
ゲスト作成者:Andy Mallon(@AMtwo)
いいえ、真剣に。 DTUとは何ですか?
アプリケーションをデプロイするときに最初に出てくる質問の1つは、「これにはいくらかかりますか?」です。私たちのほとんどは、ある時点でSQL Serverのインストールのサイズを決定するためにこの種の演習を行ってきましたが、クラウドに展開する場合はどうでしょうか。 Azure IaaSの展開では、ほとんど変更されていません。CPU数、メモリの量に基づいてサーバーを構築し、ワークロードに十分なIOPSを提供するようにストレージを構成しています。ただし、PaaSに移行すると、Azure SQLデータベースはさまざまなサービス層でサイズ設定され、パフォーマンスはDTUで測定されます。 DTUとは一体何ですか?
私はBTUが何であるかを知っています。おそらく、DTUはDatabase Thermal Unitの略ですか?データセンターの温度を1度上げるのに必要な処理能力の量ですか?推測する代わりに、ドキュメントを確認して、Microsoftの発言を確認しましょう。
[データベーストランザクションユニット]は、CPU、メモリ、データI/OとトランザクションログI/Oを組み合わせた測定値であり、実際のOLTPワークロードに典型的なように設計されたOLTPベンチマークワークロードによって決定されます。データベースのパフォーマンスレベルを上げることによってDTUを2倍にすることは、そのデータベースで使用可能なリソースのセットを2倍にすることと同じです。OK、それは私の2番目の推測でしたが、「混合メジャー」とは何ですか?サーバーのサイズ設定について知っていることをAzureSQLデータベースのサイズ設定に変換するにはどうすればよいですか?残念ながら、「2つのCPUコアと4GBのメモリ」をDTU測定値に変換する簡単な方法はありません。
DTU Calculatorはありませんか?
はい! Microsoftは、推定するためのDTU計算機を提供しています。 AzureSQLデータベースの適切なサービス層。これを使用するには、SQL Serverでワークロードを実行しながら、サーバーにPowerShellスクリプト(sql-perfmon.ps1)をダウンロードして実行します。スクリプトは、4つのperfmonカウンターを含むCSVを出力します:(1)合計%プロセッサー時間、(2)合計ディスク読み取り/秒、(3)合計ディスク書き込み/秒、および(4)合計ログバイトフラッシュ/秒。次に、このCSV出力がDTU Calculatorにアップロードされ、DTUCalculatorがニーズに最適なサービス層を推定します。 CSVに加えてDTUCalculatorが取得する唯一のデータは、ファイルを生成したサーバー上のCPUコアの数です。 DTU Calculatorはまだ少しブラックボックスです。オンプレミスのデータベースからわかっていることを、Azureにマッピングするのは簡単ではありません。
DTUの定義は、「CPU、メモリの混合測定値」であるということを指摘したいと思います。 、およびデータI/OとトランザクションログI/O…"DTUCalculatorで使用されるperfmonカウンターはいずれもメモリを考慮していませんが、計算の一部として定義に明確にリストされています。これは必ずしも問題がありますが、DTUCalculatorが完全ではないことの証拠です。
合成負荷をDTUCalculatorにアップロードし、そのブラックボックスがどのように機能するかを理解できるかどうかを確認します。実際、CSVを完全に作成して、DTUCalculatorにロードするperfmon番号を完全に制御できるようにします。一度に1つのメトリックをステップスルーしてみましょう。指標ごとに、25分(1500秒-私はラウンド数が好きです)に相当する偽造データをアップロードし、そのperfmonデータがどのようにDTUに変換されるかを確認します。
CPU
16コアサーバーをシミュレートするCSVを作成し、CPU使用率を100%に固定されるまでゆっくりと増やしていきます。 16コアサーバーでのランプアップをシミュレートするので、一度に1/16にステップアップするCSVを作成します。基本的に、1つのコアの最大化、2番目の最大化、3番目のコアの最大化をシミュレートします。その間、CSVは読み取り、書き込み、ログフラッシュがゼロであることを示します。サーバーが実際にこのようなワークロードを生成することは決してありませんが、それがポイントです。 CPUがDTUにどのように影響するかを確認できるように、CPU使用率を完全に分離しています。
1秒あたり1行のCSVファイルを作成し、94秒ごとに、合計%プロセッサ時間カウンターを最大6%増やします。他の3つのカウンターは、すべての場合でゼロになります。ここで、このファイルをDTU Calculatorにアップロードし(DTU Calculatorに16コアを考慮するように指示します)、出力は次のとおりです。
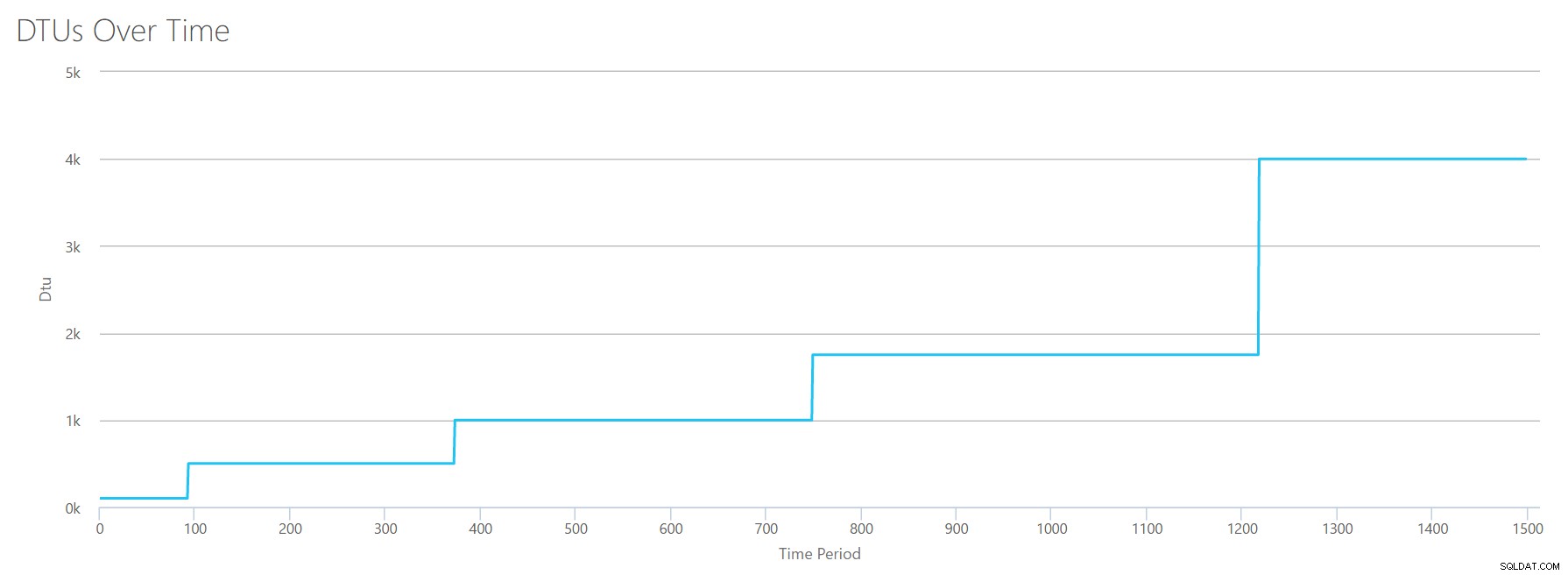
待って? CPU使用率を16ステップでステップアップしませんでしたか?このDTUグラフは、5つのステップのみを示しています。私はめちゃくちゃだったに違いない。いいえ、私のCSVには16の均等なステップがありましたが、それは(明らかに)DTUに均等に変換されません。少なくともDTUCalculatorによるとではありません。最大化されたCPUテストに基づくと、CPUからDTU、サービス層へのマッピングは次のようになります。
| Number Cores | DTU | サービス層 |
|---|---|---|
| 1 | 100 | 標準– S3 |
| 2-4 | 500 | プレミアム– P4 |
| 5-8 | 1000 | プレミアム– P6 |
| 9-13 | 1750 | プレミアム– P11 |
| 14-16 | 4000 | プレミアム– P15 |
このデータを見ると、いくつかのことがわかります。
- 1つのCPUコア、100%使用率は100DTUに相当します。
- DTUはちょっと増加します CPUが増加するにつれて直線的になりますが、一見、適合し、急増しているように見えます。
- 基本サービス層と標準サービス層は、単一のCPUコア未満です。
- マルチコアサーバーは、プレミアムサービス層内である程度のサイズに変換されます。
読み取り
今回は、同じ方法を使用します。他のperfmonカウンターをゼロにして、読み取り/秒カウンターの数を増やしてCSVを生成します。時間の経過とともに徐々に数を増やしていきます。今回は、30000に達するまで、100秒ごとに2000のチャンクでステップアップします。これにより、同じ25分の合計時間が得られますが、今回は16ではなく15のステップがあります(ラウンド数が好きです)。
このCSVをDTU計算機にアップロードすると、次のDTUグラフが表示されます。
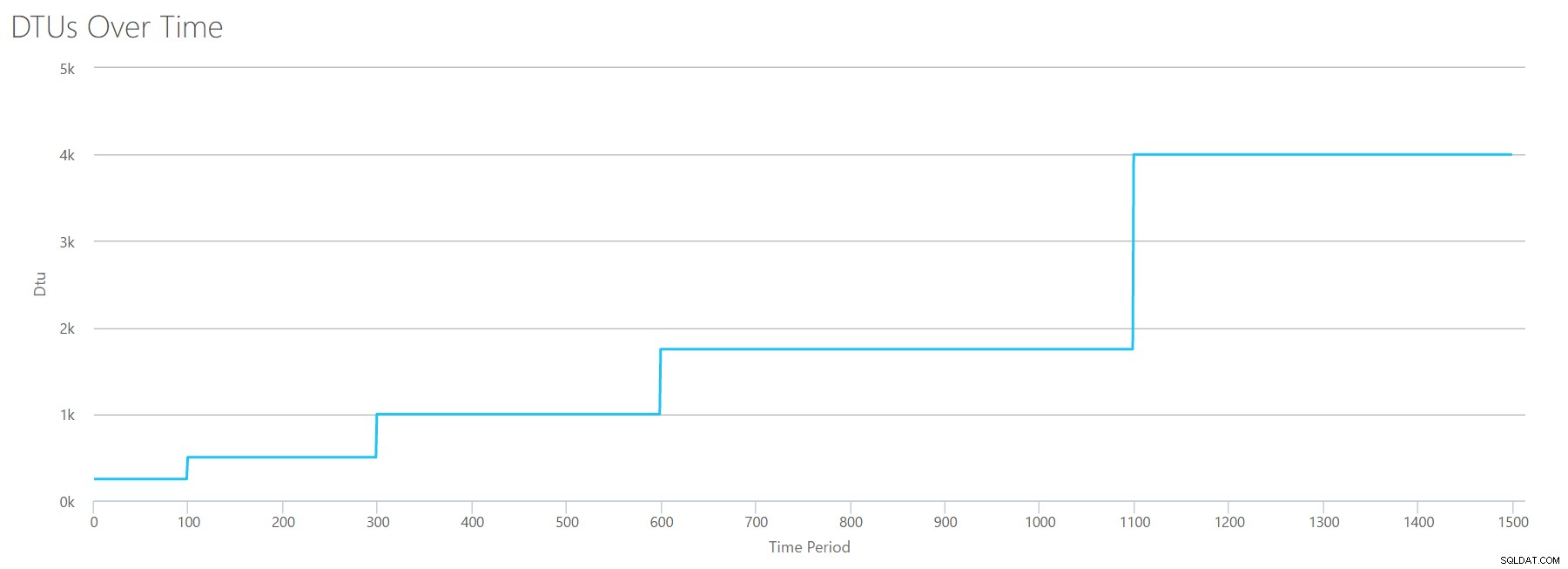
ちょっと待ってください…最初のグラフとかなり似ています。繰り返しになりますが、ファイルに15の偶数ステップがあったとしても、5つの不均一な増分でステップアップしています。表形式で見てみましょう:
| Reads / sec | DTU | サービス層 |
|---|---|---|
| 2000 | 250 | プレミアム– P2 |
| 4000-6000 | 500 | プレミアム– P4 |
| 8000-12000 | 1000 | プレミアム– P6 |
| 14000-22000 | 1750 | プレミアム– P11 |
| 24000-30000 | 4000 | プレミアム– P15 |
繰り返しになりますが、基本層と標準層は非常に速く(2000読み取り/秒未満)ジャンプしますが、プレミアム層はかなり広く、1秒あたり2000から30000読み取りに及びます。上記の表では、「読み取り/秒」はおそらく「IOPS」と考えることができます…または、技術的には、IOPSの「入力」部分を構成する書き込みがないため、単に「OPS」です。
書き込み
読み取りに使用したのと同じ式を使用してCSVを作成し、そのCSVをDTU Calculatorにアップロードすると、読み取りのグラフと同じグラフが得られます。
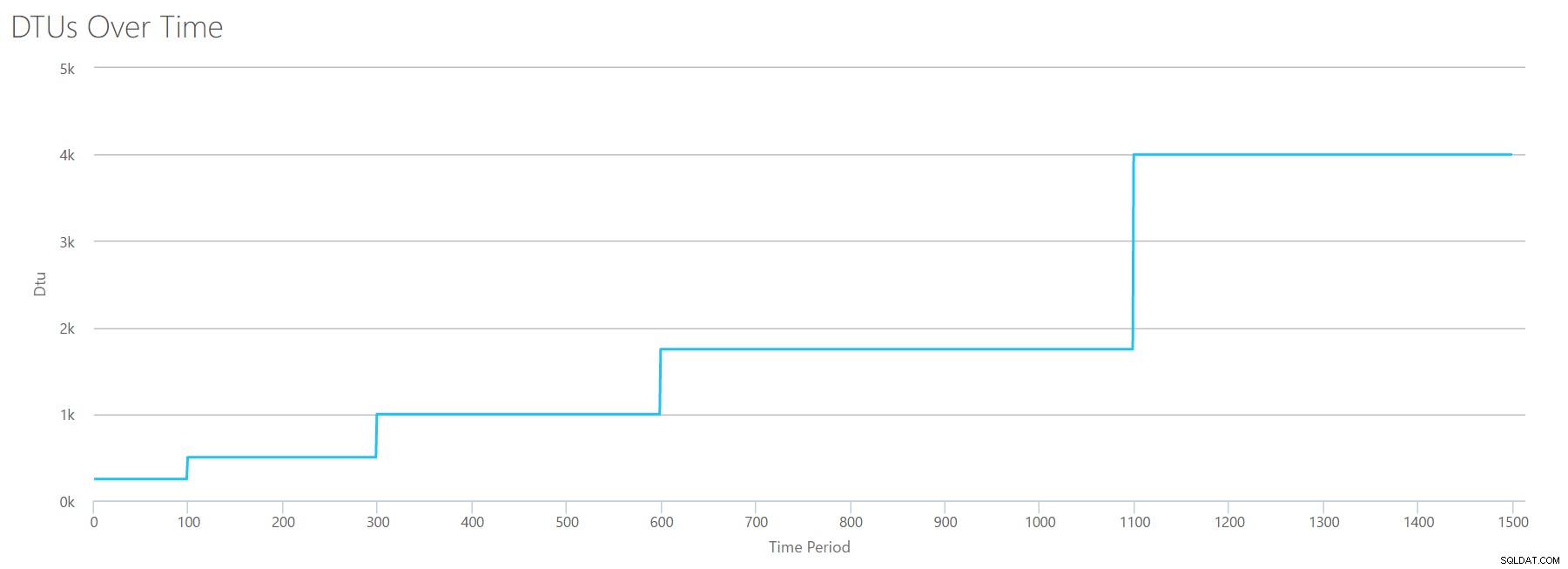
IOPSはIOPSであるため、読み取りでも書き込みでも、DTU計算では同等に考慮されているように見えます。読み取りについて私たちが知っている(または知っていると思う)ことはすべて、書き込みにも等しく当てはまるようです。
フラッシュされたログバイト
最後のperfmonカウンターまでです。1秒あたりにフラッシュされたログバイトです。これはIOの別の指標ですが、SQLServerトランザクションログに固有です。まだ理解していない方のために、これらのCSVを作成して、高い値がP15 Azure DBとして計算されるようにし、値を単純に分割して均等なステップに分割します。今回は、500万から7500万に500万刻みで進めていきます。以前のすべてのテストで行ったように、他のperfmonカウンターはゼロになります。このperfmonカウンターは1秒あたりのバイト数であり、数百万単位で測定しているため、より快適な単位である1秒あたりのメガバイト数でこれを考えることができます。
このCSVをDTU計算機にアップロードすると、次のグラフが表示されます。
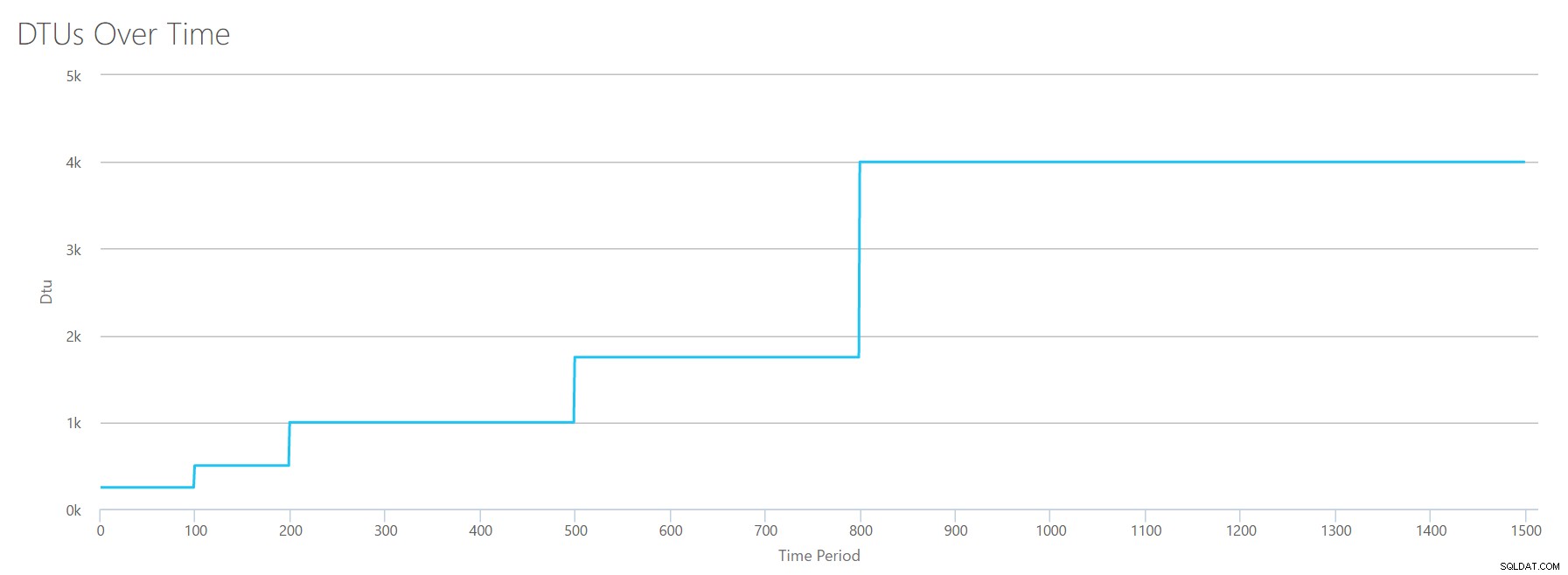
| ログメガバイトフラッシュ/秒 | DTU | サービス層 |
|---|---|---|
| 5 | 250 | プレミアム– P2 |
| 10 | 500 | プレミアム– P4 |
| 15-25 | 1000 | プレミアム– P6 |
| 30-40 | 1750 | プレミアム– P11 |
| 45-75 | 4000 | プレミアム– P15 |
このグラフの形は、かなり予測可能になっています。今回を除いて、ティアを少し速くステップアップし、わずか8ステップでP15に到達します(IOの場合は11、CPUの場合は12と比較して)。これは、「これが私の最も狭いボトルネックになるだろう」と思わせるかもしれません。しかし、私はそれをそれほど確信していません。 1秒間に75MBのログを生成する頻度 ?これは4.5GB/分です 。これは多くのデータベースアクティビティです。私の合成ワークロードは必ずしも現実的なワークロードではありません。
すべてを組み合わせる
さて、上限のいくつかが分離されているところを確認したので、データを組み合わせて、CPU、I / O、およびトランザクションログIOがすべて一度に発生しているときにそれらがどのように比較されるかを確認します。 、それは実際にどのように起こるのではありませんか?
このCSVを作成するために、上記の個々のテストに使用した既存の値を取得し、それらの値を1つのCSVに結合すると、次のような素敵なグラフが作成されます。
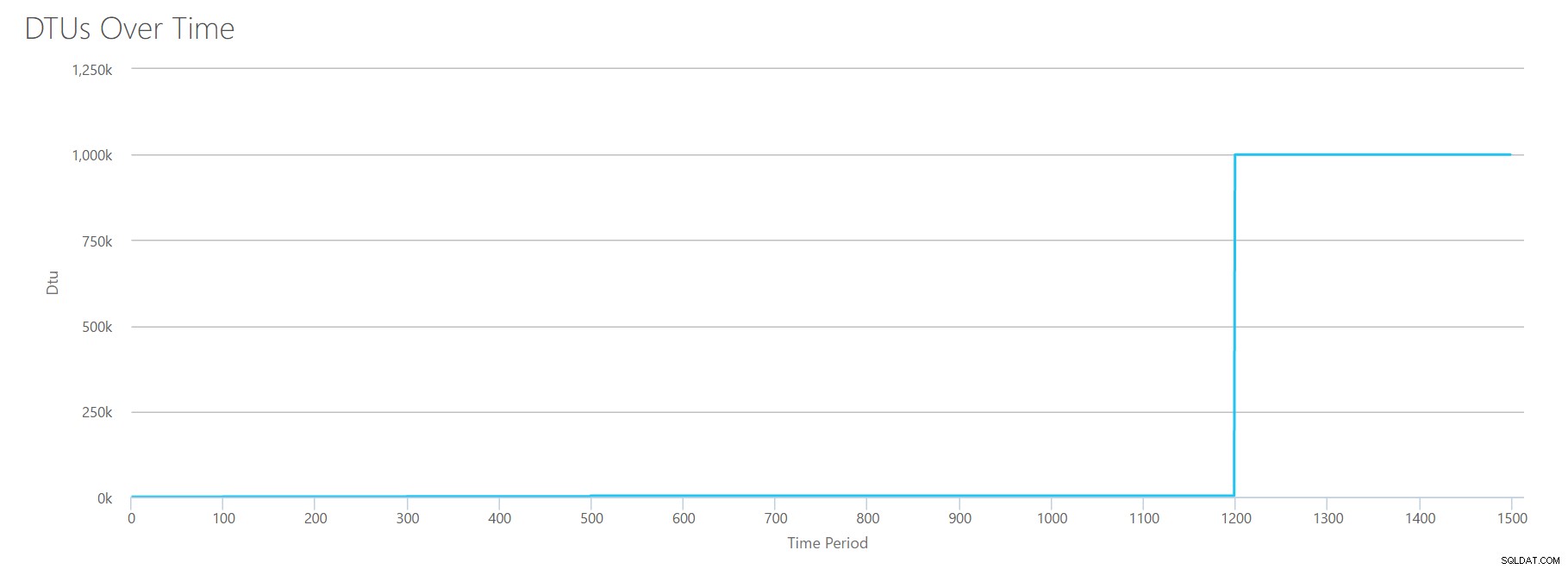
また、次のメッセージが表示されます:
データベースの使用率に基づいて、SQLServerのワークロードは範囲外です。 。現時点では、使用率をカバーするサービス層/パフォーマンスレベルはありません。Y軸を見ると、1200秒のマークで「1,000k」(つまり100万)のDTUに達していることがわかります。それは…ええと…間違っているようですか?上記のテストを見ると、1200秒のマークは、4つの個別のメトリックすべてが4000 DTU、P15層のマークに達したときでした。範囲外になることは理にかなっていますが、グラフの形は私にはまったく意味がありません。DTU計算機は、「何でも、アンディ。たくさんあります。それもそうです。これは数十億のDTUです。このワークロードはAzureSQLデータベースには適合しません。」
では、前に何が起こるか 1200秒のマーク? CSVを削減し、最初の1200秒だけで計算機に再送信しましょう。各列の最大値は、81%CPU(または100%でapx 13コア)、24000読み取り/秒、24000書き込み/秒、および60MBログフラッシュ/秒です。
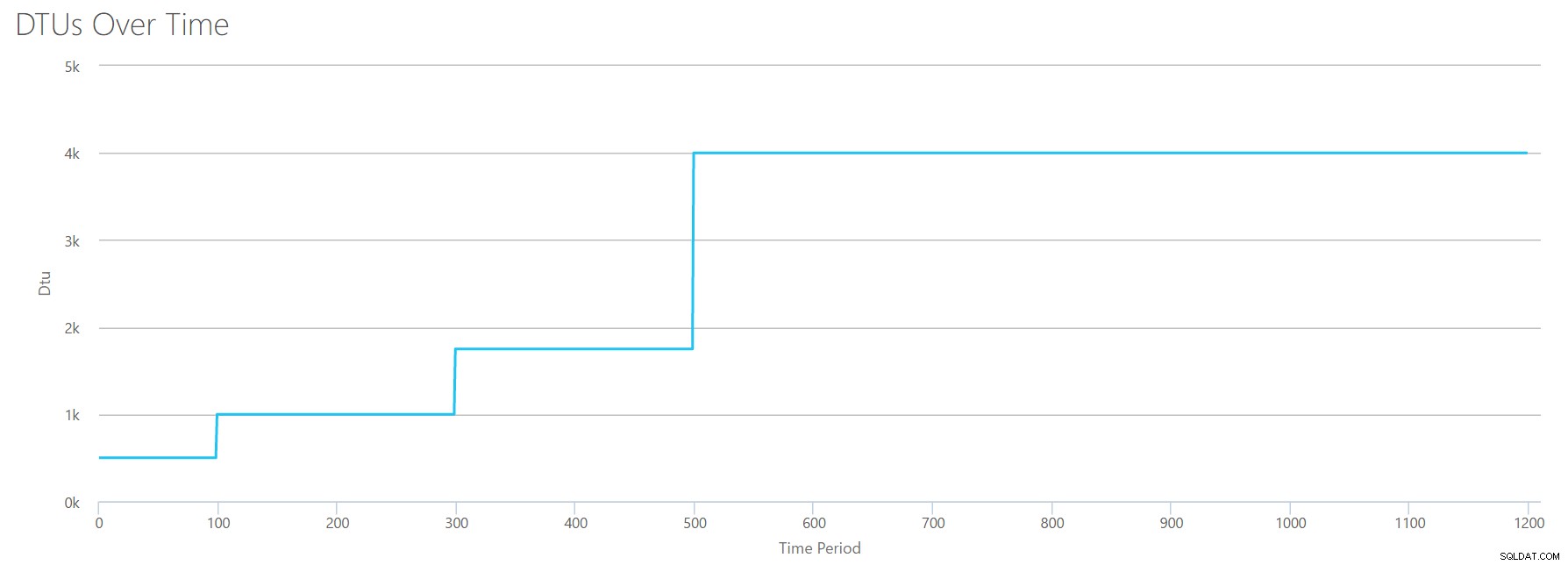
こんにちは、古くからの友人…あのなじみのある形がまた戻ってきました。これは、CSVからのデータの要約と、DTUCalculatorが合計DTU使用量とサービス層について推定するものです。
| Number Cores | 読み取り/秒 | 書き込み/秒 | フラッシュされたログメガバイト/秒 | DTU | サービス層 |
|---|---|---|---|---|---|
| 1 | 2000 | 2000 | 5 | 500 | プレミアム– P4 |
| 2-3 | 4000-6000 | 4000-6000 | 10 | 1000 | プレミアム– P6 |
| 4-5 | 8000-10000 | 8000-10000 | 15-25 | 1750 | プレミアム– P11 |
| 6-13 | 12000-24000 | 12000-24000 | 30-40 | 4000 | プレミアム– P15 |
ここで、個々のDTU計算(個別に評価した場合)を、この最新のチェックのDTU計算と比較してみましょう。
| CPU DTU | DTUを読む | DTUを作成する | ログフラッシュDTU | 合計DTU | DTU計算機の見積もり | サービス層 |
|---|---|---|---|---|---|---|
| 100 | 250 | 250 | 250 | 850 | 500 | プレミアム– P4 |
| 500 | 500 | 500 | 500 | 2000 | 1000 | プレミアム– P6 |
| 500-1000 | 1000 | 1000 | 1000 | 3500-4000 | 1750 | プレミアム– P11 |
| 1000-1750 | 1000-1750 | 1000-1750 | 1750 | 4750-7000 | 4000 | プレミアム– P15 |
DTUの計算は、個別のDTUを合計するほど単純ではないことに気付くでしょう。私が最初に引用した定義が述べているように、それはそれらの別々の測定基準の「混合された尺度」です。 「ブレンド」に使用される式は複雑であり、実際にはその式はありません。私たちが見ることができるのは、DTUCalculatorの見積もりが低いということです。 個別のDTU計算の合計よりも。
DTUを従来のハードウェアにマッピングする
DTU Calculatorからデータを取得し、従来のハードウェアがいくつかのAzureSQLデータベース層にどのようにマッピングされるかについていくつかの推測をまとめてみましょう。
まず、「読み取り/秒」と「書き込み/秒」がIOPSに直接変換され、変換は不要であると想定します。次に、これら2つのカウンターを追加すると、合計IOPSが得られると仮定します。第三に、メモリ使用量が何であるかがわからず、その面で結論を出す方法がないことを認めましょう。
ハードウェアの仕様を見積もっている間、各ハードウェア構成に適合する可能なAzureVMサイズも選択します。同様のAzureVMサイズが多数あり、それぞれが異なるパフォーマンスメトリックに最適化されていますが、私は先に進んで、選択をAシリーズとDSv2シリーズに限定しました。
| Number Cores | IOPS | メモリ | DTU | サービス層 | 同等のAzureVMサイズ |
|---|---|---|---|---|---|
| 1コア、5%の使用率 | 10 | ??? | 5 | 基本 | Standard_A0、ほとんど使用されていません |
| <1コア | 150 | ??? | 100 | 標準S0-S3 | Standard_A0、十分に活用されていません |
| 1コア | 最大4000 | ??? | 500 | プレミアム– P4 | Standard_DS1_v2 |
| 2〜3コア | 最大12000 | ??? | 1000 | プレミアム– P6 | Standard_DS3_v2 |
| 4-5コア | 最大20000 | ??? | 1750 | プレミアム– P11 | Standard_DS4_v2 |
| 6-13 | 最大48000 | ??? | 4000 | プレミアム– P15 | Standard_DS5_v2 |
基本階層は非常に限られています。たまに/カジュアルに使用するのに適しています。また、データベースを使用していないときにデータベースを「パーク」するための安価な方法です。ただし、実際のアプリケーションを実行している場合、基本層は機能しません。
標準階層もかなり制限されていますが、小規模なアプリケーションの場合は、ニーズを満たすことができます。少数のデータベースを実行している2コアサーバーがある場合、それらのデータベースは個別に標準層に適合する可能性があります。同様に、データベースが1つだけで、1つのCPUコアを100%で実行している(または2つのコアを50%で実行している)サーバーがある場合、Premium-P1サービス層にスケールを傾けるのに十分な馬力である可能性があります。
オンプレミス(またはIaaS)でマルチコアサーバーを使用する場合は、AzureSQLデータベースのプレミアムサービス層内を検索します。ワークロードに必要なCPUとI/Oの馬力を決定するだけです。 2コアの4GBサーバーは、おそらくP6 AzureSQLDBのどこかに配置されます。純粋なCPUワークロード(I / Oがゼロ)では、P15データベースは16コア相当の処理を処理できますが、IOをミックスに追加すると、最大12コアを超えるものはAzureSQLデータベースに適合しません。
次回は、実際のワークロードをいくつか取り上げて、サービス層全体のパフォーマンスを比較します。 DTU Calculatorの見積もりは正確ですか?調べます。
作者について
 Andy Mallonは、SQLServerDBAおよびMicrosoftDataPlatform MVPであり、ヘルスケア、金融、eのデータベースを管理しています。 -コマース、および非営利セクター。 2003年以来、Andyは、要求の厳しいパフォーマンスニーズを持つ大量の高可用性OLTP環境をサポートしてきました。 Andyは、BostonSQLの創設者であり、SQLSaturday Bostonの共同主催者であり、am2.coのブログです。
Andy Mallonは、SQLServerDBAおよびMicrosoftDataPlatform MVPであり、ヘルスケア、金融、eのデータベースを管理しています。 -コマース、および非営利セクター。 2003年以来、Andyは、要求の厳しいパフォーマンスニーズを持つ大量の高可用性OLTP環境をサポートしてきました。 Andyは、BostonSQLの創設者であり、SQLSaturday Bostonの共同主催者であり、am2.coのブログです。