更新:2021年9月2日 (元々は2012年7月26日に公開されました。)
私たちのお気に入りのデータベースプラットフォームのいくつかのメジャーバージョンの過程で、多くのことが変化します。 SQL Server 2016は、これまで必要だったカスタムソリューションの多くを不要にするネイティブ関数であるSTRING_SPLITをもたらしました。それも速いですが、完璧ではありません。たとえば、1文字の区切り文字のみをサポートし、入力要素の順序を示すものは何も返しません。この投稿が書かれてから、この関数(およびSQL Server 2017に登場したSTRING_AGG)に関するいくつかの記事を書きました:
- パフォーマンスの驚きと仮定:STRING_SPLIT()
- SQL Server 2016のSTRING_SPLIT():フォローアップ#1
- SQL Server 2016のSTRING_SPLIT():フォローアップ#2
- SQLServerのSTRING_SPLITを使用した文字列置換コードの分割
- 文字列の分割/連結方法の比較
- SQLServerの新しいSTRING_AGGおよびSTRING_SPLIT関数に関する古い問題を解決します
- SQLServerのSTRING_SPLIT関数での1文字の区切り文字の処理
- STRING_SPLITの改善にご協力ください
- SQL ServerでSTRING_SPLITを改善する方法–そしてあなたは助けることができます
後世と歴史的関連性のために、またテスト方法のいくつかは文字列の分割以外の他の問題に関連しているため、以下のコンテンツをここに残しますが、分割方法については、上記の参照のいくつかを参照してくださいSQL Serverの最新のサポートされているバージョンの文字列–およびこの投稿では、文字列の分割が、新しい関数であるかどうかにかかわらず、データベースで最初に解決したい問題ではない理由を説明しています。
- 文字列の分割:T-SQLが少なくなりました
多くの人が「スプリットストリング」の問題にうんざりしていることは知っていますが、それでもフォーラムやStack OverflowなどのQ&Aサイトでほぼ毎日発生しているようです。これは、人々が次のような文字列を渡したい場合の問題です:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
手順の中で、彼らは次のようなことをしたいと思っています:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); @FavoriteTeamsは単一の文字列であり、上記は次のように変換されるため、これは機能しません。
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); したがって、SQL Serverは、 Patriots、Red Sox、Bruinsという名前のチームを見つけようとします。 、そして私はそのようなチームはないと思います。彼らがここで本当に望んでいるのは、次と同等です:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); ただし、SQL Serverには配列型がないため、これは変数の解釈方法ではありません。それでも、コンマが含まれている単純な単一の文字列です。疑わしいスキーマ設計はさておき、この場合、コンマ区切りのリストを個々の値に「分割」する必要があります。これは、まさにそれを達成するための最良の解決策について、多くの「新しい」議論や解説に拍車をかける質問です。
答えは、ほとんどの場合、CLRを使用する必要があるということのようです。 CLRを使用できない場合、および企業ポリシー、先のとがった髪のボス、または頑固さのために使用できない人がたくさんいることを知っている場合は、存在する多くの回避策の1つを使用します。そして、多くの回避策が存在します。
しかし、どちらを使用する必要がありますか?
いくつかのソリューションのパフォーマンスを比較し、誰もが常に尋ねる質問に焦点を当てます。「どれが最速ですか?」潜在的な方法の*すべて*についての議論を詳しく説明するつもりはありません。なぜなら、それらは単にスケーリングしないという事実のために、いくつかはすでに排除されているからです。また、将来、他の指標への影響を調べるためにこれを再検討する可能性がありますが、今のところは期間に焦点を当てます。比較する候補は次のとおりです(4つのCPUと8GBのRAMを搭載したWindows7VMでSQLServer 2012、11.00.2316を使用):
CLR
CLRを使用したい場合は、自分で書くことを考える前に、MVPの仲間であるAdam Machanicからコードを借りる必要があります(車輪の再発明については以前にブログを書いていますが、このような無料のコードスニペットにも適用されます)。彼は、文字列を効率的に解析するために、このCLR関数を微調整することに多くの時間を費やしました。現在CLR関数を使用していて、そうでない場合は、展開して比較することを強くお勧めします。機能的に同等の、はるかに単純なVBベースのCLRルーチンに対してテストしましたが、VBアプローチのパフォーマンスは約3倍劣っています。アダムより。
そこで、Adamの関数を使用して、コードをDLLにコンパイルし(cscを使用)、そのファイルだけをサーバーにデプロイしました。次に、次のアセンブリと関数をデータベースに追加しました。
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
これは、入力が「安全」であることがわかっている1回限りのシナリオで使用する一般的な関数ですが、実稼働環境ではお勧めしません(詳細は以下を参照)。
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO XMLアプローチには、非常に強力な注意が必要です。これは、入力文字列に不正なXML文字が含まれていないことを保証できる場合にのみ使用できます。 <、>、または&を含む1つの名前を指定すると、関数が爆発します。したがって、パフォーマンスに関係なく、このアプローチを使用する場合は、制限に注意してください。一般的な文字列スプリッターの実行可能なオプションと見なすべきではありません。 できる場合があるかもしれないので、このまとめに含めます。 入力を信頼します。たとえば、整数またはGUIDのコンマ区切りリストに使用できます。
数値表
このソリューションでは、Numbersテーブルを使用します。このテーブルは、自分で作成して入力する必要があります。 (私たちは何年にもわたって組み込みバージョンを要求してきました。)Numbersテーブルには、分割する最長の文字列の長さを超えるのに十分な行が含まれている必要があります。この場合、1,000,000行を使用します:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (データ圧縮を使用すると、必要なページ数が大幅に削減されますが、明らかにこのオプションはEnterprise Editionを実行している場合にのみ使用してください。この場合、圧縮データは1,360ページ必要ですが、圧縮なしの場合は2,102ページで、約35%の節約になります。 )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
共通テーブル式
このソリューションでは、再帰CTEを使用して、前の部分の「余り」から文字列の各部分を抽出します。ローカル変数を使用する再帰CTEとして、これはすべてインラインである他の関数とは異なり、マルチステートメントのテーブル値関数である必要があることに注意してください。
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
JeffModenのスプリッター より長い文字列をサポートするためにマイナーな変更を加えた、JeffModenのスプリッターに基づく関数
SQLServerCentralで、Jeff ModenはCLRのパフォーマンスに匹敵するスプリッター関数を提示したので、このまとめに同様のアプローチを使用してバリエーションを含めるのは公正だと思いました。最長の文字列(500,000文字)を処理するために、彼の関数にいくつかの小さな変更を加える必要がありました。また、命名規則も同様にしました。
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; 余談ですが、Jeff Modenのソリューションを使用している場合は、上記の数値テーブルを使用して、Jeffの関数を少し変更して実験することを検討してください。
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (これは、わずかに高い読み取り値をわずかに低いCPUと交換するため、システムがすでにCPUバウンドかI / Oバウンドかによってはより良い場合があります。)
健全性チェック
正しい方向に進んでいることを確認するために、5つの関数すべてが期待される結果を返すことを確認できます。
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
実際、これらは5つのケースすべてで見られる結果です…

テストデータ
関数が期待どおりに動作することがわかったので、楽しい部分に取り掛かることができます。長さが異なるさまざまな数の文字列に対してパフォーマンスをテストすることです。しかし、最初にテーブルが必要です。次の単純なオブジェクトを作成しました:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
このテーブルにさまざまな長さの文字列のセットを入力し、各テストでほぼ同じデータのセットが使用されるようにしました。最初の10,000行は文字列の長さが50文字で、次に1,000行の文字列は500文字の長さです。 、文字列の長さが5,000文字の場合は100行、文字列の長さが50,000文字の場合は10行など、500,000文字の1行まで。これは、関数によって処理されている同じ量の全体的なデータを比較するためと、テスト時間をある程度予測可能に保つための両方で行いました。
#tempテーブルを使用して、GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
このテーブルの作成と入力には、私のマシンで約20秒かかりました。このテーブルは、約6 MB相当のデータを表します(約500,000文字×2バイト、つまりstring_typeごとに1 MB、さらに行とインデックスのオーバーヘッド)。巨大なテーブルではありませんが、関数間のパフォーマンスの違いを強調するのに十分な大きさである必要があります。
テスト
関数が配置され、テーブルに大きな文字列が適切に詰め込まれているので、最終的にいくつかの実際のテストを実行して、さまざまな関数が実際のデータに対してどのように機能するかを確認できます。ネットワークオーバーヘッドを考慮せずにパフォーマンスを測定するために、SQL Sentry Plan Explorerを使用して、テストの各セットを10回実行し、期間メトリックを収集して、平均化しました。
最初のテストでは、各文字列からアイテムをセットとしてプルしました。
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
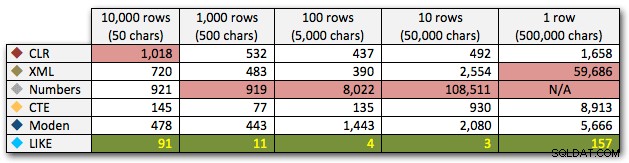
結果は、ストリングが大きくなるにつれて、CLRの利点が本当に輝いていることを示しています。下端では、結果はまちまちでしたが、XMLメソッドの使用は、XMLセーフな入力に依存しているため、XMLメソッドの横にはアスタリスクを付ける必要があります。この特定のユースケースでは、Numbersテーブルは一貫して最悪のパフォーマンスを示しました:
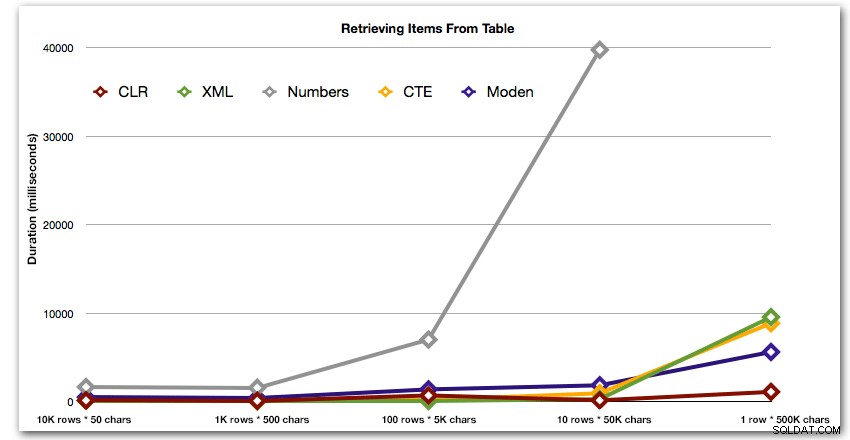
ミリ秒単位の期間
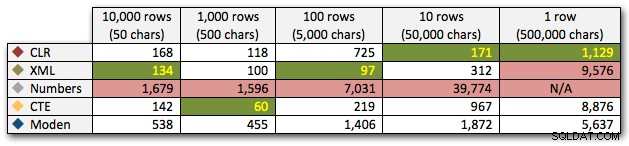
50,000文字の10行に対する数値テーブルの双曲線40秒のパフォーマンスの後、最後のテストの実行からそれを削除しました。このテストでの4つの最良の方法の相対的なパフォーマンスをよりよく示すために、グラフから数値の結果を完全に削除しました。
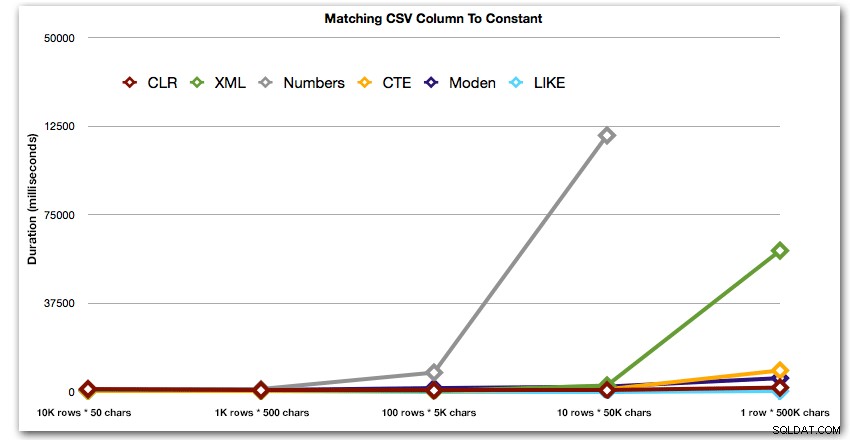
次に、カンマ区切りの値に対して検索を実行する場合を比較してみましょう(たとえば、文字列の1つが「foo」である行を返します)。ここでも上記の5つの関数を使用しますが、結果を、分割に煩わされる代わりにLIKEを使用して実行時に実行された検索と比較します。
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
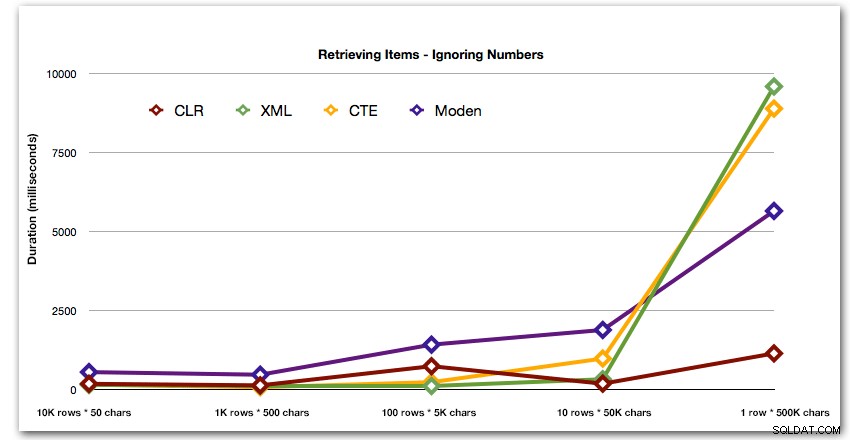
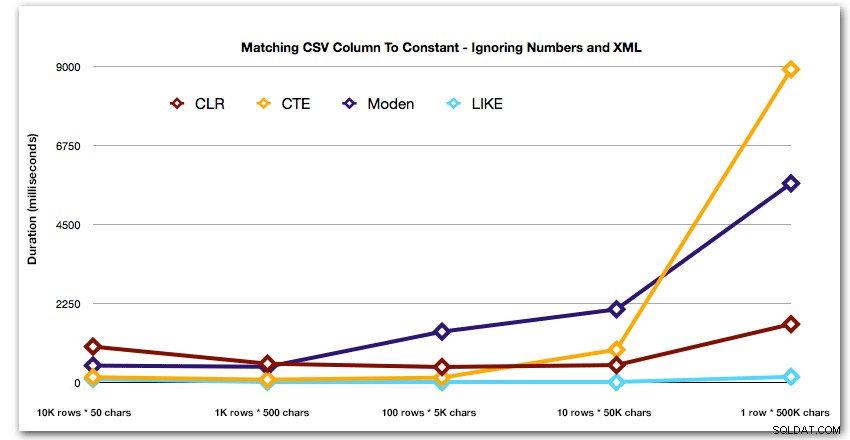
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; これらの結果は、小さな文字列の場合、CLRが実際に最も低速であり、データをまったく分割せずにLIKEを使用してスキャンを実行するのが最善の解決策であることを示しています。もう一度、文字列のサイズが大きくなるにつれてその期間が指数関数的に増加することが明らかだったときに、5番目のアプローチからNumbersテーブルソリューションを削除しました:
ミリ秒単位の期間
また、上位4つの結果のパターンをわかりやすく示すために、グラフから数値とXMLソリューションを削除しました。
次に、この投稿の最初からユースケースを複製する方法を見てみましょう。ここでは、渡されるリストに存在する1つのテーブルのすべての行を検索しようとしています。上記で作成したテーブルのデータと同様に、 '50〜500,000文字の長さの文字列を作成し、それらを変数に格納してから、リストに存在する共通のカタログビューを確認します。
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
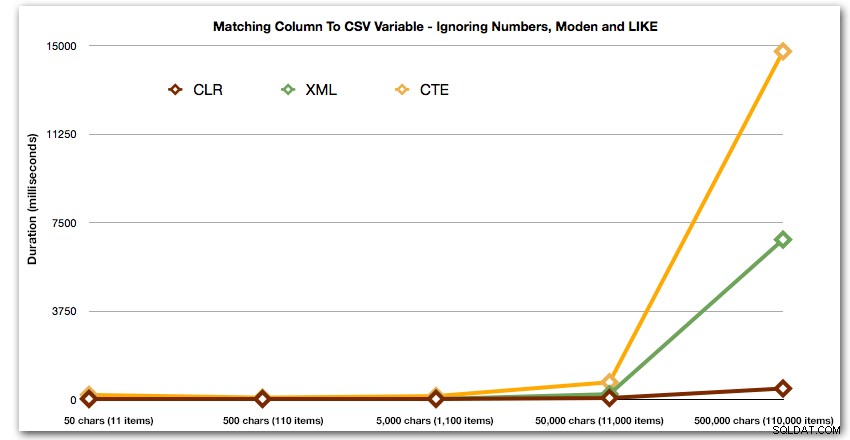
ORDER BY [object_id]; これらの結果は、このパターンの場合、文字列のサイズが大きくなるにつれて、いくつかのメソッドの期間が指数関数的に増加することを示しています。下端では、XMLはCLRと良好なペースを保っていますが、これも急速に悪化します。ここでは、CLRが一貫して明確な勝者です:
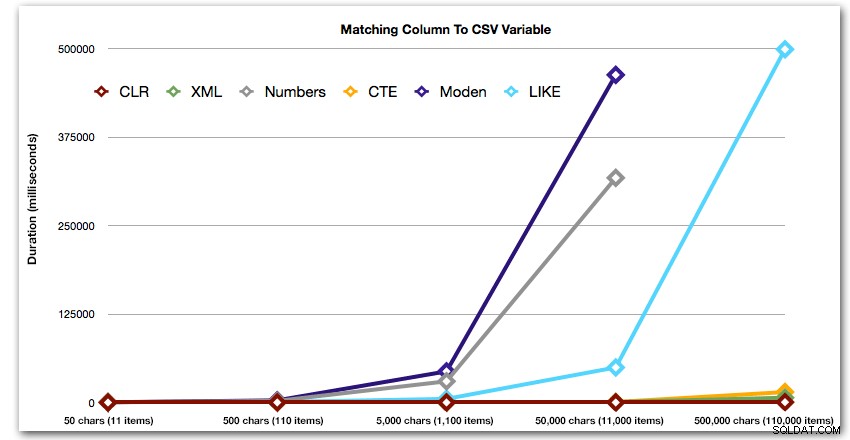
そして再び、持続時間の点で上向きに爆発する方法なしで:
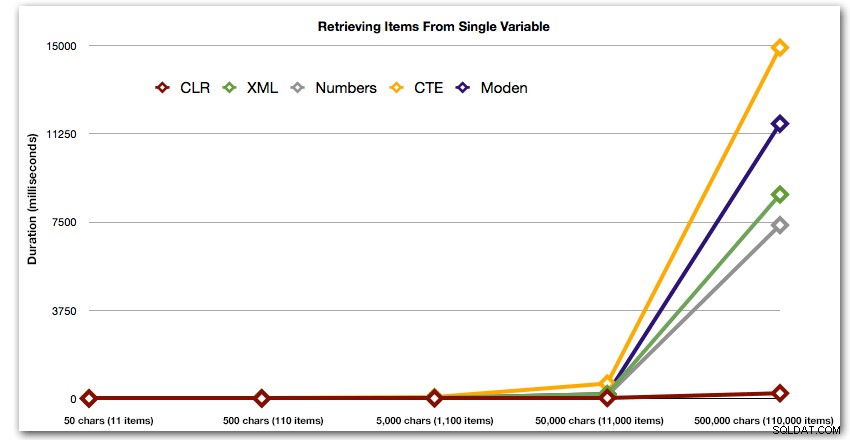
最後に、テーブルからデータを読み取るコストを無視して、さまざまな長さの単一の変数からデータを取得するコストを比較してみましょう。ここでも、50〜500,000文字のさまざまな長さの文字列を生成し、値をセットとして返します。
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
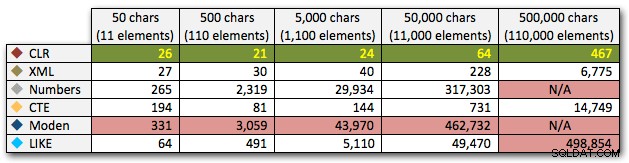
これらの結果は、CLRが期間の点でかなりフラットラインであり、セット内の最大110,000アイテムまであることを示していますが、他の方法は11,000アイテム後しばらくの間適切なペースを維持します。
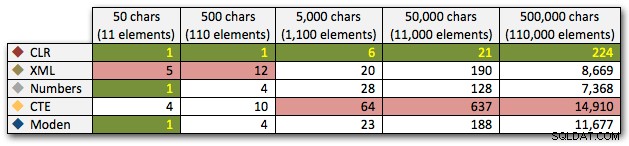
ミリ秒単位の期間
結論
ほとんどすべての場合、CLRソリューションは他のアプローチよりも明らかに優れています。場合によっては、特に弦のサイズが大きくなると、地滑りの勝利になります。他のいくつかでは、どちらの方向にも落ちる可能性のある写真判定です。最初のテストでは、XMLとCTEがローエンドでCLRを上回っていることを確認しました。したがって、これが一般的な使用例であり、文字列が1〜10,000文字の範囲にあることが確実な場合、これらのアプローチの1つはより良いオプションになります。文字列のサイズがそれよりも予測できない場合でも、CLRはおそらく全体として最善の策です。ローエンドでは数ミリ秒を失いますが、ハイエンドではかなりの量を獲得します。タスクに応じて、CLRがオプションではない場合に、2番目の場所を強調表示して選択します。入力がXMLセーフであることがわかっている場合にのみ、XMLが私の推奨される方法であることに注意してください。入力に対する信頼が低い場合、これらは必ずしも最良の選択肢ではない可能性があります。
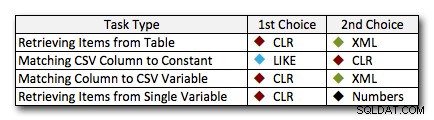
CLRが全面的に私の選択ではない唯一の本当の例外は、実際にコンマ区切りのリストをテーブルに格納し、定義されたエンティティがそのリストにある行を見つける場合です。その特定のケースでは、分割にCLRを使用しない言い訳として使用するのではなく、スキーマを再設計して適切に正規化することを最初に推奨します。これにより、これらの値が個別に保存されます。
他の理由でCLRを使用できない場合、これらのテストで明らかになった明確な「2位」はありません。上記の私の答えは、特定の文字列サイズではなく、全体的なスケールに基づいていました。ここでのすべてのソリューションは、少なくとも1つのシナリオで次点でした。したがって、CLRは、使用できる場合は明らかに選択されますが、使用できない場合は、「状況によって異なります」という答えに基づいて判断する必要があります。ユースケースと上記のテスト(または独自のテストを作成することによる)のどちらが適しているか。
補遺:そもそも分割の代替手段
上記のアプローチでは、既存のアプリケーションを変更する必要はありません。ただし、それらがすでにコンマ区切りの文字列をアセンブルし、それをデータベースにスローして処理していることを前提としています。 CLRがオプションではない場合、および/またはアプリケーションを変更できる場合に検討する必要がある1つのオプションは、テーブル値パラメーター(TVP)を使用することです。上記のコンテキストでTVPを利用する方法の簡単な例を次に示します。まず、単一の文字列列を持つテーブルタイプを作成します:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
次に、ストアドプロシージャは、このTVPを入力として受け取り、コンテンツに参加できます(または、他の方法で使用できます。これは1つの例にすぎません)。
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO たとえば、C#コードでは、コンマ区切りの文字列を作成する代わりに、DataTableにデータを入力します(または、互換性のあるコレクションがすでに値のセットを保持している可能性があるものを使用します):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} これはフォローアップ投稿の前編と見なすことができます。
もちろん、これはJSONやその他のAPIではうまく機能しません。最初にコンマ区切りの文字列がSQLServerに渡される理由はよくあります。