SQL Serverのバグについて学ぶための優れた方法の1つは、累積的な更新プログラムとサービスパックがリリースされたときにリリースノートを読むことです。ただし、これはSQLServerの機能強化についても学ぶための優れた方法である場合があります。
SQL Server 2014 ServicePack1の累積的な更新6 SQLServerでのUPDATESTATISTICSタスクのロック動作を変更する新しいトレースフラグ7471が導入されました(KB#3156157を参照)。この投稿では、ロック動作の違いと、このトレースフラグが役立つ可能性のある場所について説明します。
この投稿に適切なデモ環境を設定するために、AdventureWorks2014データベースを使用し、ブログで利用可能なスクリプトに基づいて拡大バージョンのSalesOrderDetailテーブルを作成しました。 SalesOrderDetailEnlargedテーブルのサイズが2GBに拡大されたため、テーブルのさまざまな統計に対してUPDATE STATISTICSWITHFULLSCAN操作を同時に実行できます。次に、sp_whoisactiveを使用して、両方のセッションで保持されているロックを調べました。
TF7471なしの動作
SQL Serverのデフォルトの動作では、テーブルに対してUPDATE STATISTICSコマンドが実行されるたびに、テーブルのOBJECT.UPDSTATSリソースに排他ロック(X)が必要です。これは、更新する統計に異なるインデックス名を使用して、Sales.SalesOrderDetailEnlargedテーブルに対してUPDATE STATISTICSWITHFULLSCANを2回同時に実行した場合のsp_whoisactive出力で確認できます。これにより、最初の実行が完了するまで、UPDATESTATISTICSの2番目の実行がブロックされます。
UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="OBJECT.UPDSTATS" request_mode="X" request_status="GRANT" request_count="1" />
</Locks>
</Object> UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([IX_SalesOrderDetailEnlarged_ProductID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT.UPDSTATS" request_mode="X" request_status="WAIT" request_count="1" />
</Locks>
</Object> OBJECT.UPDSTATSにあるロックリソースの粒度により、同じテーブルに対する複数の統計の同時更新が防止されます。近年のハードウェアの機能強化により、SQL Serverの実装に共通する潜在的なボトルネックが実際に変更されました。また、DBCC CHECKDBがより高速に実行されるように変更が加えられたのと同様に、UPDATE STATISTICSのロック動作が変更され、統計の同時更新が可能になりました。同じテーブルを使用すると、VLDBのメンテナンスウィンドウを大幅に短縮できます。特に、エンドユーザーのエクスペリエンスに影響を与えることなく同時更新を実行できる十分なCPUとI/Oサブシステムの容量がある場合はそうです。
TF7471での動作
トレースフラグ7471を使用したロック動作により、OBJECT.UPDSTATSリソースでの排他ロック(X)の要求から、更新中の特定の統計のMETADATA.STATSリソースでの更新ロック(U)の要求に変更され、同時実行が可能になります。同じテーブルのUPDATESTATISTICSの。トレースフラグが有効になっている同じUPDATESTATISTICSWITHFULLCANコマンドのsp_whoisactiveの出力を以下に示します。
UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="U" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
</Locks>
</Object> UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([IX_SalesOrderDetailEnlarged_ProductID]) WITH FULLSCAN; <Objects>
<Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="IX_SalesOrderDetailEnlarged_ProductID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="U" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
</Locks>
</Object> ますます一般的になりつつあるVLDBの場合、これにより、サーバー全体で統計の更新を実行するのにかかる時間に大きな違いが生じる可能性があります。
最近、ServiceBrokerとOlaHallengrenのメンテナンススクリプトを使用したSQLServerの並列メンテナンスソリューションについてブログを書きました。これは、夜間のメンテナンスタスクを最適化し、CPUとI/Oの容量が十分にあるサーバーでインデックスの再構築と統計の更新に必要な時間を短縮する方法です。利用可能。そのソリューションの一部として、インデックスの再構築/再編成とUPDATE STATISTICSタスクの両方で、同じテーブルに対して同時に実行されないようにするために、ServiceBrokerにタスクをキューに入れる順序を強制しました。これの目的は、メンテナンスタスクが終了するまで、ワーカーを可能な限りビジー状態に保つことでした。メンテナンスタスクでは、同時タスクのブロックに基づいて実行がシリアル化されます。
その投稿の処理にいくつかの変更を加えて、統計の同時更新のみでこのトレースフラグの効果をテストしました。結果は、以下のとおりです。
同時統計更新パフォーマンスのテスト
Service Broker構成を使用して統計を並行して更新するだけのパフォーマンスをテストするために、次のスクリプトを使用して、AdventureWorks2014データベースのすべての列に列統計を作成し、実行するDDLコマンドを生成することから始めました。
USE [AdventureWorks2014]
GO
SELECT *, 'DROP STATISTICS ' + QUOTENAME(c.TABLE_SCHEMA) + '.'
+ QUOTENAME(c.TABLE_NAME) + '.' + QUOTENAME(c.TABLE_NAME
+ '_' + c.COLUMN_NAME) + ';
GO
CREATE STATISTICS ' +QUOTENAME(c.TABLE_NAME + '_' + c.COLUMN_NAME)
+ ' ON ' + QUOTENAME(c.TABLE_SCHEMA) + '.' + QUOTENAME(c.TABLE_NAME)
+ ' (' +QUOTENAME(c.COLUMN_NAME) + ');' + '
GO'
FROM INFORMATION_SCHEMA.COLUMNS AS c
INNER JOIN INFORMATION_SCHEMA.TABLES AS t
ON c.TABLE_CATALOG = t.TABLE_CATALOG AND
c.TABLE_SCHEMA = t.TABLE_SCHEMA AND
c.TABLE_NAME = t.TABLE_NAME
WHERE t.TABLE_TYPE = 'BASE TABLE'
AND c.DATA_TYPE <> N'xml'; これは通常実行したいことではありませんが、統計の更新に対するトレースフラグの影響を並行してテストするための多くの統計を提供します。タスクをServiceBrokerにキューに入れる順序をランダム化する代わりに、テーブルのIDに基づいてCommandLogテーブルに存在するタスクをキューに入れ、すべてのコマンドがキューに入れられるまでIDを1ずつ増やします。処理用。
USE [master]; -- Clear the Command Log TRUNCATE TABLE [master].[dbo].[CommandLog]; DECLARE @MaxID INT; SELECT @MaxID = MAX(ID) FROM master.dbo.CommandLog; SELECT @MaxID = ISNULL(@MaxID, 1) ---- Load new tasks into the Command Log EXEC master.dbo.IndexOptimize @Databases = N'AdventureWorks2014', @FragmentationLow = NULL, @FragmentationMedium = NULL, @FragmentationHigh = NULL, @UpdateStatistics = 'ALL', @StatisticsSample = 100, @LogToTable = 'Y', @Execute = 'N'; DECLARE @NewMaxID INT SELECT @NewMaxID = MAX(ID) FROM master.dbo.CommandLog; USE msdb; DECLARE @CurrentID INT = @MaxID WHILE (@CurrentID <= @NewMaxID) BEGIN -- Begin a conversation and send a request message DECLARE @conversation_handle UNIQUEIDENTIFIER; DECLARE @message_body XML; BEGIN TRANSACTION; BEGIN DIALOG @conversation_handle FROM SERVICE [OlaHallengrenMaintenanceTaskService] TO SERVICE N'OlaHallengrenMaintenanceTaskService' ON CONTRACT [OlaHallengrenMaintenanceTaskContract] WITH ENCRYPTION = OFF; SELECT @message_body = N'<CommandLogID>'+CAST(@CurrentID AS NVARCHAR)+N'</CommandLogID>'; SEND ON CONVERSATION @conversation_handle MESSAGE TYPE [OlaHallengrenMaintenanceTaskMessage] (@message_body); COMMIT TRANSACTION; SET @CurrentID = @CurrentID + 1; END WHILE EXISTS (SELECT 1 FROM OlaHallengrenMaintenanceTaskQueue WITH(NOLOCK)) BEGIN WAITFOR DELAY '00:00:01.000' END WAITFOR DELAY '00:00:06.000' SELECT DATEDIFF(ms, MIN(StartTime), MAX(EndTime)) FROM master.dbo.CommandLog; GO 10
次に、すべてのタスクが完了するのを待ち、タスク実行の開始時間と終了時間のデルタを測定し、平均10回のテストを行って、デフォルトのサンプリングとフルスキャンの更新を同時に使用して統計を更新するだけの改善点を判断しました。
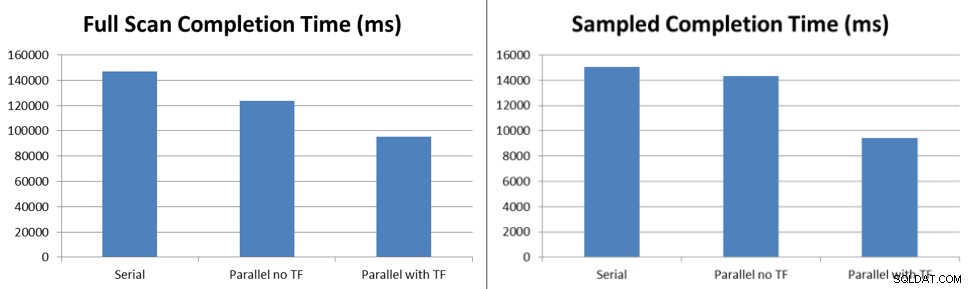
テスト結果は、トレースフラグのないデフォルトの動作でブロックが発生した場合でも、統計のサンプリングされた更新が6%速く実行され、フルスキャンの更新が16%速く実行され、5つのスレッドがServiceBrokerにキューに入れられたタスクを処理することを示しています。トレースフラグ7471を有効にすると、同じサンプリングされた統計の更新が38%速く実行され、フルスキャンの更新が45%速く実行され、5つのスレッドがServiceBrokerにキューに入れられたタスクを処理します。
TF7471の潜在的な課題
テスト結果は説得力がありますが、この世界で無料のものはありません。これを最初にテストしたときに、ラップトップで使用していたVMのサイズに問題が発生し、ワークロードの問題が発生しました。
私はもともと、この目的のために特別にセットアップした4GBRAMを備えた4vCPUVMを使用して並列メンテナンスをテストしていました。 Service Brokerでアクティベーション手順のMAX_QUEUE_READERSの数を増やし始めると、トレースフラグが有効になっているときにRESOURCE_SEMAPHORE待機の問題が発生し始め、メモリ付与要件により、AdventureWorks2014データベースの拡大されたテーブルの統計を並行して更新できるようになりました。実行されていたUPDATESTATISTICSコマンドごとに。これは、VM構成を16GB RAMに変更することで軽減されましたが、メモリ許可の不足は実行しようとしている可能性のあるエンドユーザーの要求にも影響するため、インデックスのメンテナンスを含め、より大きなテーブルで並列タスクを実行するときに監視および監視するものです。より大きなメモリ許可も必要です。
製品チームはこのトレースフラグについてもブログに書いています。彼らの投稿では、統計が作成されている間、統計の同時更新中にデッドロックシナリオが発生する可能性があると警告しています。これは、テスト中にまだ遭遇したことではありませんが、間違いなく知っておくべきことです(Kendra Littleも警告しています)。その結果、このトレースフラグは、並列メンテナンスタスクの実行中にのみ有効にし、通常のワークロード期間中は無効にすることをお勧めします。
お楽しみください!