SQL Server 2008で導入された多くの新機能の1つは、データ圧縮でした。行レベルまたはページレベルでの圧縮は、データを圧縮および解凍するためにもう少しCPUを必要とするというトレードオフで、ディスクスペースを節約する機会を提供します。システムの大部分はCPUバウンドではなく、IOバウンドであると頻繁に主張されているため、トレードオフには価値があります。キャッチ?データ圧縮を使用するには、EnterpriseEditionを使用している必要がありました。 SQL Server 2016 SP1のリリースにより、状況が変わりました。 SQL Server 2016SP1以降のStandardEditionを実行している場合は、データ圧縮を使用できるようになりました。圧縮用の新しい組み込み関数であるCOMPRESS(および対応するDECOMPRESS)もあります。データ圧縮は行外のデータでは機能しないため、テーブルにNVARCHAR(MAX)のような列があり、値が通常8000バイトを超える場合、そのデータは圧縮されません(Adam Machanicにそのリマインダーを感謝します) 。 COMPRESS関数はこの問題を解決し、最大2GBのサイズのデータを圧縮します。さらに、この関数は大きな行外のデータにのみ使用する必要があると主張しますが、行とページの圧縮と直接比較することは価値のある実験だと思いました。
セットアップ
テストデータについては、Aaron Bertrandが以前に使用したスクリプトから作業していますが、いくつかの調整を行いました。テスト用に別のデータベースを作成しましたが、tempdbまたは別のサンプルデータベースを使用できます。次に、3つのNVARCHAR列を持つCustomersテーブルから始めました。より大きな列を作成し、繰り返し文字の文字列を入力することを検討しましたが、読み取り可能なテキストを使用すると、より現実的なサンプルが得られるため、精度が向上します。
注: 圧縮の実装に興味があり、圧縮が環境のストレージとパフォーマンスにどのように影響するかを知りたい場合は、圧縮をテストすることを強くお勧めします。サンプルデータを使用した方法論を提供します。これを環境に実装するために追加の作業を行う必要はありません。
データベースを作成した後、クエリストアを有効にしていることに注意してください。 SQL Serverに組み込まれている機能を使用できるのに、パフォーマンスメトリックを追跡するために別のテーブルを作成するのはなぜですか?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
次に、データベース内にいくつかの設定を行います。
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
テーブルを作成したら、いくつかのデータを追加しますが、100万行ではなく500万行を追加します。これは私のラップトップで実行するのに約8分かかります。
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO 次に、さらに3つのテーブルを作成します。1つは行圧縮用、1つはページ圧縮用、もう1つはCOMPRESS関数用です。 COMPRESS関数では、列をVARBINARYデータ型として作成する必要があることに注意してください。その結果、テーブルには非クラスター化インデックスはありません(varbinary列にインデックスキーを作成できないため)。
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
次に、[dbo]。[Customers]から他の3つのテーブルにデータをコピーします。これは、ページテーブルと行テーブルのストレートINSERTであり、各INSERTに約2〜3分かかりますが、COMPRESS関数にはスケーラビリティの問題があります。1回の急降下で500万行を挿入しようとするのは合理的ではありません。以下のスクリプトは、50,000のバッチで行を挿入し、500万行ではなく100万行のみを挿入します。私は知っています、それは私たちが比較のためにここで本当にリンゴ同士ではないことを意味します、しかし私はそれで大丈夫です。私のマシンでは、100万行の挿入に10分かかります。スクリプトを自由に調整して、独自のテスト用に500万行を挿入してください。
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
すべてのテーブルにデータが入力されたら、サイズのチェックを行うことができます。この時点では、ROWまたはPAGE圧縮は実装されていませんが、COMPRESS関数が使用されています:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
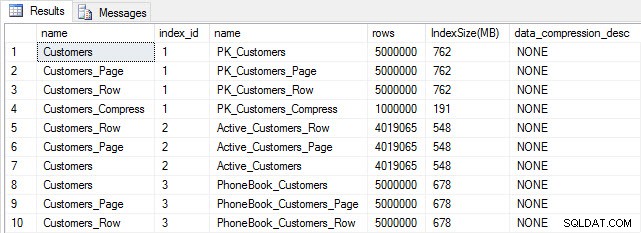
予想どおり、Customers_Compressを除くすべてのテーブルはほぼ同じサイズです。次に、すべてのテーブルのインデックスを再構築し、Customers_RowとCustomers_Pageにそれぞれ行とページの圧縮を実装します。
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
圧縮後にテーブルサイズを確認すると、ディスクスペースの節約がわかります。
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
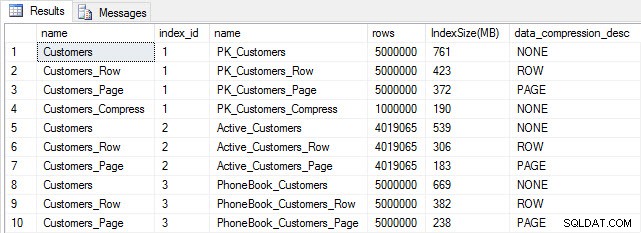
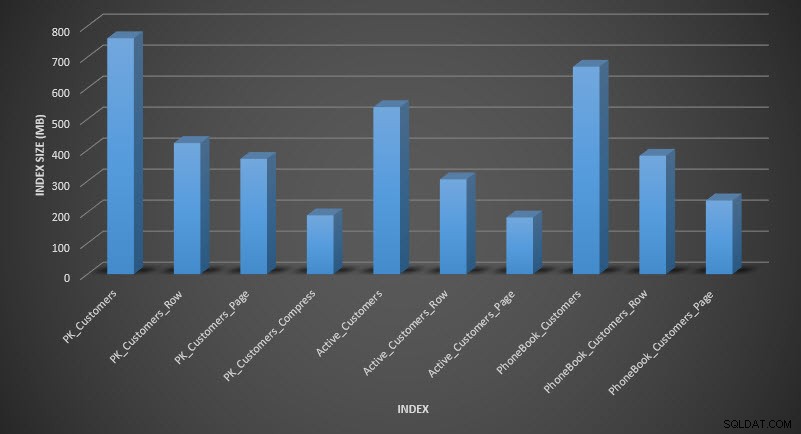
予想どおり、行とページの圧縮により、テーブルとそのインデックスのサイズが大幅に減少します。 COMPRESS関数を使用すると、スペースを最大限に節約できました。クラスター化されたインデックスは、元のテーブルの4分の1のサイズです。
クエリパフォーマンスの調査
クエリのパフォーマンスをテストする前に、クエリストアを使用してINSERTとREBUILDのパフォーマンスを確認できることに注意してください。
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
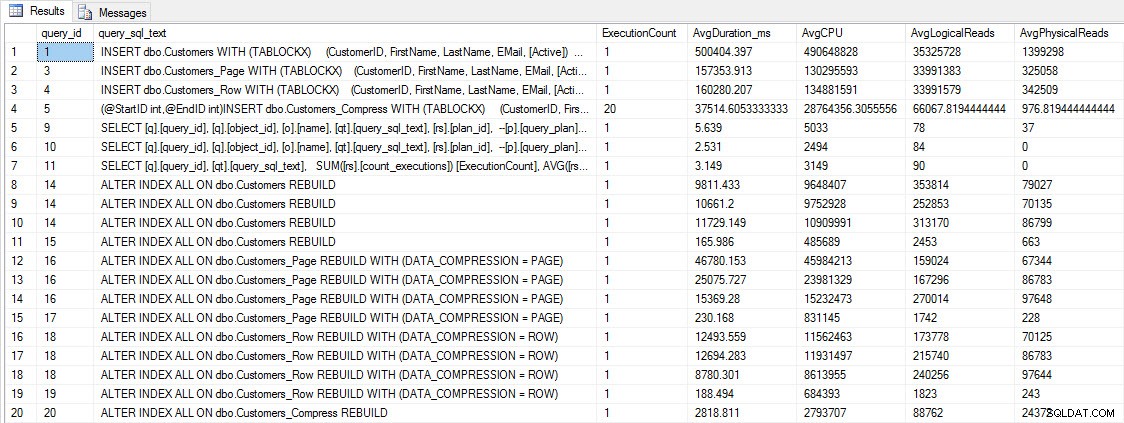 INSERTおよびREBUILDパフォーマンスメトリック
INSERTおよびREBUILDパフォーマンスメトリック
このデータは興味深いものですが、圧縮が日常のSELECTクエリにどのように影響するかについてもっと興味があります。 3つのストアドプロシージャのセットがあり、それぞれに1つのSELECTクエリがあるため、各インデックスが使用されます。テーブルごとにこれらのプロシージャを作成し、テストに使用する名前と名前の値を取得するスクリプトを作成しました。プロシージャを作成するためのスクリプトは次のとおりです。
ストアドプロシージャを作成したら、以下のスクリプトを実行してそれらを呼び出すことができます。これを開始して、数分待ちます…
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
数分後、クエリストアの内容を確認します。
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
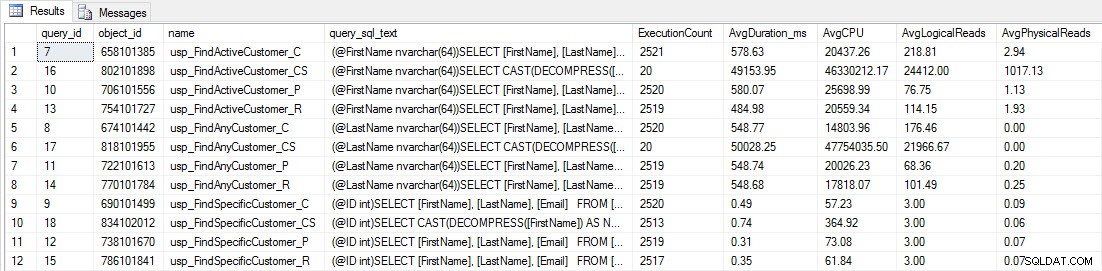
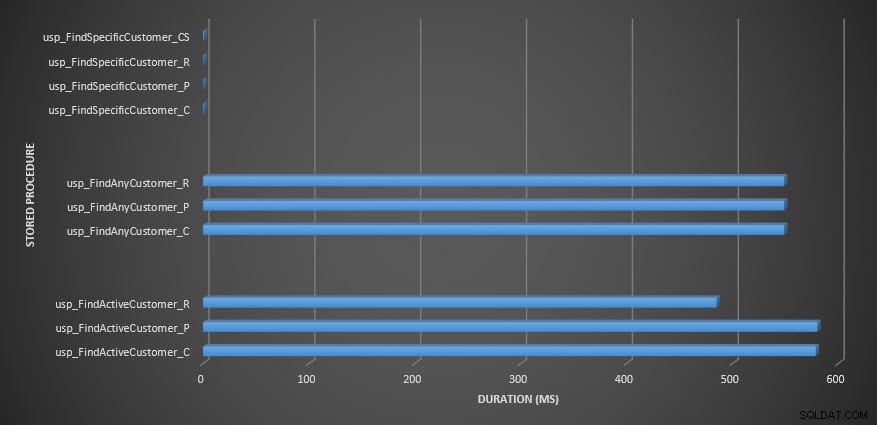
[dbo]。[Customers_Compress]に対する2つのプロシージャは本当にであるため、ほとんどのストアドプロシージャは20回しか実行されていないことがわかります。 スロー。これは驚きではありません。 [FirstName]も[LastName]もインデックス付けされていないため、クエリはテーブルをスキャンする必要があります。これらの2つのクエリでテストの速度が低下したくないので、ワークロードを変更し、EXEC[dbo]。[usp_FindActiveCustomer_CS]とEXEC[dbo]。[usp_FindAnyCustomer_CS]をコメントアウトしてから、再度開始します。今回は、約10分間実行します。クエリストアの出力をもう一度見ると、いくつかの適切なデータがあります。生の数値は以下のとおりで、マネージャーのお気に入りのグラフは以下のとおりです。
 ストアドプロシージャの期間
ストアドプロシージャの期間
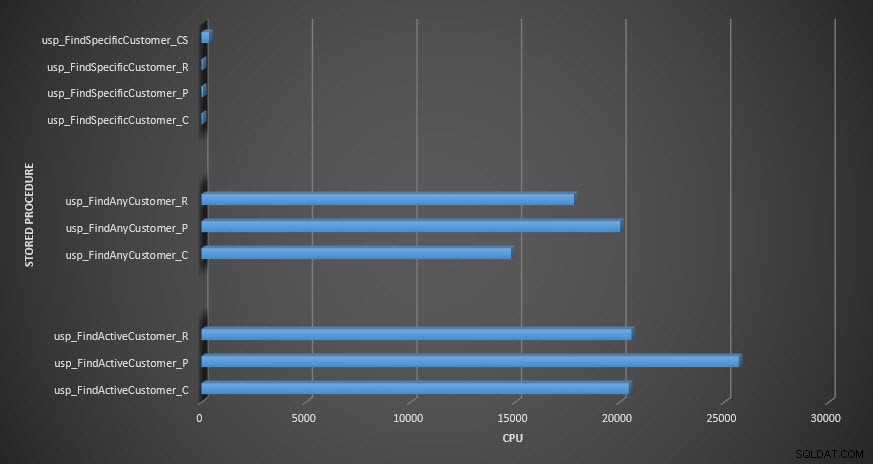
注意:_Cで終わるすべてのストアドプロシージャは、非圧縮テーブルからのものです。 _Rで終わるプロシージャは行圧縮テーブルであり、_Pで終わるプロシージャはページ圧縮され、_CSで終わるプロシージャはCOMPRESS関数を使用します(usp_FindAnyCustomer_CSとusp_FindActiveCustomer_CSの結果は、グラフが歪んでいるため、残りのデータの違い)。 usp_FindAnyCustomer_*およびusp_FindActiveCustomer_*プロシージャは、非クラスター化インデックスを使用し、実行ごとに数千行を返しました。
データの解凍のオーバーヘッドのため、非圧縮テーブルと比較して、行およびページ圧縮テーブルに対するusp_FindAnyCustomer_*およびusp_FindActiveCustomer_*プロシージャの期間が長くなると予想しました。クエリストアデータは私の期待をサポートしていません。これら2つのストアドプロシージャの期間は、これら3つのテーブル間でほぼ同じです(1つのケースではそれ以下です!)。クエリの論理IOは、非圧縮テーブルとページおよび行圧縮テーブルでほぼ同じでした。
CPUに関しては、usp_FindActiveCustomerおよびusp_FindAnyCustomerストアドプロシージャでは、圧縮されたテーブルの方が常に高くなりました。 CPUは、クラスター化されたインデックスに対するシングルトンルックアップであるusp_FindSpecificCustomerプロシージャと同等でした。 [dbo]。[Customer_Compress]テーブルに対するusp_FindSpecificCustomerプロシージャのCPUが高い(ただし、継続時間が比較的短い)ことに注意してください。このテーブルでは、データを読み取り可能な形式で表示するためにDECOMPRESS関数が必要でした。
概要
圧縮データを取得するために必要な追加のCPUが存在し、クエリストアまたは従来のベースライン方法を使用して測定できます。この最初のテストに基づくと、CPUはシングルトンルックアップに匹敵しますが、データが増えると増加します。 SQL Serverに10ページ以上の解凍を強制したかったのですが、少なくとも100ページが必要でした。このスクリプトのバリエーションを実行しました。ここでは、数万行が返され、結果はここに表示されているものと一致していました。私の予想では、データを解凍する時間による期間の大幅な違いを確認するには、クエリが数十万、または数百万の行を返す必要があります。 OLTPシステムを使用している場合は、それほど多くの行を返したくないので、ここでのテストにより、圧縮がパフォーマンスにどのように影響するかがわかります。データウェアハウスを使用している場合、大きなデータセットを返すときは、CPUが高くなるとともに、継続時間が長くなる可能性があります。 COMPRESS関数は、ページと行の圧縮に比べて大幅なスペースの節約を提供しますが、CPUの観点からパフォーマンスが低下し、データ型が原因で圧縮された列にインデックスを付けることができないため、大量のデータがない場合にのみ実行可能になります。検索しました。