
3月に、SQLServerで普及しているパフォーマンスの神話に関するシリーズを開始しました。私が時々遭遇する1つの信念は、ペナルティなしでvarcharまたはnvarchar列のサイズを大きくできるということです。
電子メールアドレスを保存していると仮定しましょう。前世では、これにかなり対処していました。当時、RFC 3696は、電子メールアドレスは320文字(64chars @ 255chars)である可能性があると述べていました。新しいRFC#5321は、254文字が電子メールアドレスの最長文字であることを認めています。そして、もしあなたの誰かがそんなに長いアドレスを持っているなら、まあ、多分私達はチャットするべきです。 :-)
さて、あなたが古い基準に従うか新しい基準に従うかにかかわらず、誰かが許可されたすべての文字を使用する可能性をサポートする必要があります。つまり、254文字または320文字を使用する必要があります。しかし、私が見たのは、標準をまったく調べていないことであり、1,000文字、4,000文字、またはそれ以上をサポートする必要があると想定しているだけです。
それでは、さまざまなサイズの電子メールアドレス列を持つテーブルがあり、まったく同じデータを格納している場合に何が起こるかを見てみましょう。
CREATE TABLE dbo.Email_V320 ( id int IDENTITY PRIMARY KEY, email varchar(320) ); CREATE TABLE dbo.Email_V1000 ( id int IDENTITY PRIMARY KEY, email varchar(1000) ); CREATE TABLE dbo.Email_V4000 ( id int IDENTITY PRIMARY KEY, email varchar(4000) ); CREATE TABLE dbo.Email_Vmax ( id int IDENTITY PRIMARY KEY, email varchar(max) );
それでは、システムメタデータから10,000個の架空の電子メールアドレスを生成し、4つのテーブルすべてに同じデータを入力してみましょう。
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') FROM sys.all_columns AS c INNER JOIN sys.all_objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.all_columns AS c2 ON c.[object_id] = c2.[object_id] ORDER BY NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- let's rebuild ALTER INDEX ALL ON dbo.Email_V320 REBUILD; ALTER INDEX ALL ON dbo.Email_V1000 REBUILD; ALTER INDEX ALL ON dbo.Email_V4000 REBUILD; ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;
各テーブルにまったく同じデータが含まれていることを検証するには:
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_<size>;
それらの4つすべてが私にとって35と77をもたらします。あなたのマイレージは異なる場合があります。また、4つのテーブルすべてがディスク上の同じページ数を占めることを確認しましょう:
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name; これらの4つのクエリすべてで89ページが生成されます(ここでも、マイレージは異なる場合があります)。
次に、クラスター化インデックススキャンを実行する一般的なクエリを見てみましょう。
SELECT id, email FROM dbo.Email_<size>;
期間、読み取り、推定コストなどを見ると、すべて同じように見えます。
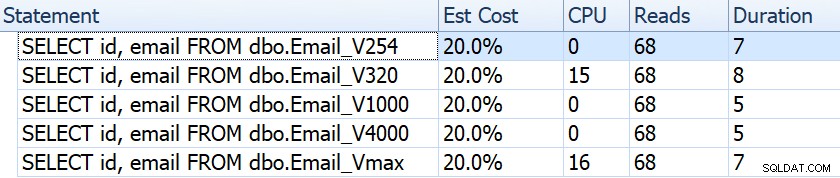
これは、パフォーマンスへの影響がまったくないという誤った仮定に人々を落ち着かせる可能性があります。しかし、もう少し詳しく見てみると、各プランのクラスター化されたインデックススキャンのツールチップで、他のより複雑なクエリで影響を与える可能性のある違いがわかります。

ここから、列の定義が大きいほど、推定される行とデータのサイズが大きくなることがわかります。この単純なクエリでは、クラスター化インデックススキャンですべてのデータを読み取る必要があるため、定義に関係なく、I / Oコスト(0.0512731)はすべてのクエリで同じです。
ただし、この推定行と合計データサイズが影響を与えるシナリオは他にもあります。並べ替えなど、追加のリソースを必要とする操作です。複数の並べ替え操作を必要とする以外は、実際の目的には役立たないこのばかげたクエリを見てみましょう。
SELECT /* V<size> */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V<size>
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email; これらの4つのクエリを実行すると、すべての計画が次のようになります。

ただし、SELECT演算子の警告アイコンは、4000/maxテーブルにのみ表示されます。警告は何ですか?これは、SQL Server 2016で導入された、過剰なメモリ許可の警告です。varchar(4000)の警告は次のとおりです。

そしてvarchar(max)の場合:

少なくともsys.dm_exec_query_statsに従って、もう少し詳しく見て、何が起こっているかを見てみましょう。
SELECT [table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kb FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ORDER BY s.last_grant_kb;
結果:

私のシナリオでは、期間はメモリ付与の違いによる影響を受けませんでしたが(最大の場合を除く)、宣言された列のサイズと一致する線形進行を明確に確認できます。これを使用して、メモリが不十分なシステムで何が起こるかを推定できます。または、はるかに大きなデータセットに対するより複雑なクエリ。または重要な並行性。これらのシナリオはいずれも、並べ替え操作を処理するために流出が必要になる可能性があり、その結果、期間はほぼ確実に影響を受けます。
しかし、これらのより大きなメモリの付与はどこから来るのでしょうか?まったく同じデータに対して、同じクエリであることを忘れないでください。問題は、特定の操作では、SQLServerが列に含まれる可能性のあるデータの量を考慮に入れる必要があることです。実際にデータをプロファイリングすることに基づいてこれを行うことはなく、<=201のヒストグラムステップ値に基づいて仮定を行うことはできません。代わりに、すべての行が宣言された列サイズの半分の値を保持していると推定する必要があります。 。したがって、varchar(4000)の場合、すべての電子メールアドレスの長さが2,000文字であると想定されます。
電子メールアドレスを254文字または320文字より長くすることができない場合、サイズを大きくしても何も得られず、失う可能性のあるものがたくさんあります。後で可変幅の列のサイズを大きくすることは、今すべての欠点に対処するよりもはるかに簡単です。
もちろん、charのサイズを大きくします またはnchar 列には、はるかに明白なペナルティがあります。