2015年1月に、私の親友であり仲間のSQLServerMVPであるRobFarleyが、2012年より前のSQLServerバージョンで中央値を見つけるという問題の新しい解決策について書きました。高度な実行計画分析を示し、クエリオプティマイザーと実行エンジンの微妙な動作を強調するために使用する優れた例です。
単一中央値
Robの記事は特にグループ化された中央値の計算を対象としていますが、重要な問題を最も明確に強調しているため、彼の方法を大きな単一の中央値の計算問題に適用することから始めます。サンプルデータは、AaronBertrandの元の記事から再び取得されます。
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); この問題にRobFarleyの手法を適用すると、次のコードが得られます。
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
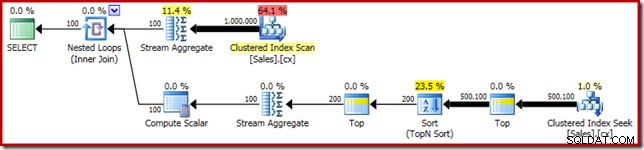
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); いつものように、私はテーブルの行数を数えることをコメントアウトし、パフォーマンスの変動の原因を避けるために定数に置き換えました。重要なクエリの実行プランは次のとおりです。

このクエリは5800msで実行されます 私のテストマシンで。
ソートスピル
このパフォーマンス低下の主な原因は、上記の実行プランを確認することで明らかになります。並べ替え演算子の警告は、ワークスペースメモリの付与が不十分なために物理的な tempdb > ディスク:
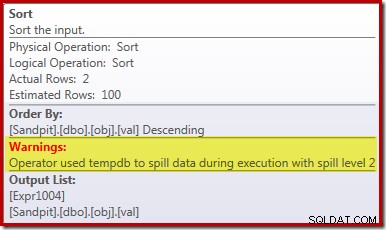
2012より前のバージョンのSQLServerでは、これを確認するには、ソートスピルイベントを個別に監視する必要があります。とにかく、不十分なソートメモリ予約は、実行前(推定)計画が示すように、カーディナリティ推定エラーが原因で発生します。

ソート入力での100行のカーディナリティ推定は、前のTop演算子のローカル変数式のため、オプティマイザーによる(非常に不正確な)推測です:

このカーディナリティ推定エラーは、行目標の問題ではないことに注意してください。トレースフラグ4138を適用すると、最初のトップの下の行ゴール効果が削除されますが、トップ後の見積もりは100行の推測のままです(したがって、ソートのメモリ予約は依然として小さすぎます):

ローカル変数の値のヒント
このカーディナリティ推定の問題を解決するには、いくつかの方法があります。 1つのオプションは、ヒントを使用して、変数に保持されている値に関する情報をオプティマイザーに提供することです。
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); ヒントを使用すると、パフォーマンスが3250ミリ秒に向上します。 5800msから。 実行後の計画は、ソートが流出しなくなったことを示しています:

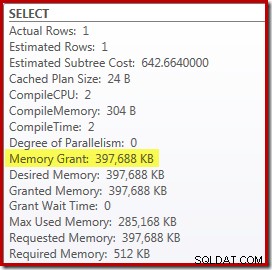
ただし、これにはいくつかの欠点があります。まず、この新しい実行プランには 388MBが必要です。 メモリ付与–サーバーがプラン、インデックス、およびデータをキャッシュするために使用する可能性のあるメモリ:
第二に、メモリを不必要に予約せずに、将来のすべての実行でうまく機能するヒントに適切な数を選択するのは難しい場合があります。
また、流出を完全に排除するために、変数の実際の値よりも10%高い変数の値を示唆する必要があることにも注意してください。一般的な並べ替えアルゴリズムは、単純なインプレース並べ替えよりも複雑であるため、これは珍しいことではありません。ソートするセットのサイズに等しいメモリを予約しても、実行時の流出を回避するのに常に(または一般的に)十分であるとは限りません。
埋め込みと再コンパイル
もう1つのオプションは、SQL Server 2008SP1CU5以降にクエリレベルの再コンパイルヒントを追加することで有効になっているパラメーター埋め込みの最適化を利用することです。このアクションにより、オプティマイザーは変数の実行時の値を確認し、それに応じて最適化できます。
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
これにより、実行時間が 3150msに向上します。 – OPTIMIZE FORを使用するよりも100ミリ秒優れています ヒント。このさらに小さな改善の理由は、新しい実行後の計画から識別できます。

式(2 – @Count % 2) – 2番目のTop演算子で前に見たように–これで単一の既知の値に折りたたむことができます。最適化後の書き換えにより、TopとSortを組み合わせて、単一のTopNSortを作成できます。 Top +SortをTopNSortに折りたたむと、定数リテラルのTop値(変数やパラメーターではない)でのみ機能するため、この書き換えは以前は不可能でした。
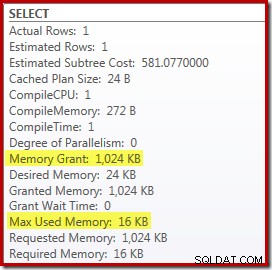
トップとソートをトップNソートに置き換えると、パフォーマンスにわずかな有益な効果があります(ここでは100ミリ秒)が、トップNソートはNの最高(または最低)を追跡するだけでよいため、メモリ要件もほぼ完全に排除されます。セット全体ではなく、行。このアルゴリズムの変更の結果、このクエリの実行後の計画では、最小の 1MB が示されています。 このプランでは、メモリはトップNソート用に予約されており、 16KBのみです。 実行時に使用されました(フルソートプランには388MBが必要でした):
再コンパイルの回避
再コンパイルクエリヒントを使用することの(明らかな)欠点は、実行のたびに完全なコンパイルが必要になることです。この場合、オーバーヘッドは非常に小さく、約1msのCPU時間と272KBのメモリです。それでも、ヒントを使用せずに、また再コンパイルせずにトップNソートの利点を得るように、クエリを微調整する方法があります。
このアイデアは、最大であることを認識することから生まれました。 最終的な中央値の計算には、2行のうちの2行が必要になります。 1行の場合もあれば、実行時に2行の場合もありますが、それ以上になることはありません。この洞察は、次のように、論理的に冗長な上位(2)中間ステップをクエリに追加できることを意味します。
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); 新しいTop(非常に重要な定数リテラルを含む)は、最終的な実行プランが、再コンパイルせずに目的のTopNSort演算子を備えていることを意味します。

この実行プランのパフォーマンスは、 3150msの再コンパイルヒントバージョンから変更されていません。 メモリ要件は同じです。ただし、パラメータが埋め込まれていないということは、並べ替えの下のカーディナリティの推定値が100行の推測であることを意味します(ただし、ここでのパフォーマンスには影響しません)。
この段階での主なポイントは、メモリの少ないトップNソートが必要な場合は、定数リテラルを使用するか、オプティマイザーがパラメーター埋め込み最適化を介してリテラルを表示できるようにする必要があることです。
コンピューティングスカラー
388MBを排除する メモリの付与(100ミリ秒のパフォーマンスの向上も行います)は確かに価値がありますが、はるかに大きなパフォーマンスの向上が得られます。この最終的な改善の可能性の低いターゲットは、クラスター化インデックススキャンのすぐ上にあるComputeScalarです。
このComputeScalarは、式(0E + f.val)に関連しています。 AVGに含まれています クエリで集計します。奇妙に見える場合、これは平均的な計算で整数演算を回避するためのかなり一般的なクエリ作成のトリック(1.0を掛けるなど)ですが、いくつかの非常に重要な副作用があります。
ここには、ステップバイステップで従う必要のある特定の一連のイベントがあります。
まず、0Eに注意してください floatを持つ定数リテラルゼロです。 データ・タイプ。これを整数列valに追加するには、クエリプロセッサは列を整数からfloatに変換する必要があります(データ型の優先順位規則に従って)。列に1.0(暗黙の数値データ型を持つリテラル)を乗算することを選択した場合も、同様の種類の変換が必要になります。重要な点は、このルーチンのトリックが式を導入するということです。 。
現在、SQLServerは通常式をプッシュダウンしようとします コンパイルおよび最適化中に可能な限り計画ツリー。これは、計算列との式の照合を容易にするため、および制約情報を使用した単純化を容易にするためなど、いくつかの理由で行われます。このプッシュダウンポリシーは、ComputeScalarがクエリ内の式の元のテキスト位置が示唆するよりもプランのリーフレベルにはるかに近いように見える理由を説明しています。
このプッシュダウンを実行するリスクは、式が必要以上に計算される可能性があることです。ほとんどのプランは、結合、集計、およびフィルターの効果により、プランツリーを上に移動するにつれて行数が減少することを特徴としています。したがって、式をツリーの下にプッシュすると、それらの式を必要以上に(つまり、より多くの行で)評価するリスクがあります。
これを軽減するために、SQL Server 2005では、ComputeScalarsが単純に定義できる最適化が導入されました。 実際に評価する作業を伴う表現 延期という表現 計画の後のオペレーターが結果を要求するまで。この最適化が意図したとおりに機能する場合、その効果は、実際に必要な回数だけ式を実際に評価しながら、式をツリーにプッシュすることのすべての利点を得ることになります。
このComputeScalarのすべての意味
実行中の例では、0E + val 式は元々AVGに関連付けられていました アグリゲートなので、Stream Aggregateで(または少し後に)表示されると予想される場合があります。ただし、この表現は押し下げられました スキャンの直後に、[Expr1004]というラベルの付いた式を持つ新しいComputeScalarになるツリー。
実行プランを見ると、[Expr1004]がStream Aggregateによって参照されていることがわかります(以下に示す[プランエクスプローラーの式]タブの抜粋):

すべてが等しい場合、式[Expr1004]の評価は延期されます 集計が平均計算の合計部分にこれらの値を必要とするまで。アグリゲートは1つまたは2つの行にしか遭遇しない可能性があるため、これにより[Expr1004]が1回または2回だけ評価されることになります。
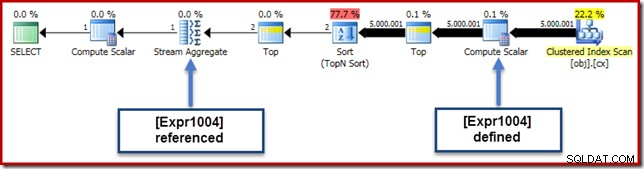
残念ながら、これはここでうまくいく方法ではありません。問題は、ソート演算子のブロックです:
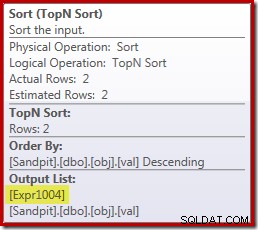
これにより、[Expr1004]の評価が強制されるため、Stream Aggregateで1回または2回だけ評価されるのではなく、Sortはvalを変換することを意味します。 列をフロートに追加し、それにゼロを追加します 5,000,001 回数!
回避策
理想的には、SQL Serverはこれらすべてについて少し賢いでしょうが、それは今日のやり方ではありません。式がプランツリーにプッシュされるのを防ぐためのクエリヒントはありません。また、プランガイドを使用してComputeScalarsを強制することもできません。必然的に、文書化されていないトレースフラグがありますが、それは私が現在の状況で責任を持って話すことができるものではありません。
したがって、良くも悪くも、これにより、クエリの結果を変更せずに、SQL Serverが式を集計から分離し、並べ替えを超えてプッシュダウンするのを防ぐクエリの書き換えを見つけようとすることになります。これはあなたが思うほど簡単ではありませんが、以下の(確かに少し奇妙に見える)変更はCASEを使用してこれを達成します 非決定論的組み込み関数の表現:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); この最終形式のクエリの実行プランを以下に示します。

ClusteredIndexScanとTopの間にComputeScalarが表示されなくなったことに注意してください。 0E + val 式は、Stream Aggregateで最大2行(500万行ではなく!)で計算されるようになり、パフォーマンスがさらに 32%向上します。 3150msから2150ms 結果として。
これでも、OFFSETの1秒未満のパフォーマンスとは比較できません。 動的カーソル中央値計算ソリューションですが、それでも元の 5800msよりも大幅に改善されています。 大きな単一中央値の問題セットに対するこの方法の場合。
もちろん、CASEトリックが将来機能することは保証されていません。要点は、Compute Scalarの潜在的なパフォーマンスへの影響に関するものであるため、奇妙な大文字小文字の表現のトリックを使用することについてはそれほど重要ではありません。この種のことを知ったら、1.0を掛けたり、平均計算にフロートゼロを追加したりする前に、よく考えてみてください。
更新: 文書化されていないトリックを必要としないRobertHeinigによる優れた回避策については、最初のコメントを参照してください。次に、平均的な集計で整数に10進数(または浮動小数点数)を掛けようとするときに覚えておくべきことがあります。
グループ化された中央値
完全を期すために、そしてこの分析をロブの元の記事にさらに密接に結び付けるために、グループ化された中央値の計算に同じ改善を適用することで終了します。セットサイズが小さい(グループあたり)ということは、もちろん効果が小さいことを意味します。
グループ化された中央値のサンプルデータ(これも元々Aaron Bertrandによって作成されたもの)は、100人の架空の営業担当者ごとに1万行で構成されています。
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); Rob Farleyのソリューションを直接適用すると、次のコードが得られます。このコードは 560msで実行されます。 私のマシンで。
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); 実行計画には、単一の中央値と明らかに類似しています:
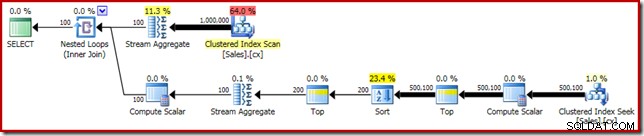
最初の改善点は、明示的なTop(2)を追加して、SortをTopNSortに置き換えることです。これにより、実行時間が560ミリ秒から550ミリ秒にわずかに改善されます。 。
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); 実行プランには、期待どおりに上位Nソートが表示されます:
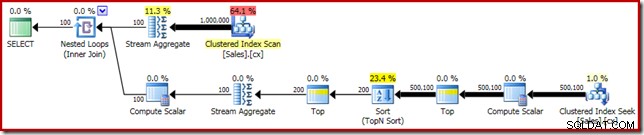
最後に、奇妙に見えるCASE式をデプロイして、プッシュされたComputeScalar式を削除します。これにより、パフォーマンスがさらに450msに向上します。 (オリジナルより20%改善):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); 完成した実行計画は次のとおりです。