この記事は、T-SQLのバグ、落とし穴、およびベストプラクティスに関するシリーズの第3回です。以前は、決定論とサブクエリについて説明しました。今回は結合に焦点を当てます。ここで取り上げるバグとベストプラクティスのいくつかは、他のMVPに対して行った調査の結果です。 Erland Sommarskog、Aaron Bertrand、Alejandro Mesa、Umachandar Jayachandran(UC)、Fabiano Neves Amorim、Milos Radivojevic、Simon Sabin、Adam Machanic、Thomas Grohser、Chan Ming Man、PaulWhiteに洞察を提供してくれてありがとう!
私の例では、TSQLV5というサンプルデータベースを使用します。このデータベースを作成してデータを取り込むスクリプトはここにあり、そのER図はここにあります。
この記事では、4つの古典的な一般的なバグに焦点を当てます。外部結合のCOUNT(*)、ダブルディッピングアグリゲート、ON-WHERE矛盾、およびOUTER-INNER結合矛盾です。これらのバグはすべて、T-SQLクエリの基本に関連しており、単純なベストプラクティスに従うと簡単に回避できます。
外部結合のCOUNT(*)
最初のバグは、外部結合とCOUNT(*)集計を使用した結果として、空のグループについて報告された誤ったカウントに関係しています。顧客あたりの注文数と総貨物量を計算する次のクエリについて考えてみます。
USE TSQLV5; -- https://tsql.solidq.com/SampleDatabases/TSQLV5.zip SELECT custid, COUNT(*) AS numorders, SUM(freight) AS totalfreight FROM Sales.Orders GROUP BY custid ORDER BY custid;
このクエリは、次の出力(省略形)を生成します:
custid numorders totalfreight ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559.52 ... 21 7 232.75 23 5 637.94 ... 56 10 862.74 58 6 277.96 ... 87 15 822.48 88 9 194.71 89 14 1353.06 90 7 88.41 91 7 175.74 (89 rows affected)
現在、Customersテーブルには91の顧客が存在し、そのうち89が注文しました。したがって、このクエリの出力には、89の顧客グループとその正しい注文数および総貨物量が表示されます。 ID 22および57の顧客は、Customersテーブルに存在しますが、注文を行っていないため、結果には表示されません。
関連する注文がない顧客をクエリ結果に含めるように要求されたとします。このような場合に行うべき自然なことは、顧客と注文の間で左外部結合を実行して、注文なしで顧客を保護することです。ただし、既存のソリューションを結合を適用するソリューションに変換する際の一般的なバグは、次のクエリ(クエリ1と呼びます)に示すように、注文数の計算をCOUNT(*)のままにすることです。
SELECT C.custid, COUNT(*) AS numorders, SUM(O.freight) AS totalfreight
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
GROUP BY C.custid
ORDER BY C.custid; このクエリは次の出力を生成します:
custid numorders totalfreight ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559.52 ... 21 7 232.75 22 1 NULL 23 5 637.94 ... 56 10 862.74 57 1 NULL 58 6 277.96 ... 87 15 822.48 88 9 194.71 89 14 1353.06 90 7 88.41 91 7 175.74 (91 rows affected)
今回は顧客22と57が結果に表示されますが、COUNT(*)は注文ではなく行をカウントするため、注文数は0ではなく1になります。 SUM(freight)はNULL入力を無視するため、総貨物は正しく報告されます。
このクエリの計画を図1に示します。
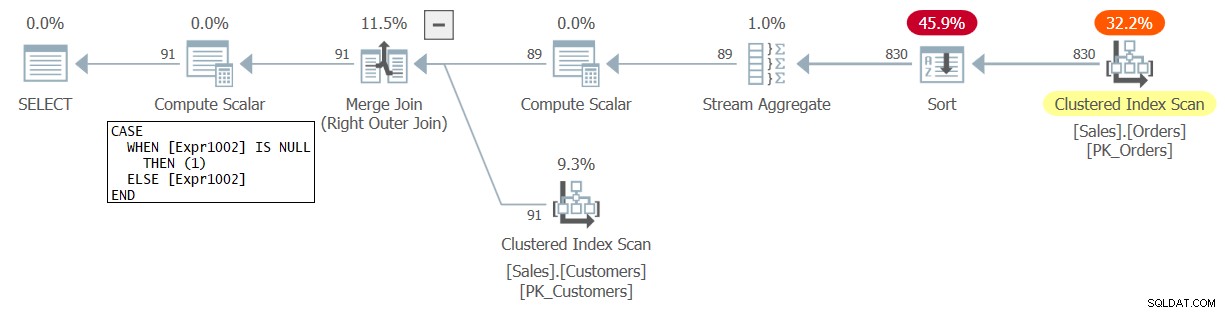 図1:クエリ1の計画
図1:クエリ1の計画
このプランでは、Expr1002はグループごとの行数を表します。これは、外部結合の結果として、一致する注文がない顧客の場合、最初はNULLに設定されます。次に、ルートSELECTノードのすぐ下にあるCompute Scalar演算子は、NULLを1に変換します。これは、順序をカウントするのではなく、行をカウントした結果です。
このバグを修正するには、外部結合の保存されていない側から要素にCOUNT集計を適用し、入力としてNULL可能でない列を使用するようにします。主キー列は良い選択です。バグが修正されたソリューションクエリ(クエリ2と呼びます)は次のとおりです。
SELECT C.custid, COUNT(O.orderid) AS numorders, SUM(O.freight) AS totalfreight
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
GROUP BY C.custid
ORDER BY C.custid; このクエリの出力は次のとおりです。
custid numorders totalfreight ------- ---------- ------------- 1 6 225.58 2 4 97.42 3 7 268.52 4 13 471.95 5 18 1559.52 ... 21 7 232.75 22 0 NULL 23 5 637.94 ... 56 10 862.74 57 0 NULL 58 6 277.96 ... 87 15 822.48 88 9 194.71 89 14 1353.06 90 7 88.41 91 7 175.74 (91 rows affected)
今回は、顧客22と57が正しいゼロのカウントを示していることに注意してください。
このクエリの計画を図2に示します。
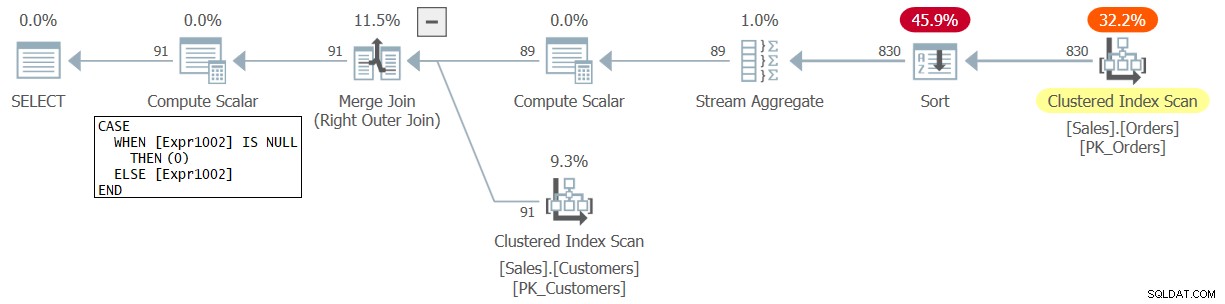 図2:クエリ2の計画
図2:クエリ2の計画
プランの変更も確認できます。ここでは、一致する注文がない顧客の数を表すNULLが、今回は1ではなく0に変換されます。
結合を使用する場合は、COUNT(*)集計の適用に注意してください。外部結合を使用する場合、通常はバグです。ベストプラクティスは、COUNT集計を、1対多結合の多側からNULL不可能な列に適用することです。主キー列はNULLを許可しないため、この目的に適しています。要件の変更により、後で内部結合を外部結合に変更する必要があるかどうかわからないため、これは内部結合を使用する場合でも良い習慣になる可能性があります。
ダブルディッピング骨材
2番目のバグには、結合と集計の混合も含まれます。今回は、ソース値を複数回考慮します。例として次のクエリを考えてみましょう。
SELECT C.custid, COUNT(O.orderid) AS numorders, SUM(O.freight) AS totalfreight,
CAST(SUM(OD.qty * OD.unitprice * (1 - OD.discount)) AS NUMERIC(12, 2)) AS totalval
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
LEFT OUTER JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid
GROUP BY C.custid
ORDER BY C.custid; このクエリは、Customers、Orders、およびOrderDetailsを結合し、custidごとに行をグループ化し、注文数、総運賃、顧客ごとの総価値などの集計を計算することになっています。このクエリは次の出力を生成します:
custid numorders totalfreight totalval ------- ---------- ------------- --------- 1 12 419.60 4273.00 2 10 306.59 1402.95 3 17 667.29 7023.98 4 30 1447.14 13390.65 5 52 4835.18 24927.58 ... 87 37 2611.93 15648.70 88 19 546.96 6068.20 89 40 4017.32 27363.61 90 17 262.16 3161.35 91 16 461.53 3531.95
ここでバグを見つけることができますか?
OrderヘッダーはOrdersテーブルに保存され、それぞれの注文行はOrderDetailsテーブルに保存されます。オーダーヘッダーをそれぞれのオーダーラインと結合すると、ラインごとの結合の結果でヘッダーが繰り返されます。その結果、COUNT(O.orderid)集計は、注文の数ではなく、注文の行の数を誤って反映します。同様に、SUM(O.freight)は、注文ごとに複数回、つまり注文内の注文明細の数と同じ数の貨物を誤って考慮します。このクエリでの唯一の正しい集計計算は、注文明細の属性に適用されるため、合計値の計算に使用されるものです:SUM(OD.qty * OD.unitprice *(1 – OD.discount)。
正しい注文数を取得するには、COUNT(DISTINCT O.orderid)という個別の数の集計を使用するだけで十分です。同じ修正を総貨物の計算に適用できると思うかもしれませんが、これは新しいバグを導入するだけです。注文ヘッダーのメジャーに個別の集計が適用されたクエリは次のとおりです。
SELECT C.custid, COUNT(DISTINCT O.orderid) AS numorders, SUM(DISTINCT O.freight) AS totalfreight,
CAST(SUM(OD.qty * OD.unitprice * (1 - OD.discount)) AS NUMERIC(12, 2)) AS totalval
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid
LEFT OUTER JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid
GROUP BY C.custid
ORDER BY C.custid; このクエリは次の出力を生成します:
custid numorders totalfreight totalval ------- ---------- ------------- --------- 1 6 225.58 4273.00 2 4 97.42 1402.95 3 7 268.52 7023.98 4 13 448.23 13390.65 ***** 5 18 1559.52 24927.58 ... 87 15 822.48 15648.70 88 9 194.71 6068.20 89 14 1353.06 27363.61 90 7 87.66 3161.35 ***** 91 7 175.74 3531.95
注文数は正しくなりましたが、合計貨物額は正しくありません。新しいバグを見つけることができますか?
新しいバグは、同じ顧客が複数の注文がまったく同じ運賃値を持っているケースが少なくとも1つある場合にのみ現れるため、よりわかりにくいです。このような場合、現在、運賃は顧客ごとに1回だけ考慮されており、注文ごとに1回は考慮されていません。
次のクエリ(SQL Server 2017以降が必要)を使用して、同じ顧客の不明確な運賃値を特定します。
WITH C AS
(
SELECT custid, freight,
STRING_AGG(CAST(orderid AS VARCHAR(MAX)), ', ')
WITHIN GROUP(ORDER BY orderid) AS orders
FROM Sales.Orders
GROUP BY custid, freight
HAVING COUNT(*) > 1
)
SELECT custid,
STRING_AGG(CONCAT('(freight: ', freight, ', orders: ', orders, ')'), ', ') as duplicates
FROM C
GROUP BY custid; このクエリは次の出力を生成します:
custid duplicates ------- --------------------------------------- 4 (freight: 23.72, orders: 10743, 10953) 90 (freight: 0.75, orders: 10615, 11005)
これらの調査結果から、バグのあるクエリで顧客4と90の合計貨物値が正しく報告されていないことがわかります。残りの顧客の貨物値はたまたま一意であったため、クエリで正しい合計貨物値が報告されました。
バグを修正するには、次のように、テーブル式を使用して、注文の集計と注文行の計算を異なるステップに分離する必要があります。
WITH O AS
(
SELECT custid, COUNT(orderid) AS numorders, SUM(freight) AS totalfreight
FROM Sales.Orders
GROUP BY custid
),
OD AS
(
SELECT O.custid,
CAST(SUM(OD.qty * OD.unitprice * (1 - OD.discount)) AS NUMERIC(12, 2)) AS totalval
FROM Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS OD
ON O.orderid = OD.orderid
GROUP BY O.custid
)
SELECT C.custid, O.numorders, O.totalfreight, OD.totalval
FROM Sales.Customers AS C
LEFT OUTER JOIN O
ON C.custid = O.custid
LEFT OUTER JOIN OD
ON C.custid = OD.custid
ORDER BY C.custid; このクエリは次の出力を生成します:
custid numorders totalfreight totalval ------- ---------- ------------- --------- 1 6 225.58 4273.00 2 4 97.42 1402.95 3 7 268.52 7023.98 4 13 471.95 13390.65 ***** 5 18 1559.52 24927.58 ... 87 15 822.48 15648.70 88 9 194.71 6068.20 89 14 1353.06 27363.61 90 7 88.41 3161.35 ***** 91 7 175.74 3531.95
顧客4と90の合計運賃値が高くなっていることを確認します。これらは正しい番号です。
ここでのベストプラクティスは、データを結合および集約するときに注意することです。複数のテーブルを結合し、結合のエッジまたはリーフテーブルではないテーブルからメジャーに集計を適用する場合は、このような場合に注意する必要があります。このような場合、通常、テーブル式内で集計計算を適用してから、テーブル式を結合する必要があります。
そのため、ダブルディッピングアグリゲートのバグが修正されました。ただし、このクエリには別のバグが存在する可能性があります。見つけられますか?このような潜在的なバグの詳細については、後で「OUTER-INNER参加の矛盾」で取り上げる4番目のケースとして説明します。
どこでも矛盾
3番目のバグは、ON句とWHERE句が果たすべき役割を混乱させた結果です。例として、2019年2月12日以降に行った顧客と注文を照合するタスクが与えられたが、それ以降に注文しなかった顧客も出力に含めるとします。次のクエリ(クエリ3と呼びます)を使用してタスクを解決しようとします:
SELECT C.custid, C.companyname, O.orderid, O.orderdate
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
WHERE O.orderdate >= '20190212'; 内部結合を使用する場合、ONとWHEREの両方が同じフィルタリングの役割を果たします。したがって、これらの句の間で述語をどのように編成するかは重要ではありません。ただし、この場合のように外部結合を使用する場合、これらの句の意味は異なります。
ON句は一致する役割を果たします。つまり、結合の保存された側(この場合はCustomers)からのすべての行が返されます。 ON述語に基づいて一致するものは、それらの一致に接続され、その結果、一致ごとに繰り返されます。一致するものがないものは、保存されていない側の属性のプレースホルダーとしてNULLで返されます。
逆に、WHERE句は、常に、より単純なフィルタリングの役割を果たします。これは、フィルタリング述部がtrueと評価された行が返され、残りはすべて破棄されることを意味します。その結果、結合の保存された側の一部の行を完全に削除できます。
外部結合の保存されていない側(この場合は順序)からの属性は、外部行(不一致)に対してNULLとしてマークされることに注意してください。結合の保存されていない側からの要素を含むフィルターを適用するときはいつでも、フィルター述語はすべての外側の行に対して不明と評価され、結果としてそれらが削除されます。これは、SQLが従う3値述語論理と一致しています。事実上、結合は結果として内部結合になります。このルールの1つの例外は、非保存側から要素内のNULLを具体的に探して、不一致を識別する場合です(要素はNULLです)。
バグのあるクエリは次の出力を生成します:
custid companyname orderid orderdate ------- --------------- -------- ---------- 1 Customer NRZBB 11011 2019-04-09 1 Customer NRZBB 10952 2019-03-16 2 Customer MLTDN 10926 2019-03-04 4 Customer HFBZG 11016 2019-04-10 4 Customer HFBZG 10953 2019-03-16 4 Customer HFBZG 10920 2019-03-03 5 Customer HGVLZ 10924 2019-03-04 6 Customer XHXJV 11058 2019-04-29 6 Customer XHXJV 10956 2019-03-17 8 Customer QUHWH 10970 2019-03-24 ... 20 Customer THHDP 10979 2019-03-26 20 Customer THHDP 10968 2019-03-23 20 Customer THHDP 10895 2019-02-18 24 Customer CYZTN 11050 2019-04-27 24 Customer CYZTN 11001 2019-04-06 24 Customer CYZTN 10993 2019-04-01 ... (195 rows affected)
目的の出力は、2019年2月12日以降に行われた注文を表す195行と、それ以降に注文されていない顧客を表す18行を含む213行であると想定されています。ご覧のとおり、実際の出力には、指定された日付以降に注文していない顧客は含まれていません。
このクエリの計画を図3に示します。
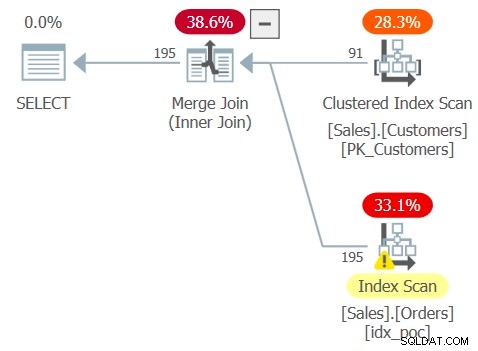 図3:クエリ3の計画
図3:クエリ3の計画
オプティマイザが矛盾を検出し、外部結合を内部結合に内部変換したことを確認します。確認するのは良いことですが、同時に、クエリにバグがあることを明確に示しています。
次のように、WHERE句に述語OR O.orderidISNULLを追加してバグを修正しようとした場合があります。
SELECT C.custid, C.companyname, O.orderid, O.orderdate
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
WHERE O.orderdate >= '20190212'
OR O.orderid IS NULL; 一致する唯一の述語は、両側の顧客IDを比較する述語です。したがって、結合自体は、一般的に注文した顧客と、一致する注文、および注文属性にNULLが含まれる、まったく注文しなかった顧客を返します。次に、フィルタリング述語は、指定された日付以降に注文した顧客と、まったく注文していない顧客(顧客22および57)をフィルタリングします。一部の注文を行ったが、指定された日付以降ではない顧客がクエリに含まれていません!
このクエリは次の出力を生成します:
custid companyname orderid orderdate ------- --------------- -------- ---------- 1 Customer NRZBB 11011 2019-04-09 1 Customer NRZBB 10952 2019-03-16 2 Customer MLTDN 10926 2019-03-04 4 Customer HFBZG 11016 2019-04-10 4 Customer HFBZG 10953 2019-03-16 4 Customer HFBZG 10920 2019-03-03 5 Customer HGVLZ 10924 2019-03-04 6 Customer XHXJV 11058 2019-04-29 6 Customer XHXJV 10956 2019-03-17 8 Customer QUHWH 10970 2019-03-24 ... 20 Customer THHDP 10979 2019-03-26 20 Customer THHDP 10968 2019-03-23 20 Customer THHDP 10895 2019-02-18 22 Customer DTDMN NULL NULL 24 Customer CYZTN 11050 2019-04-27 24 Customer CYZTN 11001 2019-04-06 24 Customer CYZTN 10993 2019-04-01 ... (197 rows affected)
バグを正しく修正するには、両側の顧客IDを比較する述語と、一致する述語と見なされる注文日に対する述語の両方が必要です。これを実現するには、次のように両方をON句で指定する必要があります(このクエリ4と呼びます):
SELECT C.custid, C.companyname, O.orderid, O.orderdate
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
AND O.orderdate >= '20190212'; このクエリは次の出力を生成します:
custid companyname orderid orderdate ------- --------------- -------- ---------- 1 Customer NRZBB 11011 2019-04-09 1 Customer NRZBB 10952 2019-03-16 2 Customer MLTDN 10926 2019-03-04 3 Customer KBUDE NULL NULL 4 Customer HFBZG 11016 2019-04-10 4 Customer HFBZG 10953 2019-03-16 4 Customer HFBZG 10920 2019-03-03 5 Customer HGVLZ 10924 2019-03-04 6 Customer XHXJV 11058 2019-04-29 6 Customer XHXJV 10956 2019-03-17 7 Customer QXVLA NULL NULL 8 Customer QUHWH 10970 2019-03-24 ... 20 Customer THHDP 10979 2019-03-26 20 Customer THHDP 10968 2019-03-23 20 Customer THHDP 10895 2019-02-18 21 Customer KIDPX NULL NULL 22 Customer DTDMN NULL NULL 23 Customer WVFAF NULL NULL 24 Customer CYZTN 11050 2019-04-27 24 Customer CYZTN 11001 2019-04-06 24 Customer CYZTN 10993 2019-04-01 ... (213 rows affected)
このクエリの計画を図4に示します。
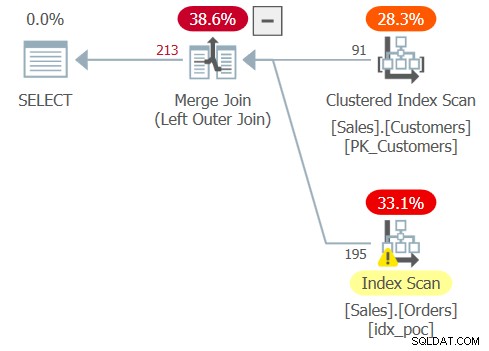 図4:クエリ4の計画
図4:クエリ4の計画
ご覧のとおり、今回はオプティマイザーが結合を外部結合として処理しました。
これは、説明のために使用した非常に単純なクエリです。はるかに複雑で複雑なクエリでは、経験豊富な開発者でさえ、述語がON句に属しているのかWHERE句に属しているのかを判断するのに苦労する可能性があります。私にとって物事を簡単にするのは、述語が一致する述語なのか、フィルタリングする述語なのかを自問することです。前者の場合、ON句に属します。後者の場合、WHERE句に属します。
OUTER-INNERは矛盾に参加します
4番目で最後のバグは、ある意味で3番目のバグのバリエーションです。これは通常、結合タイプを混在させる複数結合クエリで発生します。例として、Customers、Orders、OrderDetails、Products、Suppliersの各テーブルを結合して、共同で活動した顧客とサプライヤのペアを特定する必要があるとします。次のクエリを記述します(クエリ5と呼びます):
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
INNER JOIN Sales.Orders AS O
ON O.custid = C.custid
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
INNER JOIN Production.Products AS P
ON P.productid = OD.productid
INNER JOIN Production.Suppliers AS S
ON S.supplierid = P.supplierid; このクエリは、1,236行の次の出力を生成します。
custid customer supplierid supplier ------- --------------- ----------- --------------- 1 Customer NRZBB 1 Supplier SWRXU 1 Customer NRZBB 3 Supplier STUAZ 1 Customer NRZBB 7 Supplier GQRCV ... 21 Customer KIDPX 24 Supplier JNNES 21 Customer KIDPX 25 Supplier ERVYZ 21 Customer KIDPX 28 Supplier OAVQT 23 Customer WVFAF 3 Supplier STUAZ 23 Customer WVFAF 7 Supplier GQRCV 23 Customer WVFAF 8 Supplier BWGYE ... 56 Customer QNIVZ 26 Supplier ZWZDM 56 Customer QNIVZ 28 Supplier OAVQT 56 Customer QNIVZ 29 Supplier OGLRK 58 Customer AHXHT 1 Supplier SWRXU 58 Customer AHXHT 5 Supplier EQPNC 58 Customer AHXHT 6 Supplier QWUSF ... (1236 rows affected)
このクエリの計画を図5に示します。
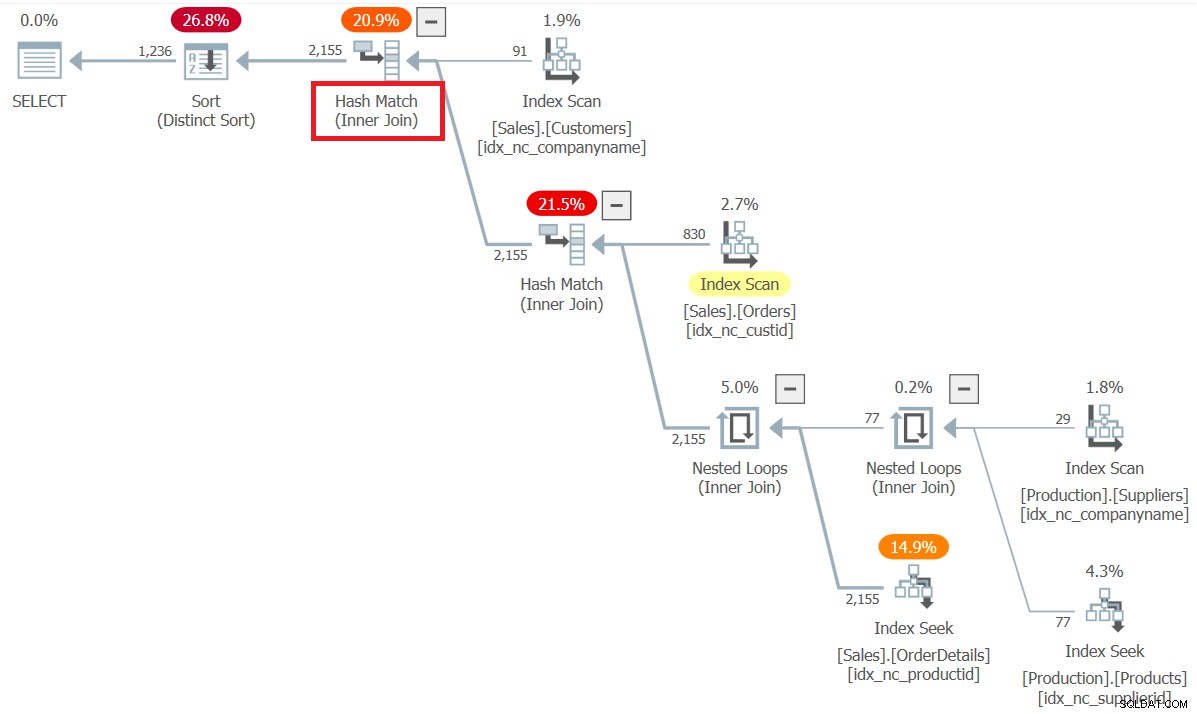 図5:クエリ5の計画
図5:クエリ5の計画
プラン内のすべての結合は、期待どおりに内部結合として処理されます。
プランでは、オプティマイザーが結合順序の最適化を適用したことも確認できます。内部結合を使用すると、オプティマイザは、元のクエリの意味を維持しながら、結合の物理的な順序を好きなように再配置できることを認識しているため、柔軟性が高くなります。ここでは、コストベースの最適化により、join(Customers、join(Orders、join(join(Suppliers、Products)、OrderDetails))))という順序になりました。
注文していない顧客が含まれるようにクエリを変更する必要があるとします。現在、そのような顧客が2つ(ID 22と57)あるため、目的の結果は1,238行になるはずです。このような場合の一般的なバグは、CustomersとOrdersの間の内部結合を左外部結合に変更し、残りのすべての結合を内部結合のままにすることです。たとえば、次のようになります。
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
INNER JOIN Production.Products AS P
ON P.productid = OD.productid
INNER JOIN Production.Suppliers AS S
ON S.supplierid = P.supplierid; 続いて左外部結合の後に内部または右外部結合が続き、結合述部が左外部結合の保存されていない側からの何かを他の要素と比較する場合、述部の結果は論理値が不明であり、元の外部行は破棄されます。左外側の結合は事実上内側の結合になります。
その結果、このクエリはクエリ5と同じ出力を生成し、1,236行のみを返します。また、ここでオプティマイザーは矛盾を検出し、外部結合を内部結合に変換して、図5で前に示したのと同じ計画を生成します。
バグを修正する一般的な試みは、次のように、すべての結合を左外部結合にすることです。
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON O.custid = C.custid
LEFT OUTER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
LEFT OUTER JOIN Production.Products AS P
ON P.productid = OD.productid
LEFT OUTER JOIN Production.Suppliers AS S
ON S.supplierid = P.supplierid; このクエリは、顧客22と57を含む次の出力を生成します。
custid customer supplierid supplier ------- --------------- ----------- --------------- 1 Customer NRZBB 1 Supplier SWRXU 1 Customer NRZBB 3 Supplier STUAZ 1 Customer NRZBB 7 Supplier GQRCV ... 21 Customer KIDPX 24 Supplier JNNES 21 Customer KIDPX 25 Supplier ERVYZ 21 Customer KIDPX 28 Supplier OAVQT 22 Customer DTDMN NULL NULL 23 Customer WVFAF 3 Supplier STUAZ 23 Customer WVFAF 7 Supplier GQRCV 23 Customer WVFAF 8 Supplier BWGYE ... 56 Customer QNIVZ 26 Supplier ZWZDM 56 Customer QNIVZ 28 Supplier OAVQT 56 Customer QNIVZ 29 Supplier OGLRK 57 Customer WVAXS NULL NULL 58 Customer AHXHT 1 Supplier SWRXU 58 Customer AHXHT 5 Supplier EQPNC 58 Customer AHXHT 6 Supplier QWUSF ... (1238 rows affected)
ただし、このソリューションには2つの問題があります。顧客以外に、クエリ内の別のテーブルに行があり、後続のテーブルに一致する行がない可能性があり、そのような場合、それらの外側の行を保持したくないとします。たとえば、ご使用の環境で注文のヘッダーを作成し、後で注文行を入力することが許可されている場合はどうでしょうか。このような場合、クエリがそのような空の注文ヘッダーを返すことは想定されていないとします。それでも、クエリは注文なしで顧客を返すことになっています。 OrdersとOrderDetailsの間の結合は左外側の結合であるため、このクエリは、そのような空の注文を返しますが、そうではありません。
もう1つの問題は、外部結合を使用する場合、結合順序の最適化の一部として探索できる再配置に関して、オプティマイザーにより多くの制限を課すことです。オプティマイザーは、結合A LEFT OUTERJOINBをBRIGHTOUTER JOIN Aに再配置できますが、探索できる再配置はこれだけです。内部結合を使用すると、オプティマイザは、サイドを反転するだけでなく、テーブルを並べ替えることもできます。たとえば、join(join(join(join(A、B)、C)、D)、E))))をjoin(A、図5で前述したように、join(B、join(join(E、D)、C)))。
あなたがそれについて考えるならば、あなたが本当に求めているのは、残りのテーブル間の内部結合の結果で顧客を左結合することです。明らかに、これはテーブル式で実現できます。ただし、T-SQLは別のトリックをサポートしています。論理結合の順序を実際に決定するのは、FROM句のテーブルの順序ではなく、ON句の順序です。ただし、クエリを有効にするには、結合する2つのユニットのすぐ下に各ON句を表示する必要があります。したがって、顧客と残りの部分の結合を最後と見なすには、次のように、顧客と残りの部分を接続するON句を移動して最後に表示するだけです。
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
-- move from here -----------------------
INNER JOIN Sales.OrderDetails AS OD --
ON OD.orderid = O.orderid --
INNER JOIN Production.Products AS P --
ON P.productid = OD.productid --
INNER JOIN Production.Suppliers AS S --
ON S.supplierid = P.supplierid --
ON O.custid = C.custid; -- <-- to here -- ここで、論理的な結合の順序は、leftjoin(Customers、join(join(join(Orders、OrderDetails)、Products)、Suppliers))です。今回は、注文していない顧客は保持しますが、一致する注文明細がない注文ヘッダーは保持しません。また、Orders、OrderDetails、Products、Suppliers間の内部結合でオプティマイザーの完全な結合順序の柔軟性を許可します。
この構文の1つの欠点は、読みやすさです。幸いなことに、これはかっこを使用することで簡単に修正できます(このクエリ6と呼びます):
SELECT DISTINCT
C.custid, C.companyname AS customer,
S.supplierid, S.companyname AS supplier
FROM Sales.Customers AS C
LEFT OUTER JOIN
( Sales.Orders AS O
INNER JOIN Sales.OrderDetails AS OD
ON OD.orderid = O.orderid
INNER JOIN Production.Products AS P
ON P.productid = OD.productid
INNER JOIN Production.Suppliers AS S
ON S.supplierid = P.supplierid )
ON O.custid = C.custid; ここでの括弧の使用を派生テーブルと混同しないでください。これは派生テーブルではなく、わかりやすくするために、テーブル演算子の一部を独自のユニットに分離するための単なる方法です。言語にはこれらの括弧は実際には必要ありませんが、読みやすくするために強くお勧めします。
このクエリの計画を図6に示します。
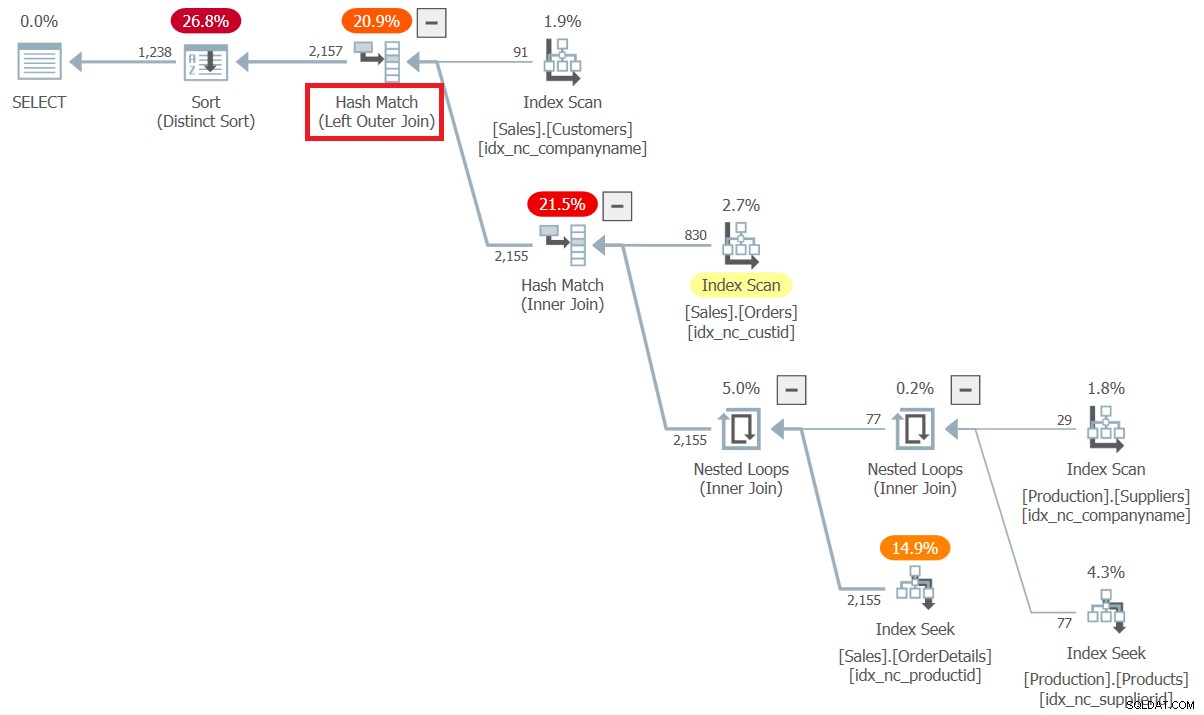 図6:クエリ6の計画
図6:クエリ6の計画
今回は、Customersと残りの結合が外部結合として処理され、オプティマイザーが結合順序の最適化を適用したことを確認してください。
結論
この記事では、結合に関連する4つの古典的なバグについて説明しました。外部結合を使用する場合、COUNT(*)集計を計算すると、通常、バグが発生します。 The best practice is to apply the aggregate to a non-NULLable column from the nonpreserved side of the join.
When joining multiple tables and involving aggregate calculations, if you apply the aggregates to a nonleaf table in the joins, it’s usually a bug resulting in double-dipping aggregates. The best practice is then to apply the aggregates within table expressions and joining the table expressions.
It’s common to confuse the meanings of the ON and WHERE clauses. With inner joins, they’re both filters, so it doesn’t really matter how you organize your predicates within these clauses. However, with outer joins the ON clause serves a matching role whereas the WHERE clause serves a filtering role. Understanding this helps you figure out how to organize your predicates within these clauses.
In multi-join queries, a left outer join that is subsequently followed by an inner join, or a right outer join, where you compare an element from the nonpreserved side of the join with others (other than the IS NULL test), the outer rows of the left outer join are discarded. To avoid this bug, you want to apply the left outer join last, and this can be achieved by shifting the ON clause that connects the preserved side of this join with the rest to appear last. Use parentheses for clarity even though they are not required.