2014年に、クエリプラン全体のパフォーマンスチューニングという記事を書きました。適度に大きなデータセットから比較的少数の個別の値を見つける方法を検討し、再帰的なソリューションが最適である可能性があると結論付けました。このフォローアップ投稿では、より多くの行を使用して、SQLServer2019の質問を再検討します。
50GBのStackOverflow2013データベースを使用しますが、個別の値の数が少ない大きなテーブルであれば問題ありません。
BountyAmountで個別の値を探します dbo.Votesの列 表、賞金の昇順で表示されます。投票テーブルには、5,300万行弱(正確には52,928,720行)があります。 NULLを含め、19種類の報奨金があります 。
Stack Overflow 2013データベースには、ダウンロード時間を最小限に抑えるための非クラスター化インデックスが付属していません。 Idにはクラスター化された主キーインデックスがあります dbo.Votesの列 テーブル。 SQL Server 2008との互換性(レベル100)に設定されていますが、SQL Server 2017(レベル140)のより新しい設定から始めます。
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
テストは、SQL Server 2019 CU 2を使用して私のラップトップで実行されました。このマシンには、2.4GHzの基本速度の4つのi7 CPU(8にハイパースレッド)があります。 32GBのRAMがあり、SQLServer2019インスタンスで24GBを使用できます。並列処理のコストしきい値は50に設定されています。
各テスト結果は、必要なすべてのデータとインデックスページがメモリ内にある、10回の実行のベストを表しています。
1。行ストアクラスター化インデックス
ベースラインを設定するための最初の実行は、新しいインデックスを作成しないシリアルクエリです(これは、データベースが互換性レベル140に設定されていることを忘れないでください):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
これにより、クラスター化インデックスがスキャンされ、行モードのハッシュ集計を使用して、BountyAmountの個別の値が検出されます。 :
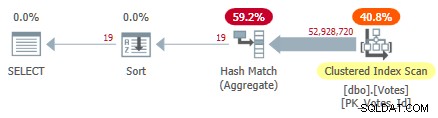
これには10,500ミリ秒かかります 同じ量のCPU時間を使用して完了します。これは、メモリ内のすべてのデータを使用して10回以上実行するのに最適な時間であることを忘れないでください。 BountyAmountで自動的に作成されたサンプル統計 列は最初の実行時に作成されました。
経過時間の約半分はクラスター化インデックススキャンに費やされ、約半分はハッシュマッチアグリゲートに費やされます。ソートには処理する行が19行しかないため、消費するのは1ミリ秒程度です。このプランのすべてのオペレーターは、行モードの実行を使用します。
MAXDOP 1を削除する ヒントは並行計画を提供します:

これは、オプティマイザーが構成にヒントなしで選択するプランです。結果を4,200msで返します 合計32,800ミリ秒のCPUを使用(DOP 8)。
2。非クラスター化インデックス
テーブル全体をスキャンして、BountyAmountだけを見つけます 非効率に見えるため、このクエリに必要な1つの列だけに非クラスター化インデックスを追加してみるのは自然なことです。
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
このインデックスの作成には時間がかかります(1分40秒)。 MAXDOP 1 オプティマイザーは非クラスター化インデックスを使用してBountyAmountに行を表示できるため、クエリはStreamAggregateを使用するようになりました。 注文:
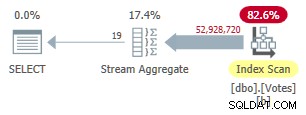
これは9,300msで実行されます (同じ量のCPU時間を消費します)。元の10,500msを大幅に改善しましたが、地球を破壊することはほとんどありません。
MAXDOP 1を削除する ヒントは、ローカル(スレッドごと)の集約を使用した並列プランを提供します:

これは3,400msで実行されます 25,800msのCPU時間を使用します。新しいインデックスの行またはページの圧縮を改善できる可能性がありますが、もっと興味深いオプションに移りたいと思います。
3。行ストアのバッチモード(BMOR)
次に、以下を使用してデータベースをSQLServer2019互換モードに設定します。
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
これにより、オプティマイザは、価値があると判断した場合に、行ストアでバッチモードを自由に選択できます。これにより、列ストアインデックスを必要とせずに、バッチモード実行の利点のいくつかを提供できます。技術的な詳細と文書化されていないオプションについては、このテーマに関するDmitryPiluginの優れた記事を参照してください。
残念ながら、オプティマイザは、シリアルテストクエリとパラレルテストクエリの両方にストリーム集計を使用した完全な行モードの実行を選択します。行ストア実行プランでバッチモードを取得するために、ハッシュ一致(バッチモードで実行可能)を使用して集計を促進するためのヒントを追加できます:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); これにより、すべてのオペレーターがバッチモードで実行される計画が得られます。

結果は2,600msで返されます (通常どおりすべてのCPU)。これはすでに並列よりも高速です はるかに少ないCPU(2,600ms対25,800ms)を使用しながら、行モード計画(3,400ms経過)。
MAXDOP 1を削除する ヒント(ただし、HASH GROUPは保持します )行ストアプランで並列バッチモードを提供します:
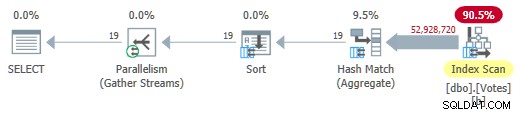
これはわずか725msで実行されます 5,700ミリ秒のCPUを使用しています。
4。列ストアのバッチモード
行ストア結果の並列バッチモードは、印象的な改善です。データの列ストア表現を提供することで、さらに優れた成果を上げることができます。他のすべてを同じに保つために、非クラスター化を追加します 必要な列だけの列ストアインデックス:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
これは、既存のb-tree非クラスター化インデックスから入力され、作成に15秒しかかかりません。
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); オプティマイザーは、列ストアインデックススキャンを含む完全なバッチモードプランを選択します。
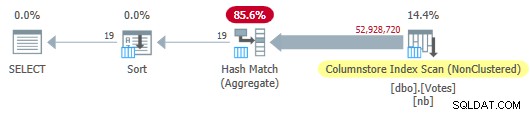
これは115msで実行されます 同じ量のCPU時間を使用します。プランの推定コストが並列処理のコストしきい値を下回っているため、オプティマイザーはシステム構成に関するヒントなしでこのプランを選択します。 。
並行計画を立てるには、コストのしきい値を下げるか、文書化されていないヒントを使用します。
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); いずれにせよ、並行計画は次のとおりです。

クエリの経過時間が30msに短縮されました 、210msのCPUを消費します。
5。プッシュダウンを使用した列ストアのバッチモード
特に元の10,500msと比較した場合、現在の最高の実行時間である30msは印象的です。それでも、スキャンからハッシュマッチアグリゲートに5,300万行近く(58,868バッチ)を渡さなければならないのは少し残念です。
SQL Serverが集計をスキャンにプッシュダウンし、列ストアから直接個別の値を返すことができれば便利です。 DISTINCTを表現する必要があると思われるかもしれません GROUP BYとして Grouped Aggregate Pushdownを取得しますが、これは論理的に冗長であり、いずれの場合も全体像ではありません。
現在のSQLServerの実装では、実際に集計を計算する必要があります。 集約プッシュダウンをアクティブにします。それ以上に、使用する必要があります どういうわけか集計結果、またはオプティマイザーは不要なものとしてそれを削除します。
集約プッシュダウンを実現するためのクエリを作成する1つの方法は、論理的に冗長な2次順序付け要件を追加することです。
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); シリアルプランは次のとおりです:
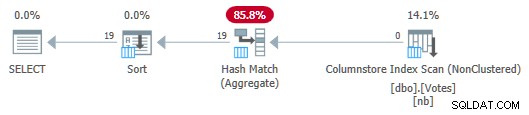
ScanからAggregateに行が渡されないことに注意してください。裏で、BountyAmountの部分的な集計 値とそれに関連する行数はHashMatchAggregateに渡され、Hash Match Aggregateは部分的な集計を合計して、必要な最終(グローバル)集計を形成します。 13ms の経過時間で確認されるように、これは非常に効率的です。 (これらはすべてCPU時間です)。念のため、以前のシリアルプランには115ミリ秒かかりました。
セットを完了するために、以前と同じ方法で並列バージョンを取得できます。

これは7ms実行されます 合計40msのCPUを使用しています。
プッシュダウンするだけでなく、集計を計算して使用する必要があるのは残念です。おそらくこれは将来改善され、DISTINCT およびGROUP BY 骨材なしでスキャンにプッシュダウンできます。
6。行モードの再帰共通テーブル式
最初に、大規模なデータセットで少数の重複を見つけるために使用される再帰CTEソリューションを再検討することを約束しました。その手法を使用して現在の要件を実装することは非常に簡単ですが、コードはこれまでに見たものよりも必然的に長くなります:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0);による注文 このアイデアは、いわゆるインデックススキップスキャンにルーツがあります。昇順のbツリーインデックスの先頭で関心のある最小値を見つけ、次にインデックス順に次の値を見つけようとします。 bツリーインデックスの構造により、次に高い値を非常に効率的に見つけることができます。重複をスキャンする必要はありません。
ここでの唯一の本当のトリックは、オプティマイザーにTOPを使用できるように説得することです。 CTEの「再帰的」部分で、個別の値ごとに1つのコピーを返します。詳細について復習が必要な場合は、前回の記事をご覧ください。
実行計画(ここでCraig Freedmanによって一般的に説明されています)は次のとおりです。
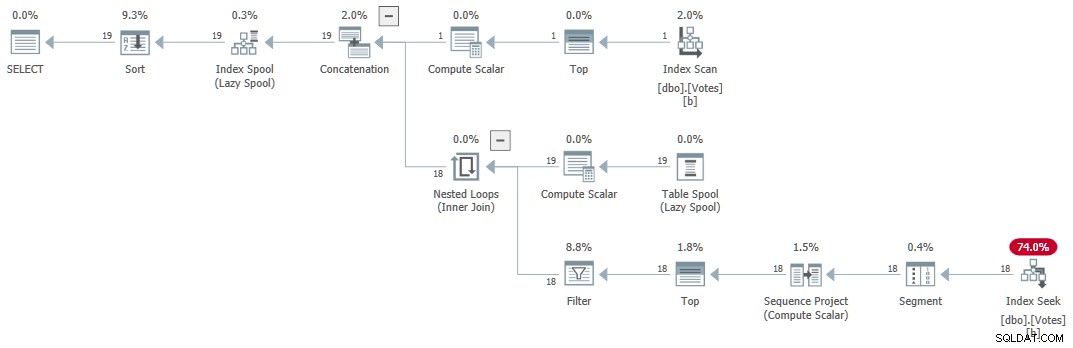
クエリは1msで正しい結果を返します Sentry One Plan Explorerによると、1ミリ秒のCPUを使用しています。
7。反復T-SQL
同様のロジックは、WHILEを使用して表現できます。 ループ。コードは、再帰CTEよりも読みやすく理解しやすい場合があります。また、CTEの再帰部分に対する多くの制限を回避するためにトリックを使用する必要がなくなります。パフォーマンスは約15msで競争力があります。このコードは目的のために提供されており、パフォーマンスの概要表には含まれていません。
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount;
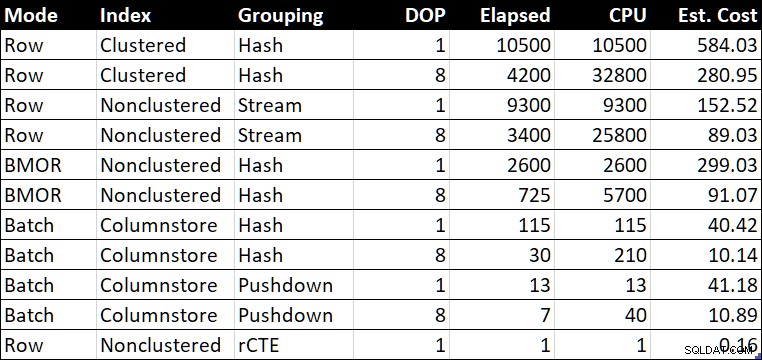 パフォーマンスサマリーテーブル(ミリ秒単位の期間/ CPU)
パフォーマンスサマリーテーブル(ミリ秒単位の期間/ CPU)
「Est。 「コスト」列には、テストシステムで報告された各クエリのオプティマイザのコスト見積もりが表示されます。
少数の個別の値を見つけることは非常に具体的な要件のように思えるかもしれませんが、通常はより大きなクエリの調整の一環として、長年にわたってかなり頻繁に遭遇しました。
最後のいくつかの例は、パフォーマンスが非常に近いものでした。多くの人は、優先順位に応じて、1秒未満の結果のいずれかに満足するでしょう。行ストアの結果が2,600msのシリアルバッチモードでさえ、最高の並列とよく比較されます。 行モードプラン。SQLServer2019にアップグレードし、データベース互換性レベル150を有効にするだけで、大幅な高速化が可能になります。すべてのユーザーが列ストアストレージにすばやく移動できるわけではなく、いずれにしても常に適切なソリューションとは限りません。 。行ストアのバッチモードは、オプティマイザーにそれを使用することを選択するように説得できると仮定して、列ストアで可能な利益のいくつかを達成するためのきちんとした方法を提供します。
5,700万行の並列列ストア集計プッシュダウンの結果 7msで処理 (40msのCPUを使用)は、特にハードウェアを考慮すると注目に値します。 13msのシリアルアグリゲートプッシュダウンの結果 同様に印象的です。これらの計画を取得するために、意味のない集計結果を追加する必要がなかったとしたら、それは素晴らしいことです。
SQL Server 2019または列ストアストレージにまだ移行できない場合でも、適切なbツリーインデックスが存在する場合、再帰CTEは実行可能で効率的なソリューションであり、必要な個別の値の数は非常に少ないことが保証されます。 SQL Serverが再帰CTE(またはWHILEを使用した同等の反復ループT-SQLコード)を記述せずに、このようなbツリーにアクセスできれば便利です。 。
この問題のもう1つの可能な解決策は、インデックス付きビューを作成することです。これにより、明確な値が非常に効率的に提供されます。欠点は、いつものように、基になるテーブルを変更するたびに、マテリアライズドビューに格納されている行数を更新する必要があることです。
ここで紹介する各ソリューションには、要件に応じてその場所があります。さまざまなツールを利用できるようにすることは、クエリを調整するときに一般的に良いことです。ほとんどの場合、重複がいくつ存在してもパフォーマンスは非常に予測可能であるため、バッチモードソリューションの1つを選択します。