この記事は、データのグループ化と集約に関連する最適化のしきい値に関するシリーズの2番目です。パート1では、StreamAggregateオペレーターコストのリバースエンジニアリング式を提供しました。この演算子は、グループ化セットによって順序付けられた行(そのメンバーの任意の順序)を消費する必要があり、データがインデックスから事前に順序付けられて取得されると、行数と行数に関して線形スケーリングが得られることを説明しました。グループ。また、このような場合、メモリの付与は必要ありません。
この記事では、データがインデックスから事前に並べ替えられて取得されていない場合のストリーム集計ベースの操作のコストとスケーリングに焦点を当てます。むしろ、最初に並べ替える必要があります。
私の例では、パート1のように、PerformanceV3サンプルデータベースを使用します。このデータベースを作成してデータを取り込むスクリプトは、ここからダウンロードできます。この記事の例を実行する前に、まず次のコードを実行して、不要なインデックスをいくつか削除してください。
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
このテーブルに残しておく必要があるインデックスは、idx_cl_odの2つだけです。 (orderdateでクラスター化 キーとして)およびPK_Orders (orderidでクラスター化されていない キーとして)。
並べ替え+ストリーム集計
この記事の焦点は、データがグループ化セットによって事前に順序付けされていない場合に、ストリーム集約操作がどのようにスケーリングするかを理解することです。 Stream Aggregateオペレーターは順序付けられた行を処理する必要があるため、インデックスで事前に順序付けされていない場合、プランには明示的なSort演算子を含める必要があります。したがって、考慮すべき集計操作のコストは、並べ替え+ストリーム集計演算子のコストの合計です。
次のクエリ(クエリ1と呼びます)を使用して、このような最適化を含む計画を示します。
SELECT shipperid, MAX(orderdate) AS maxod FROM (SELECT TOP (100) * FROM dbo.Orders) AS D GROUP BY shipperid;
このクエリの計画を図1に示します。

図1:クエリ1の計画
TOPフィルターでテーブル式を使用する理由は、グループ化と集計に関係する(推定)行の正確な数を制御するためです。制御された変更を適用すると、原価計算式のリバースエンジニアリングが容易になります。
この例でこのような少数の行をフィルタリングする理由がわからない場合は、この戦略をハッシュ集計アルゴリズムよりも優先させる最適化のしきい値と関係があります。パート3では、代替ハッシュのコストとスケーリングについて説明します。オプティマイザがそれ自体でストリーム集約操作を選択しない場合、たとえば、多数の行が含まれる場合、調査プロセス中にヒントOPTION(ORDER GROUP)を使用していつでも強制できます。シリアルプランの原価計算に焦点を当てる場合、並列処理を排除するためにMAXDOP1ヒントを追加することができます。
前述のように、事前順序付けされていないストリーム集約アルゴリズムのコストとスケーリングを評価するには、Sort +StreamAggregate演算子の合計を考慮する必要があります。パート1のStreamAggregateオペレーターの原価計算式は既に知っています。
@numrows * 0.0000006 + @numgroups * 0.0000005このクエリでは、100個の推定入力行と5個の推定出力グループ(密度情報に基づいて推定された5個の個別の荷送人ID)があります。したがって、私たちの計画におけるStreamAggregateオペレーターのコストは次のとおりです。
100 * 0.0000006 + 5 * 0.0000005 =0.0000625並べ替え演算子の原価計算式を試してみましょう。オプティマイザーが選択をある戦略から別の戦略に変更する最適化のしきい値を把握することが最終的な目標であるため、私たちの焦点は推定コストとスケーリングであることを忘れないでください。
I / Oコストの見積もりは固定されているようです:0.0112613。行数、並べ替え列数、データ型などの要因に関係なく、同じI/Oコストが発生します。これはおそらく、予想されるI/O作業を説明するためです。
CPUコストに関しては、残念ながら、Microsoftは並べ替えに使用する正確なアルゴリズムを公開していません。ただし、データベースエンジンによる並べ替えに一般的に使用される一般的なアルゴリズムには、マージソートとクイックソートのさまざまな実装があります。 Windowsデバッガスタックトレースを見るのが好きなPaulWhiteの努力のおかげで(私たち全員がこれに腹を立てているわけではありません)、彼のシリーズ「Internals of the Seven SQL Server」で公開された、トピックについてもう少し洞察を得ることができます。並べ替えます。」 Paulの調査結果によると、一般的なソートクラス(上記の計画で使用)はマージソートを使用します(最初に内部、次に外部に移行します)。平均して、このアルゴリズムでは、n個のアイテムを並べ替えるためにn個のlogn個の比較が必要です。これを念頭に置いて、オペレーターのコストのCPU部分が次のような式に基づいていると想定することは、おそらく出発点として安全な賭けです。
オペレーターのCPUコスト=<起動コスト>+@numrows * LOG(@numrows)*<比較コスト>もちろん、これはMicrosoftが使用する実際の原価計算式を単純化しすぎている可能性がありますが、この問題に関するドキュメントがないため、これは最初の最良の推測です。
次に、異なる数の行、たとえば1000と2000を並べ替えるために作成された2つのクエリプランから並べ替えCPUコストを取得し、それらと上記の式に基づいて、比較コストと起動コストをリバースエンジニアリングします。この目的のために、グループ化されたクエリを使用する必要はありません。基本的なORDERBYを実行するだけで十分です。次の2つのクエリを使用します(クエリ2とクエリ3と呼びます):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid;
計算結果による順序付けのポイントは、並べ替え演算子をプランで使用するように強制することです。
図2は、2つの計画の関連部分を示しています。
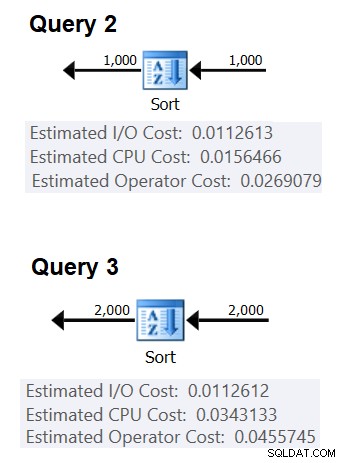
図2:クエリ2とクエリ3の計画>
1つの比較のコストを推測するには、次の式を使用します。
比較コスト=
((<クエリ3のCPUコスト> –<起動コスト> )–(<クエリ2のCPUコスト> –<起動コスト> ))
/(<クエリ3 #comparisons> –<クエリ2#comparisons>)=
(0.0343133 – 0.0156466)/(2000 * LOG(2000)– 1000 * LOG(1000))= 2.25061348918698E-06
起動コストについては、いずれかのプランに基づいて推測できます。たとえば、2000行を並べ替えるプランに基づいて推測できます。
起動コスト=0.0343133 – 2000 * LOG(2000)* 2.25061348918698E-06 = 9.99127891201865E-05
したがって、ソートCPUコストの式は次のようになります。
ソート演算子のCPUコスト=9.99127891201865E-05+ @numrows * LOG(@numrows)* 2.25061348918698E-06同様の手法を使用すると、平均行サイズ、順序付け列の数、およびそれらのデータ型などの要因が、推定されるソートCPUコストに影響を与えないことがわかります。関連すると思われる唯一の要因は、推定行数です。ソートにはメモリ許可が必要であり、許可は行数(グループではない)と平均行サイズに比例することに注意してください。しかし、現在私たちの焦点は推定オペレーターコストであり、この推定は推定行数によってのみ影響を受けるようです。
この式は、約5,000行のしきい値までのCPUコストを十分に予測しているようです。次の番号で試してください:100、200、300、400、500、1000、2000、3000、4000、5000:
SELECT
numrows,
9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS predicatedcost
FROM (VALUES(100), (200), (300), (400), (500), (1000), (2000), (3000), (4000), (5000))
AS D(numrows); 数式が予測するものと、次のクエリに対して計画が示す推定CPUコストを比較します。
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (200) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (300) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (400) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (3000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (4000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (5000) * FROM dbo.Orders) AS D ORDER BY myorderid;
次の結果が得られました:
numrows predicatedcost estimatedcost ratio ----------- --------------- -------------- ------- 100 0.0011363 0.0011365 1.00018 200 0.0024848 0.0024849 1.00004 300 0.0039510 0.0039511 1.00003 400 0.0054937 0.0054938 1.00002 500 0.0070933 0.0070933 1.00000 1000 0.0156466 0.0156466 1.00000 2000 0.0343133 0.0343133 1.00000 3000 0.0541576 0.0541576 1.00000 4000 0.0747667 0.0747665 1.00000 5000 0.0959445 0.0959442 1.00000
予測コストの列はリバースエンジニアリングされた式に基づく予測を示し、推定コストの列は計画に表示される推定コストを示し、比率の列は後者と前者の比率を示します。
予測は、5,000行まではかなり正確に見えます。ただし、数値が5,000を超えると、リバースエンジニアリングされた数式がうまく機能しなくなります。次のクエリは、6K、7K、10K、20K、100K、および200K行の述語を提供します。
SELECT
numrows,
9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS predicatedcost
FROM (VALUES(6000), (7000), (10000), (20000), (100000), (200000)) AS D(numrows); 次のクエリを使用して、プランから推定CPUコストを取得します(行数が多いほど、コスト計算式が並列処理に合わせて調整される並列プランを取得する可能性が高いため、シリアルプランを強制するためのヒントに注意してください):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (6000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (7000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1);
次の結果が得られました:
numrows predicatedcost estimatedcost ratio
----------- --------------- -------------- ------
6000 0.117575 0.160970 1.3691
7000 0.139583 0.244848 1.7541
10000 0.207389 0.603420 2.9096
20000 0.445878 1.311710 2.9419
100000 2.591210 7.623920 2.9422
200000 5.494330 16.165700 2.9423 ご覧のとおり、5,000行を超えると、数式の精度はますます低下しますが、不思議なことに、精度比は約20,000行で約2.94で安定します。これは、数値が大きい場合でも、比較コストが高い場合にのみ式が適用され、およそ5,000〜20,000行の間で、低い比較コストから高い比較コストに徐々に移行することを意味します。しかし、小規模と大規模の違いを説明できるのは何でしょうか。良いニュースは、答えが量子力学と一般相対性理論を弦理論と調和させるほど複雑ではないということです。小規模では、MicrosoftがCPUキャッシュが使用される可能性が高いという事実を考慮したかっただけであり、コスト計算の目的で、固定キャッシュサイズを想定しています。
したがって、大規模な比較コストを計算するには、20,000を超える数の2つのプランからのソートCPUコストを使用する必要があります。 100,000行と200,000行を使用します(上の表の最後の2行)。比較コストを推測する式は次のとおりです。
比較コスト=(16.1657 – 7.62392)/(200000 * LOG(200000)– 100000 * LOG(100000))= 6.62193536908588E-06
次に、200,000行の計画に基づいて起動コストを推測する式は次のとおりです。
起動コスト=16.1657 – 200000 * LOG(200000)* 6.62193536908588E-06 = 1.35166186417734E-04
小規模と大規模の起動コストが同じであり、得られた違いは丸め誤差によるものである可能性があります。いずれにせよ、行数が多いと、比較のコストと比較して、起動コストはごくわずかになります。
要約すると、多数(> =20000)のSortオペレーターのCPUコストの式は次のとおりです。
オペレーターのCPUコスト=1.35166186417734E-04+ @numrows * LOG(@numrows)* 6.62193536908588E-06500K、1M、および10M行で数式の精度をテストしてみましょう。次のコードは、数式の述語を示しています。
SELECT
numrows,
1.35166186417734E-04 + numrows * LOG(numrows) * 6.62193536908588E-06 AS predicatedcost
FROM (VALUES(500000), (1000000), (10000000)) AS D(numrows); 次のクエリを使用して、推定CPUコストを取得します。
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT CHECKSUM(NEWID()) as myorderid FROM (SELECT TOP (10000000) O1.orderid FROM dbo.Orders AS O1 CROSS JOIN dbo.Orders AS O2) AS D ORDER BY myorderid OPTION(MAXDOP 1);
次の結果が得られました:
numrows predicatedcost estimatedcost ratio
----------- --------------- -------------- ------
500000 43.4479 43.448 1.0000
1000000 91.4856 91.486 1.0000
10000000 1067.3300 1067.340 1.0000
大きな数の数式はかなりうまくいくようです。
すべてをまとめる
少数の行(<=5,000行)に対して明示的な並べ替えを使用してストリーム集計を適用するための総コストは次のとおりです。
<ソートI/Oコスト>+<ソートCPUコスト>+<ストリーム集約オペレーターコスト>=0.0112613
+ 9.99127891201865E-05 + @numrows * LOG(@ numrows)* 2.25061348918698E-06
+ @numrows * 0.0000006 + @numgroups * 0.0000005
図3には、このコストがどのように変化するかを示す面グラフがあります。
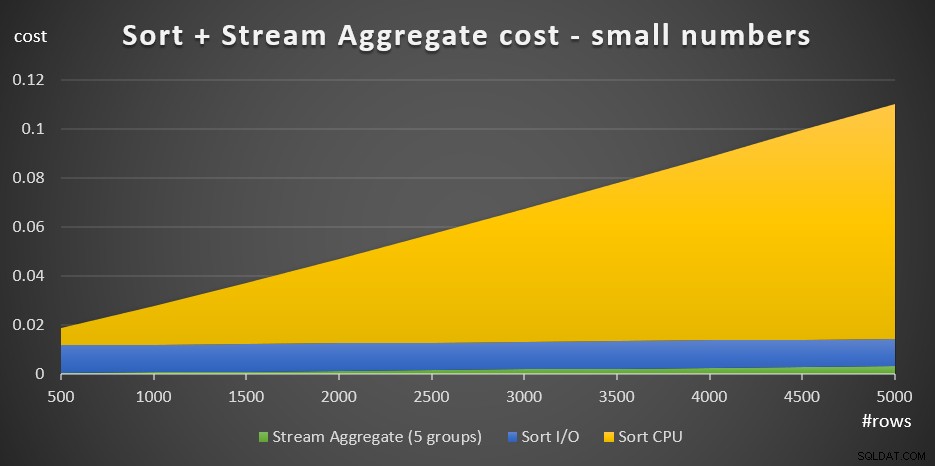
図3:少数のソート+ストリーム集計のコスト行
ソートCPUコストは、ソート+ストリームの総コストの中で最も重要な部分です。それでも、行数が少ない場合、StreamAggregateコストとコストのSortI/O部分は完全に無視できるわけではありません。視覚的には、グラフの3つの部分すべてをはっきりと見ることができます。
多数の行(> =20,000)の場合、原価計算式は次のとおりです。
0.0112613+ 1.35166186417734E-04 + @numrows * LOG(@numrows)* 6.62193536908588E-06
+ @numrows * 0.0000006 + @numgroups * 0.0000005
比較コストが小規模から大規模に移行する正確な方法を追求することにあまり価値はありませんでした。
図4には、多数のコストがどのように変化するかを示す面グラフがあります。
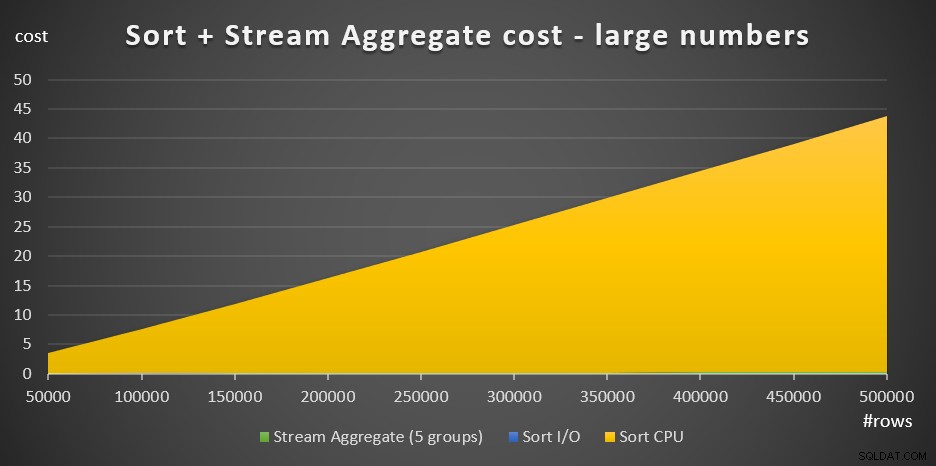
図4:多数の行
行数が多い場合、StreamAggregateコストとSortI / Oコストは、Sort CPUコストと比較してごくわずかであるため、グラフでは肉眼でも見えません。さらに、起動作業に起因するソートCPUコストの部分もごくわずかです。したがって、実際に意味のあるコスト計算の唯一の部分は、合計比較コストです。
@numrows * LOG(@numrows)*<比較コスト>これは、Sort + Stream Aggregate戦略のスケーリングを評価する必要がある場合、この主要な部分だけに単純化できることを意味します。たとえば、コストが100,000行から100,000,000行にどのようにスケーリングするかを評価する必要がある場合は、次の式を使用できます(比較コストは無関係であることに注意してください):
(100000000 * LOG(100000000)これは、行数が100,000から1,000倍に増加すると、推定コストが1,600倍に増加することを示しています。
1,000,000行から1,000,000,000行へのスケーリングは、次のように計算されます。
(1000000000 * LOG(1000000000))/(1000000 * LOG(1000000))=1500つまり、行数が1,000,000から1,000倍になると、推定コストは1,500倍になります。
これらは、Sort +StreamAggregate戦略のスケーリング方法に関する興味深い観察結果です。起動コストが非常に低く、線形スケーリングが追加されているため、この戦略は非常に少数の行ではうまく機能しますが、多数の行ではうまく機能しないことが予想されます。また、Stream Aggregateオペレーターだけが、ソートも必要な場合と比較して、コストのごく一部を占めるという事実は、サポートインデックスを作成できる状況であれば、パフォーマンスを大幅に向上させることができることを示しています。 。
シリーズの次のパートでは、HashAggregateアルゴリズムのスケーリングについて説明します。原価計算式を理解しようとするこの演習を楽しんでいる場合は、このアルゴリズムでそれを理解できるかどうかを確認してください。重要なのは、それに影響を与える要因、スケーリングの方法、および他のアルゴリズムよりも優れている条件を把握することです。