
私は最近、クラスター化されていないインデックスがクラスター化されたインデックスよりも特定のクエリに対して優れたパフォーマンスを発揮することを示唆したことで叱られました。この人物は、クラスター化インデックスは常に定義によってカバーされているため常に最適であり、同じキー列の一部またはすべてを持つ非クラスター化インデックスは常に冗長であると述べました。
クラスター化インデックスが常にカバーしていることに喜んで同意します(ここでのあいまいさを避けるために、従来のBツリーインデックスを使用したディスクベースのテーブルに固執します)。
 ただし、クラスター化されたインデックスが常にであることに同意しません。 非クラスター化インデックスよりも高速です。また、クラスタリングキーの同じ(または同じいくつかの)列で構成される非クラスター化インデックスまたは一意性制約を作成することが常に冗長であることに同意しません。
ただし、クラスター化されたインデックスが常にであることに同意しません。 非クラスター化インデックスよりも高速です。また、クラスタリングキーの同じ(または同じいくつかの)列で構成される非クラスター化インデックスまたは一意性制約を作成することが常に冗長であることに同意しません。
この例を見てみましょう。Warehouse.StockItemTransactions 、WideWorldImportersから。クラスター化インデックスは、StockItemTransactionIDの主キーを介して実装されます。 列(IDENTITYまたはSEQUENCEによって生成されたある種の代理IDがある場合はかなり一般的です)。
テーブル全体のカウントを要求することはかなり一般的なことです(多くの場合、より良い方法がありますが)。これは、カジュアルな検査またはページネーション手順の一部として使用できます。ほとんどの人はこのようにします:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
現在のスキーマでは、これは非クラスター化インデックスを使用します:
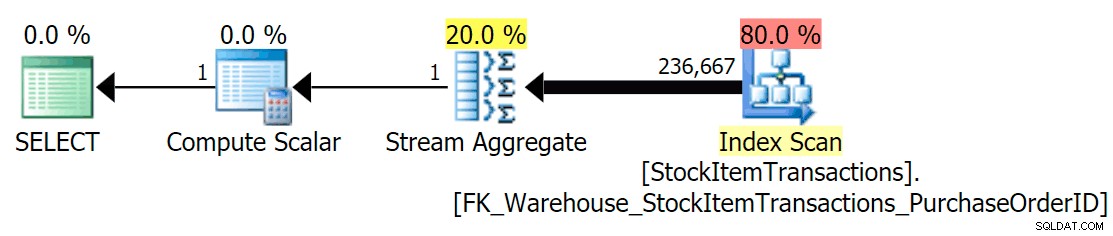
非クラスター化インデックスには、クラスター化インデックスのすべての列が含まれているわけではありません。カウント操作では、どの列が存在するかを気にせずに、すべての行が含まれていることを確認するだけでよいため、SQL Serverは通常、ページ数が最も少ないインデックスを選択します(この場合、選択されたインデックスは最大414ページです)。
次に、クエリをもう一度実行してみましょう。今回は、クラスター化されたインデックスの使用を強制するヒント付きクエリと比較します。
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
ほぼ同じ平面形状が得られますが、読み取りに大きな違いが見られます(選択したインデックスの414とクラスター化されたインデックスの1,982):
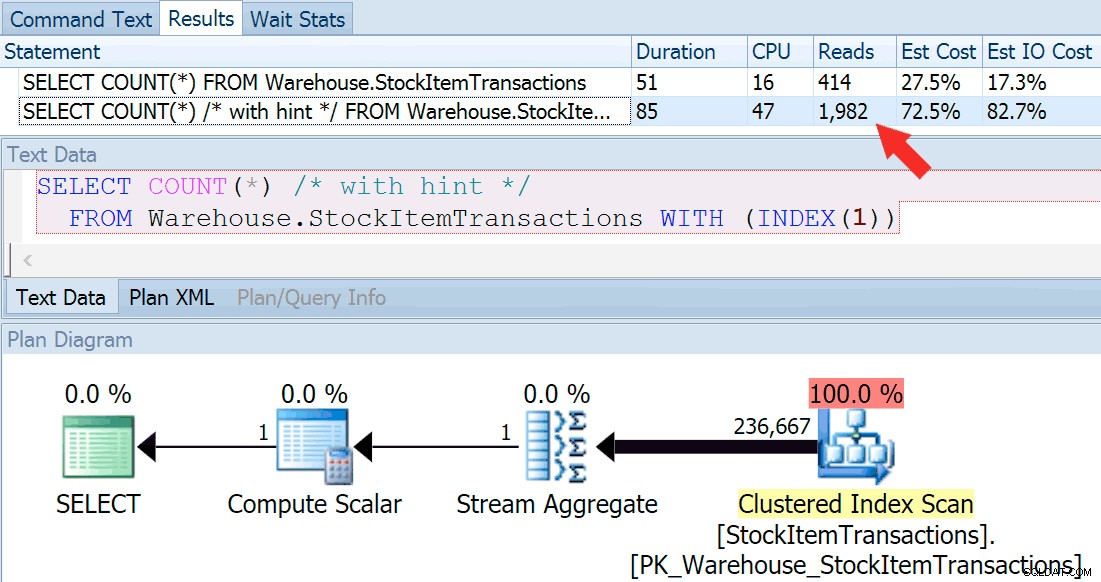
クラスター化されたインデックスの期間はわずかに長くなりますが、高速ディスクにキャッシュされた少量のデータを処理する場合、その違いはごくわずかです。この不一致は、データが多い場合、低速のディスク上、またはメモリが不足しているシステム上では、はるかに顕著になります。
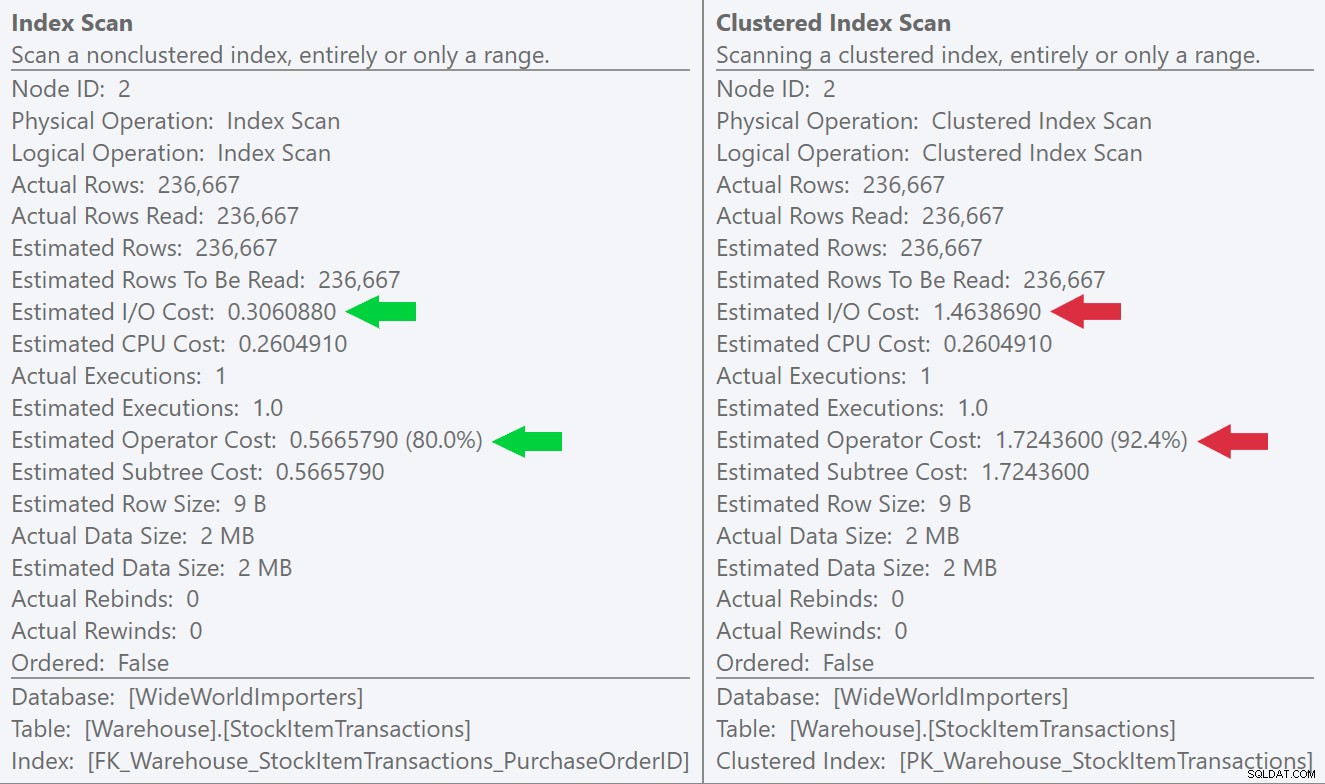
スキャン操作のツールチップを見ると、行数と推定CPUコストは同じですが、推定I / Oコストに大きな違いがあることがわかります(SQL Serverは、非クラスター化インデックスよりもクラスター化インデックス):
ID列だけに新しい一意のインデックスを作成すると、この違いをさらに明確に確認できます(クラスター化インデックスと「冗長」になりますよね?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
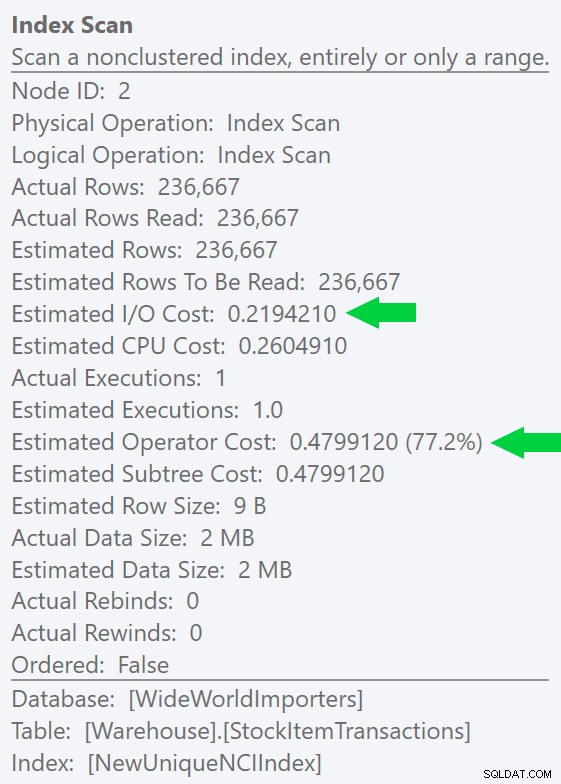 明示的なインデックスヒントを使用して同様のクエリを実行すると、同じプランの形状が生成されますが、推定I/Oはさらに低くなりますコスト(およびさらに短い期間)–右の画像を参照してください。また、ヒントなしで元のクエリを実行すると、SQLServerもこのインデックスを選択するようになります。
明示的なインデックスヒントを使用して同様のクエリを実行すると、同じプランの形状が生成されますが、推定I/Oはさらに低くなりますコスト(およびさらに短い期間)–右の画像を参照してください。また、ヒントなしで元のクエリを実行すると、SQLServerもこのインデックスを選択するようになります。
当たり前のように思えるかもしれませんが、多くの人は、クラスター化されたインデックスがここでの最良の選択であると信じています。 SQL Serverは、ほとんどの場合、すべてのI / Oを実行するための最も安価な方法を提供する方法を大いに支持します。フルスキャンの場合、それが「最も細い」インデックスになります。これは、少なくともインデックスがカバーしている場合は、両方のタイプのシーク(シングルトンスキャンと範囲スキャン)でも発生する可能性があります。
さて、いつものように、それはありません いずれにせよ、カウントクエリを満たすために、すべてのテーブルに追加のインデックスを作成する必要があることを意味します。これは、テーブルサイズをチェックする非効率的な方法であるだけでなく(この記事も参照)、それをサポートするインデックスは、データを更新するよりも頻繁にそのクエリを実行していることを意味する必要があります。すべてのインデックスにはディスク上のスペースとメモリ上のスペースが必要であり、テーブルに対するすべての書き込みもすべてのインデックスにアクセスする必要があることに注意してください(フィルタリングされたインデックスは別として)。
概要
クラスター化されたインデックスのキー列を複製する場合でも、クラスター化されていないものが有用であり、メンテナンスのコストに見合う場合を示す他の多くの例を思いつくことができます。非クラスター化索引は、同じキー列で異なるキー順序で作成することも、列自体に異なるASC / DESCを使用して作成して、代替の表示順序をより適切にサポートすることもできます。フィルタを使用して、行の小さなサブセットのみを保持する非クラスタ化インデックスを作成することもできます。最後に、最も一般的なクエリをより細い非クラスター化インデックスで満たすことができれば、それはメモリ消費にも適しています。
しかし、実際、このシリーズの私のポイントは、このような包括的な発言をすることの愚かさを説明する反例を示すことだけです。 DBA.SEの回答で、このような非クラスター化インデックスが実際にクラスター化インデックスよりもはるかに優れたパフォーマンスを発揮できる理由を説明するPaulWhiteからの説明を残しておきます。これは、両方がどちらかのタイプのシークを使用している場合でも当てはまります。
- クラスター化インデックスシークと非クラスター化インデックスシークの違い