SQL Server 2012がまだベータ版だった頃、私は新しいFORMAT()についてブログを書きました。 関数:SQL Server v.Next(Denali):CTP3 T-SQLの機能強化:FORMAT()。
当時、私は新機能にとても興奮していたので、パフォーマンステストを行うことすら考えていませんでした。私は最近のブログ投稿でこれに対処しましたが、それは単に日時から時間を取り除くという文脈でのみです:日時からの時間のトリミング–フォローアップ。
先週、私の親友のJason Horner(ブログ| @jasonhorner)がこれらのツイートで私を騙しました:
| |
これに関する私の問題は、そのFORMAT()だけです。 便利に見えますが、他のアプローチと比較すると非常に非効率的です(ああ、そのAS VARCHAR 物事も悪いです)。あなたがこのonesy-twosyをやっていて、小さな結果セットの場合、私はそれについてあまり心配しません。しかし、大規模な場合、かなり高価になる可能性があります。例を挙げて説明しましょう。まず、1000個の疑似ランダム日付を持つ小さなテーブルを作成しましょう:
SELECT TOP (1000) d = DATEADD(DAY, CHECKSUM(NEWID())%1000, o.create_date) INTO dbo.dtTest FROM sys.all_objects AS o ORDER BY NEWID(); GO CREATE CLUSTERED INDEX d ON dbo.dtTest(d);
それでは、このテーブルのデータを使用してキャッシュを準備し、人々がその時間だけを提示する傾向がある3つの一般的な方法を説明しましょう。
SELECT d, CONVERT(DATE, d), CONVERT(CHAR(10), d, 120), FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest;
それでは、これらのさまざまな手法を使用して個々のクエリを実行してみましょう。それらを5回ごとに実行し、次のバリエーションを実行します。
- 1,000行すべてを選択
- クラスター化されたインデックスキーで並べ替えられたTOP(1)を選択する
- 変数への割り当て(フルスキャンを強制しますが、SSMSレンダリングがパフォーマンスに干渉するのを防ぎます)
スクリプトは次のとおりです。
-- select all 1,000 rows GO SELECT d FROM dbo.dtTest; GO 5 SELECT d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5 -- select top 1 GO SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER BY d; GO 5 -- force scan but leave SSMS mostly out of it GO DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; GO 5 DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5
これで、次のクエリでパフォーマンスを測定できます(私のシステムはかなり静かです。あなたのシステムでは、execution_countよりも高度なフィルタリングを実行する必要があるかもしれません。 ):
SELECT [t] = CONVERT(CHAR(255), t.[text]), s.total_elapsed_time, avg_elapsed_time = CONVERT(DECIMAL(12,2),s.total_elapsed_time / 5.0), s.total_worker_time, avg_worker_time = CONVERT(DECIMAL(12,2),s.total_worker_time / 5.0), s.total_clr_time FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.[sql_handle]) AS t WHERE s.execution_count = 5 AND t.[text] LIKE N'%dbo.dtTest%' ORDER BY s.last_execution_time;
私の場合の結果はかなり一貫していました:
| クエリ(切り捨て) | 期間(マイクロ秒) | |||
|---|---|---|---|---|
| total_elapsed | avg_elapsed | total_clr | ||
| 1,000行を選択 | SELECT d FROM dbo.dtTest ORDER BY d; |
1,170 |
234.00 |
0 |
SELECT d = CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; |
2,437 |
487.40 |
0 |
|
SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORD ... |
151,521 |
30,304.20 |
0 |
|
SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER ... |
240,152 |
48,030.40 |
107,258 |
|
| SELECT TOP (1) | SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; |
251 |
50.20 |
0 |
SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY ... |
440 |
88.00 |
0 |
|
SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ... |
301 |
60.20 |
0 |
|
SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest O ... |
1,094 |
218.80 |
589 |
|
| Assign variable | DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; |
639 |
127.80 |
0 |
DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.d ... |
644 |
128.80 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 12 ... | 1,972 |
394.40 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') ... |
118,062 |
23,612.40 |
98,556 |
|
And to visualize the avg_elapsed_timeを視覚化する 出力(クリックして拡大):
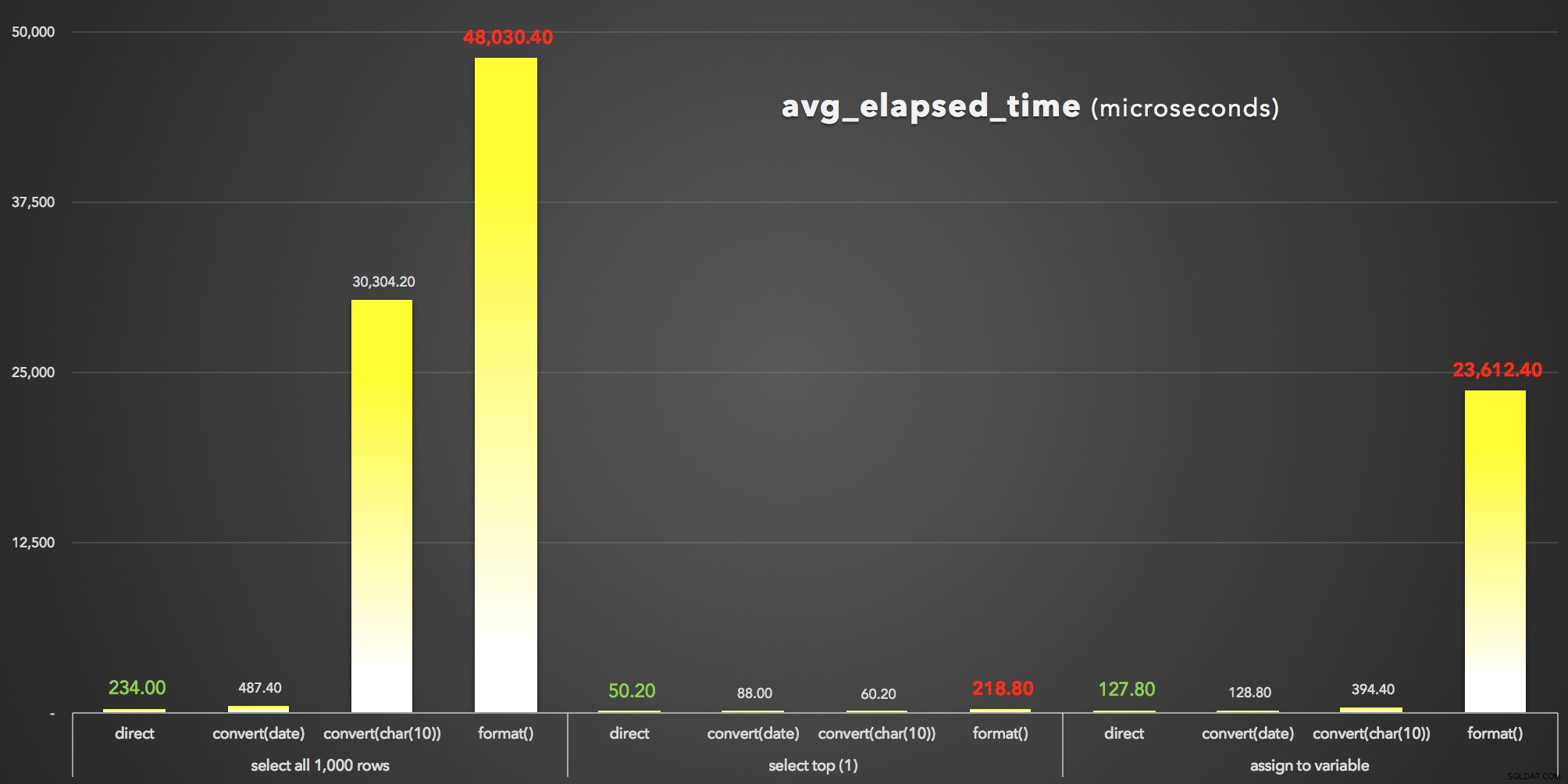 FORMAT()は明らかに敗者です:avg_elapsed_time結果(マイクロ秒)
FORMAT()は明らかに敗者です:avg_elapsed_time結果(マイクロ秒)
これらの結果から(再び)学ぶことができること:
- 何よりもまず、
FORMAT()高い 。 -
FORMAT()確かに、C#のような他の言語のメソッドと一貫性のある、より柔軟性があり、より直感的なメソッドを提供できます。ただし、そのオーバーヘッドに加えて、CONVERT()スタイル番号はわかりにくく、網羅的ではありません。FORMAT()なので、とにかく古いアプローチを使用する必要があるかもしれません。 SQLServer2012以降でのみ有効です。 - スタンバイの
CONVERT()でも メソッドは大幅にコストがかかる可能性があります(ただし、SSMSが結果をレンダリングする必要がある場合は、非常に深刻です。日付値とは異なる方法で文字列を処理することは明らかです)。 - データベースからdatetime値を直接取得するだけが、常に最も効率的でした。アプリケーションがプレゼンテーション層で希望どおりに日付をフォーマットするのにかかる追加の時間をプロファイリングする必要があります-SQLServerがかなりのフォーマットに関与することを望まない可能性が高いです(実際、多くの人が主張します)これがそのロジックが常に属する場所です。
ここではマイクロ秒しか話していませんが、1,000行しか話していません。それを実際のテーブルサイズにスケールアウトすると、間違ったフォーマットアプローチを選択した場合の影響は壊滅的なものになる可能性があります。
自分のマシンでこの実験を試してみたい場合は、サンプルスクリプトをアップロードしました:FormatIsNiceAndAllBut.sql_.zip