先週、GroupBy会議でT-SQL:Bad Habits andBestPracticesセッションを発表しました。ビデオリプレイおよびその他の資料は、こちらから入手できます:
- T-SQL:悪い習慣とベストプラクティス
そのセッションで私がいつも言及している項目の1つは、重複を排除する場合、一般的にDISTINCTよりもGROUPBYを好むということです。 DISTINCTはインテントをより適切に説明し、GROUP BYは集計が存在する場合にのみ必要ですが、多くの場合、それらは交換可能です。
WideWorldImportersを使用した簡単なものから始めましょう。これらの2つのクエリは同じ結果を生成します:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
実際、まったく同じ実行計画を使用して結果を導き出します。

同じ演算子、同じ読み取り数、CPUと合計期間の違いはごくわずかです(順番に「勝ち」ます)。
では、なぜDISTINCTよりも言葉が多く直感的でないGROUP BY構文を使用することをお勧めするのでしょうか?さて、この単純なケースでは、それはコイントスです。ただし、より複雑なケースでは、DISTINCTはより多くの作業を行うことになります。基本的に、DISTINCTは、評価が必要な式を含むすべての行を収集してから、重複を破棄します。 GROUP BYは、(場合によっては)重複する行を前で除外できます。 その作業のいずれかを実行します。
たとえば、文字列の集約について話しましょう。 SQL Server v.Nextでは、STRING_AGGを使用できるようになります(こことここの投稿を参照)が、残りのメンバーはFOR XML PATHを続行する必要があります(このための再帰CTEの素晴らしさについて説明する前に、この投稿も読んでください)。このようなクエリがあり、Sales.OrderLinesテーブルからすべての注文を、アイテムの説明とともにパイプ区切りのリストとして返そうとします。
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
これは、この種の問題を解決するための一般的なクエリであり、次の実行プランがあります(すべてのプランの警告は、XPathフィルターからの暗黙的な変換に対するものです):
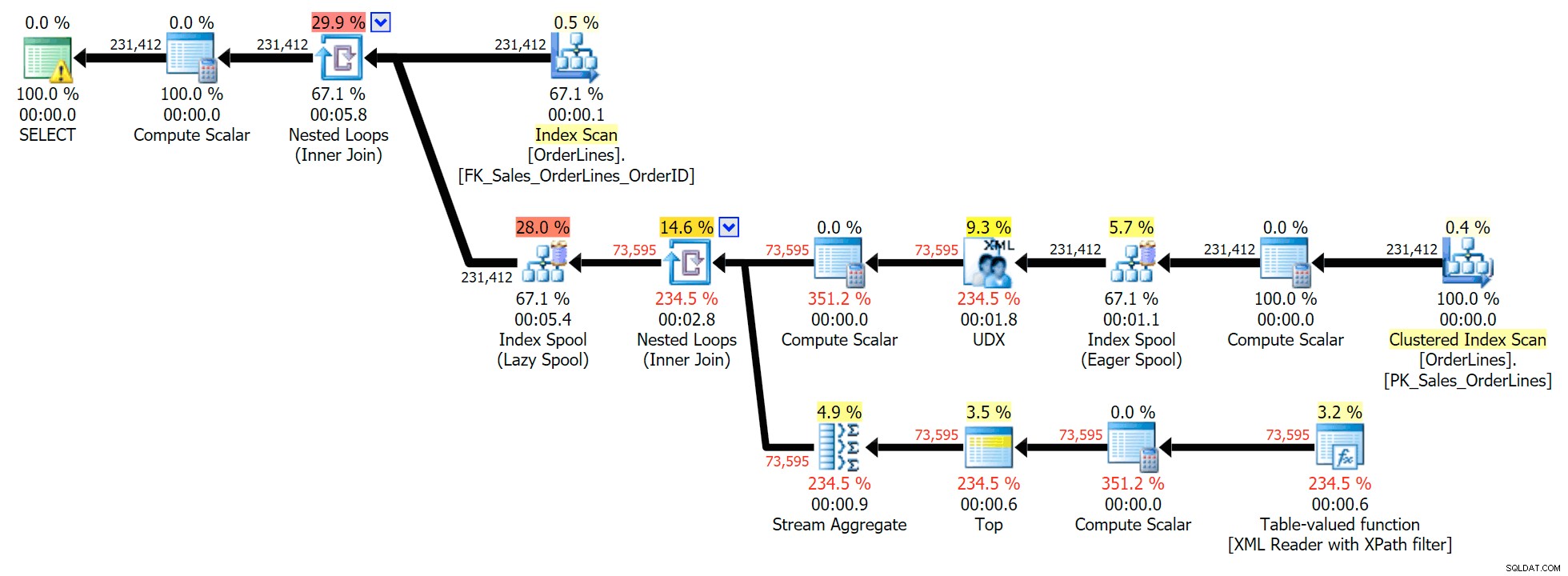
ただし、出力行数に気付く場合があるという問題があります。出力をさりげなくスキャンすると、確かにそれを見つけることができます:

注文ごとにパイプ区切りのリストが表示されますが、アイテムごとに行が表示されます。 各注文で。ひざまずく反応は、列リストにDISTINCTをスローすることです:
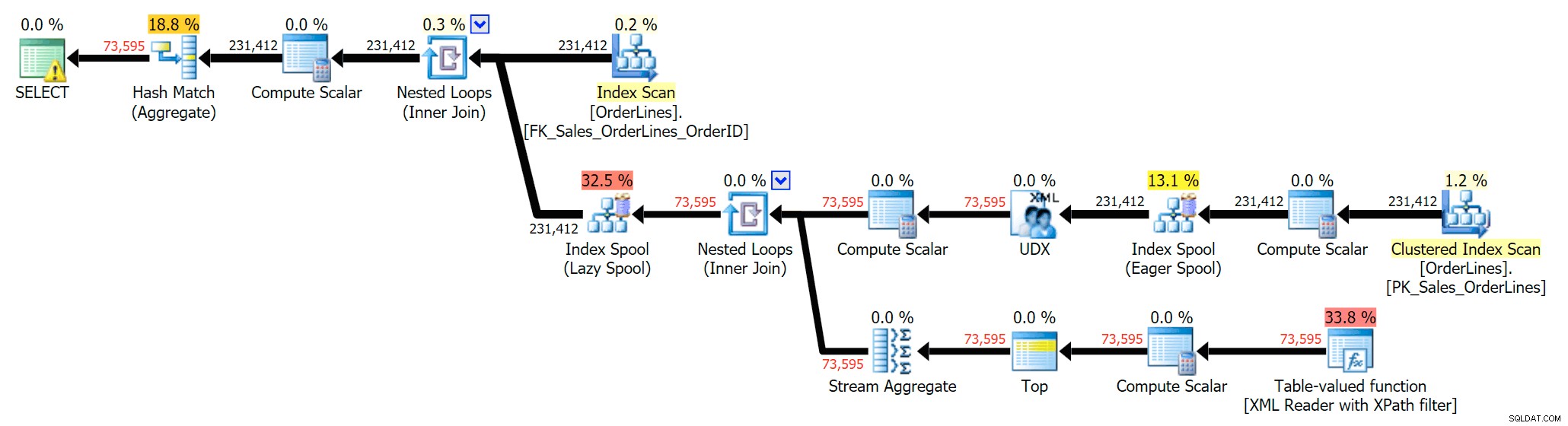
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
これにより、重複が排除され(スキャンの順序プロパティが変更されるため、結果が必ずしも予測可能な順序で表示されるとは限りません)、次の実行プランが生成されます。
これを行う別の方法は、OrderIDにGROUP BYを追加することです(サブクエリは明示的に必要ないため) GROUP BYで再度参照される):
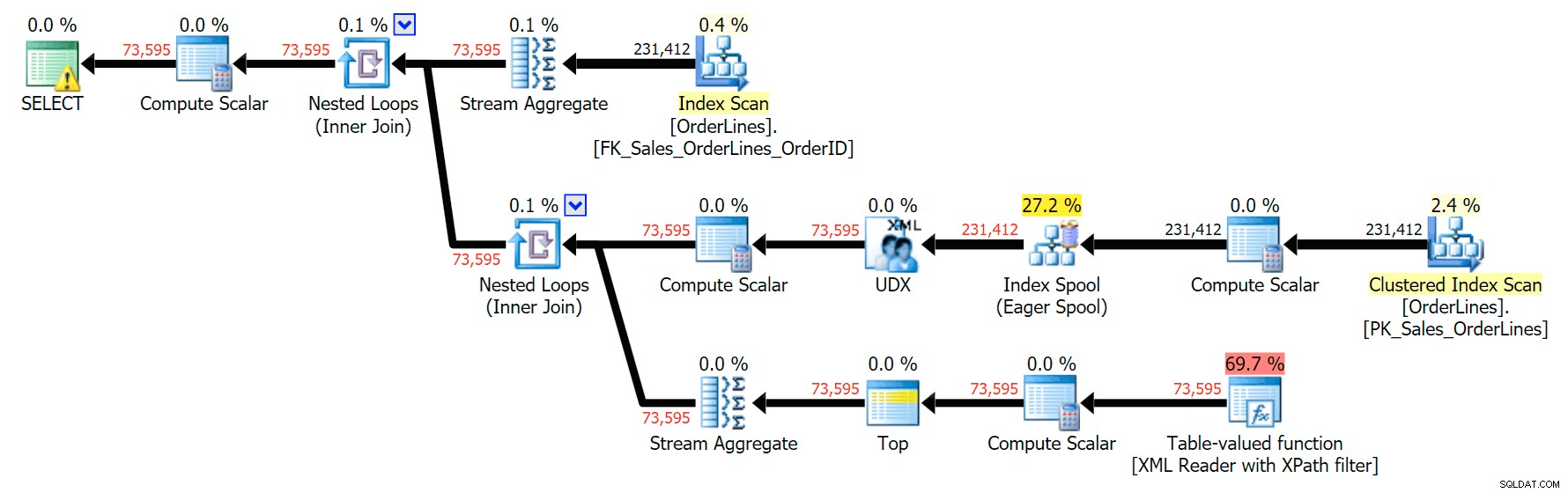
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
これにより、同じ結果が得られ(注文は返されますが)、プランが少し異なります:
ただし、パフォーマンスメトリックは比較するのに興味深いものです。

DISTINCTバリエーションは、GROUP BYバリエーションと比較した場合、4倍の時間がかかり、4倍のCPUを使用し、ほぼ6倍の読み取りを行いました。 (これらのクエリはまったく同じ結果を返すことを忘れないでください。)
また、CPU + I/Oの組み合わせからプランエクスプローラー専用の機能であるI/Oのみにコストを変更した場合の実行プランを比較することもできます。また、再原価計算された値(実際のに基づく)も表示されます。 クエリの実行中に観察されるコスト。この機能はプランエクスプローラーにのみあります)。 DISTINCTプランは次のとおりです。
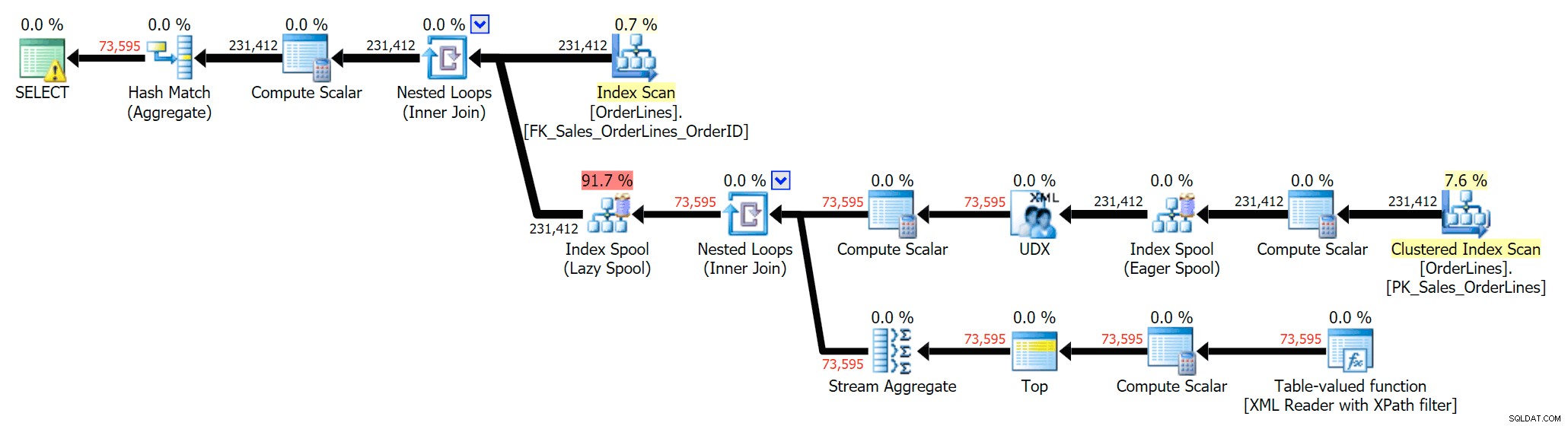
そして、これがGROUPBYプランです:
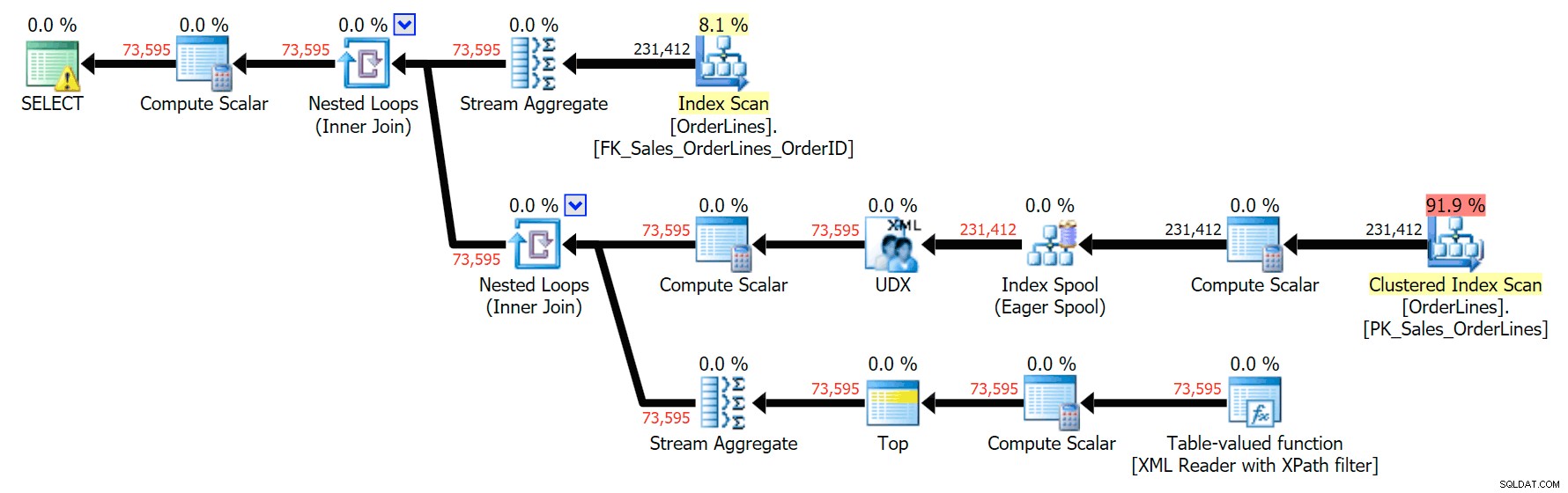
GROUP BYプランでは、ほとんどすべてのI / Oコストがスキャンに含まれていることがわかります(これがCIスキャンのツールチップであり、I / Oコストが約3.4「クエリバックス」であることを示しています)。しかし、DISTINCTプランでは、I / Oコストのほとんどはインデックススプールにあります(これがツールチップです。ここでのI / Oコストは約41.4「クエリバックス」です)。インデックススプールを使用すると、CPUもはるかに高くなることに注意してください。 「クエリバックス」については別の機会に説明しますが、要点は、インデックススプールはスキャンの10倍以上の費用がかかるということです。それでも、スキャンは両方のプランで同じ3.4です。これは、人々が最も高いコストで計画のオペレーターを「修正」する必要があると人々が言うとき、それがいつも私を悩ませている理由の1つです。プランの一部のオペレーターは常に 最も高価なものになります。修正する必要があるという意味ではありません。
@AaronBertrandこれらのクエリは実際には論理的に同等ではありません—DISTINCTは両方の列にありますが、GROUPBYは1つだけにあります
— Adam Machanic(@AdamMachanic)2017年1月20日
Adam Machanicは、これらのクエリが意味的に異なると言ったときは正しいですが、結果は同じです。まったく同じ結果を含む同じ数の行を取得し、はるかに少ない読み取りとCPUでそれを実行しました。
したがって、DISTINCTとGROUP BYは多くのシナリオで同一ですが、これはGROUP BYアプローチが確実にパフォーマンスの向上につながる1つのケースです(クエリ自体の宣言型の意図が明確ではありません)。少なくともパフォーマンスの点で、DISTINCTがGROUP BYよりも優れているシナリオがあるかどうかを知りたいと思います。これは、スタイルよりもはるかに主観的ではなく、ステートメントを自己文書化する必要があるかどうかです。
>この投稿は、私の「驚きと仮定」シリーズに当てはまります。限られた観察や特定のユースケースに基づいて真実として保持している多くのことを、他のシナリオで使用したときにテストできるからです。 SQLクエリの最適化の一環として時間をかけることを忘れないでください…
参考資料
- SQLServerでのグループ化された連結
- グループ化された連結:重複の順序付けと削除
- グループ化された連結の4つの実用的なユースケース
- SQL Server v.Next:STRING_AGG()のパフォーマンス
- SQL Server v.Next:STRING_AGGパフォーマンス、パート2