パフォーマンスチューニングの取り組みは、作業中に多くのターンを経ることになる可能性があります。それはすべて、問題として何が現れているか、およびデータが何を示しているかに依存します。ある日、それは特定のクエリまたはクエリのセットに到達します。これは、新しいインデックスまたは既存のインデックスへの変更のいずれかで、インデックスを使用して改善できます。チューニングの私のお気に入りの部分の1つはインデックスの操作です。この投稿について考えていたとき、インデックスのチューニングを「より簡単な」タスクとしてラベル付けしたくなりました…しかし、実際にはそうではありません。
インデックスチューニングは芸術と科学だと思います。オプティマイザーのように考えてみてください。また、テーブルスキーマと、調整しようとしている1つまたは複数のクエリを理解する必要があります。これらは両方ともデータ駆動型であり、したがって科学のカテゴリーに属します。 その他について考えると、アートコンポーネントが機能します。 テーブルのインデックス、およびすべて その他 インデックスの変更によって影響を受ける可能性のあるテーブルを含むクエリ。
ステップ1:クエリを特定し、計画を確認します
インデックスの恩恵を受ける可能性のあるクエリを特定すると、すぐにそのプランを取得します。プランキャッシュまたはクエリストアから実行プランを取得し、SSMSを使用して実行プランと実行時統計(別名実際の実行プラン)を取得することがよくあります。多くの場合、これら2つの計画の形は同じです。しかし、それは保証ではありません。それが私が両方を見たい理由です。
プランには、推奨されるインデックスがない場合、クラスター化されたインデックススキャン(またはクラスター化されたインデックスがない場合はヒープスキャン)がある場合、非クラスター化インデックスを使用している場合がありますが、ルックアップして追加の列を取得する場合があります。これらの問題を個別に修正するのは非常に簡単に聞こえます。不足しているインデックスを追加するだけですよね?クラスタ化されたインデックスまたはヒープのスキャンがある場合は、クエリに必要なインデックスを作成して実行しますか?または、使用されているインデックスがあり、それがテーブルに移動して追加の列を取得する場合は、そのインデックスに列を追加するだけですか?
通常、それほど簡単ではありません。簡単な場合でも、ここで概説しているプロセスを実行します。
ステップ2:確認するテーブルを決定する
クエリができたので、どのテーブルが適切にインデックス付けされていないかを把握する必要があります。計画の確認に加えて、SSMSでIOおよびTIME統計も有効にします。実行計画には、リリースごとに期間やオペレーターごとのIO数など、ますます多くの情報が含まれているため、これはおそらく私にとっては古い学校ですが、各テーブルの読み取りをすばやく確認できるため、IO統計が気に入っています。複数の結合、サブクエリ、CTE、またはネストされたビューで複雑なクエリの場合、IOや時間がクエリドライブのどこで費やされているかを理解します。この時点から可能な限り、私はより大きく複雑なクエリを取り上げて、最大の問題を引き起こしている部分に絞り込みます。
たとえば、10個のテーブルに結合し、2つのサブクエリがあるクエリがある場合、プラン(IOおよび期間情報とともに)は、問題が存在する場所を特定するのに役立ちます。次に、クエリのその部分(問題のあるテーブルと、それが結合する他のいくつかのテーブル)を取り出して、それに焦点を当てます。サブクエリだけの場合もあるので、そこから始めます。
ステップ3:既存のインデックスを確認する
クエリ(またはクエリの一部)を定義したら、関連するテーブルの既存のインデックスに焦点を当てます。このステップでは、Kimberlyのバージョンのsp_helpindexに依存しています。 INCLUDEd列とフィルター定義(存在する場合)もリストされるため、標準のsp_helpindexよりも彼女のバージョンの方がはるかに好きです。テーブルに表示されるインデックスの数に応じて、これをコピーしてExcelに貼り付け、インデックスキー、含まれている列に基づいて並べ替えることがよくあります。これにより、冗長性をすばやく見つけることができます。
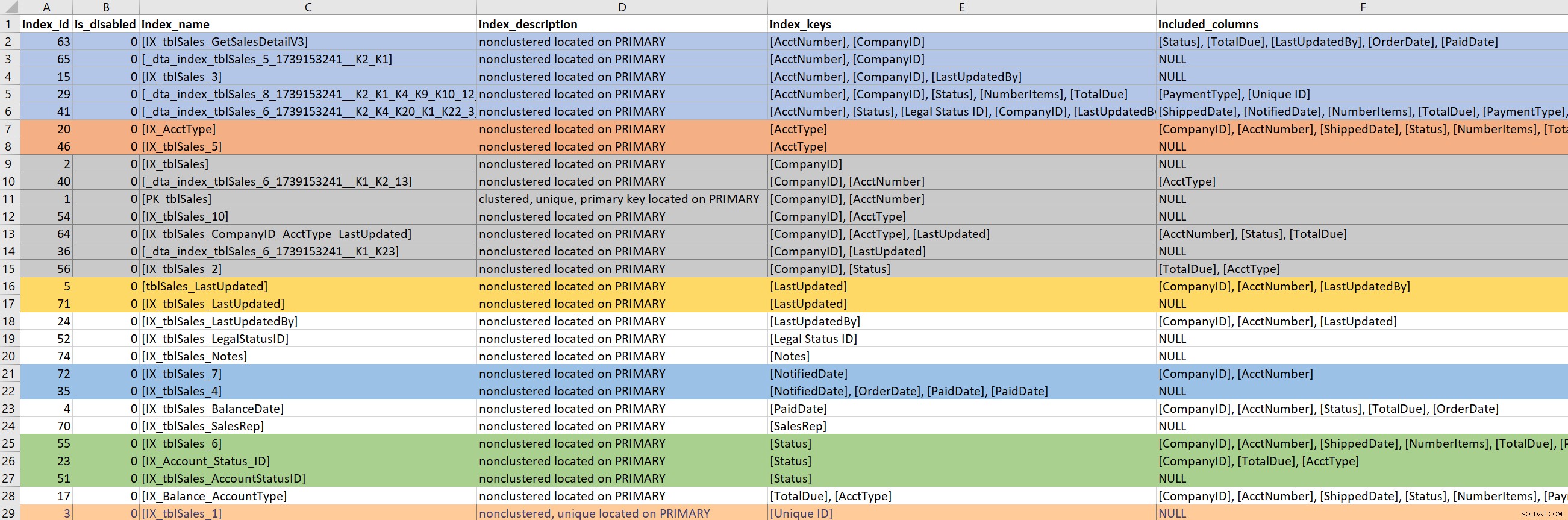
上記の出力例に基づくと、CompanyIDで始まる7つのインデックス、AcctNumberで始まる5つのインデックス、およびその他の潜在的な冗長性があります。 1つだけにするのが理想的ですが 十分ではない一部のクエリパターンについて、特定の列(CompanyIDなど)につながるインデックス。
既存のインデックスを見ると、うさぎの穴を簡単に見つけることができます。上記の出力を見て、CompanyIDで始まるインデックスが7つある理由をすぐに尋ね始めます。誰がそれらを作成したのか、なぜ、どのクエリに対して作成したのかを知りたいのです。しかし…問題のあるクエリでCompanyIDが使用されていない場合は、気にする必要がありますか?はい…一般的に私はパフォーマンスを向上させるためにそこにいるので、それが途中でテーブル上の他のインデックスを調べることを意味するのであれば、そうです。しかし、これは時間(そして真の目的)を見失いがちな場所です。
問題のあるクエリでPaidDateにつながるインデックスが必要な場合は、既存のインデックスを1つだけ処理する必要があります。問題のあるクエリでAcctNumberにつながるインデックスが必要な場合は、注意が必要です。既存のインデックスがクエリをカバーしていて、インデックスを拡張する(列を追加する)か、統合する(2つまたは3つのインデックスを1つに統合する)ことを検討している場合は、掘り下げる必要があります。
ステップ4:インデックス使用統計
多くの人が継続的にインデックス使用統計を取得していないことがわかりました。これは残念なことです。保持するインデックスと、削除またはマージするインデックスを決定するときにデータが役立つと思うからです。過去の使用状況の統計がない場合は、少なくとも現在の使用状況を確認します(最後のサービスの再起動以降):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
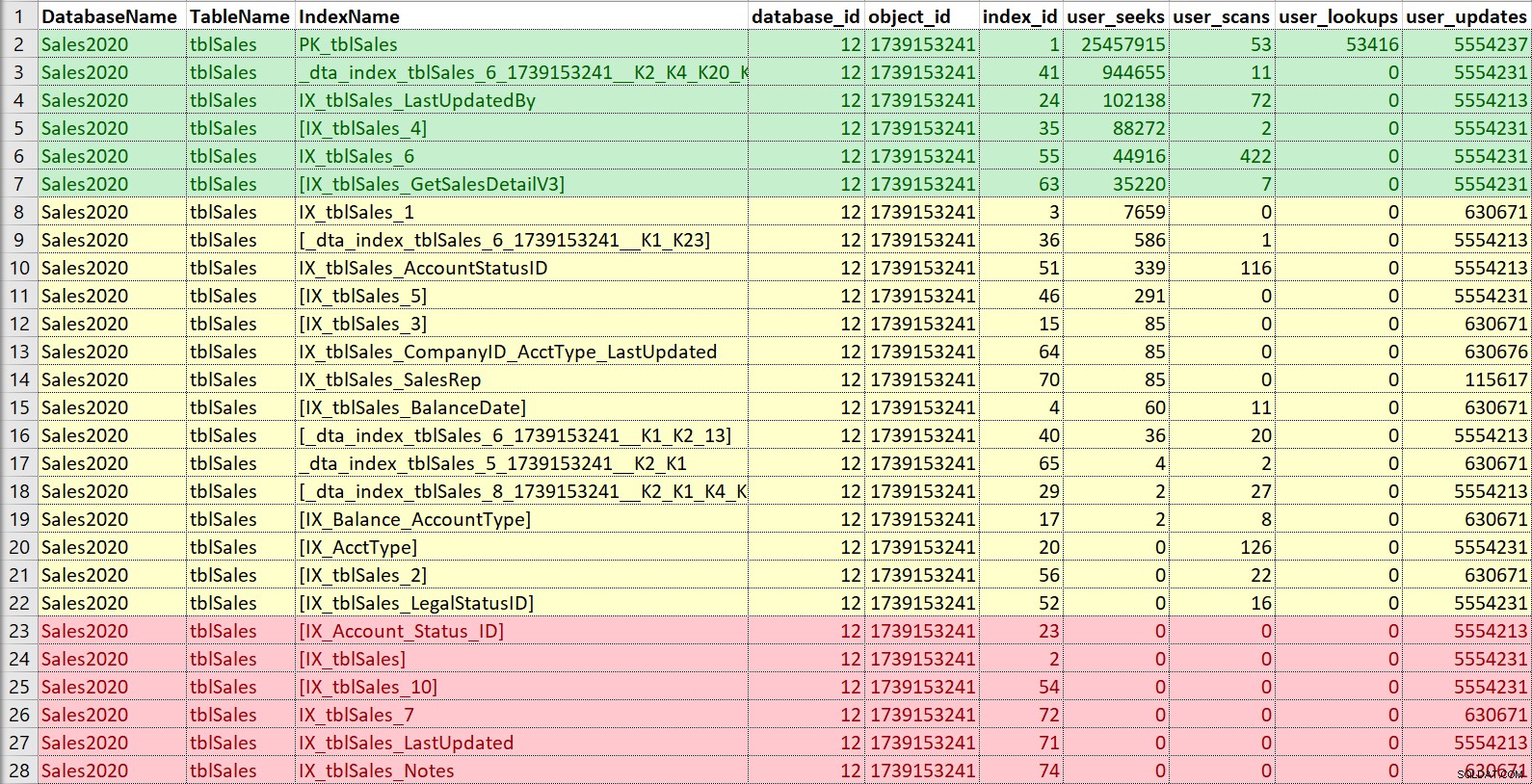
繰り返しになりますが、これをExcelに入れ、シークで並べ替えてからスキャンし、更新に注意するのが好きです。この例では、赤で表示されているインデックスは、シーク、スキャン、ルックアップがなく、更新のみのインデックスです。それらが本当に使用されていない場合、それらは無効にされ、潜在的に削除される可能性があります(ここでも、使用履歴があると役立ちます)。緑のインデックスは間違いなく使用されています。私はそれらを保持したいと思います(場合によっては微調整することもできますが)。黄色のものは…使用されているものもあれば、ほとんど使用されていないものもあります。繰り返しになりますが、ここでは履歴、または他の人からのコンテキストが役立ちます。常に実行されないレポートやプロセスでは、インデックスが重要になる場合があります。
真のクリーンアップと統合ではなく、新しいインデックスを変更または追加することだけを考えている場合は、追加または変更したいものと同様のインデックスに主に関心があります。ただし、使用状況情報をお客様に必ず指摘し、時間が許せば、テーブルの全体的なインデックス作成戦略を支援します。
次は何ですか?
まだ終わっていません!これは、インデックスチューニングへの私のアプローチのパート1であり、次回の記事では、残りのステップをリストします。それまでの間、インデックスの使用状況の統計情報を取得していない場合は、上記のクエリまたは別のバリエーションを使用して設定できます。上記のように特定のテーブルとデータベースだけでなく、すべてのユーザーデータベースの使用統計をキャプチャすることをお勧めします。そのため、必要に応じて述語を変更します。そして最後に、その情報をテーブルにスナップショットするスケジュールされたジョブの一部として、データがしばらくそこにあった後にテーブルをクリーンアップする別のステップを忘れないでください(私は少なくとも6か月間それを保持します;一部の人は言うかもしれません年が必要です。