ANY 集計は、TransactSQLで直接記述できるものではありません。これは、クエリオプティマイザと実行エンジンによって使用される内部のみの機能です。
私は個人的にANYが大好きです 総計なので、それがかなり根本的な方法で壊れていることを知るのは少し残念でした。ここで言及している「壊れた」の特定のフレーバーは、間違った結果の多様性です。
この投稿では、ANYが存在する2つの特定の場所を見ていきます。 集計は一般的に表示され、間違った結果の問題を示し、必要に応じて回避策を提案します。
ANYの背景について 集計については、以前の投稿「文書化されていないクエリプラン:任意の集計」を参照してください。
1。グループクエリごとに1行
これは、非常によく知られているソリューションを使用した、最も一般的な日常のクエリ要件の1つである必要があります。おそらく、この種のクエリは、実際には考えずに、パターンに従って自動的に毎日作成します。
アイデアは、ROW_NUMBERを使用して行の入力セットに番号を付けることです。 1つまたは複数のグループ化列によって分割されたウィンドウ関数。これは、共通テーブル式にラップされています。 または派生テーブル 、および計算された行番号が1に等しい行にフィルターされます。 ROW_NUMBER以降 グループごとに1つずつ再起動します。これにより、グループごとに必要な1行が得られます。
その一般的なパターンに問題はありません。 ANYの対象となるグループクエリごとの1行のタイプ 集約問題は、どの特定の行が選択されているかを気にしない問題です。 各グループから。
その場合、必須のORDER BYでどの列を使用する必要があるかが明確ではありません。 ROW_NUMBERの句 ウィンドウ関数。結局のところ、私たちは明示的に気にしない どの行が選択されているか。一般的なアプローチの1つは、PARTITION BYを再利用することです。 ORDER BYの列 句。ここで問題が発生する可能性があります。
おもちゃのデータセットを使用した例を見てみましょう:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
要件は、各グループからデータの完全な1行を返すことです。ここで、グループメンバーシップは、列c1の値によって定義されます。 。

ROW_NUMBERに続く パターンの場合、次のようなクエリを作成できます(ORDER BYに注意してください) ROW_NUMBERの句 ウィンドウ関数はPARTITION BYと一致します 条項):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; 示されているように、このクエリは正常に実行され、正しい結果が得られます。結果は技術的に非決定論的です SQL Serverは、各グループの行のいずれか1つを有効に返すことができるためです。それでも、このクエリを自分で実行すると、私と同じ結果が表示される可能性が非常に高くなります。
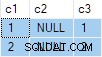
実行プランは、使用するSQL Serverのバージョンに依存し、データベースの互換性レベルには依存しません。
SQL Server 2014以前では、計画は次のとおりです。

SQL Server 2016以降の場合、次のように表示されます。

どちらの計画も安全ですが、理由は異なります。 個別の並べ替え プランにはANYが含まれています 集計しますが、個別の並べ替え オペレーターの実装はバグを明らかにしません。
より複雑なSQLServer2016+プランでは、ANYは使用されません。 まったく集約します。 並べ替え 行番号付け操作に必要な順序に行を配置します。 セグメント オペレーターは、新しい各グループの開始時にフラグを設定します。 シーケンスプロジェクト 行番号を計算します。最後に、フィルター 演算子は、計算された行番号が1の行のみを渡します。
このデータセットで誤った結果を得るには、SQL Server 2014以前、およびANYを使用する必要があります。 アグリゲートはStreamAggregateに実装する必要があります または熱心なハッシュ骨材 演算子( Flow Distinct Hash Match Aggregate バグは発生しません)。
オプティマイザにStreamAggregateを選択するように促す1つの方法 個別の並べ替えの代わりに クラスタ化されたインデックスを追加して、列c1による順序付けを提供します :
CREATE CLUSTERED INDEX c ON #Data (c1);
その変更後、実行プランは次のようになります。

ANY 集計はプロパティに表示されます Stream Aggregateのときのウィンドウ 演算子が選択されています:

クエリの結果は次のとおりです。
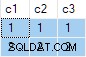
これは間違っています 。 SQL Serverは、存在しない行を返しました。 ソースデータで。 c2 = 1のソース行はありません およびc3 = 1 例えば。注意点として、ソースデータは次のとおりです。
実行プランは誤ってseparateを計算します ANY c2の集計 およびc3 列、nullを無視します。各集計は独立して 最初のnull以外を返します 遭遇する値、c2の値が得られる結果 およびc3 異なるソース行から 。これは、元のSQLクエリ仕様が要求したものではありません。
同じ間違った結果がありまたはなしで生成される可能性があります OPTION (HASH GROUP)を追加してクラスター化されたインデックス 熱心なハッシュ骨材を使用して計画を作成するためのヒント Stream Aggregateの代わりに 。
この問題は、複数のANYの場合にのみ発生する可能性があります 集計が存在し、集計データにnullが含まれています。前述のように、この問題は Stream Aggregateにのみ影響します と熱心なハッシュ骨材 演算子; 個別の並べ替え およびFlowDistinct 影響を受けません。
SQL Server 2016以降では、複数のANYの導入を回避するように努めています。 ソース列がnull許容の場合、グループごとの任意の1行の行番号付けクエリパターンの集計。これが発生すると、実行プランにはセグメントが含まれます。 、シーケンスプロジェクト 、およびフィルタ 集合体の代わりに演算子。 ANYがないため、このプランの形状は常に安全です。 集計が使用されます。
SQLServer2016+でのバグの再現
SQL Serverオプティマイザーは、列が元々NOT NULLに制約されていた場合の検出に完全ではありません。 データ操作によってnullの中間値が生成される可能性があります。
これを再現するために、すべての列がNOT NULLとして宣言されているテーブルから始めます。 :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
このデータセットからさまざまな方法でnullを生成できますが、そのほとんどはオプティマイザーが正常に検出できるため、ANYの導入は避けてください。 最適化中に集計されます。
レーダーの下に滑り込むヌルを追加する1つの方法を以下に示します。
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; そのクエリは次の出力を生成します:
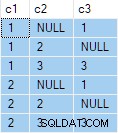
次のステップは、そのクエリ仕様を標準の「グループごとに任意の1行」クエリのソースデータとして使用することです。
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; 任意のバージョン SQL Serverの場合、次の計画が作成されます。
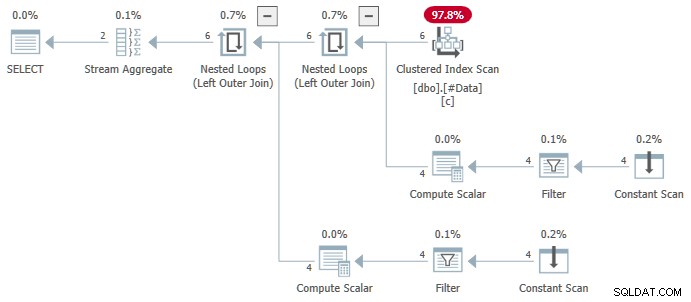
Stream Aggregate 複数のANYが含まれています 集計すると、結果は間違っています 。返された行はどちらもソースデータセットに表示されません:
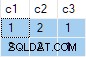
db<>フィドルオンラインデモ
このバグが修正されるまでの唯一の完全に信頼できる回避策は、ROW_NUMBERのパターンを回避することです。 ORDER BYに同じ列があります PARTITION BYにある句 条項。
気にしないとき 各グループから1行が選択されますが、ORDER BYが残念です 節はまったく必要です。この問題を回避する1つの方法は、ORDER BY @@SPIDのような実行時定数を使用することです。 ウィンドウ関数で。
2。非決定論的更新
複数のANYの問題 null許容入力の集計は、グループクエリパターンごとに1行に制限されません。クエリオプティマイザは、内部のANYを導入できます さまざまな状況で集計します。それらのケースの1つは、非決定論的な更新です。
非決定論的 updateは、ステートメントが各ターゲット行が最大で1回更新されることを保証しない場合です。つまり、少なくとも1つのターゲット行に対して複数のソース行があります。ドキュメントはこれについて明示的に警告しています:
UPDATEステートメントの結果は、ステートメントに、更新される列の出現ごとに1つの値しか使用できないように指定されていないFROM句が含まれている場合、未定義になります。 UPDATEステートメントが決定論的でない場合です。
非決定論的更新を処理するために、オプティマイザーは行をキー(インデックスまたはRID)でグループ化し、ANYを適用します。 残りの列に集約します。基本的な考え方は、複数の候補から1つの行を選択し、その行の値を使用して更新を実行することです。以前のROW_NUMBERとの明らかな類似点があります 問題があるため、誤った更新を簡単に示すことができるのは当然のことです。
前号とは異なり、SQLServerは現在特別な手順はありません 複数のANYを避けるため 非決定論的更新を実行するときに、NULL可能列に集約します。したがって、以下はすべてのSQLServerバージョンに関連しています。 、SQL Server 2019CTP3.0を含む。
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>フィドルオンラインデモ
論理的には、この更新は常にエラーを生成するはずです。ターゲットテーブルはどの列にもnullを許可しません。ソーステーブルから一致する行が選択された場合は、列c2を更新しようとします またはc3 ヌルにする必要 発生します。
残念ながら、更新は成功し、ターゲットテーブルの最終状態は提供されたデータと一致しません:
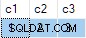
これをバグとして報告しました。回避策は、非決定論的なUPDATEを記述しないようにすることです。 ステートメントなので、ANY あいまいさを解決するために集計は必要ありません。
前述のように、SQLServerはANYを導入できます ここに示した2つの例よりも多くの状況で集計されます。集計列にnullが含まれているときにこれが発生すると、間違った結果が生じる可能性があります。