RBCのジュニア債券アナリストであるKarenLyは、完全一致を見つけるのではなく、最も近い一致を見つけることを含むT-SQLチャレンジを私に与えました。この記事では、一般化された単純化された形式の課題について説明します。
課題
課題には、T1とT2の2つのテーブルの行を照合することが含まれます。次のコードを使用して、testdbというサンプルデータベースを作成し、その中にテーブルT1とT2を作成します。
SET NOCOUNT ON;
IF DB_ID('testdb') IS NULL
CREATE DATABASE testdb;
GO
USE testdb;
DROP TABLE IF EXISTS dbo.T1, dbo.T2;
CREATE TABLE dbo.T1
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T1 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T1_col1 DEFAULT(0xAA)
);
CREATE TABLE dbo.T2
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T2 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T2_col1 DEFAULT(0xBB)
); ご覧のとおり、T1とT2の両方にvalという数値列(この例ではINT型)があります。課題は、T1の各行をT2.valとT1.valの絶対差が最も小さいT2の行と一致させることです。同点の場合(T2で複数の一致する行)、valの昇順、keycolの昇順に基づいて一番上の行を一致させます。つまり、val列の値が最も低い行であり、まだ同点の場合は、keycol値が最も低い行です。タイブレーカーは、決定論を保証するために使用されます。
次のコードを使用して、ソリューションの正確さを確認できるように、T1とT2にサンプルデータの小さなセットを入力します。
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 (val)
VALUES(1),(1),(3),(3),(5),(8),(13),(16),(18),(20),(21);
INSERT INTO dbo.T2 (val)
VALUES(2),(2),(7),(3),(3),(11),(11),(13),(17),(19); T1の内容を確認してください:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T1 ORDER BY val, keycol;
このコードは次の出力を生成します:
keycol val othercols ----------- ----------- --------- 1 1 0xAA 2 1 0xAA 3 3 0xAA 4 3 0xAA 5 5 0xAA 6 8 0xAA 7 13 0xAA 8 16 0xAA 9 18 0xAA 10 20 0xAA 11 21 0xAA
T2の内容を確認してください:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T2 ORDER BY val, keycol;
このコードは次の出力を生成します:
keycol val othercols ----------- ----------- --------- 1 2 0xBB 2 2 0xBB 4 3 0xBB 5 3 0xBB 3 7 0xBB 6 11 0xBB 7 11 0xBB 8 13 0xBB 9 17 0xBB 10 19 0xBB
与えられたサンプルデータの望ましい結果は次のとおりです。
keycol1 val1 othercols1 keycol2 val2 othercols2 ----------- ----------- ---------- ----------- ----------- ---------- 1 1 0xAA 1 2 0xBB 2 1 0xAA 1 2 0xBB 3 3 0xAA 4 3 0xBB 4 3 0xAA 4 3 0xBB 5 5 0xAA 4 3 0xBB 6 8 0xAA 3 7 0xBB 7 13 0xAA 8 13 0xBB 8 16 0xAA 9 17 0xBB 9 18 0xAA 9 17 0xBB 10 20 0xAA 10 19 0xBB 11 21 0xAA 10 19 0xBB
チャレンジに取り掛かる前に、目的の結果を調べて、タイブレークロジックを含むマッチングロジックを理解していることを確認してください。たとえば、keycolが5、valが5であるT1の行について考えてみます。この行には、T2で最も近い一致が複数あります。
keycol val othercols ----------- ----------- --------- 4 3 0xBB 5 3 0xBB 3 7 0xBB
これらすべての行で、T2.valとT1.val(5)の絶対差は2です。valの昇順に基づくタイブレークロジックを使用して、ここで一番上の行を昇順するkeycolは、valが3、keycolが4の行です。
サンプルデータの小さなセットを使用して、ソリューションの有効性を確認します。パフォーマンスを確認するには、より大きなセットが必要です。次のコードを使用して、GetNumsというヘルパー関数を作成します。この関数は、要求された範囲の整数のシーケンスを生成します。
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE OR ALTER FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO 次のコードを使用して、T1とT2に大量のサンプルデータを入力します。
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; 変数@numrowsT1および@numrowsT2は、テーブルに入力する行数を制御します。変数@maxvalT1と@maxvalT2は、val列の個別の値の範囲を制御するため、列の密度に影響を与えます。上記のコードは、テーブルをそれぞれ1,000,000行で埋め、両方のテーブルのval列に1〜10,000,000の範囲を使用します。これにより、列の密度が低くなります(多数の個別の値、少数の重複)。より低い最大値を使用すると、密度が高くなります(個別の値の数が少なくなるため、重複が多くなります)。
ソリューション1、1つのTOPサブクエリを使用
最も単純で最も明白な解決策は、おそらくT1をクエリするソリューションであり、CROSS APPLY演算子を使用すると、TOP(1)フィルターを使用してクエリが適用され、T2.valを使用してT1.valとT2.valの絶対差で行が並べ替えられます。 、タイブレーカーとしてのT2.keycol。ソリューションのコードは次のとおりです。
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) T2.*
FROM dbo.T2
ORDER BY ABS(T2.val - T1.val), T2.val, T2.keycol ) AS A; 各テーブルには1,000,000行あることを忘れないでください。また、val列の密度は両方のテーブルで低くなっています。残念ながら、適用されるクエリにはフィルタリング述語がなく、順序付けには列を操作する式が含まれるため、ここでサポートインデックスを作成する可能性はありません。このクエリは、図1の計画を生成します。
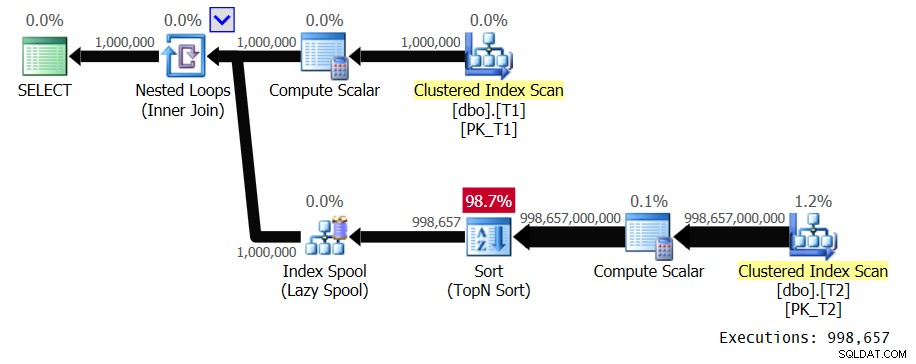 図1:ソリューション1の計画
図1:ソリューション1の計画
ループの外部入力は、T1から1,000,000行をスキャンします。ループの内部入力は、T2のフルスキャンと、個別のT1.val値ごとにTopNソートを実行します。私たちの計画では、密度が非常に低いため、これは998,657回発生します。 T1.valでキー設定されたインデックススプールに行を配置して、T1.val値の重複オカレンスにそれらを再利用できるようにしますが、重複はほとんどありません。この計画には2次の複雑さがあります。ループの内部ブランチの予想されるすべての実行の間に、1兆行近くを処理することが予想されます。クエリが処理する多数の行について話すとき、数十億の行について言及し始めると、人々はあなたが高価なクエリを扱っていることをすでに知っています。通常、米国の国債や株式市場の暴落について話し合っていない限り、人々は数兆のような言葉を発しません。通常、クエリ処理のコンテキストではそのような数値を処理しません。しかし、2次の複雑さを持つ計画は、すぐにそのような数になる可能性があります。 [ライブクエリ統計を含める]を有効にしてSSMSでクエリを実行すると、ラップトップのT1からわずか100行を処理するのに39.6秒かかりました。これは、このクエリが完了するまでに約4。5日かかることを意味します。問題は、あなたは本当に一気見のライブクエリプランに興味がありますか?試して設定するのに興味深いギネス記録になる可能性があります。
ソリューション2、2つのTOPサブクエリを使用
完了するまでに数日ではなく数秒かかるソリューションを求めていると仮定して、ここにアイデアがあります。適用されたテーブル式で、2つの内部TOP(1)クエリを統合します。1つはT2.val
このソリューションをサポートするための推奨インデックスは次のとおりです。
CREATE INDEX idx_val_key ON dbo.T1(val, keycol) INCLUDE(othercols); CREATE INDEX idx_val_key ON dbo.T2(val, keycol) INCLUDE(othercols); CREATE INDEX idx_valD_key ON dbo.T2(val DESC, keycol) INCLUDE(othercols);
完全なソリューションコードは次のとおりです。
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; 各テーブルには1,000,000行あり、val列の値は1〜10,000,000(低密度)の範囲であり、最適なインデックスが設定されていることに注意してください。
このクエリの計画を図2に示します。
図2:ソリューション2の計画
T2でのインデックスの最適な使用を観察し、線形スケーリングの計画を作成します。このプランは、前のプランと同じ方法でインデックススプールを使用します。つまり、重複するT1.val値に対してループの内部ブランチで作業を繰り返さないようにします。システムでこのクエリを実行するために取得したパフォーマンス統計は次のとおりです。
Elapsed: 27.7 sec, CPU: 27.6 sec, logical reads: 17,304,674
解決策2、スプーリングが無効になっている
ここでインデックススプールが本当に有益かどうか疑問に思わずにはいられません。重要なのは、重複するT1.val値に対して作業を繰り返さないようにすることですが、密度が非常に低い私たちのような状況では、重複はほとんどありません。これは、スプーリングに関連する作業が、単に重複する作業を繰り返すよりも大きい可能性が高いことを意味します。これを確認する簡単な方法があります。トレースフラグ8690を使用すると、次のようにプランでスプーリングを無効にできます。
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); この実行について、図3に示す計画を取得しました:
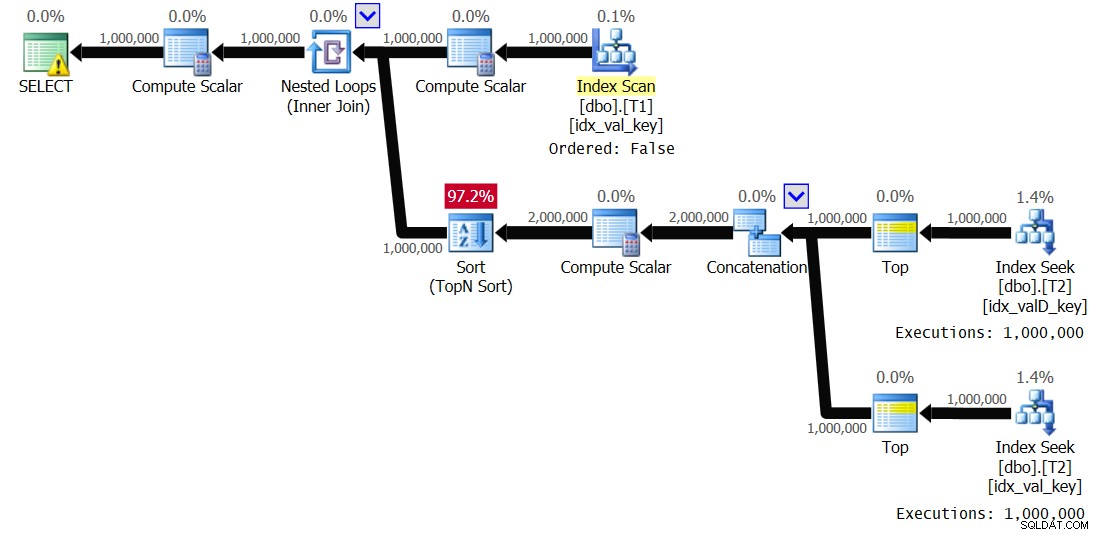 図3:スプーリングを無効にしたソリューション2の計画
図3:スプーリングを無効にしたソリューション2の計画
インデックススプールが消えたことを確認します。今回は、ループの内部ブランチが1,000,000回実行されます。この実行で得られたパフォーマンス統計は次のとおりです。
Elapsed: 19.18 sec, CPU: 19.17 sec, logical reads: 6,042,148
これは、実行時間の44%の削減です。
ソリューション2、値の範囲とインデックスを変更
T1.val値の密度が低い場合は、スプーリングを無効にすることは非常に理にかなっています。ただし、高密度の場合、スプーリングは非常に有益です。たとえば、次のコードを実行して、T1とT2にサンプルデータ設定@maxvalT1と@maxvalT2を1000(最大1,000個の個別の値)に再設定します。
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 1000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 1000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; 最初にトレースフラグなしでソリューション2を再実行します:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; この実行の計画を図4に示します。
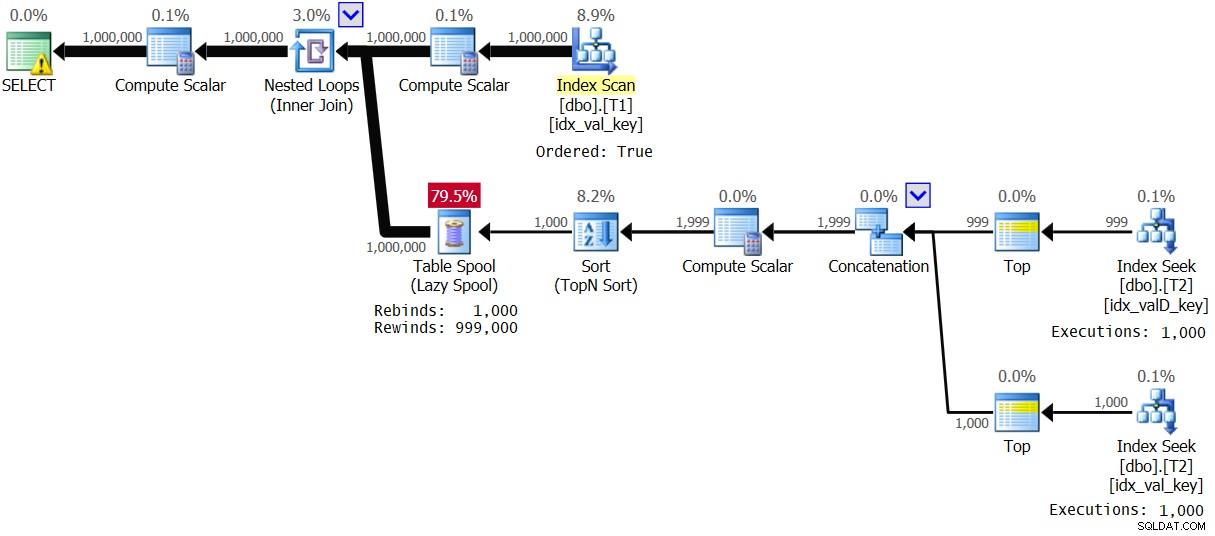 図4:ソリューション2の計画、値の範囲は1〜1000 >
図4:ソリューション2の計画、値の範囲は1〜1000 >
オプティマイザは、T1.valの密度が高いため、別のプランを使用することにしました。 T1のインデックスがキー順にスキャンされることを確認します。したがって、個別のT1.val値が最初に出現するたびに、ループの内部分岐が実行され、結果は通常のテーブルスプールにスプールされます(再バインド)。次に、値が最初に出現しないたびに、巻き戻しが適用されます。 1,000の異なる値を使用すると、内部ブランチは1,000回だけ実行されます。これにより、優れたパフォーマンス統計が得られます:
Elapsed: 1.16 sec, CPU: 1.14 sec, logical reads: 23,278
次に、スプーリングを無効にしてソリューションを実行してみてください:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); 図5に示す計画を取得しました。
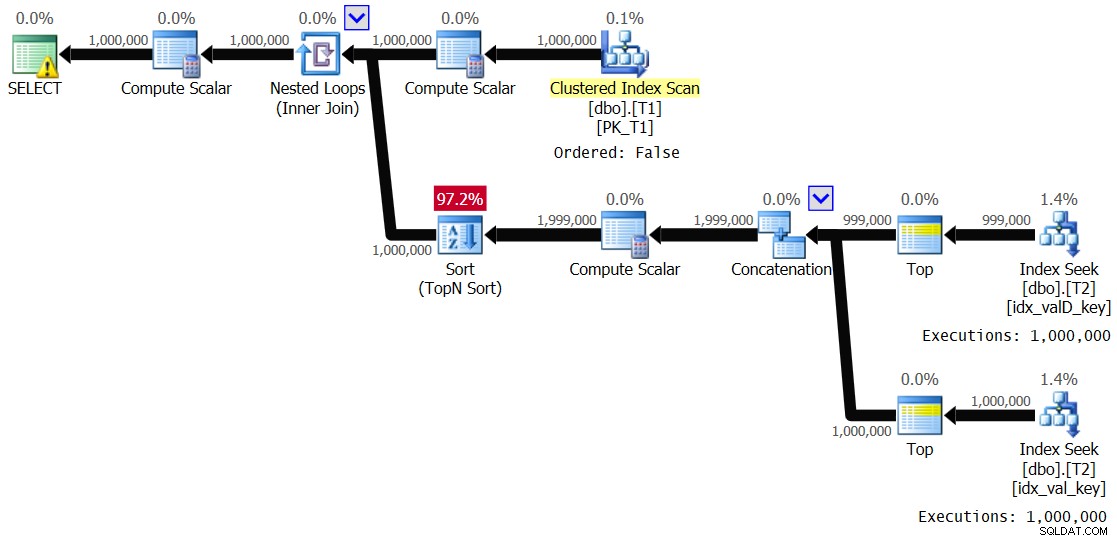 図5:ソリューション2の計画、値の範囲は1〜1,000、スプーリングは無効
図5:ソリューション2の計画、値の範囲は1〜1,000、スプーリングは無効
これは、図3で前に示した計画と基本的に同じです。ループの内側のブランチは1,000,000回実行されます。この実行で得られたパフォーマンス統計は次のとおりです。
Elapsed: 24.5 sec, CPU: 24.2 sec, logical reads: 8,012,548
明らかに、T1.valに高密度がある場合は、スプーリングを無効にしないように注意する必要があります。
状況が単純で、サポートするインデックスを作成できる場合、人生は良好です。実際には、実際には、クエリに十分な追加ロジックがあり、最適なサポートインデックスを作成する機能が妨げられている場合があります。このような場合、ソリューション2はうまく機能しません。
インデックスをサポートしないソリューション2のパフォーマンスを示すには、T1とT2にサンプルデータ設定@maxvalT1と@maxvalT2を10000000(値の範囲1〜10M)に再設定し、サポートするインデックスを削除します。
DROP INDEX IF EXISTS idx_val_key ON dbo.T1;
DROP INDEX IF EXISTS idx_val_key ON dbo.T2;
DROP INDEX IF EXISTS idx_valD_key ON dbo.T2;
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; SSMSで[ライブクエリ統計を含める]を有効にして、ソリューション2を再実行します。
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; このクエリについて、図6に示す計画を取得しました:
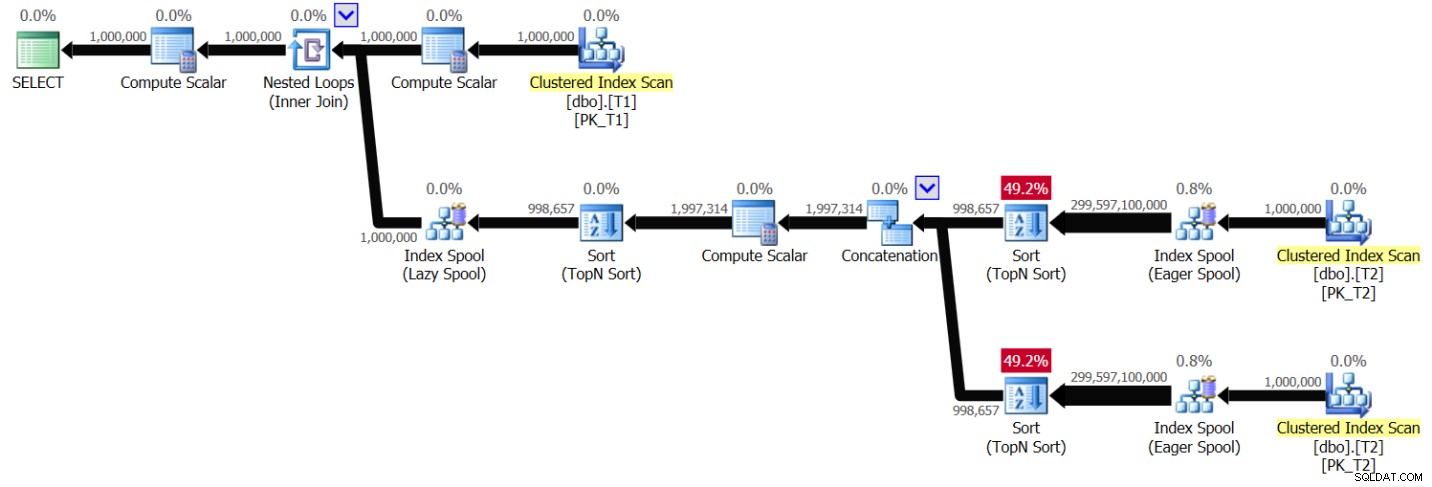 図6:ソリューション2の計画、インデックスなし、値の範囲1〜1,000,000
図6:ソリューション2の計画、インデックスなし、値の範囲1〜1,000,000
図1で前に示したものと非常によく似たパターンを見ることができますが、今回は、プランが個別のT1.val値ごとにT2を2回スキャンします。繰り返しますが、計画の複雑さは2次式になります。 [ライブクエリ統計を含める]を有効にしてSSMSでクエリを実行すると、ラップトップでT1から100行を処理するのに49.6秒かかりました。つまり、このクエリが完了するまでに約5。7日かかるはずです。もちろん、ライブクエリプランを一気見することでギネス世界記録を破ろうとしている場合、これは朗報を意味する可能性があります。
結論
この素晴らしい最も近い試合のチャレンジを提示してくれたRBCのKarenLyに感謝します。私はそれを処理するための彼女のコードに非常に感銘を受けました。これには、彼女のシステムに固有の多くの追加ロジックが含まれていました。この記事では、最適なサポートインデックスを作成できる場合に、合理的に実行されるソリューションを示しました。しかし、ご覧のとおり、これがオプションではない場合、明らかに、取得する実行時間はひどいものです。最適なサポートインデックスがなくてもうまくいくソリューションを考えられますか?続く…