インデックスの断片化の除去と防止は、SQL Serverだけでなく、多くのプラットフォームで、通常のデータベース保守操作の一部として長い間使用されてきました。インデックスの断片化は多くの理由でパフォーマンスに影響を与えます。ほとんどの人は、回避すべきものとして、ディスクベースのストレージに物理的に発生する可能性のあるI/Oのランダムな小さなブロックの影響について話します。インデックスの断片化に関する一般的な懸念は、先読みI/Oのサイズを制限することでスキャンのパフォーマンスに影響を与えることです。これは、インデックスの断片化によって引き起こされる問題についてのこの限られた理解に基づいており、一部の人々は、インデックスの断片化はソリッドステートストレージデバイス(SSD)では問題ではなく、今後はインデックスの断片化を無視できるという考えを広め始めています。
ただし、これはいくつかの理由で当てはまりません。この記事では、これらの理由の1つを説明し、デモンストレーションします。インデックスの断片化は、クエリの実行プランの選択に悪影響を与える可能性があります。これは、インデックスの断片化により、通常、インデックスのページ数が増えるために発生します(これらの余分なページは、ページ分割から取得されます。 このサイトのこの投稿で説明されているように、操作)、したがって、そのインデックスの使用は、SQLServerのクエリオプティマイザによってより高いコストがかかると見なされます。
例を見てみましょう。
最初に行う必要があるのは、適切なテストデータベースとデータセットを構築して、インデックスの断片化がSQLServerでのクエリプランの選択にどのように影響するかを調べるために使用することです。次のスクリプトは、同じデータを持つ2つのテーブルを含むデータベースを作成します。1つは大きく断片化されており、もう1つは最小限に断片化されています。
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO インデックスを再構築した後、次のクエリで断片化レベルを確認できます。
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO 結果:

ここで、 GuidHighFragmentation テーブルは99%断片化されており、 GuidLowFragmentation よりも31%多くのページスペースを使用します 同じ7,000,000行のデータがあるにもかかわらず、データベース内のテーブル。各テーブルに対して基本的な集計クエリを実行し、SentryOneプランエクスプローラーを使用してSQL Serverのデフォルトのインストール(デフォルトの構成オプションと値を使用)で実行プランを比較する場合:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


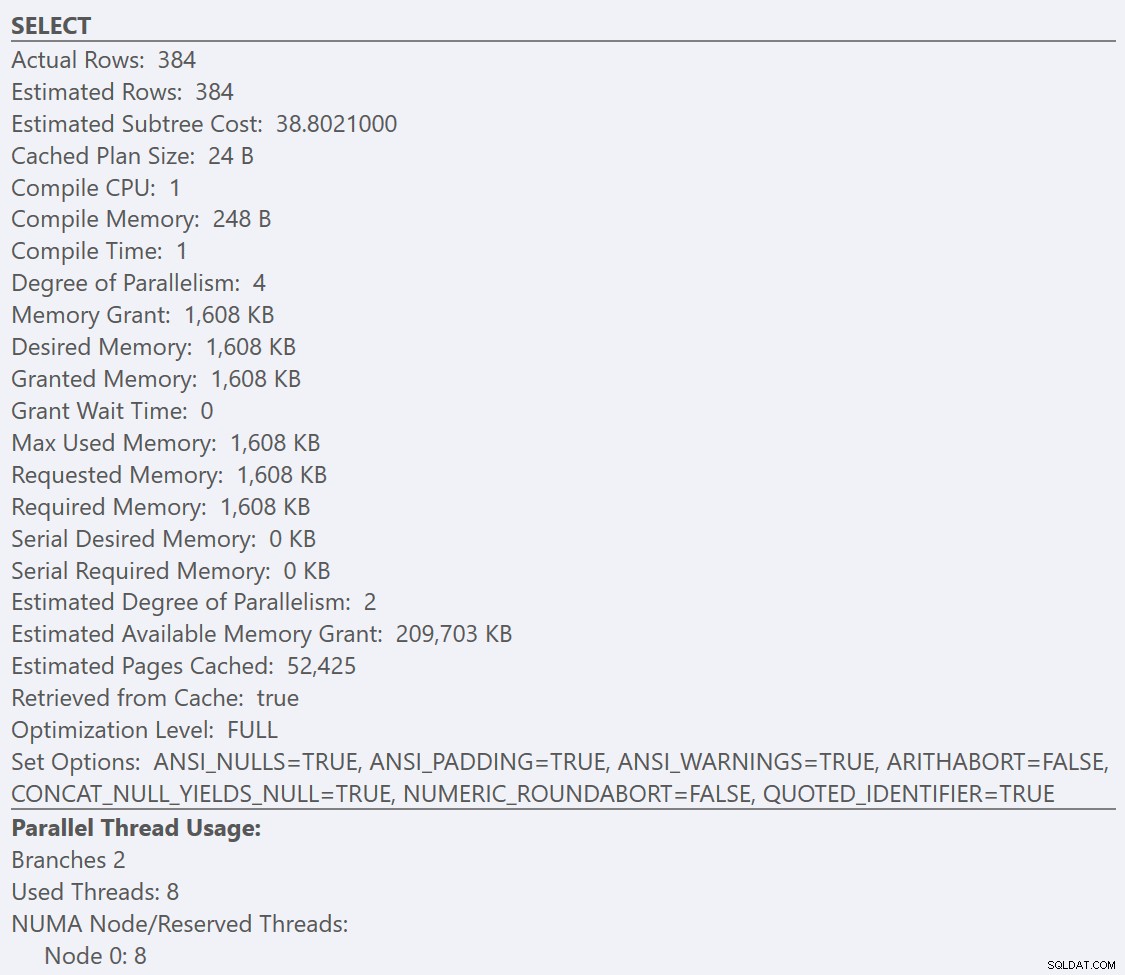

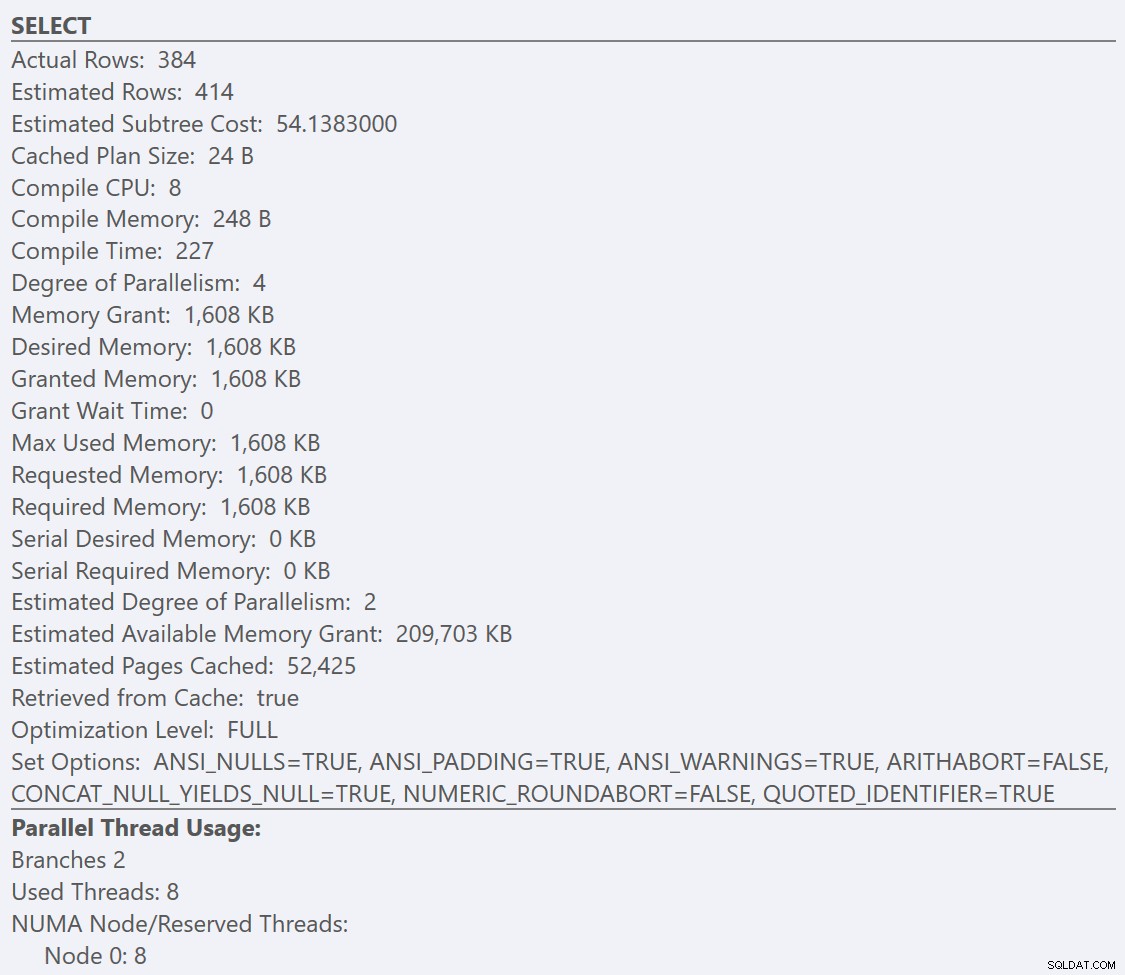
SELECTのツールチップを見ると 各プランの演算子、 GuidLowFragmentationのプラン テーブルのクエリコストは38.80(ツールチップの上から3行目)ですが、GuidHighFragmentationプランのプランのクエリコストは54.14です。
SQL Serverのデフォルト構成では、推定クエリコストが「並列処理のコストしきい値」sp_configureオプションのデフォルトの5よりも高いため、これらのクエリは両方とも並列実行プランを生成することになります。これは、クエリオプティマイザが最初にシリアルを生成するためです。クエリのプランをコンパイルするときのプラン(単一のスレッドでのみ実行できます)。そのシリアルプランの推定コストが、構成された「並列処理のコストしきい値」値を超える場合、代わりに並列プランが生成されてキャッシュされます。
ただし、「並列処理のコストしきい値」sp_configureオプションがデフォルトの5に設定されておらず、より高く設定されている場合はどうなりますか?このオプションをデフォルトの低い5から25から50(またはそれ以上)に増やすことをお勧めします(そして正しい方法です)。これにより、小さなクエリで並列処理の追加のオーバーヘッドが発生するのを防ぐことができます。
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
ベストプラクティスのガイドラインに従い、「並列処理のコストしきい値」を50に増やした後、クエリを再実行すると、 GuidHighFragmentationの同じ実行プランになります。 テーブルですが、 GuidLowFragmentation クエリのシリアルコスト44.68は、「並列処理のコストしきい値」の値を下回っているため(推定並列コストは38.80であったことを思い出してください)、シリアル実行プランを取得します。
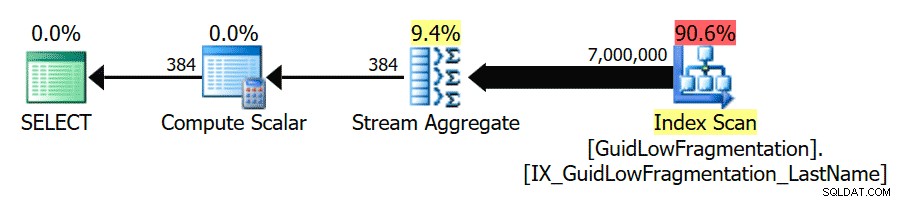
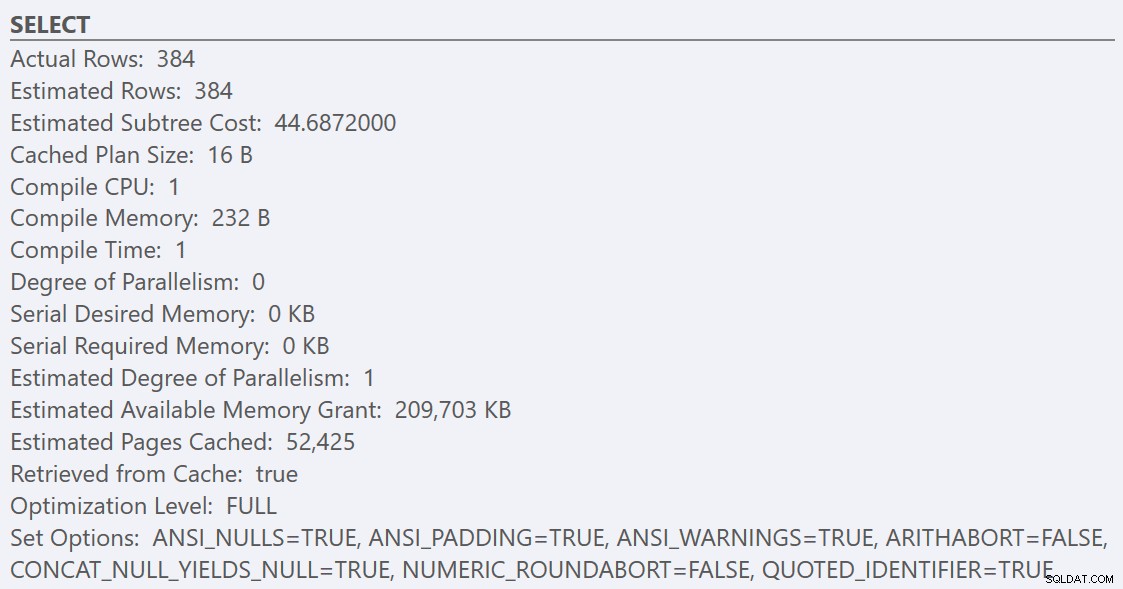
GuidHighFragmentationの追加のページスペース クラスター化されたインデックスは、コストを「並列処理のコストしきい値」のベストプラクティス設定より上に保ち、並列プランを作成しました。
ここで、これがベストプラクティスのガイダンスに従い、最初に「並列処理のコストしきい値」を値50に設定したシステムであると想像してください。その後、インデックスの断片化を完全に無視するという誤ったアドバイスに従いました。
これは基本的なクエリではなく、より複雑ですが、システムで非常に頻繁に実行され、インデックスの断片化の結果として、ページ数がコストを並列プランに転嫁すると、より多くのCPUと結果として、全体的なワークロードのパフォーマンスに影響を与えます。
職業はなんですか?クエリがシリアル実行プランを維持するように、「並列処理のコストしきい値」を増やしますか? OPTION(MAXDOP 1)を使用してクエリをヒントし、シリアル実行プランに強制しますか?
インデックスの断片化は、データベース内の1つのテーブルに影響を与えるだけでなく、完全に無視している可能性があることに注意してください。多くのクラスター化インデックスと非クラスター化インデックスが断片化されており、必要以上のページ数を持っている可能性があります。そのため、インデックスの断片化が広まっている結果として、多くのI / O操作のコストが増加し、多くの非効率的なクエリが発生する可能性があります。計画。
概要
信じてほしいと思う人もいるかもしれないので、インデックスの断片化を完全に無視することはできません。これを行うことによる他の欠点の中でも、クエリ実行の累積コストは、クエリプランのシフトに追いつきます。これは、クエリオプティマイザがコストベースのオプティマイザであり、これらの断片化されたインデックスを利用するのに費用がかかると正しく見なすためです。
ここでのクエリとシナリオは明らかに考案されたものですが、クライアントシステムの実際の断片化によって実行プランが変更されるのを見てきました。
使用しているハードウェアに関係なく、断片化によってワークロードのパフォーマンスの問題が発生するインデックスのインデックスの断片化に対処していることを確認する必要があります。