ化された中央値検定では、ネストされたカーソルが330ミリ秒実行されました。 対320ミリ秒 OFFSETの場合 。
どちらの場合も、カーソル方式は他の非 OFFSETよりも大幅に高速でした。 メソッド。 2012年より前のインスタンスで単一またはグループ化された中央値を計算する必要がある場合は、動的カーソルまたはネストされたカーソルが実際に最適な選択である可能性があります。
コールドキャッシュのパフォーマンス
コールドキャッシュのパフォーマンスについて疑問に思われる方もいらっしゃるかもしれません。各テストの前に以下を実行します:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
単一中央値検定の結果は次のとおりです。
オフセット 方法:940ミリ秒
動的カーソル:955ミリ秒
グループ化された中央値の場合:
オフセット 方法:380ミリ秒
ネストされたカーソル:385ミリ秒
最終的な考え
動的カーソルソリューションは、 OFFSET以外のソリューションよりも大幅に高速です。 少なくともこれらのサンプルデータセットを使用した、単一およびグループ化された中央値の両方のメソッド。データセットが意図的に動的カーソルに偏らないように、意図的にAaronのテストデータを再利用することを選択しました。そこにかもしれない 動的カーソルが適切なオプションではない他のデータ分布である。それにもかかわらず、カーソルが正しい種類の問題に対する高速で効率的な解決策になる場合があることを示しています。動的でネストされたカーソルですら。
ワシの目の読者は、 PAGLOCKに気づいたかもしれません。 OFFSETのヒント グループ化された中央値検定。これは、次の記事で説明する理由から、最高のパフォーマンスを得るために必要です。これがないと、2012年のソリューションは実際には適切なマージン( 590ms )でネストされたカーソルに負けます。 対330ms 。