転換点は、SQLServerのパフォーマンスチューニングの第一人者であり長年のSentryOne諮問委員会のメンバーであるKimberlyTrippが最初に使用した用語です。彼女は、ここにすばらしいブログシリーズを掲載しています。転換点は、クエリプランが非カバー非クラスター化インデックスの検索からクラスター化インデックスまたはヒープのスキャンに「転換」するしきい値です。他にもさまざまな影響要因があるため、厳格なルールではない基本的な式は次のとおりです。
- クラスター化インデックス(またはテーブル)スキャンは、推定行がテーブルのページ数の33%を超えるとよく発生します
- 非クラスター化シークプラスキールックアップは、推定行がテーブルのページの25%未満の場合によく発生します
- 25%から33%の間で、どちらの方向にも進むことができます
カバーの場合など、他のオプティマイザの「転換点」があることに注意してください。 インデックス シークからスキャンへ、またはクエリが並列になる場合にチップしますが、私たちが焦点を当てているのは、非カバー非クラスター化インデックスです。 シナリオが最も一般的である傾向があるため、すべてのクエリを網羅するのは困難です。また、パフォーマンスにとって最も危険である可能性があります。誰かがSQL Serverインデックスの転換点を参照していると聞いた場合、これは通常、その意味です。
以前のPlanExplorerバージョンの転換点
Plan Explorerは、パラメータスニッフィングがインデックス分析で機能している場合の転換点の正味の効果を以前に示しました。 タブ、特に Est(imated)Operation パラメータの行 ペイン:
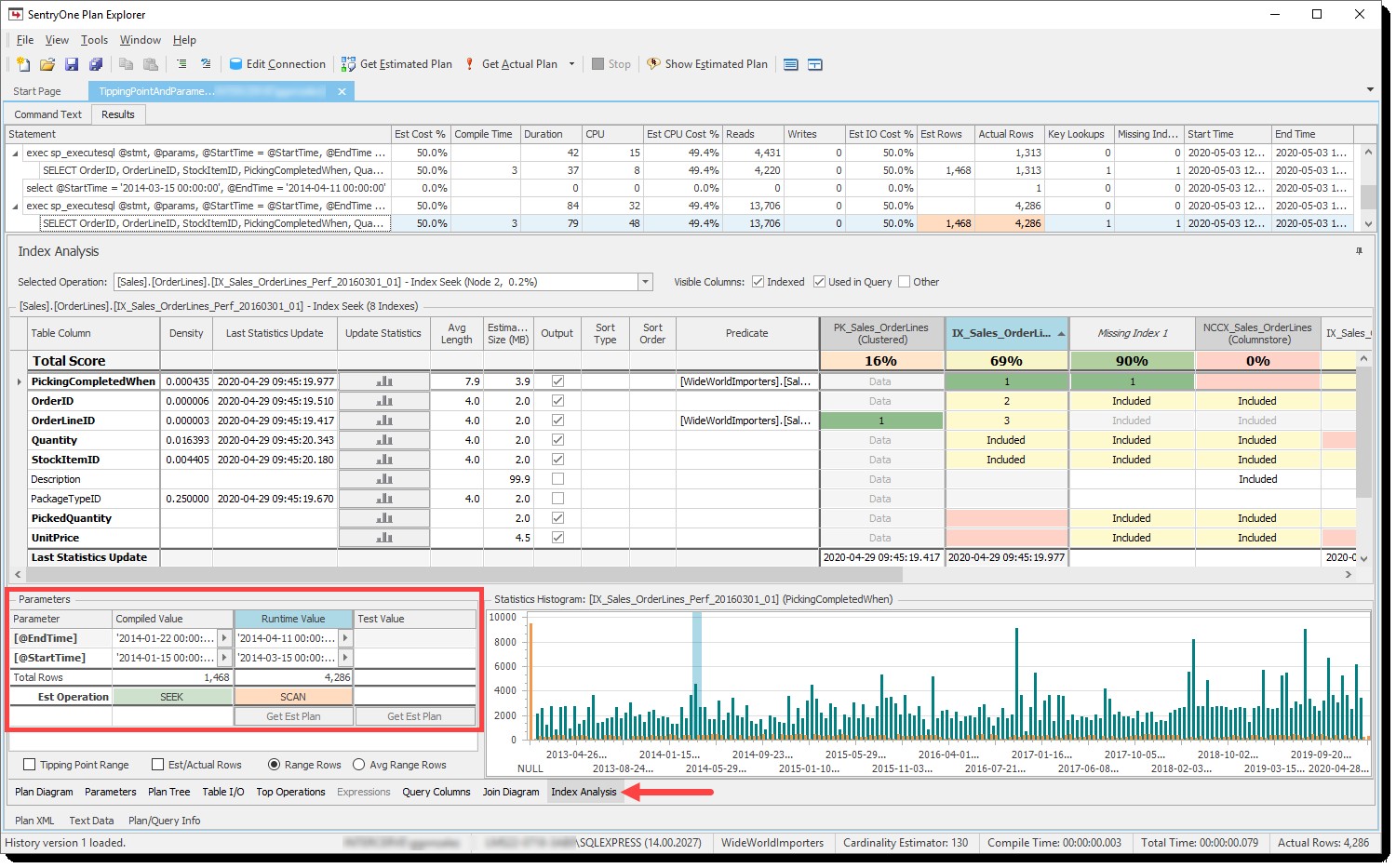 行数に基づいた、コンパイル済みパラメーターとランタイムパラメーターの推定操作
行数に基づいた、コンパイル済みパラメーターとランタイムパラメーターの推定操作
インデックス分析モジュールをまだ検討していない場合は、検討することをお勧めします。プラン図やその他のプランエクスプローラーの機能は優れていますが、率直に言って、インデックス分析は、クエリとインデックスを調整するときにほとんどの時間を費やす必要がある場所です。 Aaron Bertrandによる機能とシナリオの詳細なレビューと、DevonLeannWilsonによる優れたカバーインデックスチュートリアルをここで確認してください。
舞台裏では、転換点の計算を行い、コンパイルされたパラメーターと実行時パラメーターの両方について、テーブル内の推定行数とページ数に基づいてインデックス操作(シークまたはスキャン)を予測し、関連するセルを次のように色分けします。それらが一致するかどうかをすばやく確認できます。そうでない場合は、上記の例のように、パラメータスニッフィングに問題があることを示す強力な指標となる可能性があります。
統計ヒストグラム グラフは、等しい行(オレンジ)と範囲行(ティール)の列を使用して、インデックスの先頭キーの値の分布を反映しています。これらは、 DBCC SHOW_STATISTICSから取得する値と同じです。 またはsys.dm_db_stats_histogram 。コンパイルされたパラメーターと実行時パラメーターの両方がヒットするディストリビューションの部分が強調表示され、それぞれに含まれる行の数がおおよそわかります。 コンパイル済みの値のいずれかを選択するだけです または実行時の値 選択した範囲を表示する列:
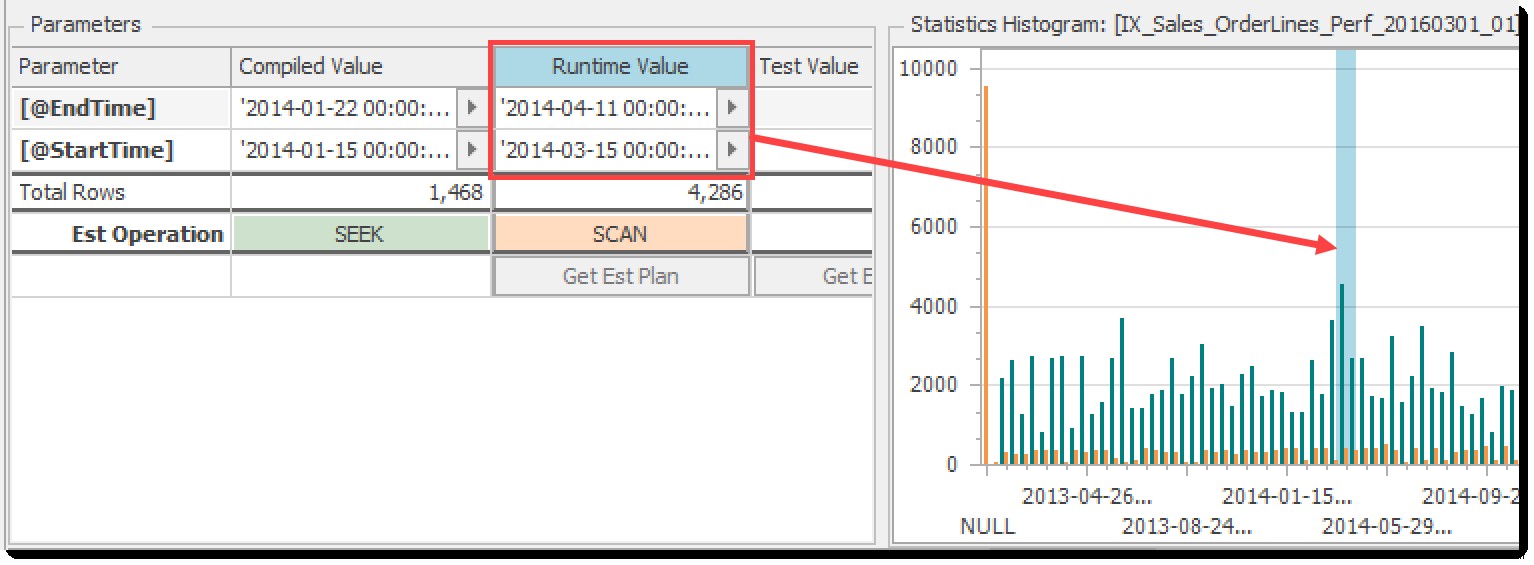 ランタイムパラメータがヒットする範囲を示すヒストグラムチャート
ランタイムパラメータがヒットする範囲を示すヒストグラムチャート
新しいコントロールとビジュアル
上記の機能は素晴らしかったですが、しばらくの間、物事をより明確にするためにできることがもっとあると感じました。そのため、Plan Explorerの最新リリース(2020.8.7)では、[パラメーター]ペインの下部に、ヒストグラムチャートに関連するビジュアルを含むいくつかの新しいコントロールがあります。
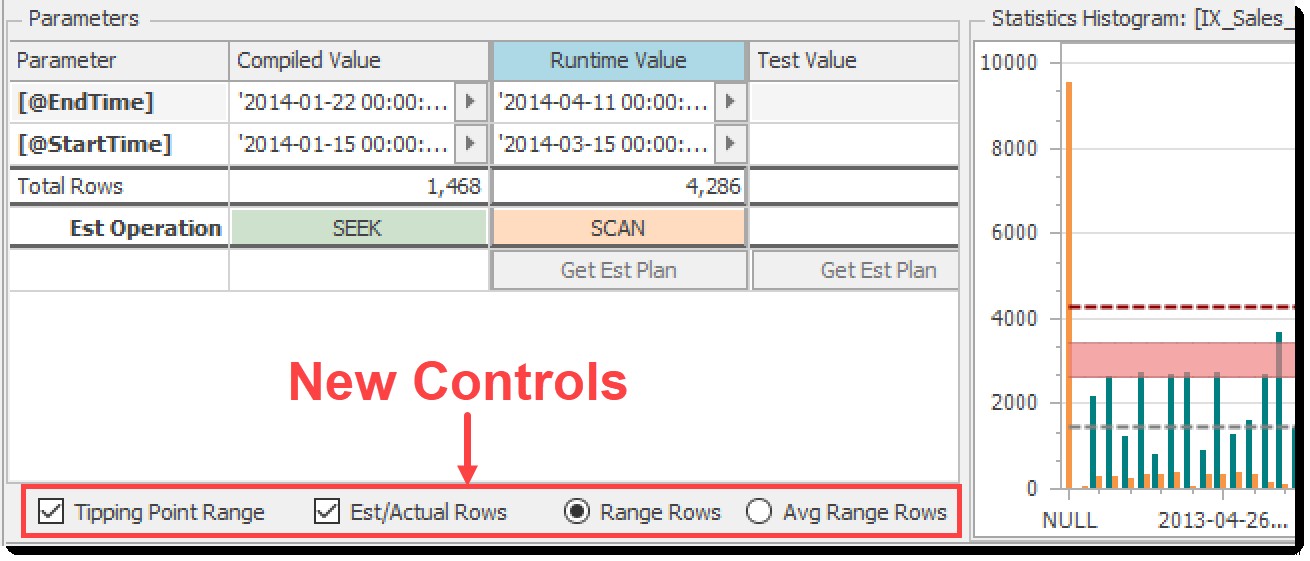 ヒストグラムビジュアルの新しいコントロール
ヒストグラムビジュアルの新しいコントロール
デフォルトで表示されるヒストグラムは、クエリが選択したテーブルにアクセスするために使用するインデックス用ですが、グリッド内の他のインデックスヘッダーまたはテーブル列をクリックすると、別のヒストグラムを表示できます。
転換点の範囲
転換点の範囲 チェックボックスをオンにすると、ヒストグラムチャートに表示される明るい赤のバンドが切り替わります。
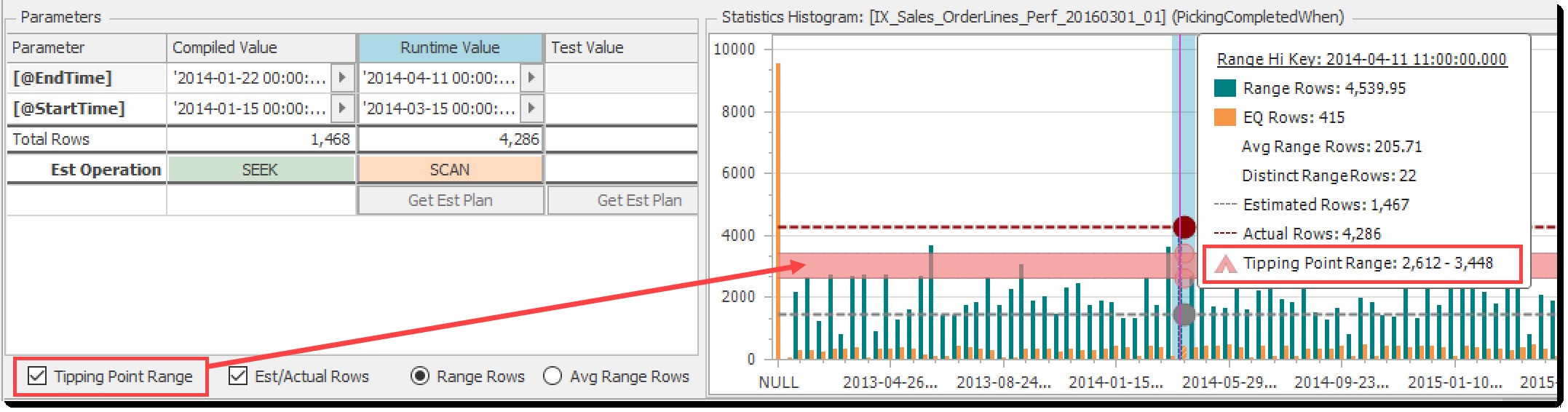
推定された行がこの範囲を下回っている場合、オプティマイザーはシーク+ルックアップを優先し、その上でテーブルスキャンを実行します。範囲内は誰の推測でもあります。
Est(imated)/実際の行
Est / Actual Rows チェックボックスは、(コンパイルされたパラメーターからの)推定行と(ランタイムパラメーターからの)実際の行の表示を切り替えます。下のグラフの矢印は、このコントロールと関連する要素の関係を示しています。
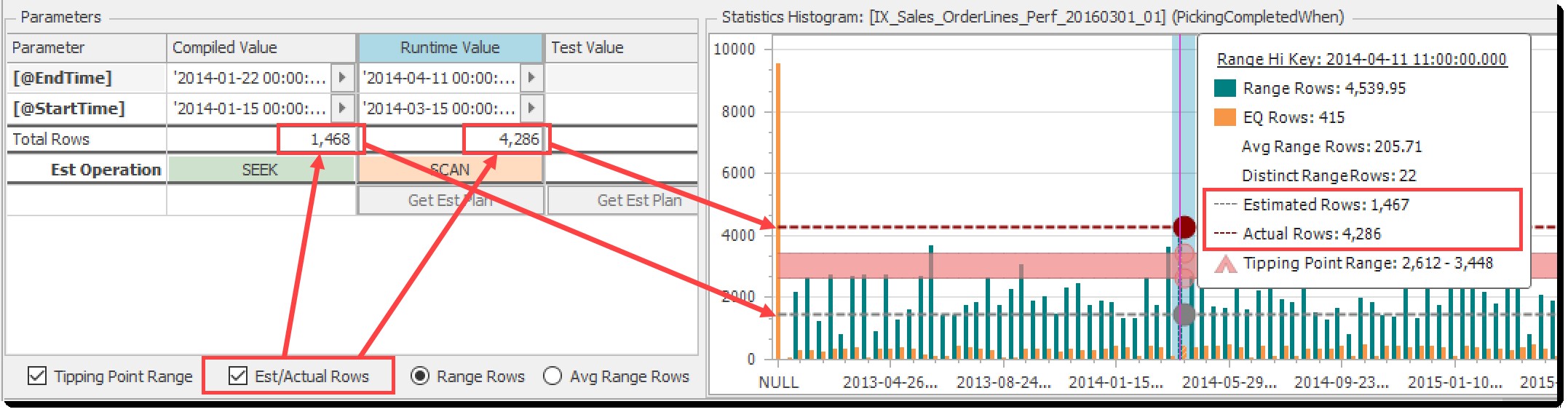
この例では、推定された行が転換点より下にあり、返される実際の行が転換点より上にあることは明らかです。これは、リストされた推定操作と実際の操作(シークとスキャン)の違いに反映されます。これは古典的なパラメータスニッフィングであり、図解されています!
将来の投稿では、これが計画図とステートメントグリッドに表示されるものとどのように相関するかを掘り下げます。それまでの間、この例(seek-to-scanパラメータースニッフィング)とscan-to-seekの例を含むPlanExplorerセッションファイルを次に示します。どちらも拡張されたWideWorldImportersデータベースを活用しています。
範囲行または平均範囲行
以前のバージョンのPlanExplorerは、ヒストグラムバケット内の行の総数を表すために、等しい行と範囲の行を1つの列に積み上げていました。これは、上記のように不等式または範囲の述語がある場合にうまく機能しますが、等式の述語の場合はあまり意味がありません。オプティマイザーが推定に使用するのは平均範囲の行であるため、実際に確認したいのは平均範囲の行です。残念ながら、これを取得する方法はありませんでした。
新しいプランエクスプローラーのヒストグラムでは、積み重ねられた列のシリーズの代わりに、同じ行と範囲の行が並んでいるクラスター化された列を使用するようになりました。 範囲行/平均範囲行を使用して、範囲行の合計または平均を適切に表示するかどうかを制御します セレクタ。これについてはもうすぐ…
まとめ
これらの新機能にとても興奮しています。お役に立てば幸いです。新しいプランエクスプローラーをダウンロードして試してみてください。これは簡単な紹介に過ぎませんでした。ここでいくつかの異なるシナリオを取り上げることを楽しみにしています。いつものように、あなたの考えを教えてください!