このシリーズのパート1とパート2では、名前付きテーブル式の一般的な論理的または概念的な側面、具体的には派生テーブルについて説明しました。今月と来月は、派生テーブルの物理的な処理の側面について説明します。パート1から、物理データの独立性を思い出してください。 関係理論の原理。リレーショナルモデルとそれに基づく標準のクエリ言語は、データの概念的な側面のみを処理し、データの保存、最適化、アクセス、処理などの物理的な実装の詳細をデータベースプラットフォームに任せることになっています(実装 )。数学モデルと標準言語に基づいているため、さまざまなリレーショナルデータベース管理システムで非常に類似しているデータの概念的な処理とは異なり、データの物理的な処理は標準に基づいていないため、傾向があります。非常にプラットフォーム固有である必要があります。シリーズの名前付きテーブル式の物理的な処理については、MicrosoftSQLServerとAzureSQLDatabaseでの処理に焦点を当てています。他のデータベースプラットフォームでの物理的な扱いはまったく異なる場合があります。
このシリーズのきっかけとなったのは、名前付きテーブル式に関するSQLServerコミュニティに存在する混乱であったことを思い出してください。用語と最適化の両方の観点から。シリーズの最初の2つのパートでいくつかの用語の考慮事項を取り上げましたが、CTE、ビュー、およびインラインTVFについて説明するときに、今後の記事でさらに取り上げます。名前付きテーブル式の最適化に関しては、次の項目について混乱があります(この記事の焦点であるため、ここでは派生テーブルについて説明します):
- 永続性: 派生テーブルはどこにでも永続化されていますか?それはディスク上に永続化されますか?SQLServerはそのためのメモリをどのように処理しますか?
- 列の投影: インデックスマッチングは派生テーブルでどのように機能しますか?たとえば、派生テーブルが基になるテーブルの列の特定のサブセットを投影し、最も外側のクエリが派生テーブルの列のサブセットを投影する場合、SQL Serverは、列の最終サブセットに基づいて最適なインデックスを把握するのに十分スマートです。それは実際に必要ですか?そして、パーミッションについてはどうでしょうか。ユーザーには、内部クエリで参照されるすべての列へのアクセス許可が必要ですか、それとも実際に必要な最後の列へのアクセス許可のみが必要ですか?
- 列エイリアスへの複数の参照: 派生テーブルに非決定論的計算に基づく結果列がある場合(たとえば、関数SYSDATETIMEの呼び出し)、外部クエリにその列への複数の参照がある場合、計算は1回だけ、または外部参照ごとに個別に実行されます?
- ネスト解除/置換/インライン化: SQL Serverは、派生テーブルクエリを検出しませんか、またはインラインにしますか?つまり、SQL Serverは、元のネストされたコードをベーステーブルに直接対抗する1つのクエリに変換する置換プロセスを実行しますか?もしそうなら、このネスト解除プロセスを回避するようにSQL Serverに指示する方法はありますか?
これらはすべて重要な質問であり、これらの質問への回答はパフォーマンスに重大な影響を与えるため、SQLServerでこれらの項目がどのように処理されるかを明確に理解することをお勧めします。今月は、最初の3つの項目について説明します。 4番目の項目については多くのことを言うことがあるので、来月は別の記事を取り上げます(パート4)。
私の例では、TSQLV5というサンプルデータベースを使用します。 TSQLV5を作成してデータを取り込むスクリプトはここにあり、そのER図はここにあります。
永続性
一部の人々は、SQL Serverが派生テーブルのテーブル式部分の結果(内部クエリの結果)を作業テーブルに保持すると直感的に想定しています。この記事の執筆時点ではそうではありません。ただし、永続性の考慮事項はベンダーの選択であるため、Microsoftは将来これを変更することを決定する可能性があります。実際、SQL Serverは、クエリ処理の一部として、中間クエリ結果をワークテーブル(通常はtempdb)に保持できます。そうすることを選択した場合、プランに何らかの形式のスプール演算子(スプール、熱心なスプール、レイジースプール、テーブルスプール、インデックススプール、ウィンドウスプール、行数スプール)が表示されます。ただし、SQL Serverがワークテーブルに何かをスプールするかどうかの選択は、現在、クエリでの名前付きテーブル式の使用とは関係ありません。 SQL Serverは、繰り返しの作業を回避するなどのパフォーマンス上の理由(現在は名前付きテーブル式の使用とは関係ありません)や、ハロウィーンの保護などの他の理由で中間結果をスプールする場合があります。
前述のように、来月は派生テーブルのネスト解除の詳細について説明します。今のところ、SQL Serverは通常、ネスト解除/インライン化プロセスを派生テーブルに適用し、ネストされたクエリを基になるベーステーブルに対するクエリに置き換えます。ええと、私は少し単純化しすぎています。 SQL Serverが、派生テーブルを含む元のT-SQLクエリ文字列を、それらを含まない新しいクエリ文字列に文字通り変換するのとは異なります。むしろ、SQL Serverは、演算子の内部論理ツリーに変換を適用します。その結果、通常、派生テーブルはネストされなくなります。派生テーブルを含むクエリの実行プランを見ると、ほとんどの最適化の目的でそれらが存在しないため、それらについての言及はありません。基になるベーステーブルのデータを保持する物理構造へのアクセスが表示されます(ディスクベースのテーブルの場合はヒープ、Bツリーの行ストアインデックスと列ストアのインデックス、メモリ最適化テーブルの場合はツリーとハッシュのインデックス)。
SQL Serverが派生テーブルのネストを解除できない場合がありますが、その場合でも、SQLServerはテーブル式の結果を作業テーブルに保持しません。来月、例とともに詳細を提供します。
SQL Serverは派生テーブルを永続化せず、基になるベーステーブルのデータを保持する物理構造と直接対話するため、派生テーブルのメモリの処理方法に関する質問は重要ではありません。基になるベーステーブルがディスクベースのテーブルである場合、それらの関連ページはバッファプールで処理される必要があります。基になるテーブルがメモリ最適化されたテーブルである場合、それらの関連するメモリ内の行を処理する必要があります。ただし、これは、派生テーブルを使用せずに、基になるテーブルを自分で直接クエリする場合と同じです。したがって、ここでは特別なことは何もありません。派生テーブルを使用する場合、SQLServerはそれらに特別なメモリの考慮事項を適用する必要はありません。ほとんどのクエリ最適化の目的では、それらは存在しません。
中間ステップの結果をワークテーブルに永続化する必要がある場合は、名前付きテーブル式ではなく、一時テーブルまたはテーブル変数を使用する必要があります。
列の投影とSELECTの単語*
射影は関係代数の元々の演算子の1つです。属性x、y、zを持つリレーションR1があるとします。その属性の一部のサブセット(xとzなど)へのR1の射影は、新しい関係R2であり、その見出しはR1から射影された属性のサブセット(この場合はxとz)であり、本体はタプルのセットです。 R1のタプルから投影された属性値の元の組み合わせから形成されます。
タプルのセットであるリレーションの本体には、定義上重複がないことを思い出してください。したがって、結果のリレーションのタプルは、元のリレーションから投影された属性値の明確な組み合わせであることは言うまでもありません。ただし、SQLのテーブルの本体は行の多重集合であり、セットではないことに注意してください。通常、SQLは、指示がない限り、重複する行を削除しません。列x、y、zを持つテーブルR1が与えられた場合、次のクエリは重複する行を返す可能性があるため、関係代数の射影演算子のセットを返すセマンティクスには従いません。
SELECT x, z FROM R1;
DISTINCT句を追加することで、重複する行を排除し、リレーショナルプロジェクションのセマンティクスに厳密に従うことができます。
SELECT DISTINCT x, z FROM R1;
もちろん、クエリの結果にDISTINCT句を必要としない個別の行があることがわかっている場合もあります。たとえば、返される列のサブセットに、クエリされたテーブルのキーが含まれている場合などです。たとえば、xがR1のキーである場合、上記の2つのクエリは論理的に同等です。
とにかく、派生テーブルと列の射影を含むクエリの最適化に関して前述した質問を思い出してください。インデックスマッチングはどのように機能しますか?派生テーブルが基になるテーブルの列の特定のサブセットを投影し、最も外側のクエリが派生テーブルの列のサブセットを投影する場合、SQL Serverは、実際の列の最終サブセットに基づいて最適なインデックスを把握するのに十分スマートです。必要ですか?そして、パーミッションについてはどうでしょうか。ユーザーには、内部クエリで参照されるすべての列へのアクセス許可が必要ですか、それとも実際に必要な最後の列へのアクセス許可のみが必要ですか?また、テーブル式クエリが計算に基づく結果列を定義しているが、外部クエリはその列を投影していないとします。計算はまったく評価されていますか?
最後の質問から始めて、試してみましょう。次のクエリについて考えてみます。
USE TSQLV5; GO SELECT custid, city, 1/0 AS div0error FROM Sales.Customers;
ご想像のとおり、このクエリはゼロ除算エラーで失敗します:
メッセージ8134、レベル16、状態1ゼロ除算エラーが発生しました。
次に、上記のクエリに基づいてDという派生テーブルを定義し、外部クエリプロジェクトDで、次のようにcustidとcityのみを定義します。
SELECT custid, city
FROM ( SELECT custid, city, 1/0 AS div0error
FROM Sales.Customers ) AS D; 前述のように、SQL Serverは通常、ネスト解除/置換を適用します。このクエリにはネスト解除を禁止するものがないため(来月の詳細)、上記のクエリは次のクエリと同等です。
SELECT custid, city FROM Sales.Customers;
ここでも、少し単純化しすぎています。現実は、これら2つのクエリが完全に同一であると見なされるよりも少し複雑ですが、来月はこれらの複雑さに到達します。重要なのは、式1/0はクエリの実行プランにも表示されず、まったく評価されないため、上記のクエリはエラーなしで正常に実行されるということです。
それでも、テーブル式は有効である必要があります。たとえば、次のクエリについて考えてみます。
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; 外部クエリは内部クエリのグループ化セットから列のみを投影しますが、内部クエリはグループ化セットの一部でも集計関数にも含まれていない列を返そうとするため、無効です。このクエリは次のエラーで失敗します:
メッセージ8120、レベル16、状態1列'Sales.Customers.custid'は、集計関数またはGROUP BY句のいずれにも含まれていないため、選択リストでは無効です。
次に、インデックスマッチングの質問に取り組みましょう。外部クエリが派生テーブルの列のサブセットのみを投影する場合、SQL Serverは、返された列(およびもちろん、フィルタリングなど、他の方法で意味のある役割を果たす他の列)のみに基づいてインデックスマッチングを実行するのに十分スマートです。グループ化など)?しかし、この質問に取り組む前に、なぜ私たちがそれを気にしているのか不思議に思うかもしれません。なぜ、外部クエリが必要としない内部クエリの戻り列があるのでしょうか。
答えは簡単です。内部クエリに悪名高いSELECT*を使用させることで、コードを短縮します。 SELECT *を使用することは悪い習慣であることは誰もが知っていますが、それは主に最も外側のクエリで使用される場合に当てはまります。特定の見出しを持つテーブルをクエリし、後でその見出しが変更された場合はどうなりますか?アプリケーションにバグが発生する可能性があります。バグが発生しなくても、アプリケーションが実際には必要としない列を返すことで、不要なネットワークトラフィックを生成する可能性があります。さらに、このような場合は、本当に必要な列に基づくカバーリングインデックスが一致する可能性が低くなるため、インデックス作成の利用が最適化されません。
とはいえ、実際には、テーブル式でSELECT *を使用することは非常に快適です。とにかく、最も外側のクエリで本当に必要な列のみを投影することを知っています。論理的な観点からは、これはかなり安全ですが、いくつかの小さな注意点がありますが、これについては後ほど説明します。そのような場合にインデックスマッチングが最適に行われる限り、それは良いニュースです。
これを示すために、Sales.Ordersテーブルにクエリを実行して、各顧客の最新の3つの注文を返す必要があるとします。 custidで分割され、orderdate DESC、orderid DESCで並べ替えられた行番号(結果列rownum)を計算するクエリに基づいて、Dという派生テーブルを定義することを計画しています。外側のクエリはDからフィルタリングされます(リレーショナル制限 )rownumが3以下である行のみ、およびcustid、orderdate、orderid、およびrownumにプロジェクトD。現在、Sales.Ordersには、投影する必要のある列よりも多くの列がありますが、簡潔にするために、内部クエリでSELECT*と行番号の計算を使用する必要があります。これは安全であり、インデックスマッチングの観点から最適に処理されます。
次のコードを使用して、クエリをサポートするための最適なカバーインデックスを作成します。
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
手元のタスクをアーカイブするクエリ(クエリ1と呼びます)は次のとおりです。
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; 内部クエリのSELECT*と外部クエリの明示的な列リストに注目してください。
SentryOne Plan Explorerによってレンダリングされた、このクエリの計画を図1に示します。
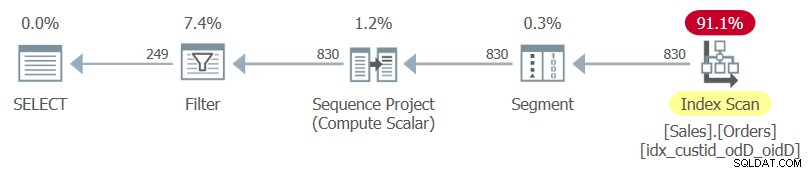 図1:クエリ1の計画
図1:クエリ1の計画
この計画で使用されている唯一のインデックスは、作成したばかりの最適なカバーインデックスであることに注意してください。
内部クエリのみを強調表示してその実行プランを調べると、使用されているテーブルのクラスター化インデックスとそれに続く並べ替え操作が表示されます。
良いニュースです。
許可に関しては、それは別の話です。最終的に不要である限り、内部クエリによって参照される列をインデックスに含める必要がないインデックスマッチングとは異なり、参照されるすべての列へのアクセス許可が必要です。
これを示すために、次のコードを使用してuser1というユーザーを作成し、いくつかの権限を割り当てます(Sales.Customersのすべての列、および上記のクエリに最終的に関連するSales.Ordersの3つの列のみに対するSELECT権限):
CREATE USER user1 WITHOUT LOGIN; GRANT SHOWPLAN TO user1; GRANT SELECT ON Sales.Customers TO user1; GRANT SELECT ON Sales.Orders(custid, orderdate, orderid) TO user1;
次のコードを実行して、user1になりすます1:
EXECUTE AS USER = 'user1';
Sales.Ordersからすべての列を選択してみてください:
SELECT * FROM Sales.Orders;
予想どおり、一部の列の権限がないため、次のエラーが発生します。
メッセージ230、レベル14、状態1オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「empid」でSELECT権限が拒否されました。
Msg 230 、レベル14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「requireddate」でSELECT権限が拒否されました。
Msg 230、Level 14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shippeddate」でSELECT権限が拒否されました。
Msg 230、レベル14状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipperid」でSELECT権限が拒否されました。
Msg 230、レベル14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「freight」でSELECT権限が拒否されました。
Msg 230、レベル14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipname」でSELECT権限が拒否されました。
Msg 230、レベル14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipaddress」でSELECT権限が拒否されました。
Msg 230、レベル14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipcity」でSELECT権限が拒否されました。
メッセージ230、レベル14、状態1
SELECTオブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipregion」でアクセス許可が拒否されました。
Msg 230、レベル14、状態1
SELECTアクセス許可はオブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shippostalcode」で拒否されました。
Msg 230、レベル14、状態1
SELECT権限が拒否されましたオブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipcountry」。
次のクエリを試して、user1が権限を持っている列のみを投影して操作します。
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; それでも、SELECT *:
を介して内部クエリによって参照される一部の列の権限がないため、列の権限エラーが発生します。 メッセージ230、レベル14、状態1オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「empid」でSELECT権限が拒否されました。
Msg 230 、レベル14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「requireddate」でSELECT権限が拒否されました。
Msg 230、Level 14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shippeddate」でSELECT権限が拒否されました。
Msg 230、レベル14状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipperid」でSELECT権限が拒否されました。
Msg 230、レベル14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「freight」でSELECT権限が拒否されました。
Msg 230、レベル14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipname」でSELECT権限が拒否されました。
Msg 230、レベル14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipaddress」でSELECT権限が拒否されました。
Msg 230、レベル14、状態1
オブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipcity」でSELECT権限が拒否されました。
メッセージ230、レベル14、状態1
SELECTオブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipregion」でアクセス許可が拒否されました。
Msg 230、レベル14、状態1
SELECTアクセス許可はオブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shippostalcode」で拒否されました。
Msg 230、レベル14、状態1
SELECT権限が拒否されましたオブジェクト「Orders」、データベース「TSQLV5」、スキーマ「Sales」の列「shipcountry」。
実際にあなたの会社で、ユーザーが操作する必要のある関連する列のみにアクセス許可を割り当てることが慣例である場合は、少し長いコードを使用し、内部クエリと外部クエリの両方で列リストを明示するのが理にかなっています。そのように:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; 今回は、クエリはエラーなしで実行されます。
ユーザーが関連する列に対してのみアクセス許可を持っている必要がある別のバリエーションは、内側のクエリのSELECTリストで列名を明示し、外側のクエリでSELECT*を使用することです。
SELECT *
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; このクエリもエラーなしで実行されます。ただし、このバージョンは、後でネストの内部レベルでいくつかの変更が行われた場合に備えて、バグが発生しやすいバージョンだと思います。前述のように、私にとってのベストプラクティスは、最も外側のクエリの列リストについて明示することです。一部の列に対する権限の欠如について懸念がない限り、内部クエリではSELECT *を使用できますが、最も外部クエリでは明示的な列リストを使用できます。特定の列のアクセス許可を適用することが会社の一般的な慣行である場合は、すべてのレベルのネストで列名を明示するのが最善です。スキーマバインディングではクエリ内のどこでもSELECT*を使用できないため、クエリがスキーマバインドオブジェクトで使用される場合は、ネストのすべてのレベルで列名を明示することが実際には必須です。
この時点で、次のコードを実行して、Sales.Ordersで以前に作成したインデックスを削除します。
DROP INDEX IF EXISTS idx_custid_odD_oidD ON Sales.Orders;
SELECT*を使用することの正当性に関して同様のジレンマを持つ別のケースがあります。 EXISTS述語の内部クエリで。
次のクエリについて考えてみます(これをクエリ2と呼びます):
SELECT custid
FROM Sales.Customers AS C
WHERE EXISTS (SELECT * FROM Sales.Orders AS O
WHERE O.custid = C.custid); このクエリの計画を図2に示します。
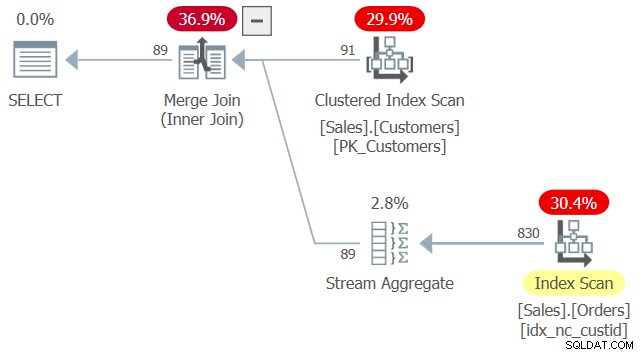 図2:クエリ2の計画
図2:クエリ2の計画
インデックスマッチングを適用する場合、オプティマイザーは、インデックスidx_nc_custidが、このクエリで唯一の真に関連する列であるcustid列を含むため、Sales.Ordersのカバーインデックスであると判断しました。これは、このインデックスにcustid以外の列が含まれておらず、EXISTS述語の内部クエリがSELECT*と言っているにもかかわらずです。これまでのところ、動作は派生テーブルでのSELECT*の使用と似ているようです。
このクエリとの違いは、user1にはSales.Ordersの一部の列に対する権限がないにもかかわらず、エラーなしで実行されることです。ここには、すべての列に権限を必要としないことを正当化する議論があります。結局のところ、EXISTS述語は一致する行の存在をチェックするだけでよいので、内部クエリのSELECTリストは実際には無意味です。このような場合、SQLがSELECTリストをまったく必要としないのがおそらく最善でしたが、その船はすでに出航しています。幸いなことに、SELECTリストは、インデックスの一致と必要な権限の両方の観点から、事実上無視されます。
また、内部クエリでSELECT *を使用すると、派生テーブルとEXISTSの間に別の違いがあるように見えます。記事の前半のこのクエリを覚えておいてください:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; 思い出してください。内部クエリが無効であるため、このコードはエラーを生成しました。
同じ内部クエリを試してください。今回はEXISTS述語でのみ(これをステートメント3と呼びます):
IF EXISTS ( SELECT *
FROM Sales.Customers
GROUP BY country )
PRINT 'This works! Thanks Dmitri Korotkevitch for the tip!'; 奇妙なことに、SQL Serverはこのコードを有効と見なし、正常に実行されます。このコードの計画を図3に示します。
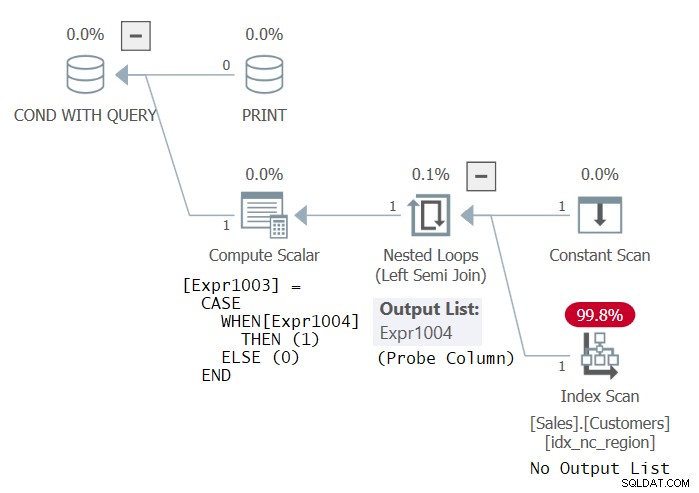 図3:ステートメント3の計画
図3:ステートメント3の計画
このプランは、内部クエリがSELECT * FROM Sales.Customers(GROUP BYなし)の場合に得られるプランと同じです。結局のところ、グループの存在をチェックしていて、行がある場合は当然グループがあります。とにかく、SQLServerがこのクエリを有効と見なしているという事実はバグだと思います。確かに、SQLコードは有効であるはずです!しかし、EXISTSクエリのSELECTリストが無視されることになっていると主張する人がいる理由はわかります。いずれにせよ、プランはプローブされた左半結合を使用します。これは列を返す必要はなく、テーブルをプローブして行の存在を確認するだけです。顧客のインデックスは任意のインデックスにすることができます。
この時点で、次のコードを実行して、user1のなりすましを停止し、削除することができます。
REVERT; DROP USER IF EXISTS user1;
ネストの内部レベルでSELECT*を使用するのが便利な方法であることがわかったという事実に戻ると、レベルが多いほど、この方法によってコードが短縮され、単純化されます。 2つのネストレベルの例を次に示します。
SELECT orderid, orderyear, custid, empid, shipperid
FROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear
FROM ( SELECT *, YEAR(orderdate) AS orderyear
FROM Sales.Orders ) AS D1 ) AS D2
WHERE orderdate = endofyear; この方法が使用できない場合があります。たとえば、次の例のように、内部クエリが共通の列名を持つテーブルを結合する場合:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Sales.CustomersとSales.Ordersの両方に、custidという列があります。 2つのテーブル間の結合に基づくテーブル式を使用して、派生テーブルDを定義しています。テーブルの見出しは列のセットであり、セットとして、列名を重複させることはできません。したがって、このクエリは次のエラーで失敗します。
メッセージ8156、レベル16、状態1列「custid」が「D」に複数回指定されました。
ここでは、内部クエリで列名を明示する必要があり、テーブルの1つだけからcustidを返すか、両方を返す場合は結果の列に一意の列名を割り当てるようにしてください。多くの場合、次のように前者のアプローチを使用します。
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; 繰り返しになりますが、次のように、内部クエリで列名を明示し、外部クエリでSELECT*を使用できます。
SELECT *
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; ただし、前述したように、最も外側のクエリで列名を明示しないことは悪い習慣だと思います。
列エイリアスへの複数の参照
次の項目、つまり派生テーブル列への複数の参照に進みましょう。派生テーブルに非決定論的計算に基づく結果列があり、外部クエリにその列への複数の参照がある場合、計算は参照ごとに1回だけ評価されますか、それとも個別に評価されますか?
クエリ内の同じ非決定論的関数への複数の参照は、独立して評価されることになっているという事実から始めましょう。例として次のクエリを考えてみましょう。
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2;
このコードは、2つの異なるGUIDを示す次の出力を生成します。
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406
逆に、非決定的な計算に基づく列を持つ派生テーブルがあり、外部クエリにその列への複数の参照がある場合、計算は1回だけ評価されることになっています。次のクエリについて考えてみます(これをクエリ4と呼びます):
SELECT mynewid AS mynewid1, mynewid AS mynewid2 FROM ( SELECT NEWID() AS mynewid ) AS D;
このクエリの計画を図4に示します。
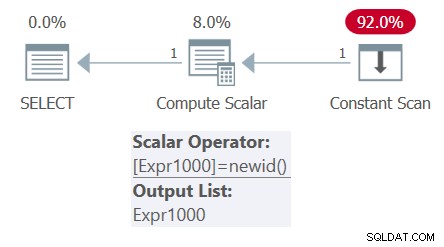 図4:クエリ4の計画
図4:クエリ4の計画
プランにはNEWID関数の呼び出しが1つしかないことに注意してください。したがって、出力には同じGUIDが2回表示されます。
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74A
したがって、上記の2つのクエリは論理的に同等ではなく、インライン化/置換が行われない場合があります。
一部の非決定論的関数では、クエリ内の複数の呼び出しが別々に処理されることを示すのは少し難しいです。例としてSYSDATETIME関数を取り上げます。精度は100ナノ秒です。次のようなクエリが実際に2つの異なる値を表示する可能性はどのくらいありますか?
SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;
退屈している場合は、それが起こるまでF5を繰り返し押すことができます。時間に関してもっと重要なことがある場合は、次のようにループを実行することをお勧めします。
DECLARE @i AS INT = 1;
WHILE EXISTS( SELECT *
FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; たとえば、このコードを実行すると、1971年になりました。
非決定論的関数が1回だけ呼び出され、複数のクエリ参照で同じ値に依存するようにする場合は、関数の呼び出しに基づいて列を使用してテーブル式を定義し、その列への複数の参照があることを確認してください同様に、外部クエリから(これをクエリ5と呼びます):
SELECT mydt AS mydt1, mydt AS mydt1 FROM ( SELECT SYSDATETIME() AS mydt ) AS D;
このクエリの計画を図5に示します。
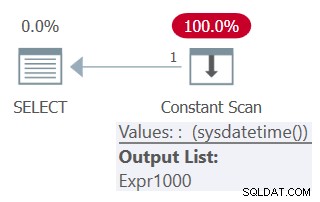 図5:クエリ5の計画
図5:クエリ5の計画
計画では、関数が1回だけ呼び出されることに注意してください。
Now this could be a really interesting exercise in patients to hit F5 repeatedly until you get two different values. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT = 1;
WHILE EXISTS ( SELECT *
FROM (SELECT mydt AS mydt1, mydt AS mydt2
FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT
CASE
WHEN RAND() < 0.5
THEN STR(RAND(), 5, 3) + ' is less than half.'
ELSE STR(RAND(), 5, 3) + ' is at least half.'
END; Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."
Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT
CASE
WHEN rnd < 0.5
THEN STR(rnd, 5, 3) + ' is less than half.'
ELSE STR(rnd, 5, 3) + ' is at least half.'
END
FROM ( SELECT RAND() AS rnd ) AS D; 概要
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.