sql.dnhlms.comでブログを書いているDanHolmesによる投稿
SQL Server Books Online(BOL)、ホワイトペーパー、およびその他の多くのソースには、テーブルまたはインデックスの統計を更新する方法と理由が示されています。ただし、これらの値を形成する方法は1つしかありません。利用可能な200ステップの範囲内で、希望どおりに統計を作成する方法を紹介します。
免責事項 :これは、アプリケーション、データベース、およびユーザーの通常のワークフローとアプリケーションの使用パターンを知っているので、うまくいきます。ただし、文書化されていないコマンドを使用するため、誤って使用すると、アプリケーションのパフォーマンスが大幅に低下する可能性があります。私たちのアプリケーションでは、Schedulingユーザーは、明日と次の数日間のイベントを表すデータを定期的に読み書きしています。今日以前のデータはスケジューラーによって使用されません。朝一番に、明日のデータセットは数百行から始まり、正午までに1400以上になる可能性があります。次のグラフは、行数を示しています。このデータは、2015年11月18日水曜日の朝に収集されました。これまで、週末と翌日を除いて、通常の行数は約1,400であることがわかります。
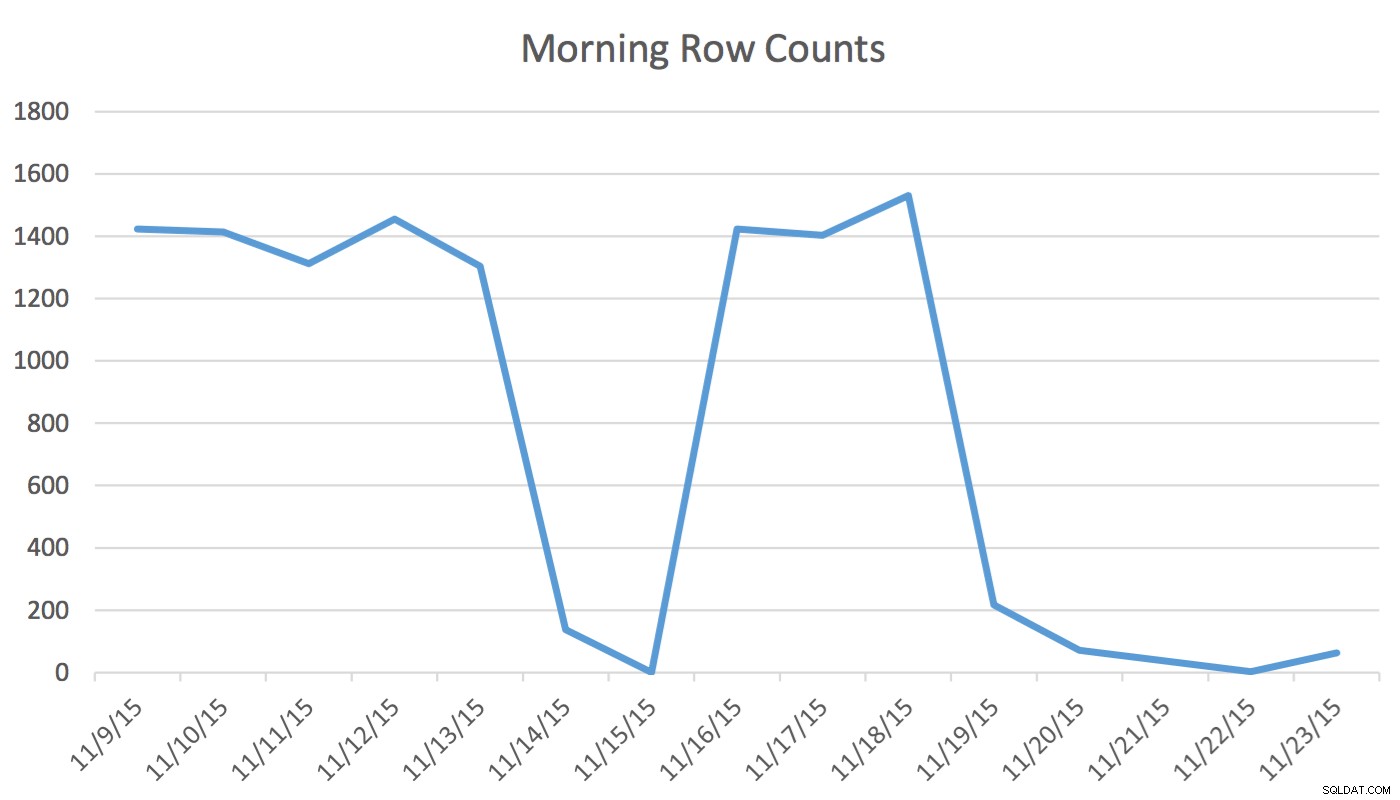
スケジューラの場合、関連するデータは次の数日のみです。今日起こっていることと昨日起こったことは彼の活動とは関係ありません。では、これはどのように問題を引き起こすのでしょうか?このテーブルには2,259,205行あります。これは、朝から正午までの行数の変更では、SQLServerが開始する統計の更新をトリガーするのに十分ではないことを意味します。さらに、UPDATE STATISTICSを使用して統計を作成する手動でスケジュールされたジョブ テーブル内のすべてのデータのサンプルをヒストグラムに入力しますが、関連情報が含まれていない場合があります。この行数のデルタは、計画を変更するのに十分です。ただし、統計の更新と正確なヒストグラムがないと、データが変更されても計画が改善されることはありません。
2015年11月4日付けのバックアップからのこのテーブルのヒストグラムの関連する選択は、次のようになります。
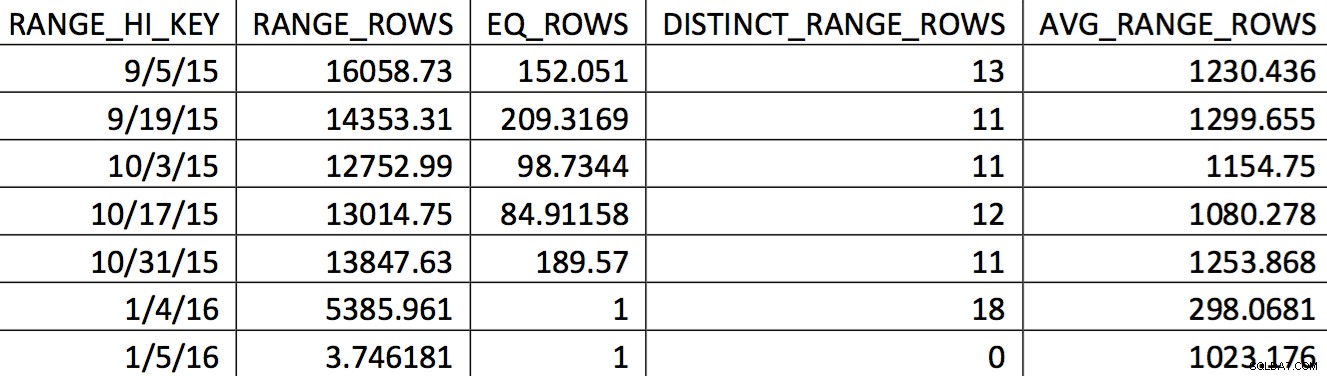
対象の値は、ヒストグラムに正確に反映されていません。 2015年11月5日の日付に使用されるのは、2016年1月4日の高値になります。グラフに基づくと、このヒストグラムは、対象の日付のオプティマイザーにとって明らかに適切な情報源ではありません。使用する値をヒストグラムに強制することは信頼できないので、どうすればそれを行うことができますか?私の最初の試みは、WITH SAMPLEを繰り返し使用することでした。 UPDATE STATISTICSのオプション 必要な値がヒストグラムに含まれるまでヒストグラムをクエリします(ここで詳しく説明します)。最終的に、そのアプローチは信頼できないことが判明しました。
このヒストグラムは、このタイプの動作を伴う計画につながる可能性があります。行を過小評価すると、ネストされたループ結合とインデックスシークが生成されます。その後、このプランを選択したため、読み取り値は本来よりも高くなります。これは、ステートメントの期間にも影響します。
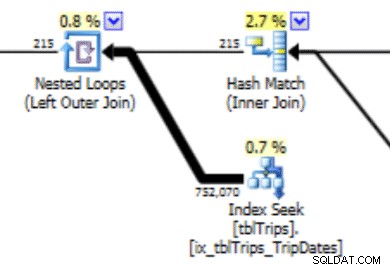
はるかにうまく機能するのは、希望どおりにデータを作成することです。その方法は次のとおりです。
UPDATE STATISTICSのサポートされていないオプションがあります :STATS_STREAM 。これは、Microsoftカスタマーサポートが統計をエクスポートおよびインポートするために使用するため、テーブルにすべてのデータがなくてもオプティマイザーを再作成できます。その機能を使用できます。アイデアは、カスタマイズしたい統計のDDLを模倣するテーブルを作成することです。関連するデータがテーブルに追加されます。統計はエクスポートされ、元のテーブルにインポートされます。
この場合、それはNULL以外の日付の200行と、NULL値を含む1行のテーブルです。さらに、そのテーブルには、ヒストグラム値が不良なインデックスと一致するインデックスがあります。
テーブルの名前はtblTripsScheduledです。 。 (id, TheTripDate)に非クラスター化インデックスがあります TheTripDateのクラスター化されたインデックス 。他にもいくつかの列がありますが、重要なのはインデックスに関係する列だけです。
テーブルとインデックスを模倣するテーブル(必要に応じて一時テーブル)を作成します。テーブルとインデックスは次のようになります:
CREATE TABLE #tbltripsscheduled_cix_tripsscheduled(
id INT NOT NULL
, tripdate DATETIME NOT NULL
, PRIMARY KEY NONCLUSTERED(id, tripdate)
);
CREATE CLUSTERED INDEX thetripdate ON #tbltripsscheduled_cix_tripsscheduled(tripdate);
次に、統計の基になる200行のデータをテーブルに入力する必要があります。私の状況では、それは次の60日までの日です。過去および60日を超えると、10日ごとに「ランダムな」選択が行われます。 (cnt CTEの値はデバッグ値です。最終結果には影響しません。)rnの降順 列には、60日が含まれ、その後、可能な限り過去が含まれるようにします。
DECLARE @date DATETIME = '20151104';
WITH tripdates
AS
(
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE NOT thetripdate BETWEEN @date AND @date
AND thetripdate < DATEADD(DAY, 60, @date) --only look 60 days out GROUP BY thetripdate
HAVING DATEDIFF(DAY, 0, thetripdate) % 10 = 0
UNION ALL
SELECT thetripdate, COUNT(*) cnt
FROM dbo.tbltripsscheduled
WHERE thetripdate BETWEEN @date AND DATEADD(DAY, 60, @date)
GROUP BY thetripdate
),
tripdate_top_200
AS
(
SELECT *
FROM
(
SELECT *, ROW_NUMBER() OVER(ORDER BY thetripdate DESC) rn
FROM tripdates
) td
WHERE rn <= 200
)
INSERT #tbltripsscheduled_cix_tripsscheduled (id, tripdate)
SELECT t.tripid, t.thetripdate
FROM tripdate_top_200 tp
INNER JOIN dbo.tbltripsscheduled t ON t.thetripdate = tp.thetripdate;
これで、テーブルには、今日のユーザーにとって価値のあるすべての行と、選択した履歴行が表示されます。列TheTripdateの場合 null許容型の場合、挿入には次のものも含まれます。
UNION ALL SELECT id, thetripdate FROM dbo.tbltripsscheduled WHERE thetripdate IS NULL;
次に、一時テーブルのインデックスの統計を更新します。
UPDATE STATISTICS #tbltrips_IX_tbltrips_tripdates (tripdates) WITH FULLSCAN;
次に、これらの統計を一時テーブルにエクスポートします。そのテーブルは次のようになります。 DBCC SHOW_STATISTICS WITH HISTOGRAMの出力と一致します 。
CREATE TABLE #stats_with_stream
(
stream VARBINARY(MAX) NOT NULL
, rows INT NOT NULL
, pages INT NOT NULL
);
DBCC SHOW_STATISTICS 統計をストリームとしてエクスポートするオプションがあります。私たちが望んでいるのはそのストリームです。そのストリームは、UPDATE STATISTICSと同じストリームでもあります。 ストリームオプションはを使用します。そのためには:
INSERT INTO #stats_with_stream --SELECT * FROM #stats_with_stream
EXEC ('DBCC SHOW_STATISTICS (N''tempdb..#tbltripsscheduled_cix_tripsscheduled'', thetripdate)
WITH STATS_STREAM,NO_INFOMSGS'); 最後のステップは、ターゲットテーブルの統計を更新するSQLを作成し、それを実行することです。
DECLARE @sql NVARCHAR(MAX);
SET @sql = (SELECT 'UPDATE STATISTICS tbltripsscheduled(cix_tbltripsscheduled) WITH
STATS_STREAM = 0x' + CAST('' AS XML).value('xs:hexBinary(sql:column("stream"))',
'NVARCHAR(MAX)') FROM #stats_with_stream );
EXEC (@sql); この時点で、ヒストグラムをカスタムビルドのものに置き換えました。ヒストグラムを確認することで確認できます:
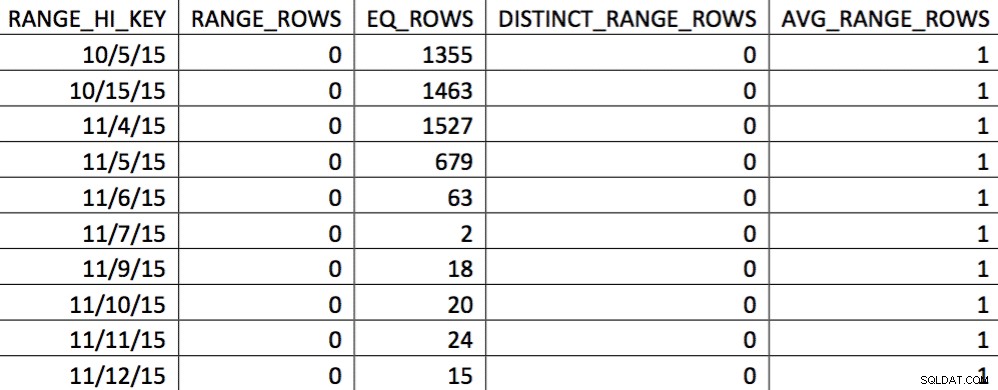
この11/4のデータの選択では、11/4以降のすべての日が表示され、履歴データが正確に表示されます。前に示したクエリプランの部分を再検討すると、修正された統計に基づいてオプティマイザがより適切に選択されたことがわかります。
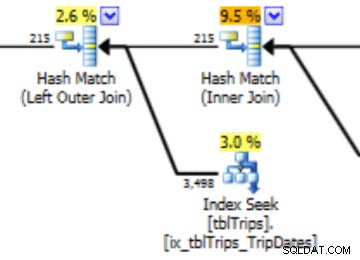
インポートされた統計にはパフォーマンス上の利点があります。統計を計算するためのコストは「オフライン」テーブルにあります。本番テーブルの唯一のダウンタイムは、ストリームのインポートの期間です。
このプロセスは文書化されていない機能を使用しており、危険である可能性があるように見えますが、簡単に元に戻すことができることを忘れないでください:更新統計ステートメント。問題が発生した場合は、標準のT-SQLを使用して統計をいつでも更新できます。
このコードを定期的に実行するようにスケジュールすると、転換点を超えて変化するが統計の更新をトリガーするのに十分ではないデータセットが与えられた場合、オプティマイザーがより良い計画を作成するのに大いに役立ちます。
この記事の最初のドラフトを終えたとき、最初のグラフのテーブルの行数が217から717に変更されました。これは300%の変更です。これは、オプティマイザーの動作を変更するには十分ですが、統計の更新をトリガーするには十分ではありません。このデータの変更は、悪い計画を残していたでしょう。この問題が解決されるのは、ここで説明するプロセスです。
参照:
- 統計の更新(オンラインブック)
- SQL2008統計ホワイトペーパー
- 転換点検索