バッチモードのデータは正規化されていることを簡単に説明しました 前回の記事で、SQLServerのバッチモードビットマップ。バッチ内のすべてのデータは、基になるデータ型に関係なく、この特定の正規化された形式で8バイトの値で表されます。
そのステートメントは、間違いなくいくつかの疑問を提起します。特に、8バイトをはるかに超える長さのデータをその方法で格納する方法については特にそうです。この記事では、バッチデータの正規化表現について説明し、すべての8バイトデータ型が64ビット内に収まらない理由を説明し、これらすべてがバッチモードのパフォーマンスにどのように影響するかの例を示します。
実行プランに重要な違いをもたらすバッチデータ形式を示す例から始めます。ここに示す結果を再現するには、SQL Server 2016(またはそれ以降)とDeveloper Edition(または同等のもの)が必要です。
最初に必要なのは、 bigintのテーブルです。 1から102,400までの数字。これらの数値は、まもなく列ストアテーブルにデータを入力するために使用されます(行数は、単一の圧縮セグメントを取得するために必要な最小数です)。
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); 次のスクリプトは、数値テーブルを使用して、特定の値でオフセットされた同じ数値を含む別のテーブルを作成します。このテーブルは、プライマリストレージにcolumnstoreを使用して、後でバッチモードの実行を生成します。
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); 新しい列ストアテーブルに対して次のテストクエリを実行します。
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SUM内の追加 オーバーフローを回避することです。 WHEREはスキップできます SQL Server 2017を実行している場合は、(些細な計画を回避するための)句。
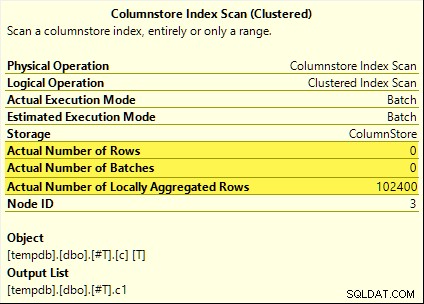
これらのクエリはすべて、集約プッシュダウンの恩恵を受けます。集計は、 Columnstore Index Scanで計算されます。 バッチモードではなくHashAggregate オペレーター。実行後の計画では、スキャンによって放出された行がゼロであることが示されています。 102,400行すべてが「ローカルに集約」されました。
SUM 例として計画を以下に示します:

次に、ドロップしてから、オフセットを1つ減らして列ストアテストテーブルを再作成します。
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); 以前とまったく同じ集計プッシュダウンテストクエリを実行します。
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
今回は、 COUNT_BIGのみ アグリゲートはアグリゲートプッシュダウンを実現します(SQL Server 2017のみ)。 MAX およびSUM 集合体はそうではありません。これが新しいSUMです 最初のテストのものとの比較を計画します:

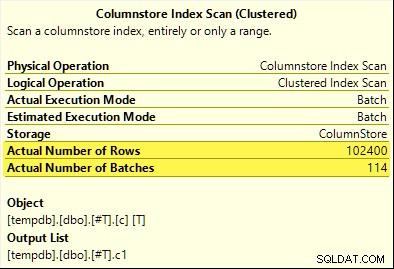
すべての102,400行(114バッチ)は、 Columnstore Index Scanによって発行されます。 、 Compute Scalarによって処理されます 、 Hash Aggregateに送信されます 。
なぜ違いがあるのですか?列ストアテーブルに格納されている数値の範囲を1つオフセットするだけでした!
冒頭で、すべての8バイトデータ型が64ビットに収まるわけではないことを説明しました。この事実は重要です 多くの列ストアおよびバッチモードのパフォーマンス最適化は、64ビットサイズのデータでのみ機能するためです。集約プッシュダウンはそれらの1つです。データが64ビットに収まる場合にのみ最適に(またはまったく)機能するパフォーマンス機能は他にもたくさんあります(すべてが文書化されているわけではありません)。
特定の例では、集約プッシュダウンは無効です。 列ストアセグメントの場合、1つでも 64ビットに収まらないデータ値。 SQL Serverは、すべてのデータをチェックすることなく、各セグメントに関連付けられた最小値と最大値のメタデータからこれを判断できます。各セグメントは個別に評価されます。
集計プッシュダウンは、 COUNT_BIGでも引き続き機能します 2番目のテストでのみ集計します。これは、SQL Server 2017のある時点で追加された最適化です(私のテストはCU16で実行されました)。行のみをカウントし、特定のデータ値に対して何も実行しない場合は、集約プッシュダウンを無効にしないのが論理的です。この改善に関するドキュメントは見つかりませんでしたが、最近ではそれほど珍しいことではありません。
ちなみに、SQL Server 2017 CU16では、以前はサポートされていなかったデータ型 realの集約プッシュダウンが有効になっていることに気付きました。 、 float 、 datetimeoffset 、および数値 18を超える精度—データが64ビットに収まる場合。これも執筆時点では文書化されていません。
わかりました、でもなぜですか?
あなたは非常に合理的な質問をしているかもしれません:なぜ1セットの bigint テスト値は明らかに64ビットに収まりますが、他の値は収まりませんか?
理由がNULLに関連していると推測した場合 、自分にダニを与えます。テストテーブルの列がNOTNULLとして定義されている場合でも 、SQLServerはbigintに同じ正規化されたデータレイアウトを使用します データがnullを許可するかどうか。これにはいくつかの理由があり、少しずつ開梱します。
いくつかの観察から始めましょう:
- バッチ内のすべての列値は、基になるデータ型に関係なく、正確に8バイト(64ビット)で格納されます。この固定サイズのレイアウトにより、すべてがより簡単かつ迅速になります。バッチモードの実行は速度がすべてです。
- バッチのサイズは64KBで、投影される列の数に応じて64〜900行が含まれます。列のデータサイズが64ビットに固定されていることを考えると、これは理にかなっています。列が多いほど、64KBの各バッチに収まる行が少なくなります。
- 原則として、すべてのSQLServerデータ型が64ビットに収まるわけではありません。長い文字列(一例を挙げると)は、単一の64ビットエントリは言うまでもなく、64KBバッチ全体(許可されている場合)にさえ収まらない可能性があります。
SQL Serverは、8バイトの参照を格納することにより、この最後の問題を解決します。 64ビットより大きいデータに。 「大きな」データ値は、メモリの他の場所に保存されます。この配置を「オフロー」または「アウトオブバッチ」ストレージと呼ぶ場合があります。内部的には、詳細データと呼ばれます 。
現在、null許容の場合、8バイトのデータ型は64ビットに収まりません。 bigint NULLを取る 例えば 。 null以外のデータ範囲では、64ビット全体が必要になる場合がありますが、nullかどうかを示すために別のビットが必要です。
これらの課題に対する創造的かつ効率的な解決策は、最下位ビットを予約することです。 フラグとしての64ビット値の(LSB)。フラグはバッチ内を示します LSBがクリアの場合のデータストレージ (ゼロに設定)。 LSBが設定されている場合 (1つに)、それは2つのことのいずれかを意味する可能性があります:
- 値はnullです。 または
- 値はオフバッチで保存されます(これはディープデータです)。
これらの2つのケースは、残りの63ビットの状態によって区別されます。 すべてゼロの場合 、値は NULLです 。それ以外の場合、「値」は他の場所に保存されている詳細データへのポインタです。
整数として表示する場合、LSBを設定すると、ディープデータへのポインタは常に奇数になります。 数字。ヌルは(奇数)1で表されます(他のすべてのビットはゼロです)。バッチ内データは偶数で表されます LSBがゼロであるため数値。
これはありません つまり、SQLServerはバッチ内に偶数しか格納できません。これは、正規化された表現を意味します 「バッチ内」に格納されている場合、基になる列の値のLSBは常にゼロになります。これはすぐに意味があります。
正規化は、基になるデータ型に応じて、さまざまな方法で実行されます。 bigintの場合 プロセスは次のとおりです。
- データがnullの場合 、値1を保存します(LSBのみが設定されます)。
- 値を63ビットで表現できる場合 、すべてのビットを1桁左にシフトし、LSBをゼロにします。値を整数として見る場合、これは倍増を意味します 値。たとえば、
bigint値1は値2に正規化されます。バイナリでは、7つのすべてゼロのバイトの後に00000010が続きます。 。 LSBがゼロの場合、これはインラインで保存されたデータであることを示します。 SQL Serverが元の値を必要とする場合、64ビット値を1桁右シフトします(LSBフラグを破棄します)。 - 値ができない場合 63ビットで表され、値は詳細データとしてオフバッチで保存されます 。インバッチポインタにはLSBが設定されています(奇数になります)。
bigintかどうかをテストするプロセス 63ビットに収まる値は次のとおりです。
- 生の*
bigintを保存します 64ビットプロセッサレジスタの値r8。 -
r8の2倍の値を格納します レジスターrax。 -
raxのビットをシフトします 右側に1か所。 -
raxの値かどうかをテストします およびr8等しい。
* T-SQLをバイナリ型に変換しても、すべてのデータ型の生の値を確実に決定できるわけではないことに注意してください。 T-SQLの結果のバイト順序が異なる場合があり、メタデータが含まれている場合もあります。 時間 分数秒精度。
手順4のテストに合格すると、値を2倍にして、64ビット以内で半分にすることができます。元の値が保持されます。
このすべての結果は、 bigintの範囲が バッチで保存できる値は削減されます 1ビット単位(LSBが使用できないため)。次のbigintの包括的範囲 値は詳細データとしてオフバッチで保存されます :
- -4,611,686,018,427,387,905から-9,223,372,036,854,775,808
- +4,611,686,018,427,387,904から+9,223,372,036,854,775,807
これらのbigintを受け入れる見返りに 範囲の制限、正規化により、SQL Serverは(ほとんどの) bigintを格納できます 値、null、および詳細なデータ参照バッチ内 。これは、null可能性と深いデータ参照のために別々の構造を持つよりもはるかに単純でスペース効率が良いです。また、SIMDプロセッサ命令を使用したバッチデータの処理がはるかに簡単になります。
SQLServerには正規化が含まれています バッチモード実行でサポートされる各データ型のコード。各ルーチンは、着信バイナリレイアウトを効率的に処理し、必要な場合にのみ詳細データを作成するように最適化されています。正規化すると、常にLSBが予約されてヌルまたはディープデータを示しますが、残りの63ビットのレイアウトはデータ型ごとに異なります。
次のデータ型の正規化されたデータは、常にバッチで保存されます 63ビットを超える必要はないため:
日付-
time(n)–内部でtime(7)に再スケーリングされました -
datetime2(n)–内部でdatetime2(7)に再スケーリングされました 整数-
smallint -
tinyint ビット–tinyintを使用します 実装。-
smalldatetime -
datetime 本物フロート-
smallmoney
次のデータ型は、バッチデータまたは詳細データに保存される場合があります データ値に応じて:
-
bigint–前述のとおり。 お金–bigintと同じ範囲のバッチ ただし、10,000で割った値です。数値/小数–バッチ内の小数点以下18桁以下関係なく 宣言された精度の。たとえば、decimal(38,9)値-999999999.999999999は、8バイト整数-999999999999999999(f21f494c589c0001)として表すことができます。 hex)、これは2倍にして-1999999999999999998(e43e9298b1380002hex)64ビット以内で可逆的に。 SQL Serverは、データ型のスケールから小数点がどこにあるかを認識しています。-
datetimeoffset(n)–ランタイム値の場合はバッチ内datetimeoffset(2)に収まります 関係なく 宣言された分数秒の精度。 タイムスタンプ–内部フォーマットはディスプレイとは異なります。たとえば、タイムスタンプT-SQLから0x000000000099449Aとして表示されます 内部的には9a44990000000000として表されます (16進数)。この値は、2倍(1ビット左シフト)すると64ビットに収まらないため、ディープデータとして格納されます。
以下は常にディープデータとして保存されます(nullを除く) :
一意の識別子-
varbinary(n)–(max)を含む バイナリ-
char / varchar(n)/ nchar / nvarchar(n)/ sysname(max)を含む –これらのタイプは、辞書を使用する場合もあります(利用可能な場合)。 -
text / ntext / image / xml–varbinary(n)を使用します 実装。
明確にするために、すべてのnull バッチモード互換のデータ型は、特別な値「one」としてバッチで保存されます。
64ビットに収まるデータ型と値を使用する場合は、使用可能な列ストアとバッチモードの最適化を最大限に活用することが期待できます。また、メインテキストに記載されているプッシュダウンを集約するための最新の改善など、時間の経過に伴う製品の段階的な改善から利益を得る可能性が最も高くなります。パフォーマンス上の利点のすべてが実行計画に表示されたり、文書化されたりするわけではありません。それでも、違いは非常に重要になる可能性があります。
また、行モードの実行プランオペレーターがバッチモードの親にデータを提供する場合、または非列ストアスキャンがバッチを生成する場合(行ストアのバッチモード)、データが正規化されることにも言及する必要があります。バッチに追加する前に、各列の値に対して適切な正規化ルーチンを呼び出す、非表示の行からバッチへのアダプターがあります。複雑な正規化と深いデータストレージを備えたデータ型を回避すると、ここでもパフォーマンス上のメリットが得られます。