この記事は、テーブル式に関するシリーズの第4部です。第1部と第2部では、派生テーブルの概念的な扱いについて説明しました。パート3では、派生テーブルの最適化に関する考慮事項について説明し始めました。今月は、派生テーブルの最適化のさらなる側面について説明します。具体的には、派生テーブルの置換/ネスト解除に焦点を当てています。
私の例では、TSQLV5およびPerformanceV5と呼ばれるサンプルデータベースを使用します。 TSQLV5を作成してデータを取り込むスクリプトはここにあり、そのER図はここにあります。 PerformanceV5を作成して設定するスクリプトはここにあります。
ネスト解除/置換
テーブル式のネスト解除/置換は、テーブル式のネストを含むクエリを取得するプロセスであり、ネストされたロジックが削除されたクエリで置換するかのようになります。実際には、SQLServerがネストされたロジックを含む元のクエリ文字列をネストしない新しいクエリ文字列に変換する実際のプロセスはないことを強調する必要があります。実際に発生するのは、クエリ解析プロセスによって、元のクエリを厳密に反映した論理演算子の初期ツリーが生成されることです。次に、SQL Serverはこのクエリツリーに変換を適用し、不要な手順の一部を削除し、複数の手順をより少ない手順にまとめ、演算子を移動します。その変換では、特定の条件が満たされている限り、SQL Serverは、元々テーブル式の境界であったものを超えて、ネストされたユニットを削除するかのように効果的にシフトできます。これらはすべて、最適な計画を見つけるためのものです。
この記事では、このようなネスト解除が行われる場合と、ネスト解除阻害剤の両方について説明します。つまり、特定のクエリ要素を使用すると、SQL Serverがクエリツリー内の論理演算子を移動できなくなり、元のクエリで使用されているテーブル式の境界に基づいて演算子を処理するように強制されます。
まず、派生テーブルがネストされない簡単な例を示します。また、ネストされていない阻害剤の例も示します。次に、ネスト解除が望ましくなく、エラーまたはパフォーマンスの低下を引き起こす可能性がある異常なケースについて説明し、ネスト解除抑制剤を使用して、これらのケースでネスト解除を防止する方法を示します。
次のクエリ(クエリ1と呼びます)は、派生テーブルのネストされた複数のレイヤーを使用します。各テーブル式は、定数に基づく基本的なフィルタリングロジックを適用します。
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; ご覧のとおり、各テーブル式は、異なる日付で始まる一連の注文日をフィルタリングします。 SQL Serverは、この多層クエリロジックのネストを解除します。これにより、4つのフィルタリング述語を4つの述語すべての共通部分を表す単一の述語にマージできます。
図1に示すクエリ1の計画を調べます。
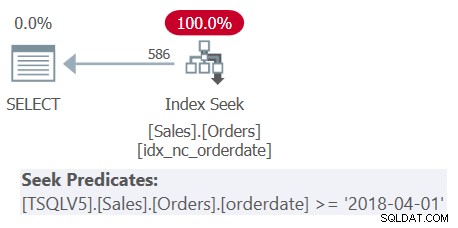 図1:クエリ1の計画
図1:クエリ1の計画
4つのフィルタリング述語すべてが4つの共通部分を表す単一の述語にマージされたことを確認してください。プランは、シーク述語として単一のマージされた述部に基づいて、インデックスidx_nc_orderdateにシークを適用します。このインデックスは、orderdate(明示的に)、orderid(orderidにクラスター化されたインデックスが存在するために暗黙的に)にインデックスキーとして定義されます。
また、すべてのテーブル式がSELECT *を使用し、最も外側のクエリのみが対象の2つの列(orderdateとorderid)を投影している場合でも、前述のインデックスはカバーしていると見なされることに注意してください。パート3で説明したように、インデックスの選択などの最適化の目的で、SQLServerは最終的に関連性のないテーブル式の列を無視します。ただし、これらの列をクエリするには権限が必要です。
前述のように、SQL Serverはテーブル式のネストを解除しようとしますが、ネスト解除の阻害要因に遭遇した場合はネスト解除を回避します。後で説明する特定の例外を除いて、TOPまたはOFFSETFETCHを使用するとネスト解除が禁止されます。その理由は、TOPまたはOFFSET FETCHを使用してテーブル式をアンネストしようとすると、元のクエリの意味が変わる可能性があるためです。
例として、次のクエリ(クエリ2と呼びます)を考えてみましょう。
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; TOPフィルターへの入力行数は、BIGINT型の値です。この例では、最大のBIGINT値(2 ^ 63 – 1、SELECT POWER(2。、63)– 1を使用してT-SQLで計算)を使用しています。 Ordersテーブルにこれほど多くの行が含まれることはないため、TOPフィルターは実際には無意味ですが、SQL Serverは、フィルターが意味を持つための理論上の可能性を考慮に入れる必要があります。したがって、SQLServerはこのクエリのテーブル式を検出しません。クエリ2の計画を図2に示します。
 図2:クエリ2の計画
図2:クエリ2の計画
ネスト解除の阻害要因により、SQL Serverはフィルタリング述語をマージできず、プランの形状が概念クエリにより近くなりました。ただし、SQL Serverが、最終的に最も外側のクエリに関連しない列を無視しているため、orderdate、orderidでカバーインデックスを使用できたことを確認するのは興味深いことです。
TOPとOFFSET-FETCHがネスト解除の阻害要因である理由を説明するために、簡単な述語プッシュダウン最適化手法を取り上げましょう。述部プッシュダウンとは、オプティマイザーがフィルター述部を、論理照会処理で表示される元のポイントと比較して前のポイントにプッシュすることを意味します。たとえば、内部結合と、結合のいずれかの側の列に基づくWHEREフィルターの両方を含むクエリがあるとします。論理クエリ処理に関しては、WHEREフィルターは結合後に評価されることになっています。ただし、多くの場合、オプティマイザーはフィルター述部を結合の前のステップにプッシュします。これにより、結合で処理する行が少なくなり、通常、より最適なプランが得られるためです。ただし、このような変換は、正しい結果セットを確実に取得できるという意味で、元のクエリの意味が保持されている場合にのみ許可されることに注意してください。
次のコードについて考えてみます。このコードには、派生テーブルに対するWHEREフィルターを使用した外部クエリがあり、これはTOPフィルターを使用したテーブル式に基づいています。
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders ) AS D
WHERE orderdate >= '20180101'; もちろん、このクエリは、テーブル式にORDER BY句がないため、非決定的です。実行したとき、SQL Serverは2018年より前の注文日で最初の3行にアクセスしたため、出力として空のセットを取得しました:
orderid orderdate ----------- ---------- (0 rows affected)
前述のように、テーブル式でTOPを使用すると、ここでテーブル式のネスト解除/置換ができなくなりました。 SQL Serverがテーブル式のネストを解除した場合、置換プロセスは次のクエリと同等の結果になります。
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101';
このクエリも、ORDER BY句がないため非決定的ですが、明らかに、元のクエリとは異なる意味を持っています。 Sales.Ordersテーブルに2018年以降に少なくとも3つの注文があった場合、元のクエリとは異なり、このクエリは必ず3つの行を返します。このクエリを実行したときに得られた結果は次のとおりです。
orderid orderdate ----------- ---------- 10400 2018-01-01 10401 2018-01-01 10402 2018-01-02 (3 rows affected)>
上記の2つのクエリの非決定論的な性質が混乱を招く場合に備えて、決定論的なクエリの例を次に示します。
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderid ) AS D
WHERE orderdate >= '20170708'
ORDER BY orderid; テーブル式は、IDが最も低い3つの注文をフィルタリングします。次に、外部クエリは、2017年7月8日以降に行われた注文のみをこれらの3つの注文からフィルタリングします。対象となる注文は1つだけであることがわかります。このクエリは次の出力を生成します:
orderid orderdate ----------- ---------- 10250 2017-07-08 (1 row affected)
SQL Serverが元のクエリのテーブル式のネストを解除し、置換プロセスによって次の同等のクエリが生成されたとします。
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20170708' ORDER BY orderid;
このクエリの意味は、元のクエリとは異なります。このクエリは、最初に2017年7月8日以降に行われた注文をフィルタリングし、次に、注文IDが最も低い注文の上位3つをフィルタリングします。このクエリは次の出力を生成します:
orderid orderdate ----------- ---------- 10250 2017-07-08 10251 2017-07-08 10252 2017-07-09 (3 rows affected)>
元のクエリの意味が変更されないようにするため、SQLServerはここでネスト解除/置換を適用しません。
最後の2つの例では、WHEREフィルタリングとTOPフィルタリングを単純に組み合わせていますが、ネストを解除すると、競合する要素が追加される可能性があります。たとえば、次の例のように、テーブル式と外部クエリで異なる順序指定がある場合はどうなりますか。
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC ) AS D
ORDER BY orderid; SQL Serverがテーブル式のネストを解除し、2つの異なる順序指定を1つにまとめた場合、結果のクエリは元のクエリとは異なる意味を持つことになります。間違った行をフィルタリングしたか、結果の行を間違った表示順序で表示した可能性があります。つまり、SQL Serverが安全に実行できるのは、TOPおよびOFFSET-FETCHクエリに基づくテーブル式のネスト解除/置換を回避することである理由を理解できます。
TOPとOFFSET-FETCHを使用するとネスト解除が防止されるという規則には例外があることを前述しました。これは、ORDER BY句の有無にかかわらず、ネストされたテーブル式でTOP(100)PERCENTを使用する場合です。 SQL Serverは、実際のフィルタリングが行われていないことを認識し、オプションを最適化します。これを示す例を次に示します。
SELECT orderid, orderdate
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; TOPフィルターは無視され、ネストが解除され、図1のクエリ1で前に示したものと同じプランが得られます。
ネストされたテーブル式でFETCH句を指定せずにOFFSET0ROWSを使用する場合、実際のフィルタリングも実行されません。したがって、理論的にはSQL Serverもこのオプションを最適化し、ネスト解除を有効にすることができますが、この記事の執筆時点ではそうではありません。これを示す例を次に示します。
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1
WHERE orderdate >= '20180201'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2
WHERE orderdate >= '20180301'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3
WHERE orderdate >= '20180401'; 図2のクエリ2で前に示したものと同じ計画が得られ、ネスト解除が行われなかったことを示しています。
先ほど、ネスト解除/置換プロセスは、最適化される新しいクエリ文字列を実際には生成せず、SQLServerが論理演算子のツリーに適用する変換に関係していることを説明しました。 SQL Serverがネストされたテーブル式を使用してクエリを最適化する方法と、ネストされていない実際の論理的に同等のクエリとの間には違いがあります。派生テーブルなどのテーブル式やサブクエリを使用すると、単純なパラメーター化が妨げられます。記事の前半で示したクエリ1を思い出してください:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; クエリは派生テーブルを使用するため、単純なパラメータ化は行われません。つまり、SQL Serverは定数をパラメータに置き換えずにクエリを最適化し、クエリを定数で最適化します。定数に基づく述語を使用すると、SQL Serverは交差する期間をマージできます。この場合、図1で示したように、プラン内に単一の述語が生成されます。
次に、次のクエリ(クエリ3と呼びます)を検討します。これは、クエリ1と論理的に同等ですが、ネスト解除を自分で適用します。
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401';
このクエリの計画を図3に示します。
 図3:クエリ3の計画
図3:クエリ3の計画
この計画は単純なパラメーター化に対して安全であると考えられているため、定数はパラメーターに置き換えられ、その結果、述語はマージされません。もちろん、パラメーター化の動機は、使用する定数のみが異なる同様のクエリを実行するときに、プランが再利用される可能性を高めることです。
前述のように、クエリ1で派生テーブルを使用すると、単純なパラメータ化が妨げられました。同様に、サブクエリを使用すると、単純なパラメータ化が妨げられます。たとえば、WHERE句に追加されたサブクエリに基づく意味のない述語を使用した以前のクエリ3は次のとおりです。
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401' AND (SELECT 42) = 42;
今回は単純なパラメーター化が行われないため、SQL Serverは、述語で表される交差する期間を定数とマージできるため、図1で前述したのと同じ計画になります。
定数を使用するテーブル式を使用するクエリがあり、SQL Serverがコードをパラメーター化することが重要であり、何らかの理由で自分でパラメーター化できない場合は、プランガイドで強制パラメーター化を使用するオプションがあることに注意してください。例として、次のコードはクエリ3のそのような計画ガイドを作成します:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX);
EXEC sys.sp_get_query_template
@querytext = N'SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= ''20180101'' ) AS D1
WHERE orderdate >= ''20180201'' ) AS D2
WHERE orderdate >= ''20180301'' ) AS D3
WHERE orderdate >= ''20180401'';',
@templatetext = @stmt OUTPUT,
@parameters = @params OUTPUT;
EXEC sys.sp_create_plan_guide
@name = N'TG1',
@stmt = @stmt,
@type = N'TEMPLATE',
@module_or_batch = NULL,
@params = @params,
@hints = N'OPTION(PARAMETERIZATION FORCED)'; プランガイドを作成した後、クエリ3を再度実行します。
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; パラメータ化された述語を使用して、図3で前に示したものと同じプランを取得します。
完了したら、次のコードを実行してプランガイドを削除します。
EXEC sys.sp_control_plan_guide @operation = N'DROP', @name = N'TG1';
ネスト解除の防止
SQL Serverは、最適化の理由でテーブル式をネスト解除することに注意してください。目標は、ネストを解除しない場合と比較して、より低コストのプランを見つける可能性を高めることです。これは、オプティマイザによって適用されるほとんどの変換ルールに当てはまります。ただし、ネスト解除を防止したいという珍しいケースがいくつかある可能性があります。これは、エラーを回避するため(はい、いくつかのまれなケースではネストを解除するとエラーが発生する可能性があります)、または他のパフォーマンスヒントを使用する場合と同様に、パフォーマンス上の理由で特定のプランの形状を強制するためです。非常に多くのTOPを使用してネスト解除を禁止する簡単な方法があることを忘れないでください。
エラーを回避するための例
まず、テーブル式のネストを解除するとエラーが発生する可能性がある場合から始めます。
次のクエリを検討してください(これをクエリ4と呼びます):
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
この例は、2番目のフィルター述語を簡単に書き直してエラー(割引<0.1)が発生しないという意味で少し工夫されていますが、私のポイントを説明するのに便利な例です。割引はマイナスではありません。したがって、割引がゼロの注文明細がある場合でも、クエリはそれらを除外することになっています(最初のフィルター述語は、割引がテーブルの最小割引よりも大きくなければならないことを示しています)。ただし、SQL Serverが書面による順序で述語を評価するという保証はないため、短絡を当てにすることはできません。
図4に示すクエリ4の計画を調べます。
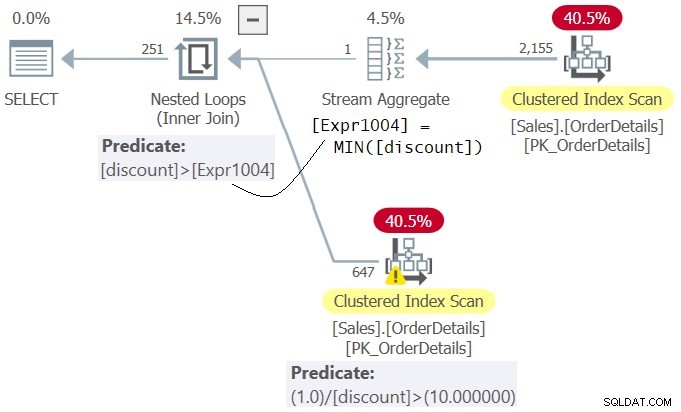 図4:クエリ4の計画
図4:クエリ4の計画
プランでは、述語1.0 / discount> 10.0(WHERE句の2番目)が述語discount>
Msg 8134, Level 16, State 1 Divide by zero error encountered.
おそらく、派生テーブルを使用して、フィルタリングタスクを内部タスクと外部タスクに分離することで、エラーを回避できると考えているかもしれません。
SELECT orderid, productid, discount
FROM ( SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; ただし、SQL Serverは派生テーブルのネスト解除を適用するため、図4で前述したのと同じ計画が作成され、その結果、このコードもゼロ除算エラーで失敗します。
Msg 8134, Level 16, State 1 Divide by zero error encountered.
ここでの簡単な修正は、そのようなネスト解除阻害剤を導入することです(このソリューションをクエリ5と呼びます):
SELECT orderid, productid, discount
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; クエリ5の計画を図5に示します。
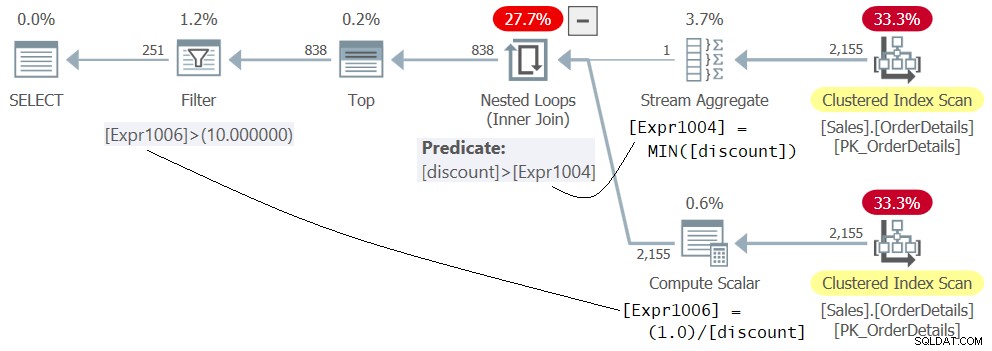 図5:クエリ5の計画
図5:クエリ5の計画
式1.0/discountが、最初に評価されるかのように、ネストされたループ演算子の内部に表示されるという事実と混同しないでください。これは、メンバーExpr1006の定義にすぎません。述語Expr1006>10.0の実際の評価は、最小割引の行が以前にネストされたループオペレーターによってフィルターで除外された後、プランの最後のステップとしてフィルターオペレーターによって適用されます。このソリューションはエラーなしで正常に実行されます。
パフォーマンス上の理由による例
テーブル式のネストを解除するとパフォーマンスが低下する可能性がある場合を続行します。
次のコードを実行して、コンテキストをPerformanceV5データベースに切り替え、STATISTICSIOとTIMEを有効にすることから始めます。
USE PerformanceV5; SET STATISTICS IO, TIME ON;
次のクエリを検討してください(これをクエリ6と呼びます):
SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid;
オプティマイザは、shipperidとorderdateを先頭キーとしてサポートするカバーリングインデックスを識別します。したがって、図6のクエリ6の計画に示すように、インデックスの順序付きスキャンとそれに続く順序ベースのStreamAggregate演算子を使用して計画を作成します。
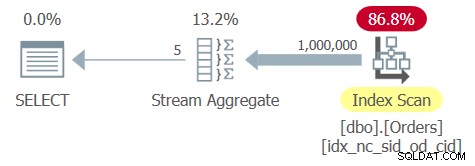 図6:クエリ6の計画
図6:クエリ6の計画
Ordersテーブルには1,000,000行があり、グループ化列のshipperidは非常に密集しています。5つの個別の荷送人IDしかないため、密度は20%(個別の値あたりの平均パーセント)になります。インデックスリーフのフルスキャンを適用するには、数千ページを読み取る必要があり、システムでの実行時間は約3分の1秒になります。このクエリの実行で得られたパフォーマンス統計は次のとおりです。
CPU time = 344 ms, elapsed time = 346 ms, logical reads = 3854
インデックスツリーは現在、3レベルの深さです。
注文数を1,000から1,000,000,000の係数でスケーリングしますが、それでも5人の個別の荷送人しかいません。インデックスリーフのページ数は1,000倍に増加し、インデックスツリーはおそらく1つの余分なレベル(4レベルの深さ)になります。この計画には線形スケーリングがあります。最終的には、4,000,000近くの論理読み取りと、数分の実行時間になります。
グループ化列に非常に高密度で(重要!)、グループ化列と集計列にキーが設定されたサポートBツリーインデックスを持つ大きなテーブルに対してMINまたはMAX集計を計算する必要がある場合は、はるかに最適です。図6の平面形状よりも平面形状を想像してください。荷送人テーブルのインデックスから荷送人IDの小さなセットをスキャンし、ループ内で各荷送人に注文のサポートインデックスに対するシークを適用して集計を取得します。テーブルに1,000,000行ある場合、5回のシークには15回の読み取りが含まれます。 1,000,000,000行の場合、5回のシークには20回の読み取りが含まれます。 1兆行で、合計25回の読み取りが行われます。明らかに、はるかに最適な計画です。このような計画は、Shippersテーブルにクエリを実行し、Ordersに対してスカラー集計サブクエリを使用して集計を取得することで実際に実現できます(このソリューションをクエリ7と呼びます):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid = S.shipperid) AS maxod FROM dbo.Shippers AS S;
このクエリの計画を図7に示します。
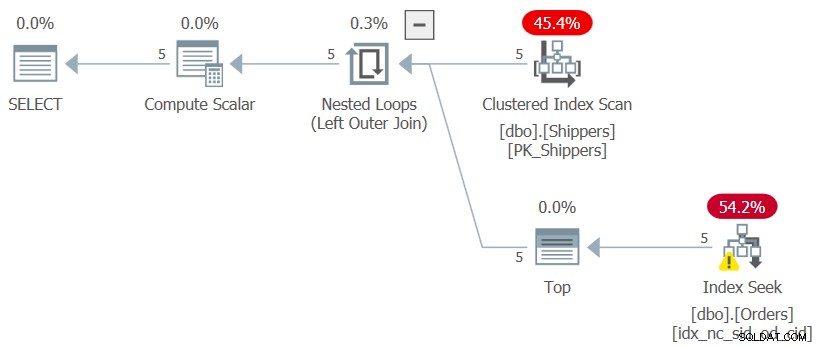 図7:クエリ7の計画
図7:クエリ7の計画
目的の計画の形が達成され、このクエリを実行するためのパフォーマンスの数値は予想どおり無視できます。
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
グループ化列が非常に密集している限り、Ordersテーブルのサイズは実質的に重要ではなくなります。
しかし、祝う前に少し待ってください。 Ordersテーブルの関連する最大注文日が2018年以降である荷送人のみを保持する必要があります。単純な追加のように聞こえます。クエリ7に基づいて派生テーブルを定義し、次のように外部クエリにフィルタを適用します(このソリューションをクエリ8と呼びます):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; 残念ながら、SQL Serverは、派生テーブルクエリとサブクエリのネストを解除し、集約ロジックをグループ化されたクエリロジックと同等のものに変換し、shipperidをグループ化列として使用します。また、SQL Serverがグループ化されたクエリを最適化することを認識する方法は、入力データの1回のパスに基づいており、追加のフィルターを除いて、図6で前に示したものと非常によく似た計画になります。クエリ8の計画を図8に示します。
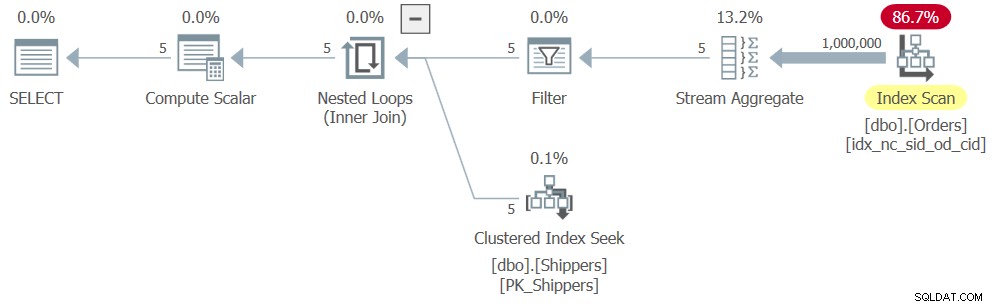 図8:クエリ8の計画
図8:クエリ8の計画
その結果、スケーリングは線形になり、パフォーマンスの数値はクエリ6の数値と同様になります。
CPU time = 328 ms, elapsed time = 325 ms, logical reads = 3854
修正は、ネストされていない抑制剤を導入することです。これは、派生テーブルの基になっているテーブル式にTOPフィルターを追加することで実行できます(このソリューションをクエリ9と呼びます):
SELECT shipperid, maxod
FROM ( SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; このクエリの計画を図9に示します。これは、シークを使用した目的の計画形状です。
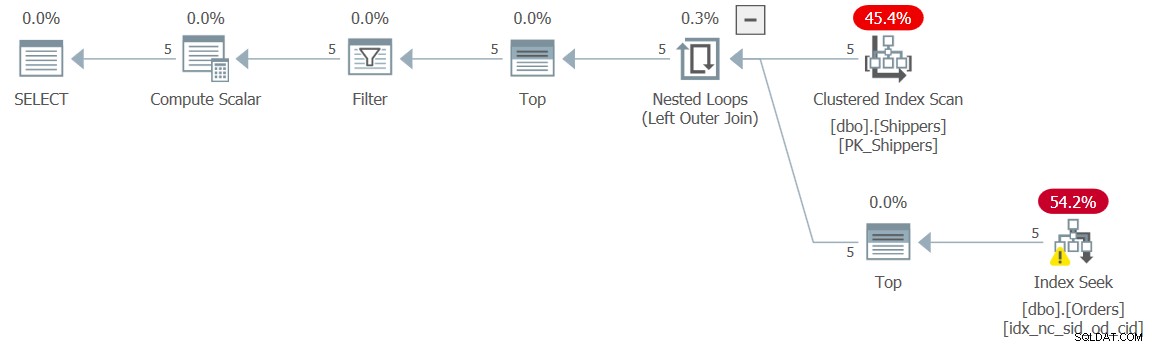 図9:クエリ9の計画
図9:クエリ9の計画
もちろん、この実行のパフォーマンス数値はごくわずかです。
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
さらに別のオプションは、MAX集計を同等のTOP(1)フィルターに置き換えることで、サブクエリのネストを防ぐことです(このソリューションをクエリ10と呼びます):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; このクエリの計画を図10に示します。これも、シークで目的の形状になっています。
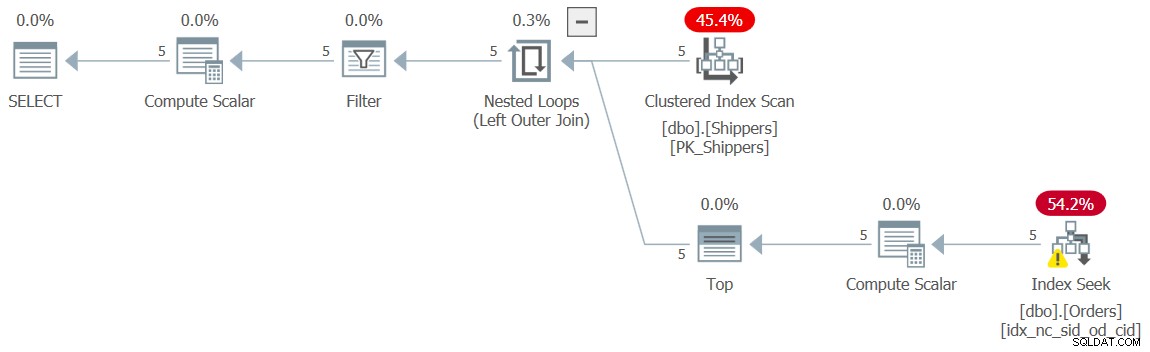 図10:クエリ10の計画
図10:クエリ10の計画
この実行では、おなじみの無視できるパフォーマンスの数値が得られました:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
完了したら、次のコードを実行してパフォーマンス統計のレポートを停止します。
SET STATISTICS IO, TIME OFF;
概要
この記事では、先月開始した派生テーブルの最適化についての議論を続けました。今月は、派生テーブルのネスト解除に焦点を当てました。通常、ネストを解除すると、ネストを解除しない場合に比べて最適なプランが得られることを説明しましたが、望ましくない例についても説明しました。ネストを解除するとエラーが発生する例と、パフォーマンスが低下する例を示しました。 TOPのような入れ子のない抑制剤を適用することによって入れ子のないことを防ぐ方法を示しました。
来月は、名前付きテーブル式の調査を続け、焦点をCTEに移します。