この記事では、あまり知られていないクエリオプティマイザの機能と制限について説明し、特定のケースでハッシュ結合のパフォーマンスが極端に低下する理由について説明します。
サンプルデータ
次のサンプルデータ作成スクリプトは、既存の数値テーブルに依存しています。これらのいずれかをまだお持ちでない場合は、以下のスクリプトを使用して効率的に作成できます。結果のテーブルには、100万から100万までの数値を持つ単一の整数列が含まれます。
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); サンプルデータ自体は、T1とT2の2つのテーブルで構成されています。どちらにも、pkという名前の順次整数主キー列とc1という名前の2番目のNULL可能列があります。テーブルT1には600,000行あり、偶数行のc1の値はpk列と同じであり、奇数行はnullです。テーブルc2には32,000行あり、列c1はすべての行でNULLです。次のスクリプトは、これらのテーブルを作成してデータを入力します。
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
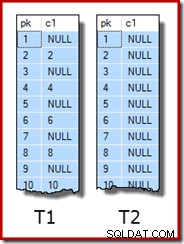
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; 各テーブルのサンプルデータの最初の10行は、次のようになります。
2つのテーブルを結合する
この最初のテストでは、列c1(pk列ではない)で2つのテーブルを結合し、結合する行のテーブルT1からpk値を返します。
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
テーブルT2のすべての行で列c1がNULLであるため、クエリは実際には行を返しません。したがって、等式結合述部に一致する行はありません。これは奇妙なことのように聞こえるかもしれませんが、実際の本番クエリに基づいていると確信しています(議論を容易にするために大幅に簡略化されています)。
この空の結果はANSI_NULLSの設定に依存しないことに注意してください。これは、nullリテラルまたは変数との比較の処理方法のみを制御するためです。列の比較の場合、等式述語は常にnullを拒否します。
この単純な結合クエリの実行プランには、いくつかの興味深い機能があります。まず、SQL Sentry Plan Explorerで実行前(「推定」)プランを確認します。
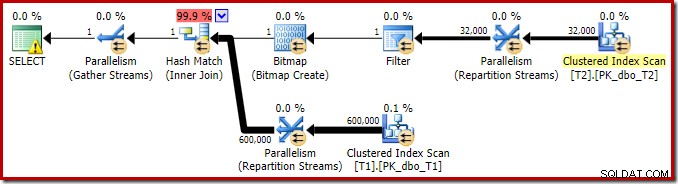
SELECTアイコンの警告は、列c1(含まれている列としてpkを使用)のテーブルT1にインデックスがないことについて不平を言っているだけです。インデックスの提案はここでは関係ありません。
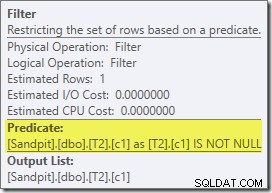
この計画で最初に関心のある実際の項目はフィルターです:
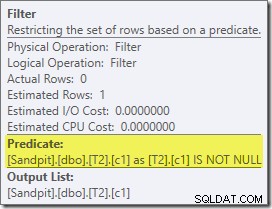
このISNOTNULL述語は、暗黙的ですが、ソースクエリには表示されません。 前述のように、結合述語で。明示的な追加演算子として分割され、結合操作の前に配置されているのは興味深いことです。フィルタがなくても、クエリは正しい結果を生成することに注意してください。結合自体はnullを拒否します。
フィルタは他の理由でも好奇心が強いです。推定コストは正確にゼロであり(32,000行で動作すると予想されますが)、残りの述語としてクラスター化インデックススキャンにプッシュダウンされていません。オプティマイザーは通常、これを行うことにかなり熱心です。
これらの両方は、このフィルターが最適化後の書き換えで導入されたという事実によって説明されます。クエリオプティマイザがコストベースの処理を完了した後、考慮される固定プランの書き換えは比較的少数です。これらの1つは、フィルターの導入を担当します。
文書化されていないトレースフラグ8607と使い慣れた3604を使用して、コストベースのプラン選択の出力(書き換え前)を確認し、テキスト出力をコンソールに送信します(SSMSの[メッセージ]タブ):
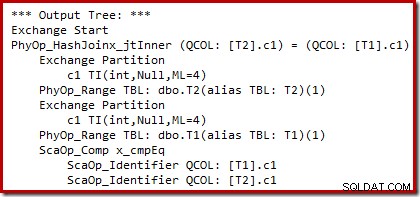
出力ツリーには、ハッシュ結合、2つのスキャン、およびいくつかの並列処理(交換)演算子が表示されます。テーブルT2のc1列にnull拒否フィルターはありません。
特定の最適化後の書き換えは、ハッシュ結合のビルド入力のみを調べます。状況の評価に応じて、結合キーでnullの行を拒否する明示的なフィルターを追加する場合があります。推定行数に対するフィルターの影響も実行プランに書き込まれますが、コストベースの最適化はすでに完了しているため、フィルターのコストは計算されません。明らかでない場合、すべてのコストベースの決定がすでに行われていると、コンピューティングコストは労力の無駄になります。
メインの最適化アクティビティが完了したため、フィルターはクラスター化インデックススキャンにプッシュダウンされるのではなく、ビルド入力に直接残ります。最適化後の書き換えは、事実上、完成した実行計画の土壇場での微調整です。
2番目の、まったく別の、最適化後の書き換えは、最終計画のビットマップ演算子を担当します(8607出力からも欠落していることに気付いたかもしれません):
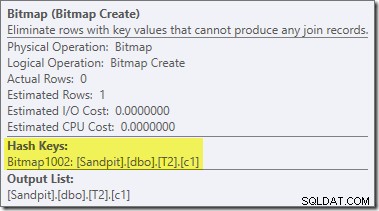
このオペレーターは、I/OとCPUの両方の推定コストもゼロです。 (コストベースの最適化ではなく)遅い調整によって導入された演算子としてそれを識別するもう1つのことは、その名前がビットマップの後に数字が続くことです。後で説明するように、コストベースの最適化中に導入される他のタイプのビットマップがあります。
今のところ、このビットマップについて重要なことは、ハッシュ結合のビルドフェーズ中に見られるc1値を記録することです。ハッシュがビルドフェーズからプローブフェーズに移行すると、完成したビットマップが結合のプローブ側にプッシュされます。ビットマップは、早期の半結合削減を実行するために使用され、結合できない可能性のある行をプローブ側から排除します。これについてさらに詳しく知りたい場合は、この件に関する以前の記事をご覧ください。
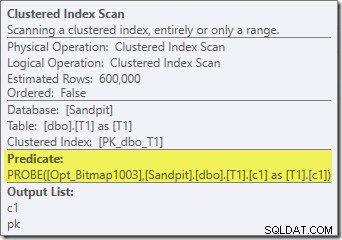
ビットマップの2番目の効果は、プローブ側のクラスター化インデックススキャンで確認できます。
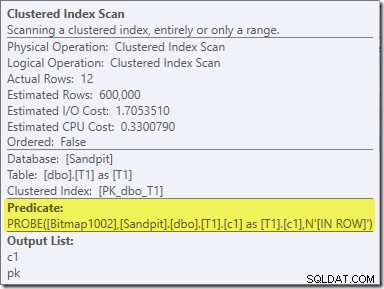
上のスクリーンショットは、テーブルT1のクラスター化インデックススキャンの一部としてチェックされている完成したビットマップを示しています。ソース列は整数であるため(bigintも機能します)、ビットマップチェックは、クエリプロセッサによってチェックされるのではなく、ストレージエンジンに完全にプッシュされます(「INROW」修飾子で示されます)。より一般的には、ビットマップは、交換から下に向かって、プローブ側の任意のオペレータに適用できます。クエリプロセッサがビットマップをプッシュできる範囲は、列のタイプとSQLServerのバージョンによって異なります。
この実行計画の主な機能の分析を完了するには、実行後(「実際の」)計画を確認する必要があります。
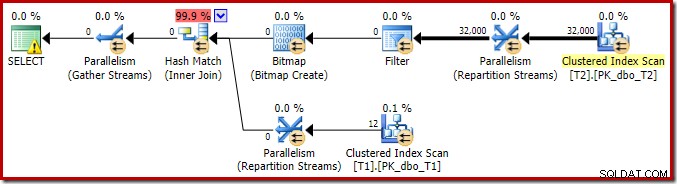
最初に気付くのは、T2スキャンとそのすぐ上の再パーティションストリーム交換の間のスレッド間での行の分散です。 1回のテスト実行で、4つの論理プロセッサを搭載したシステムで次のディストリビューションが見られました。
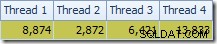
比較的少数の行での並列スキャンの場合のように、分布は特に均一ではありませんが、少なくともすべてのスレッドが何らかの作業を受け取りました。同じ再パーティションストリーム交換とフィルター間のスレッド分布は大きく異なります:
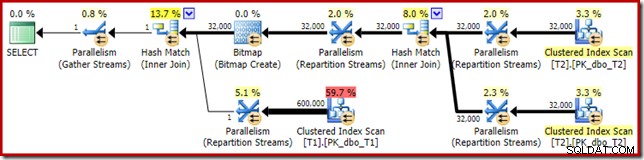
これは、テーブルT2の32,000行すべてが単一のスレッドによって処理されたことを示しています。理由を確認するには、交換プロパティを確認する必要があります:

この交換は、ハッシュ結合のプローブ側での交換と同様に、同じ結合キー値を持つ行がハッシュ結合の同じインスタンスになるようにする必要があります。 DOP 4には、4つのハッシュ結合があり、それぞれに独自のハッシュテーブルがあります。正しい結果を得るには、同じ結合キーを持つビルド側の行とプローブ側の行が同じハッシュ結合に到達する必要があります。そうしないと、プローブ側の行を間違ったハッシュテーブルと照合する可能性があります。
行モードの並列プランでは、SQL Serverは、結合列で同じハッシュ関数を使用して両方の入力を再パーティション化することでこれを実現します。この場合、結合は列c1にあるため、入力は、ハッシュ関数(パーティション化タイプ:ハッシュ)を結合キー列(c1)に適用することにより、スレッド間で分散されます。ここでの問題は、列c1にテーブルT2の単一の値(null)しか含まれていないため、32,000行すべてに同じハッシュ値が与えられ、すべてが同じスレッドに配置されることです。
幸いなことに、このクエリではこれは実際には重要ではありません。最適化後の書き換えフィルターは、多くの作業が行われる前にすべての行を削除します。私のラップトップでは、上記のクエリは約 70ms で実行されます(期待どおりに結果は生成されません)。 。
3つのテーブルを結合する
2番目のテストでは、テーブルT2から主キーのそれ自体に結合を追加します。
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
これにより、クエリの論理結果は変更されませんが、実行プランは変更されます。
予想どおり、主キーでのテーブルT2の自己結合は、そのテーブルから修飾される行数に影響を与えません。
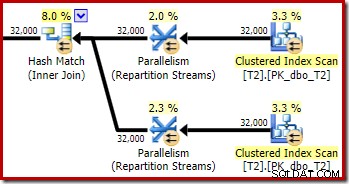
この計画セクションでは、スレッド間での行の分散も適切です。スキャンの場合、並列スキャンはオンデマンドで行をスレッドに分散するため、以前と同様です。今回はpk列である結合キーのハッシュに基づいて再パーティションを交換します。さまざまなpk値の範囲を考えると、結果のスレッド分布も非常に均一です。
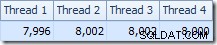
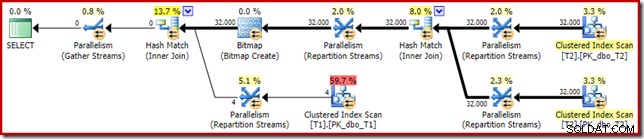
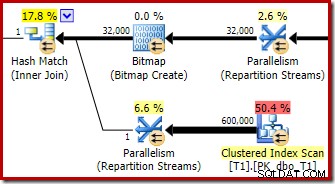
推定計画のより興味深いセクションに目を向けると、2つのテーブルのテストとはいくつかの違いがあります。

繰り返しになりますが、c1が結合キーであるため、ビルド側の交換はすべての行を同じスレッドにルーティングすることになります。したがって、再パーティションストリーム交換のパーティション列(テーブルT2のすべての行でc1はnullであることに注意してください)。
前のテストと比較して、計画のこのセクションには他に2つの重要な違いがあります。まず、ハッシュ結合のビルド側からnull-c1行を削除するフィルターがありません。その説明は、2番目の違いに関連しています。上の図からは明らかではありませんが、ビットマップが変更されています。
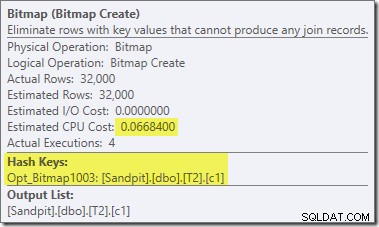
これはOpt_Bitmapであり、ビットマップではありません。違いは、このビットマップは、直前の書き換えではなく、コストベースの最適化中に導入されたことです。最適化されたビットマップを考慮するメカニズムは、スター結合クエリの処理に関連付けられています。スター結合ロジックには少なくとも3つの結合テーブルが必要であるため、これが最適化の理由を説明しています。 2テーブル結合の例では、ビットマップは考慮されていません。
この最適化されたビットマップの推定CPUコストはゼロではなく、オプティマイザーによって選択された全体的な計画に直接影響します。プローブ側のカーディナリティ推定への影響は、RepartitionStreamsオペレーターで確認できます。
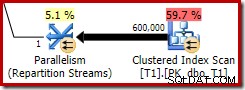
最初のテストで見たように、ビットマップが最終的にストレージエンジン(「INROW」)に完全にプッシュされたとしても、カーディナリティ効果が交換で見られることに注意してください(ただし、Opt_Bitmapリファレンスに注意してください):
>
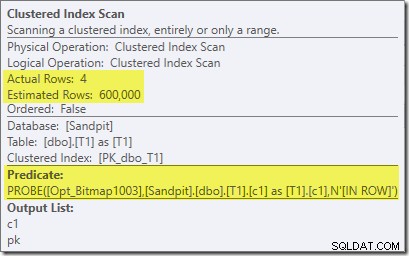
実行後(「実際の」)計画は次のとおりです。
最適化されたビットマップの予測される有効性は、ヌルフィルターの個別の最適化後の書き換えが適用されないことを意味します。個人的には、これは残念なことだと思います。フィルターを使用してnullを早期に削除すると、ビットマップを作成し、ハッシュテーブルにデータを入力し、テーブルT1のビットマップ拡張スキャンを実行する必要がなくなるためです。それにもかかわらず、オプティマイザーは別の方法で決定し、この場合はそれについて議論することはありません。
テーブルT2の余分な自己結合、および欠落しているフィルターに関連する余分な作業にもかかわらず、この実行プランは、期待される結果(行なし)を短時間で生成します。私のラップトップでの一般的な実行には、約200ミリ秒かかります 。
データ型の変更
この3番目のテストでは、両方のテーブルの列c1のデータ型を整数から10進数に変更します。この選択について特に特別なことは何もありません。同じ効果は、整数またはbigintではない任意の数値タイプで見られます。
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
3結合結合クエリの再利用:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
推定実行計画は非常によく知られているようです:
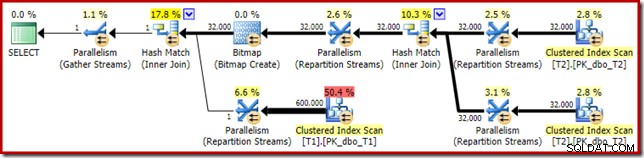
データ型の変更により、最適化されたビットマップをストレージエンジンが「INROW」に適用できなくなったことを除けば、実行プランは基本的に同じです。以下のキャプチャは、スキャンプロパティの変更を示しています。
残念ながら、パフォーマンスはかなり劇的に影響を受けます。このクエリは70ミリ秒または200ミリ秒ではなく、約20分で実行されます。 。次の実行後プランを作成したテストでは、実行時間は実際には22分29秒でした。

最も明らかな違いは、最適化されたビットマップフィルターが適用された後でも、テーブルT1のクラスター化インデックススキャンが300,000行を返すことです。ビットマップはc1列にnullのみを含む行に基づいて構築されているため、これはある程度意味があります。ビットマップは、T1スキャンからnull以外の行を削除し、c1のnull値を持つ300,000行だけを残します。 T1の行の半分がnullであることを忘れないでください。
それでも、32,000行と300,000行を結合するのに20分以上かかるのは奇妙に思えます。ご参考までに、実行全体で1つのCPUコアが100%に固定されていました。このパフォーマンスの低下と極端なリソース使用量の説明は、以前に調査したいくつかのアイデアに基づいています。
たとえば、並列実行アイコンにもかかわらず、T2からのすべての行が同じスレッドに配置されることはすでにわかっています。注意として、行モードの並列ハッシュ結合では、結合列(c1)で再パーティション化する必要があります。 T2のすべての行は、列c1で同じ値(null)を持っているため、すべての行が同じスレッドになります。同様に、ビットマップフィルターを通過するT1のすべての行も、列c1にnullがあるため、同じスレッドに再パーティション化されます。これが、単一のコアがすべての作業を行う理由を説明しています。
32,000行と300,000行をハッシュ結合するのに20分かかることは、特に両側の結合列がnullであり、とにかく結合されないため、依然として不合理に思えるかもしれません。これを理解するには、このハッシュ結合がどのように機能するかを考える必要があります。
ビルド入力(32,000行)は、結合列c1を使用してハッシュテーブルを作成します。すべてのビルド側の行には結合列c1の同じ値(null)が含まれているため、これは32,000行すべてが同じハッシュバケットに含まれることを意味します。ハッシュ結合が一致のプローブに切り替わると、c1列がnullの各プローブ側の行も同じバケットにハッシュされます。次に、ハッシュ結合は、そのバケット内の32,000エントリすべてをチェックして一致するかどうかを確認する必要があります。
300,000のプローブ行をチェックすると、32,000の比較が300,000回行われます。これは、ハッシュ結合の最悪のケースです。すべてのビルド側の行が同じバケットにハッシュされ、本質的にデカルト積になります。これは、ハッシュが長いハッシュバケットチェーンに従うため、実行時間が長く、プロセッサの使用率が100%一定であることを説明しています。
このパフォーマンスの低下は、ハッシュ結合へのビルド入力のnullを排除するための最適化後の書き換えが存在する理由を説明するのに役立ちます。この場合、フィルターが適用されなかったのは残念です。
回避策
オプティマイザーは、最適化されたビットマップがテーブルT1からすべての行をフィルターで除外すると誤って推定するため、このプランの形状を選択します。この見積もりは、クラスター化インデックススキャンではなく再パーティションストリームに表示されますが、これが決定の基礎になります。念のため、ここでも実行前計画の関連セクションを示します。
これが正しい見積もりである場合、ハッシュ結合を処理するのにまったく時間がかかりません。データ型が単純な整数またはbigintでない場合、最適化されたビットマップの選択性の見積もりが非常に間違っているのは残念です。整数またはbigintキーで構築されたビットマップは、結合できないnull行を除外することもできるようです。これが実際に当てはまる場合、これが整数またはbigint結合列を好む主な理由です。
以下の回避策は、主に、問題のある最適化されたビットマップを排除するという考えに基づいています。
シリアル実行
最適化されたビットマップが考慮されないようにする1つの方法は、非並列プランを要求することです。行モードのビットマップ演算子(最適化されているかどうかに関係なく)は、並列プランでのみ表示されます:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); そのクエリは、FORCE ORDERヒントを使用してわずかに異なる構文を使用して表現され、以前の並列プランとより簡単に比較できるプラン形状を生成します。重要な機能はMAXDOP1のヒントです。
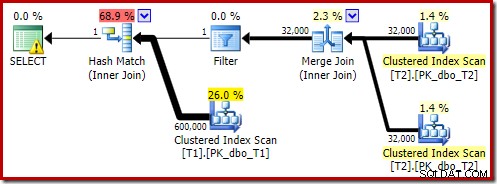
その推定計画は、最適化後の書き換えフィルターが復元されていることを示しています:
実行後のバージョンのプランは、ビルド入力からすべての行を除外することを示しています。つまり、プローブ側のスキャンを完全にスキップできます。
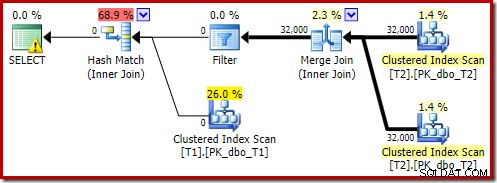
ご想像のとおり、このバージョンのクエリは非常に高速に実行されます。私にとっては平均で約20ミリ秒です。 FORCE ORDERヒントとクエリの書き換えなしで、同様の効果を達成できます。
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
この場合、オプティマイザーは別の平面形状を選択し、フィルターはT2のスキャンの真上に配置されます:
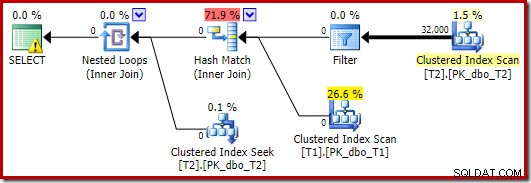
これは、予想どおり、さらに高速に(約10ミリ秒で)実行されます。当然、存在する(そして結合可能な)行の数がはるかに多い場合、これは適切な選択ではありません。
最適化されたビットマップをオフにする
最適化されたビットマップをオフにするクエリヒントはありませんが、文書化されていないいくつかのトレースフラグを使用して同じ効果を達成できます。いつものように、これは単に利息の価値のためです。これらを実際のシステムやアプリケーションで使用したくない場合:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);>
結果の実行プランは次のとおりです。
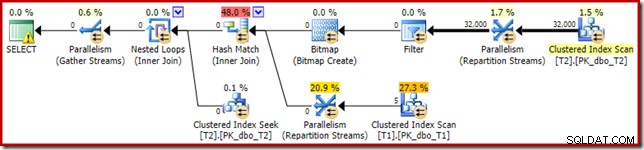
最適化されたビットマップではなく、最適化後の書き換えビットマップがあるビットマップ:
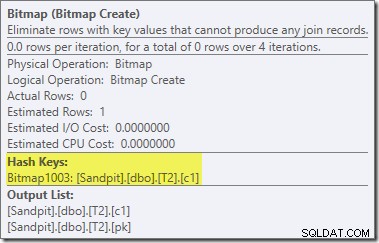
ゼロコストの見積もりとビットマップ名(Opt_Bitmapではなく)に注意してください。コスト見積もりを歪めるための最適化されたビットマップがないと、ヌル拒否フィルターを含む最適化後の書き換えがアクティブになります。この実行プランは約70msで実行されます 。
同じ実行プラン(フィルターと最適化されていないビットマップを使用)は、スター結合ビットマッププランの生成を担当するオプティマイザールールを無効にすることによっても作成できます(ここでも、厳密に文書化されておらず、実際には使用されません):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
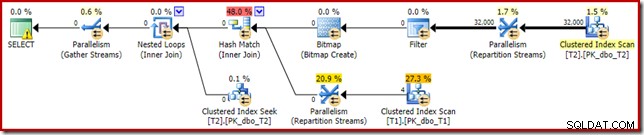
明示的なフィルターを含む
これは最も簡単なオプションですが、これまでに説明した問題を認識している場合にのみ実行することを考えます。 T2.c1からnullを削除する必要があることがわかったので、これをクエリに直接追加できます。
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
T2.c1 IS NOT NULL; -- New! 結果として得られる推定実行計画は、おそらくあなたが期待しているものとはまったく異なります。
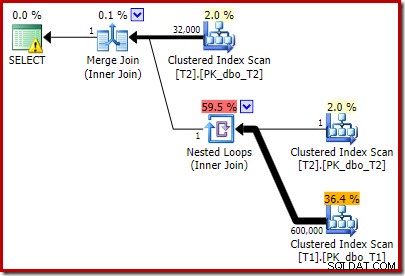
追加した追加の述語は、T2の中央のクラスター化インデックススキャンにプッシュされました:
実行後の計画は次のとおりです。
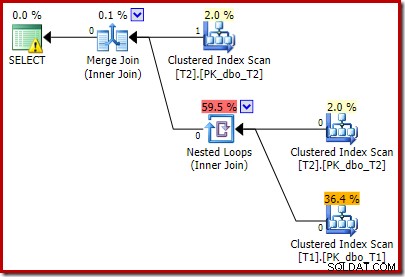
追加した述語の影響により、上部の入力から1つの行を読み取った後、下部の入力で行を見つけることができなかったため、マージ結合がシャットダウンすることに注意してください。ネストされたループの結合がその駆動入力で行を取得することはないため、テーブルT1のクラスター化インデックススキャンはまったく実行されません。この最終的なクエリフォームは、1〜2ミリ秒で実行されます。
最終的な考え
この記事では、あまり知られていないクエリオプティマイザの動作を調査し、特定のケースでハッシュ結合のパフォーマンスが極端に低下する理由を説明するためのかなりの根拠を説明しました。
オプティマイザが等式結合の前にnull拒否フィルタを定期的に追加しない理由を尋ねたくなるかもしれません。これは、十分な一般的なケースでは有益ではないと考えることしかできません。ほとんどの結合では、多くのnull =null拒否が発生することは想定されておらず、述語を定期的に追加すると、特に多くの結合列が存在する場合、すぐに逆効果になる可能性があります。ほとんどの結合では、明示的なフィルターを導入するよりも、結合演算子内でnullを拒否する方が(コストモデルの観点から)おそらく優れたオプションです。
ハッシュ結合のビルド入力に到達する前にヌル結合行を拒否するように設計された最適化後の書き換えによって、最悪のケースが現れるのを防ぐ努力がなされているようです。最適化されたビットマップフィルターの効果とこの書き換えの適用の間には、不幸な相互作用が存在するようです。また、このパフォーマンスの問題が発生した場合、実行計画だけから診断することは非常に困難です。
今のところ、最良のオプションは、null許容列でのハッシュ結合に関するこの潜在的なパフォーマンスの問題を認識しており、必要に応じて効率的な実行プランが作成されるように、明示的なnull拒否述語(コメント付き!)を追加することです。 MAXDOP 1ヒントを使用すると、わかりやすいフィルターが存在する代替プランが明らかになる場合もあります。
原則として、整数型の列に結合して存在するデータを検索するクエリは、代替手段よりもオプティマイザーモデルと実行エンジンの機能に適合する傾向があります。
謝辞
SQL_Sasquatch(@sqL_handLe)が、テクニカル分析で元の記事に回答することを許可してくれたことに感謝します。ここで使用されているサンプルデータは、その記事に大きく基づいています。
また、Rob Farley(blog | twitter)の長年にわたる技術的な議論、特に2015年1月に、equi-joinの余分なnull拒否述語の影響について議論してくれたことに感謝します。 Robは、Inverse Predicatesを含め、関連するトピックについて何度か書いています。交差する前に、両方の方向を見てください。