数週間前のPASSサミットで、MicrosoftはSQL Server 2019のCTP2.1をリリースしました。また、CTPに含まれる大きな機能拡張の1つは、ScalarUDFインライン化です。このリリースの前は、スカラーUDFのインライン化と以前のバージョンのSQL ServerでのスカラーUDFのRBAR(row-by-agonizing-row)実行のパフォーマンスの違いを試してみたかったのですが、 関数の作成 SQL Server Books Onlineで、これまで見たことのないステートメント。
CREATE FUNCTIONのDDL 関数オプションのWITH句をサポートしており、Books Onlineを読んでいるときに、構文に次のものが含まれていることに気付きました。
-Transact-SQL関数句::={[ENCRYPTION] | [スキーマバインド]| [NULL入力でNULLを返します| NULL入力で呼び出されました]| [EXECUTE_AS_Clause]}
RETURNS NULL ON NULL INPUTについて本当に興味がありました 関数オプションなので、いくつかのテストを行うことにしました。少なくともSQLServer2008 R2以降、製品に含まれているのは実際にはスカラーUDF最適化の形式であることがわかって非常に驚きました。
NULL入力が提供されたときにスカラーUDFが常にNULL結果を返すことがわかっている場合、UDFは常に RETURNS NULL ON NULL INPUTを使用して作成する必要があります。 これは、SQL Serverが、入力がNULLである行に対して関数定義をまったく実行しないためです。つまり、実際に関数を短絡し、関数本体の無駄な実行を回避します。
この動作を示すために、最新の累積的な更新が適用されたSQLServer2017インスタンスとAdventureWorks2017を使用します。 dbo.ufnLeadingZerosに同梱されているGitHubのデータベース(ここからダウンロードできます) 入力値に先行ゼロを追加し、それらの先行ゼロを含む8文字の文字列を返す関数。 RETURNS NULL ON NULL INPUTを含むその関数の新しいバージョンを作成します。 オプションなので、実行パフォーマンスについて元の関数と比較できます。
USE [AdventureWorks2017]; GO CREATE FUNCTION [dbo]。[ufnLeadingZeros_new](@Value int)RETURNS varchar(8)WITH SCHEMABINDING、RETURNS NULL INPUT AS BEGIN DECLARE @ReturnValue varchar(8); SET @ReturnValue =CONVERT(varchar(8)、@Value); SET @ReturnValue =REPLICATE( '0'、8 --DATALENGTH(@ReturnValue))+ @ReturnValue; RETURN(@ReturnValue);終わり; GO
2つの関数のデータベースエンジン内での実行パフォーマンスの違いをテストする目的で、サーバー上に拡張イベントセッションを作成して、 sqlserver.module_endを追跡することにしました。 イベント。各行のスカラーUDFの各実行の最後に発生します。これにより、行ごとの処理セマンティクスを示し、テスト中に関数が実際に呼び出された回数を追跡することもできます。 sql_batch_completedも収集することにしました およびsql_statement_completed イベントを作成し、 session_idですべてをフィルタリングします 実際にテストを実行しているセッションに関連する情報のみをキャプチャしていることを確認します(これらの結果を複製する場合は、以下のコードのすべての場所で74をテストのセッションIDに変更する必要がありますコードが実行されます)。イベントセッションはTRACK_CAUSALITYを使用しています activity_id.seq_no を使用して、関数の実行回数を簡単にカウントできるようにします。 イベントの値( session_idを満たすイベントごとに1つずつ増加します フィルタ)。
CREATE EVENT SESSION [Session72] ON SERVER ADD EVENT sqlserver.module_end(WHERE([package0]。[equal_uint64]([sqlserver]。[session_id]、(74))))、ADD EVENT sqlserver.sql_batch_completed(WHERE( [package0]。[equal_uint64]([sqlserver]。[session_id]、(74))))、ADD EVENT sqlserver.sql_batch_starting(WHERE([package0]。[equal_uint64]([sqlserver]。[session_id]、(74) )))、ADD EVENT sqlserver.sql_statement_completed(WHERE([package0]。[equal_uint64]([sqlserver]。[session_id]、(74))))、ADD EVENT sqlserver.sql_statement_starting(WHERE([package0]。[equal_uint64] ([sqlserver]。[session_id]、(74))))WITH(TRACK_CAUSALITY =ON)GO
イベントセッションを開始し、ManagementStudioでLiveData Viewerを開いたら、2つのクエリを実行しました。 1つは、元のバージョンの関数を使用して、 CurrencyRateIDにゼロを埋め込みます。 Sales.SalesOrderHeaderの列 テーブル、および同じ出力を生成するが RETURNS NULL ON NULL INPUTを使用する新しい関数 オプションで、比較のために実際の実行計画情報を取得しました。
SELECT SalesOrderID、dbo.ufnLeadingZeros(CurrencyRateID)FROM Sales.SalesOrderHeader; GO SELECT SalesOrderID、dbo.ufnLeadingZeros_new(CurrencyRateID)FROM Sales.SalesOrderHeader; GO
拡張イベントデータを確認すると、いくつかの興味深いことがわかりました。まず、元の関数は31,465回実行されました( module_end のカウントから) イベント)および sql_statement_completedの合計CPU時間 イベントは204ミリ秒で、継続時間は482ミリ秒でした。
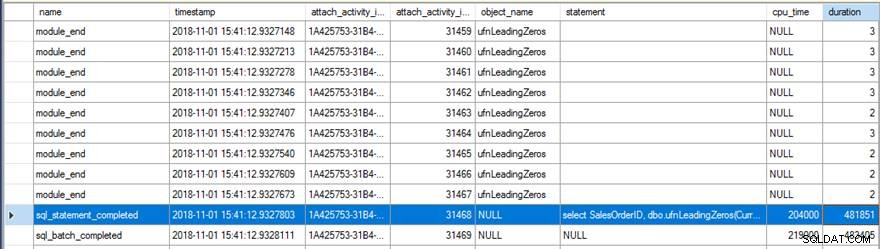
RETURNS NULL ON NULL INPUTを備えた新しいバージョン 指定されたオプションは13,976回しか実行されませんでした(ここでも、 module_end のカウントから) イベント)および sql_statement_completedのCPU時間 イベントは78ミリ秒で、持続時間は359ミリ秒でした。

これは興味深いと思ったので、実行カウントを確認するために、次のクエリを実行して NOT NULLをカウントしました。 Sales.SalesOrderHeader の値行、NULL値行、および合計行 テーブル。
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END)AS NOTNULL、SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END)AS NULLVALUE、COUNT(*)FROM Sales.SalesOrderHead
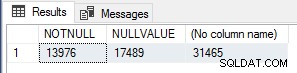
これらの番号は、 module_endの番号に正確に対応しています。 各テストのイベントであるため、これは間違いなくスカラーUDFの非常に単純なパフォーマンス最適化であり、入力値がNULLの場合に関数の結果がNULLになることがわかっている場合は、関数の実行を短絡/バイパスするために使用する必要があります。完全にそれらの行のために。
実際の実行計画のQueryTimeStats情報には、パフォーマンスの向上も反映されています。
これは、CPU時間だけでもかなりの大幅な削減であり、一部のシステムにとっては重大な問題点となる可能性があります。
スカラーUDFの使用は、パフォーマンスのよく知られた設計アンチパターンであり、コードを書き直して、使用とパフォーマンスの低下を回避するためのさまざまな方法があります。ただし、それらがすでに配置されていて、簡単に変更または削除できない場合は、 RETURNS NULL ON NULL INPUTを使用してUDFを再作成するだけです。 UDFが使用されるデータセット全体に多数のNULL入力がある場合、オプションはパフォーマンスを向上させる非常に簡単な方法である可能性があります。