SQL Serverは、SQLServer2014でインメモリOLTPオブジェクトを導入しました。初期リリースには多くの制限がありました。一部はSQLServer2016で対処されており、機能が進化し続けるにつれて、次のリリースでさらに対処されると予想されます。これまでのところ、インメモリOLTPの採用はそれほど普及していないようですが、機能が成熟するにつれて、より多くのクライアントが実装について質問し始めると思います。主要なスキーマやコードの変更と同様に、インメモリOLTPが期待されるメリットを提供するかどうかを判断するために徹底的なテストを行うことをお勧めします。そのことを念頭に置いて、インメモリOLTPを使用した非常に単純なINSERT、UPDATE、およびDELETEステートメントのパフォーマンスがどのように変化するかを確認することに興味がありました。ディスクベースのテーブルの問題としてラッチまたはロックを示すことができれば、メモリ内のテーブルはロックやラッチがないため、解決策になると期待していました。
次のテストを開発しました。ケース:
- DMLの従来のストアドプロシージャを含むディスクベースのテーブル。
- DMLの従来のストアドプロシージャを含むインメモリテーブル。
- DML用にネイティブにコンパイルされたプロシージャを含むインメモリテーブル。
ネイティブにコンパイルされたプロシージャの制限の1つは、参照されるテーブルがインメモリでなければならないことであるため、従来のストアドプロシージャとネイティブにコンパイルされたプロシージャのパフォーマンスを比較することに興味がありました。一部のシステムでは単一行の単独の変更が一般的ですが、複数のステートメント(SELECTおよびDML)が1つ以上のテーブルにアクセスする、より大きなストアドプロシージャ内で変更が発生することがよくあります。インメモリOLTPドキュメントでは、パフォーマンスの観点から最大のメリットを得るには、ネイティブにコンパイルされたプロシージャを使用することを強くお勧めします。パフォーマンスがどれだけ向上したかを知りたかったのです。
セットアップ
メモリ最適化ファイルグループを使用してデータベースを作成し、データベースに3つの異なるテーブルを作成しました(1つはディスクベース、2つはメモリ内):
- DiskTable
- InMemory_Temp1
- InMemory_Temp2
DDLはすべてのオブジェクトでほぼ同じであり、必要に応じてディスク上とメモリ内を考慮しています。 DiskTable DDLとインメモリDDL:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
また、テーブルと変更の組み合わせごとに1つずつ、合計9つのストアドプロシージャを作成しました。
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Update
- InMemRegularSP _Delete
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
各ストアドプロシージャは、その数の変更をループする整数入力を受け入れました。ストアドプロシージャは同じ形式に従い、バリエーションはアクセスされるテーブルと、オブジェクトがネイティブにコンパイルされているかどうかだけでした。データベースとオブジェクトを作成するための完全なコードは、以下のINSERTステートメントとUPDATEステートメントの例とともにここにあります。
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
注:IDs_ *テーブルは、INSERTの各セットが完了すると再入力され、3つの異なるシナリオに固有のものでした。
テスト方法
テストは、sqlcmdを使用してストアドプロシージャを実行するスクリプトを呼び出す.cmdスクリプトを使用して行われました。例:
sqlcmd -S CAP \ ROGERS -i "C:\ Temp \ SentryOne \ InMemTable_RegularDeleteSP_100.sql"exit
このアプローチを使用して、同時に実行されるデータベースへの1つ以上の接続を作成しました。パフォーマンスの基本的な変更を理解することに加えて、さまざまなワークロードの影響も調べたいと思いました。これらのスクリプトは、接続のインスタンス化のオーバーヘッドを排除するために、別のマシンから開始されました。各ストアドプロシージャは接続によって1000回実行され、1つの接続、10の接続、および100の接続(それぞれ1000、10000、および100000の変更)をテストしました。クエリストアを使用してパフォーマンスメトリックをキャプチャし、待機統計もキャプチャしました。クエリストアを使用すると、各ストアドプロシージャの平均期間とCPUを取得できました。待機統計データは、dm_exec_session_wait_statsを使用して接続ごとにキャプチャされ、テスト全体で集計されました。
各テストを4回実行してから、この投稿で使用されているデータの全体的な平均を計算しました。ワークロードテストに使用されるスクリプトは、ここからダウンロードできます。
結果
予想されるように、メモリ内オブジェクトのパフォーマンスは、ディスクベースのオブジェクトよりも優れていました。ただし、通常のストアドプロシージャを使用するインメモリテーブルは、通常のストアドプロシージャを使用するディスクベースのテーブルと比較して、パフォーマンスが同等またはわずかに優れている場合があります。覚えておいてください:メモリ内のテーブルで大きなメリットを得るには、コンパイルされたストアドプロシージャが本当に必要かどうかを理解することに興味がありました。このシナリオでは、私はそうしました。いずれの場合も、ネイティブにコンパイルされたプロシージャを使用したメモリ内テーブルのパフォーマンスが大幅に向上しました。以下の2つのグラフは、同じデータを示していますが、x軸のスケールが異なり、データを変更する通常のストアドプロシージャのパフォーマンスが、同時接続数が増えると低下することを示しています。
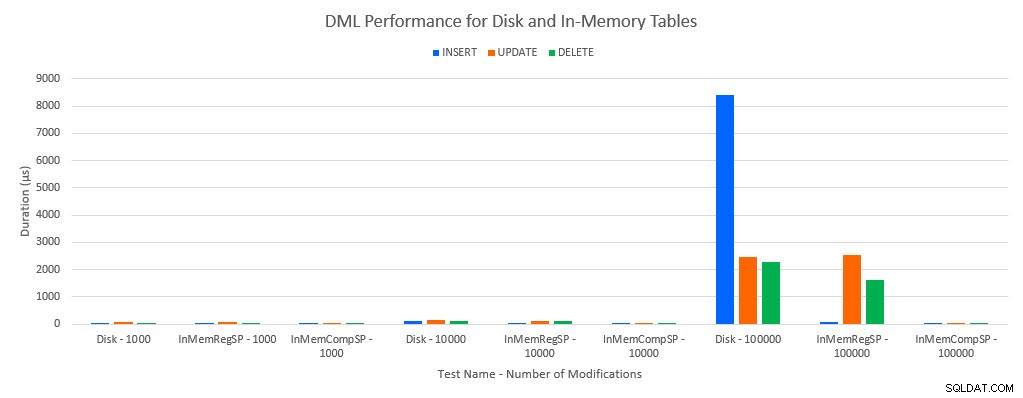
テストおよびワークロードによるDMLパフォーマンス
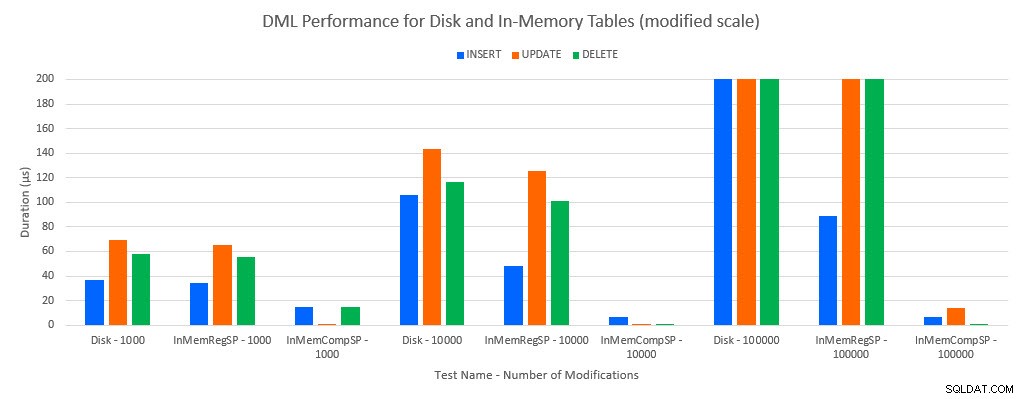
DMLのテストとワークロードによるパフォーマンス[変更されたスケール]>
例外は、通常のストアドプロシージャを使用したインメモリテーブルへのINSERTです。 100接続の場合、平均持続時間はディスクベースのテーブルでは8ミリ秒を超えますが、インメモリテーブルでは100マイクロ秒未満です。考えられる理由は、インメモリテーブルでのロックとラッチがないことです。これは、待機統計データでサポートされています。
| テスト | 挿入 | 更新 | 削除 |
|---|---|---|---|
| InMemTable_RegularSP – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 1000 | WRITELOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| ディスクテーブル– 10,000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 10,000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 10,000 | WRITELOG | WRITELOG | MEMORY_ALLOCATION_EXT |
| ディスクテーブル– 100,000 | PAGELATCH_EX | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 100,000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 100,000 | WRITELOG | WRITELOG | WRITELOG |
待機統計データは、合計リソース待機時間に基づいてここに一覧表示されます(これは通常、最高の平均リソース時間にも変換されますが、例外がありました)。 WRITELOG待機タイプは、ほとんどの場合、このシステムの制限要因です。ただし、PAGELATCH_EXは、INSERTステートメントを実行する100の同時接続を待機します。これは、追加の負荷が発生すると、ディスクベースのテーブルに存在するロックおよびラッチの動作が制限要因になる可能性があることを示しています。ディスクベースのテーブルテストで接続が10および100のUPDATEおよびDELETEシナリオでは、平均リソース待機時間はロック(LCK_M_X)で最も長くなりました。
結論
インメモリOLTPは、適切なワークロードのパフォーマンスを確実に向上させることができます。ただし、ここでテストした例は非常に単純であり、インメモリソリューションに移行する理由だけであると判断するべきではありません。考慮しなければならない制限がまだ複数あり、移行を行う前に徹底的なテストを行う必要があります(特に、メモリ内テーブルへの移行はオフラインプロセスであるため)。しかし、適切なシナリオでは、この新機能によりパフォーマンスが向上します。テーブルがディスク上にあるかメモリ内にあるかに関係なく、耐久性のあるテーブルのトランザクションログ速度など、いくつかの根本的な制限が依然として存在することを理解している限り、ほとんどの場合、方法は低下します。