これは、数級数ジェネレータの課題の解決策に関するシリーズの第4部です。 Alan Burstein、Joe Obbish、Adam Machanic、Christopher Ford、Jeff Moden、Charlie、NoamGr、Kamil Kosno、Dave Mason、John Nelson#2、Ed Wagner、Michael Burbea、PaulWhiteのアイデアとコメントに感謝します。
ポールホワイトの作品が大好きです。私は彼の発見にショックを受け続けており、彼が何をしているのかをどうやって理解しているのだろうかと思います。彼の効率的で雄弁な文章スタイルも大好きです。彼の記事や投稿を読んでいる間、私は頭を振って妻のリラックに、大人になったらポールのようになりたいと言います。
私が最初にチャレンジを投稿したとき、私はポールが解決策を投稿することを密かに望んでいました。もし彼がそうしたら、それはとても特別なものになるだろうと私は知っていました。ええと、彼はそうしました、そしてそれは魅力的です!優れたパフォーマンスを発揮し、そこから学ぶことがたくさんあります。この記事はPaulのソリューションに捧げられています。
tempdbでテストを行い、I/Oと時間の統計を有効にします。
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME, IO ON;
以前のアイデアの制限
以前のソリューションを評価すると、優れたパフォーマンスを得るための重要な要素の1つは、バッチ処理を採用できることでした。しかし、可能な限りそれを活用しましたか?
バッチ処理を利用した以前の2つのソリューションの計画を調べてみましょう。パート1では、関数dbo.GetNumsAlanCharlieItzikBatchについて説明しました。この関数は、Alan、Charlie、および私自身のアイデアを組み合わせたものです。
関数の定義は次のとおりです。
-- Helper dummy table
DROP TABLE IF EXISTS dbo.BatchMe;
GO
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
GO
-- Function definition
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO このソリューションは、16行の基本テーブル値コンストラクターと、行数を潜在的に4Bに増やすためのクロス結合を備えた一連のカスケードCTEを定義します。このソリューションでは、ROW_NUMBER関数を使用してNumsと呼ばれるCTEに数値の基本シーケンスを作成し、TOPフィルターを使用して目的の数値系列のカーディナリティをフィルター処理します。バッチ処理を有効にするために、このソリューションでは、NumsCTEと列ストアインデックスを持つdbo.BatchMeというテーブルとの間にfalse条件を指定したダミーの左結合を使用します。
次のコードを使用して、変数代入手法で関数をテストします。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
実際ののプランエクスプローラーの描写 この実行の計画を図1に示します。
 図1:dbo.GetNumsAlanCharlieItzikBatch関数の計画
図1:dbo.GetNumsAlanCharlieItzikBatch関数の計画
バッチモードと行モードの処理を分析する場合、各オペレーターがどの処理モードを使用したかを高レベルで計画を見るだけでわかるのは非常に便利です。実際、Plan Explorerは、実際の実行モードがバッチの場合、オペレーターの左下部分に水色のバッチ図を表示します。図1に示すように、バッチモードを使用した唯一の演算子は、行番号を計算するWindowAggregate演算子です。行モードで他のオペレーターによって行われる作業はまだたくさんあります。
テストで得たパフォーマンスの数値は次のとおりです。
CPU時間=10032ミリ秒、経過時間=10025ミリ秒。論理読み取り0
実行に最も時間がかかったオペレーターを特定するには、SSMSの[実際の実行プラン]オプションを使用するか、プランエクスプローラーの[実際のプランを取得]オプションを使用します。 Paulの最近の記事UnderstandingExecutionPlanOperatorTimingsを必ずお読みください。この記事では、正しい数値を取得するために、報告されたオペレーターの実行時間を正規化する方法について説明しています。
図1の計画では、ほとんどの時間は左端のネストされたループとトップオペレーターによって費やされており、どちらも行モードで実行されています。 CPUを集中的に使用する操作では、行モードはバッチモードよりも効率が悪いだけでなく、行モードからバッチモードに切り替えたり、元に戻したりすると、余分な負担がかかることに注意してください。
パート2では、関数dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2に実装されたバッチ処理を採用した別のソリューションについて説明しました。このソリューションは、John Number2、Dave Mason、Joe Obbish、Alan、Charlie、および私からのアイデアを組み合わせたものです。前のソリューションと今回のソリューションの主な違いは、前者は仮想テーブル値コンストラクターを使用し、後者は列ストアインデックスを持つ実際のテーブルを使用するため、「無料」でバッチ処理ができることです。テーブルを作成し、INSERTステートメントを使用して102,400行を入力してテーブルを圧縮するコードは、次のとおりです。
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO 関数の定義は次のとおりです。
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO> ベーステーブルの2つのインスタンス間の単一のクロス結合は、4B行の望ましい可能性をはるかに超えて生成するのに十分です。ここでも、ソリューションはROW_NUMBER関数を使用して数値の基本シーケンスを生成し、TOPフィルターを使用して目的の数値系列のカーディナリティを制限します。
変数代入手法を使用して関数をテストするコードは次のとおりです。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
この実行の計画を図2に示します。
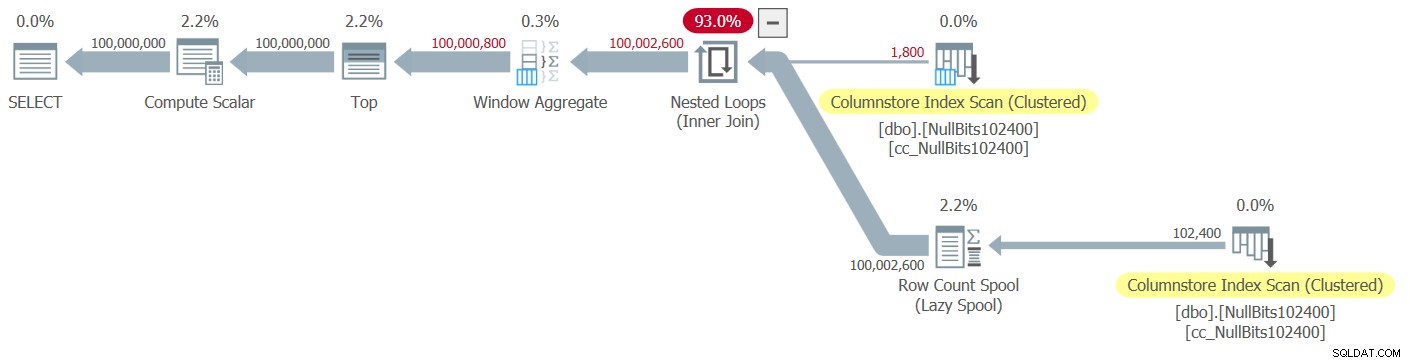 図2:dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2関数の計画
図2:dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2関数の計画
このプランでは、バッチモードを使用する演算子が2つだけであることに注意してください。ネストされたループ結合の外部入力として使用されるテーブルのクラスター化列ストアインデックスのトップスキャンと、ベース行番号の計算に使用されるウィンドウ集約演算子です。 。
テストで次のパフォーマンス数値を取得しました:
CPU時間=9812ミリ秒、経過時間=9813ミリ秒。テーブル'NullBits102400'。スキャンカウント2、論理読み取り0、物理読み取り0、ページサーバー読み取り0、先読み読み取り0、ページサーバー先読み読み取り0、lob論理読み取り8、lob物理読み取り0、lobページサーバー読み取り0、lob読み取り-先読みは0を読み取り、LOBページサーバーの先読みは0を読み取ります。
テーブル'NullBits102400'。セグメントは2を読み取り、セグメントは0をスキップしました。
繰り返しになりますが、このプランの実行のほとんどの時間は、行モードで実行される左端のネストされたループとトップ演算子によって費やされます。
ポールのソリューション
ポールの解決策を提示する前に、彼が経験した思考プロセスに関する私の理論から始めます。これは実際には素晴らしい学習演習であり、解決策を検討する前にそれを実行することをお勧めします。 Paulは、バッチモードと行モードの両方を組み合わせた計画の衰弱効果を認識し、すべてのバッチモードの計画を取得するソリューションを考え出すことに挑戦しました。成功すれば、そのようなソリューションがうまく機能する可能性は非常に高くなります。バッチモードをまだサポートしていないオペレーターがまだ多く、バッチ処理を妨げる多くの要因があることを考えると、そのような目標が達成可能かどうかを確認するのは確かに興味深いことです。たとえば、執筆時点では、バッチ処理をサポートする唯一の結合アルゴリズムはハッシュ結合アルゴリズムです。クロス結合は、ネストされたループアルゴリズムを使用して最適化されます。さらに、Top演算子は現在、行モードでのみ実装されています。これらの2つの要素は、上記の2つを含め、これまでに取り上げたソリューションの多くの計画で使用される重要な基本要素です。
オールバッチモードの計画でソリューションを作成するという課題を適切に試したと仮定して、2番目の演習に進みましょう。最初に、Paulが提供したソリューションを、インラインコメントとともに提示します。また、他のソリューションとのパフォーマンスを比較するために実行します。私は彼のソリューションを一度に1ステップずつ分解して再構築することで多くのことを学び、彼が行った各手法を使用した理由を注意深く理解したことを確認しました。私の説明を読む前に、同じことをすることをお勧めします。
これがPaulのソリューションであり、dbo.CSというヘルパー列ストアテーブルとdbo.GetNums_SQLkiwiという関数が含まれています。
-- Helper columnstore table
DROP TABLE IF EXISTS dbo.CS;
-- 64K rows (enough for 4B rows when cross joined)
-- column 1 is always zero
-- column 2 is (1...65536)
SELECT
-- type as integer NOT NULL
-- (everything is normalized to 64 bits in columnstore/batch mode anyway)
n1 = ISNULL(CONVERT(integer, 0), 0),
n2 = ISNULL(CONVERT(integer, N.rn), 0)
INTO dbo.CS
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
rn ASC
OFFSET 0 ROWS
FETCH NEXT 65536 ROWS ONLY
) AS N;
-- Single compressed rowgroup of 65,536 rows
CREATE CLUSTERED COLUMNSTORE INDEX CCI
ON dbo.CS
WITH (MAXDOP = 1);
GO
-- The function
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scala
@low - 2 + N.rn < @high;
GO 変数代入手法を使用して関数をテストするために使用したコードは次のとおりです。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000);
テスト用に図3に示す計画を取得しました。
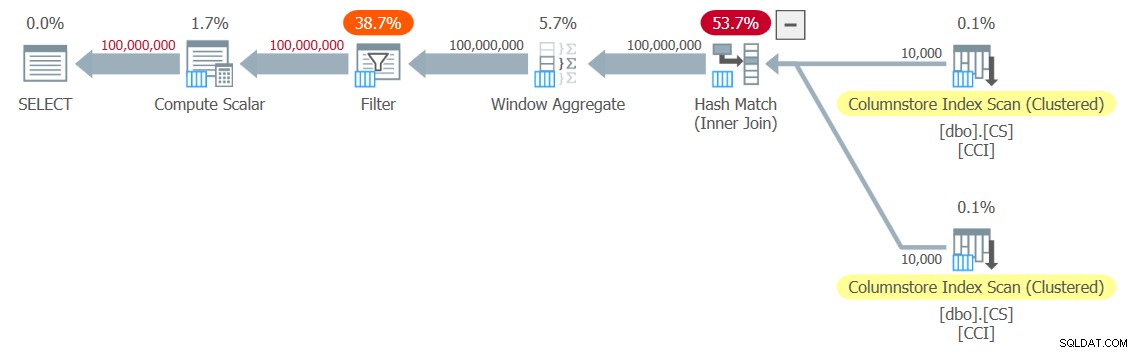 図3:dbo.GetNums_SQLkiwi関数の計画
図3:dbo.GetNums_SQLkiwi関数の計画
オールバッチモードのプランです!それは非常に印象的です。
自分のマシンでこのテストを行ったときに得られたパフォーマンスの数値は次のとおりです。
CPU時間=7812ミリ秒、経過時間=7876ミリ秒。テーブル「CS」。スキャンカウント2、論理読み取り0、物理読み取り0、ページサーバー読み取り0、先読み読み取り0、ページサーバー先読み読み取り0、lob論理読み取り44、lob物理読み取り0、lobページサーバー読み取り0、lob読み取り-先読みは0を読み取り、LOBページサーバーの先読みは0を読み取ります。
テーブル「CS」。セグメントは2を読み取り、セグメントは0をスキップしました。
また、n順に並べられた数値を返す必要がある場合、ソリューションがrnに関して順序を保持していることを確認しましょう(少なくとも入力として定数を使用する場合)。したがって、プランで明示的な並べ替えを回避します。順序でテストするためのコードは次のとおりです。
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n;
図3と同じ計画が得られるため、同様のパフォーマンス数値が得られます。
CPU時間=7765ミリ秒、経過時間=7822ミリ秒。テーブル「CS」。スキャンカウント2、論理読み取り0、物理読み取り0、ページサーバー読み取り0、先読み読み取り0、ページサーバー先読み読み取り0、lob論理読み取り44、lob物理読み取り0、lobページサーバー読み取り0、lob読み取り-先読みは0を読み取り、LOBページサーバーの先読みは0を読み取ります。
テーブル「CS」。セグメントは2を読み取り、セグメントは0をスキップしました。
これはソリューションの重要な側面です。
テスト方法の変更
Paulのソリューションのパフォーマンスは、以前の2つのソリューションと比較して、経過時間とCPU時間の両方でまともな改善ですが、オールバッチモードプランから期待されるより劇的な改善とは思えません。何かが足りないのではないでしょうか?
図4に示すように、SSMSの実際の実行プランを見て、オペレーターの実行時間を分析してみましょう。
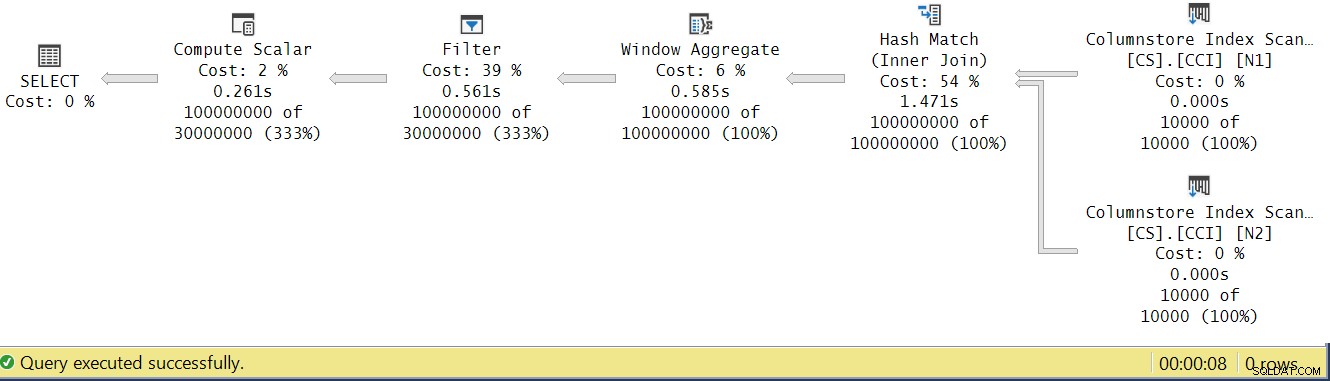 図4:dbo.GetNums_SQLkiwi関数のオペレーター実行時間
図4:dbo.GetNums_SQLkiwi関数のオペレーター実行時間
オペレーターの実行時間の分析に関するPaulの記事で、バッチモードのオペレーターでは、それぞれが独自の実行時間を報告すると説明しています。この実際の計画ですべてのオペレーターの実行時間を合計すると、2.878秒になりますが、計画の実行には7.876がかかりました。実行時間の5秒が欠落しているようです。これに対する答えは、変数の割り当てを使用した、使用しているテスト手法にあります。この手法を使用して、サーバーから呼び出し元にすべての行を送信する必要をなくし、結果をテーブルに書き込む際に必要となるI/Oを回避することにしたことを思い出してください。それは完璧なオプションのようでした。ただし、変数割り当ての実際のコストはこのプランには隠されており、もちろん、行モードで実行されます。謎は解けました。
明らかに、1日の終わりに、優れたテストとは、ソリューションの本番環境での使用を適切に反映するテストです。通常、データをテーブルに書き込む場合は、それを反映するためのテストが必要です。結果を発信者に送信する場合は、それを反映するためのテストが必要です。いずれにせよ、変数の割り当ては、テストの実行時間の大部分を表しているようであり、関数の一般的な本番環境での使用を表す可能性は低いことは明らかです。 Paulは、変数の代入の代わりに、MAXのような単純な集計を返された数値列(n / rn / op)に適用できることを提案しました。集約オペレーターはバッチ処理を利用できるため、プランはその使用の結果としてバッチモードから行モードへの変換を必要とせず、合計実行時間への寄与はかなり小さく、既知である必要があります。
それでは、この記事で取り上げた3つのソリューションすべてを再テストしましょう。関数dbo.GetNumsAlanCharlieItzikBatchをテストするコードは次のとおりです:
SELECT MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
このテストでは、図5に示す計画を取得しました。
 図5:集計を使用したdbo.GetNumsAlanCharlieItzikBatch関数の計画
図5:集計を使用したdbo.GetNumsAlanCharlieItzikBatch関数の計画
このテストで得たパフォーマンスの数値は次のとおりです。
CPU時間=8469ミリ秒、経過時間=8733ミリ秒。論理読み取り0
実行時間が変数割り当て手法を使用した10.025秒から集計手法を使用した8.733秒に短縮されたことを確認します。これは、ここで変数の割り当てに帰することができる実行時間の1秒強です。
関数dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2をテストするコードは次のとおりです:
SELECT MAX(n) AS mx FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
このテストでは、図6に示す計画を取得しました。
 図6:集約を使用したdbo.GetNumsJohn2DaveObbishAlanCharlieItzik2関数の計画
図6:集約を使用したdbo.GetNumsJohn2DaveObbishAlanCharlieItzik2関数の計画
このテストで得たパフォーマンスの数値は次のとおりです。
CPU時間=7031ミリ秒、経過時間=7053ミリ秒。テーブル'NullBits102400'。スキャンカウント2、論理読み取り0、物理読み取り0、ページサーバー読み取り0、先読み読み取り0、ページサーバー先読み読み取り0、lob論理読み取り8、lob物理読み取り0、lobページサーバー読み取り0、lob読み取り-先読みは0を読み取り、LOBページサーバーの先読みは0を読み取ります。
テーブル'NullBits102400'。セグメントは2を読み取り、セグメントは0をスキップしました。
実行時間が変数割り当て手法を使用した9.813秒から集計手法を使用した7.053に短縮されたことを確認します。これは、ここで変数の割り当てに帰することができる実行時間の2秒強です。
そして、Paulのソリューションをテストするためのコードは次のとおりです。
SELECT MAX(n) AS mx FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(MAXDOP 1);
このテストでは、図7に示す計画が得られます。
 図7:集計を使用したdbo.GetNums_SQLkiwi関数の計画
図7:集計を使用したdbo.GetNums_SQLkiwi関数の計画
そして今、大きな瞬間のために。このテストでは、次のパフォーマンス数値を取得しました。
CPU時間=3125ミリ秒、経過時間=3149ミリ秒。テーブル「CS」。スキャンカウント2、論理読み取り0、物理読み取り0、ページサーバー読み取り0、先読み読み取り0、ページサーバー先読み読み取り0、lob論理読み取り44、lob物理読み取り0、lobページサーバー読み取り0、lob読み取り-先読みは0を読み取り、LOBページサーバーの先読みは0を読み取ります。
テーブル「CS」。セグメントは2を読み取り、セグメントは0をスキップしました。
実行時間が7.822秒から3.149秒に短縮されました。図8に示すように、SSMSの実際の計画でオペレーターの実行時間を調べてみましょう。
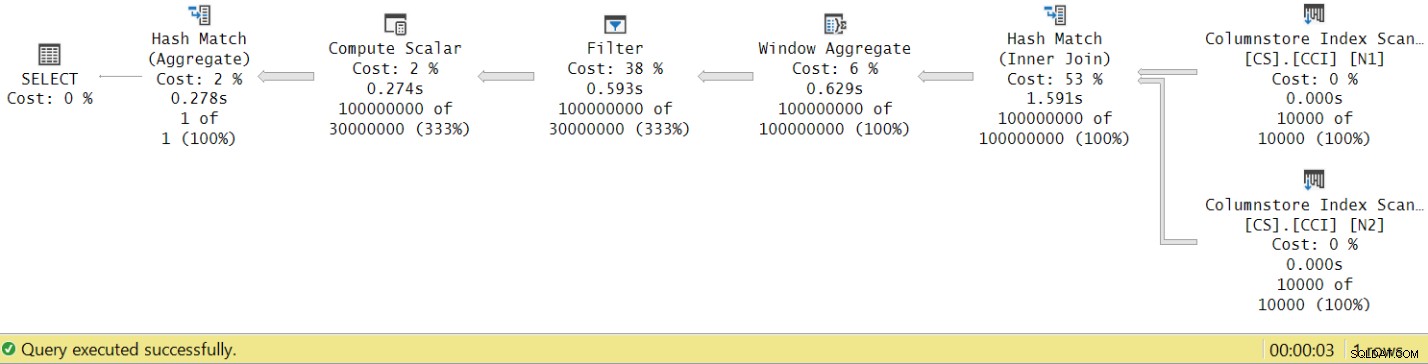 図8:集計を使用したdbo.GetNums関数の演算子実行時間
図8:集計を使用したdbo.GetNums関数の演算子実行時間
これで、個々のオペレーターの実行時間を累積すると、合計プラン実行時間と同様の数が得られます。
図9は、変数の割り当てと集計テストの両方の手法を使用した3つのソリューション間の経過時間に関するパフォーマンスの比較です。
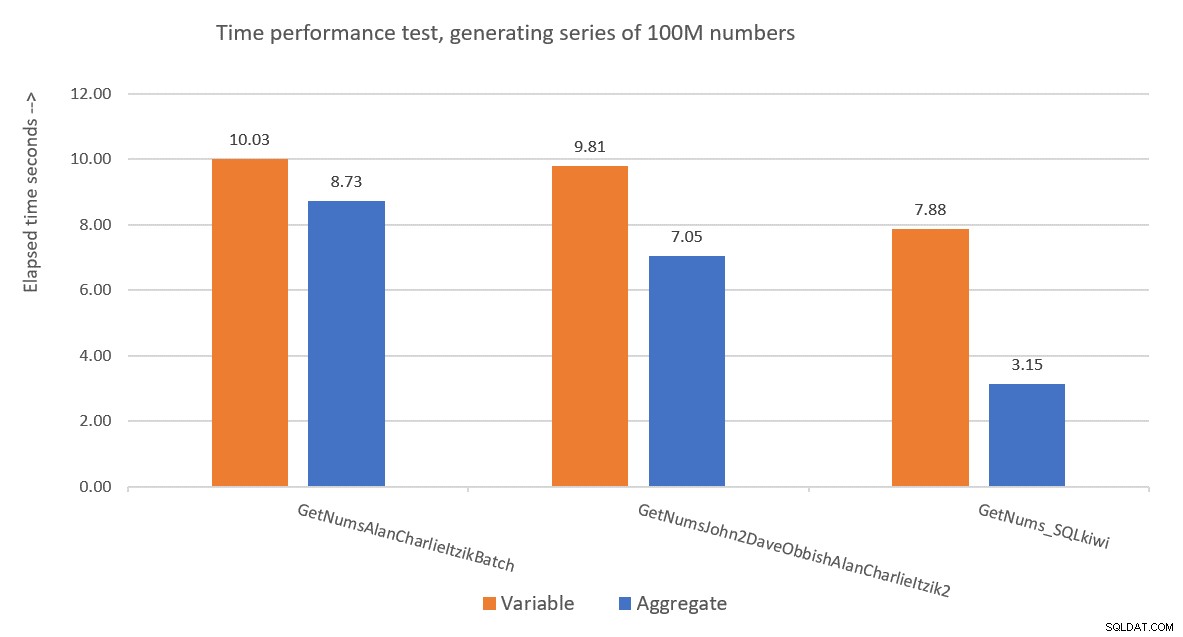 図9:パフォーマンスの比較
図9:パフォーマンスの比較
Paulのソリューションは明らかに勝者であり、これは集計テスト手法を使用する場合に特に明白です。なんて印象的な偉業でしょう!
ポールのソリューションの分解と再構築
Paulのソリューションを分解してから再構築することは素晴らしい演習であり、そうすることで多くのことを学ぶことができます。前に提案したように、読み続ける前に自分でプロセスを実行することをお勧めします。
最初に選択する必要があるのは、4Bの潜在的な行数を生成するために使用する手法です。 Paulは、列ストアテーブルを使用して、必要な数の平方根と同じ数の行、つまり65,536行を入力することを選択しました。これにより、1回のクロス結合で、必要な数を取得できます。おそらく、102,400行未満では圧縮された行グループを取得できないと考えているかもしれませんが、これは、テーブルdbo.NullBits102400で行ったようにテーブルにINSERTステートメントを入力する場合に当てはまります。事前入力されたテーブルに列ストアインデックスを作成する場合は適用されません。そこで、PaulはSELECT INTOステートメントを使用して、65,536行の行ストアベースのヒープとしてテーブルを作成してデータを設定し、クラスター化された列ストアインデックスを作成して、行グループを圧縮しました。
次の課題は、クロス結合をバッチモード演算子で処理する方法を理解することです。このためには、結合アルゴリズムがハッシュである必要があります。クロス結合は、ネストされたループアルゴリズムを使用して最適化されることに注意してください。どういうわけか、オプティマイザーをだまして、内部の等結合を使用していると思わせる必要があります(ハッシュには、少なくとも1つの等式ベースの述語が必要です)が、実際には相互結合を取得します。
明らかな最初の試みは、次のように常に真である人工結合述語で内部結合を使用することです。
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON 0 = 0; しかし、このコードは次のエラーで失敗します:
メッセージ8622、レベル16、状態1、行246このクエリで定義されたヒントが原因で、クエリプロセッサはクエリプランを生成できませんでした。ヒントを指定せず、SET FORCEPLANを使用せずに、クエリを再送信します。
SQL Serverのオプティマイザは、これが人工的な内部結合述語であることを認識し、相互結合への内部結合を単純化し、ハッシュ結合アルゴリズムを強制するためのヒントに対応できないというエラーを生成します。
これを解決するために、Paulはdbo.CSテーブルにn1というINT NOT NULL列を作成し(この仕様については後ほど詳しく説明します)、すべての行に0を入力しました。次に、結合述語N2.n1 =N1.n1を使用し、ハッシュ結合アルゴリズムの最小要件に準拠しながら、すべての一致評価で命題0=0を効果的に取得しました。
これは機能し、オールバッチモードのプランを作成します:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON N2.n1 = N1.n1; n1がINTNOTNULLとして定義される理由については;なぜNULLを禁止し、なぜBIGINTを使用しないのですか?これらの選択の理由は、ハッシュプローブの残差(元の結合述部を超えてハッシュ結合演算子によって適用される追加のフィルター)を回避するためです。これにより、余分な不要なコストが発生する可能性があります。詳細については、Paulの記事Join Performance、Implicit Conversions、およびResidualsを参照してください。これが私たちに関連する記事の一部です:
「結合がtinyint、smallint、またはintegerとして入力された単一の列にあり、両方の列がNOT NULLに制約されている場合、ハッシュ関数は「完全」です。つまり、ハッシュの衝突の可能性はなく、クエリプロセッサ値が実際に一致することを確認するために、値を再度チェックする必要はありません。この最適化はbigint列には適用されないことに注意してください。"
この側面を確認するために、null許容のn1列を持つdbo.CS2という別のテーブルを作成しましょう。
DROP TABLE IF EXISTS dbo.CS2; SELECT * INTO dbo.CS2 FROM dbo.CS; ALTER TABLE dbo.CS2 ALTER COLUMN n1 INT NULL; CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.CS2 WITH (MAXDOP = 1);でクラスター化列ストアインデックスCCIを作成します。
まず、dbo.CS(n1はINT NOT NULLとして定義されています)に対してクエリをテストし、rnという列に4Bの基本行番号を生成し、MAX集計を列に適用します。
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
) AS N; このクエリの計画を、dbo.CS2(n1はINT NULLとして定義されている)に対する同様のクエリの計画と比較します。
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS2 AS N1
JOIN dbo.CS2 AS N2
ON N2.n1 = N1.n1
) AS N; 両方のクエリの計画を図10に示します。
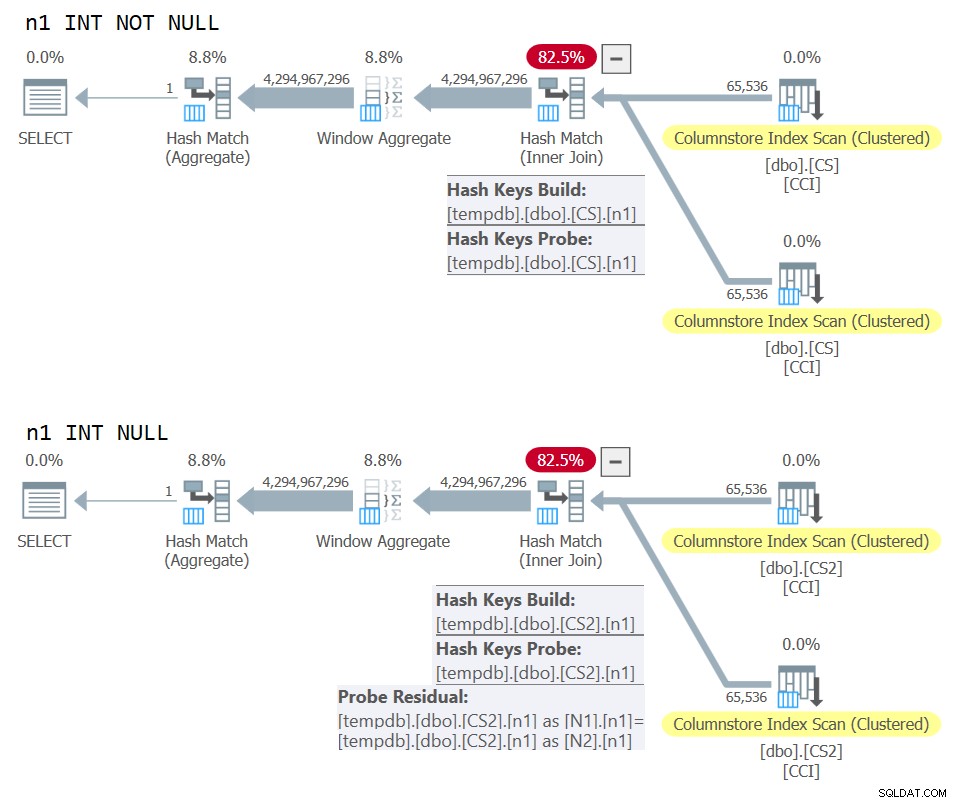 図10:NOTNULLとNULL結合キーの計画の比較
図10:NOTNULLとNULL結合キーの計画の比較
2番目の計画では適用されているが、最初の計画では適用されていない余分なプローブの残差をはっきりと確認できます。
私のマシンでは、dbo.CSに対するクエリは91秒で完了し、dbo.CS2に対するクエリは92秒で完了しました。 Paulの記事で、彼は使用した例のNOT NULLの場合に11%の違いがあると報告しています。
ところで、鋭い目を持っている人は、ROW_NUMBER関数の順序付け仕様としてORDER BY@@TRANCOUNTが使用されていることに気付くでしょう。 Paulのソリューションでのインラインコメントを注意深く読むと、@@ TRANSCOUNT関数の使用は並列処理の阻害要因であるのに対し、@@SPIDの使用はそうではないと彼は述べています。したがって、シリアルプランを強制する場合は、順序付け仕様の実行時定数として@@ TRANCOUNTを使用し、強制しない場合は@@SPIDを使用できます。
前述のように、私のマシンで実行するには、dbo.CSに対するクエリが91秒かかりました。この時点で、真のクロス結合を使用して同じコードをテストし、オプティマイザーに行モードのネストされたループ結合アルゴリズムを使用させることは興味深いかもしれません。
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
CROSS JOIN dbo.CS AS N2
) AS N; このコードが私のマシンで完了するのに104秒かかりました。したがって、バッチモードのハッシュ結合を使用すると、パフォーマンスが大幅に向上します。
次の問題は、TOPを使用して目的の行数をフィルター処理すると、行モードのTop演算子を使用してプランが得られるという事実です。 TOPフィルターを使用してdbo.GetNums_SQLkiwi関数を実装する試みは次のとおりです。
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT TOP (100000000 - 1 + 1)
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
ORDER BY rn
) AS N;
GO 関数をテストしてみましょう:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
このテストでは、図11に示す計画を取得しました。
 図11:TOPフィルターを使用した計画
図11:TOPフィルターを使用した計画
プラン内で行モード処理を使用するのはTop演算子だけであることに注意してください。
この実行について、次の時間統計を取得しました:
CPU時間=6078ミリ秒、経過時間=6071ミリ秒。このプランの実行時間の大部分は、行モードのトップオペレーターによって費やされ、プランはバッチから行モードへの変換を経て戻る必要があるという事実があります。
私たちの課題は、行モードTOPに代わるバッチモードフィルタリングを理解することです。 WHERE句で適用されるような述語ベースのフィルタは、バッチ処理で処理できる可能性があります。
Paulのアプローチは、2番目のINTタイプの列を導入することでした(インラインコメント「列ストア/バッチモードではすべてが64ビットに正規化されます」を参照してください。 )テーブルdbo.CSに対してn2を呼び出し、1から65,536までの整数シーケンスを入力します。ソリューションのコードでは、彼は2つの述語ベースのフィルターを使用しました。 1つは、結合の両側からの列n2を含む述語を使用した内部クエリの粗いフィルターです。この粗いフィルターは、誤検知を引き起こす可能性があります。このようなフィルターの最初の単純な試みは次のとおりです。
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1)))) 入力1と100,000,000を@lowと@highとして使用すると、誤検知は発生しません。しかし、1と100,000,001で試してみてください。そうすれば、いくらか得られます。 100,000,001ではなく100,020,001の数字のシーケンスを取得します。
誤検知を排除するために、Paulは、外部クエリのrn列を含む2番目の正確なフィルターを追加しました。このような正確なフィルターを使った最初の単純な試みは次のとおりです。
WHERE
-- Precise filter:
N.rn < @high - @low + 2 TOPの代わりに上記の述語ベースのフィルターを使用するように関数の定義を修正しましょう。1を取ります:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
N.rn < @high - @low + 2;
GO 関数をテストしてみましょう:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
このテストでは、図12に示す計画を取得しました。
 図12:WHEREフィルターを使用した計画、1を取る
図12:WHEREフィルターを使用した計画、1を取る
悲しいかな、何かが明らかにうまくいかなかった。 SQL Serverは、列rnを含む述語ベースのフィルターをTOPベースのフィルターに変換し、Top演算子を使用して最適化しました。これは、まさに回避しようとしたことです。怪我に侮辱を加えるために、オプティマイザーは結合にネストされたループアルゴリズムを使用することも決定しました。
このコードが私のマシンで完了するのに18.8秒かかりました。見栄えが悪い。
ネストされたループの結合に関しては、これは内部クエリで結合ヒントを使用して簡単に処理できるものです。パフォーマンスへの影響を確認するために、テストクエリ自体で使用される強制ハッシュ結合クエリヒントを使用したテストを次に示します。
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(HASH JOIN);
実行時間は13.2秒に短縮されます。
rnに対するWHEREフィルターのTOPフィルターへの変換にはまだ問題があります。これがどのように起こったかを理解してみましょう。外部クエリで次のフィルタを使用しました:
WHERE N.rn < @high - @low + 2
rnは、操作されていないROW_NUMBERベースの式を表すことに注意してください。特定の範囲内にあるこのような操作されていない式に基づくフィルターは、多くの場合、Top演算子を使用して最適化されます。これは、行モード処理を使用しているため、悪いニュースです。
Paulの回避策は、同等の述語を使用することでしたが、次のようにrnに操作を適用する述語です。
WHERE @low - 2 + N.rn < @high
ROW_NUMBERベースの式に操作を追加する式をフィルタリングすると、述語ベースのフィルターからTOPベースのフィルターへの変換が禁止されます。それは素晴らしいです!
上記のWHERE述語を使用するように関数の定義を修正してみましょう。2を取ります:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
@low - 2 + N.rn < @high;
GO Test the function again, without any special hints or anything:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
It naturally gets an all-batch-mode plan with a hash join algorithm and no Top operator, resulting in an execution time of 3.177 seconds. Looking good.
The next step is to check if the solution handles bad inputs well. Let’s try it with a negative delta:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
This execution fails with the following error.
Msg 3623, Level 16, State 1, Line 436An invalid floating point operation occurred.
The failure is due to the attempt to apply a square root of a negative number.
Paul’s solution involved two additions. One is to add the following predicate to the inner query’s WHERE clause:
@high >= @low
This filter does more than what it seems initially. If you’ve read Paul’s inline comments carefully, you could find this part:
“Try to avoid SQRT on negative numbers and enable simplification to single constant scan if @low> @high (with literals). No start-up filters in batch mode.”The intriguing part here is the potential to use a constant scan with constants as inputs. I’ll get to this shortly.
The other addition is to apply the IIF function to the input expression to the SQRT function. This is done to avoid negative input when using nonconstants as inputs to our numbers function, and in case the optimizer decides to handle the predicate involving SQRT before the predicate @high>=@low.
Before the IIF addition, for example, the predicate involving N1.n2 looked like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
After adding IIF, it looks like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
With these two additions, we’re now basically ready for the final definition of the dbo.GetNums_SQLkiwi function:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scalar
@low - 2 + N.rn < @high;
GO Now back to the comment about the constant scan. When using constants that result in a negative range as inputs to the function, e.g., 100,000,000 and 1 as @low and @high, after parameter embedding the WHERE filter of the inner query looks like this:
WHERE
1 >= 100000000
AND ... The whole plan can then be simplified to a single Constant Scan operator.試してみてください:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
The plan for this execution is shown in Figure 13.
 Figure 13:Plan with constant scan
Figure 13:Plan with constant scan
Unsurprisingly, I got the following performance numbers for this execution:
CPU time =0 ms, elapsed time =0 ms.logical reads 0
When passing a negative range with nonconstants as inputs, the use of the IIF function will prevent any attempt to compute a square root of a negative input.
Now let’s test the function with a valid input range:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
You get the all-batch-mode plan shown in Figure 14.
 Figure 14:Plan for dbo.GetNums_SQLkiwi function
Figure 14:Plan for dbo.GetNums_SQLkiwi function
This is the same plan you saw earlier in Figure 7.
I got the following time statistics for this execution:
CPU time =3000 ms, elapsed time =3111 ms.Ladies and gentlemen, I think we have a winner! :)
結論
I’ll have what Paul’s having.
Are we done yet, or is this series going to last forever?
No and no.