最近のヒントでは、SQLServer2016インスタンスがチェックポイント時間に苦労しているように見えるシナリオについて説明しました。エラーログには、次のような驚くべき数のFlushCacheエントリが入力されました。
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 この問題には少し戸惑いました。システムは確かに落ち着きがなく、十分なコア、3 TBのメモリ、XtremIOストレージでした。また、これらのFlushCacheメッセージはいずれも、エラーログにある15秒のI/O警告とペアになったことはありません。それでも、トランザクションの多いデータベースを大量にスタックすると、チェックポイントの処理がかなり遅くなる可能性があります。直接I/Oのせいではありませんが、(コミットされた からだけでなく、大量のダーティページで行わなければならないより多くの調整が必要です。 トランザクション)がこのような大量のメモリに分散し、レイジーライターを待機している可能性があります(インスタンス全体で1つしかないため)。
私はいくつかの非常に価値のある投稿をすばやく「更新」して読みました:
- チェックポイントはどのように機能し、何がログに記録されるか
- データベースチェックポイント(SQL Server)
- チェックポイントはtempdbに対して何をしますか?
- 1日のSQLServerDBAの神話:(15/30)チェックポイントはコミットされたトランザクションからのページのみを書き込みます
- FlushCacheメッセージは実際のIOストールではない可能性があります
- 間接チェックポイントとtempdb–良い、悪い、そして譲歩しないスケジューラー
- データベースのターゲットリカバリ時間を変更する
- 仕組み:FlushCacheメッセージはいつSQL Serverエラーログに追加されますか?
- SQLServer2016チェックポイントの動作の変更
- ターゲットリカバリ間隔と間接チェックポイント– SQLServer2016の新しいデフォルトの60秒
- SQL 2016 –実行速度が向上:間接チェックポイントのデフォルト
- SQL Server:大容量のRAMとDBのチェックポイント
ターゲットリカバリ間隔を0(古い方法)から60秒(新しい方法)に変更する前後に、これらのより厄介なデータベースのいくつかのチェックポイント期間を追跡することにすぐに決めました。 1月に、私は友人であり仲間のカナダ人ハンナバーノンから拡張イベントセッションを借りました:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; 各データベースを変更した時刻をマークし、元のヒントで公開されたクエリを使用して、拡張イベントデータの結果を分析しました。結果は、間接チェックポイントに変更した後、各データベースが平均30秒のチェックポイントから平均10分の1秒未満のチェックポイントに移行したことを示しています(ほとんどの場合、チェックポイントもはるかに少なくなっています)。このグラフィックから解凍するものはたくさんありますが、これは私の議論を提示するために使用した生データです(クリックして拡大):
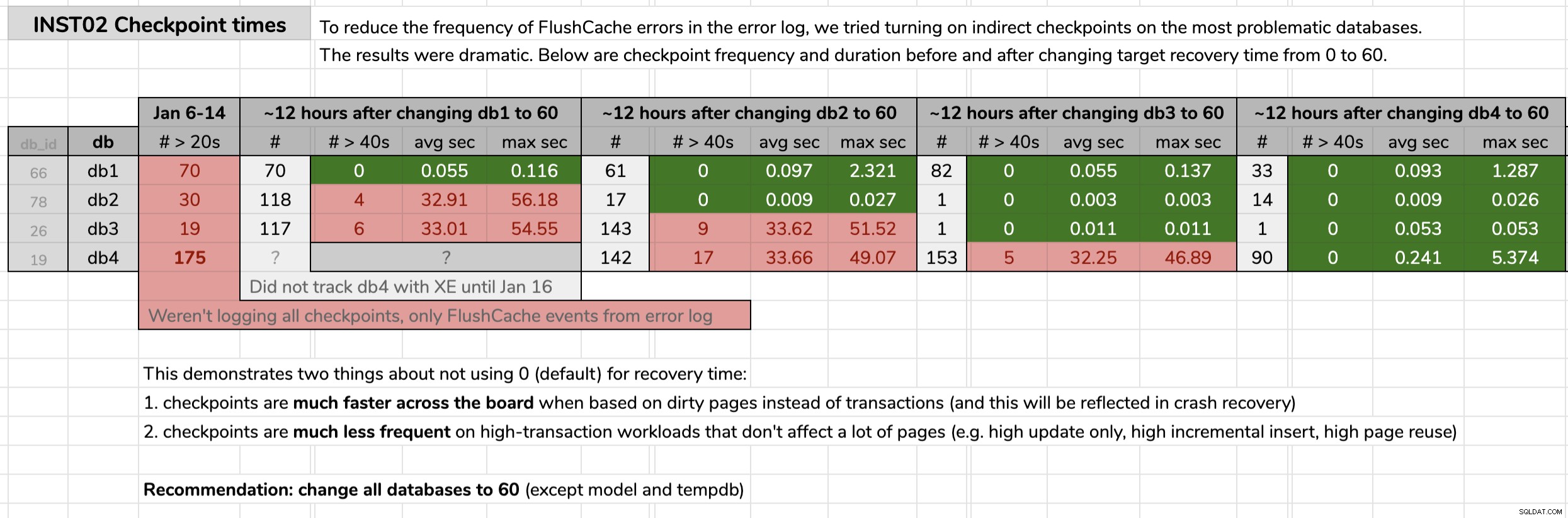
これらの問題のあるデータベース全体で自分のケースを証明すると、環境全体のすべてのユーザーデータベースにこれを実装するための青信号が得られました。最初に開発者で、次に本番環境で、CMSクエリを介して次のコマンドを実行し、話しているデータベースの数を測定しました。
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; クエリに関する注意事項:
-
database_id > 4masterに触れたくありませんでした まったく、tempdbを変更したくありませんでした ただし、最新のSQL Server 2017 CUを使用していないためです(詳細が重要である理由の1つとして、KB#4497928を参照してください)。後者はmodelを除外します モデルを変更するとtempdbに影響するためです。 次のフェイルオーバー/再起動時。msdbを変更できたはずです 、そして私はいつかそれをやり直すかもしれませんが、ここでの私の焦点はユーザーデータベースにありました。
-
[state] / is_read_only / is_in_standby
変更しようとしているデータベースがオンラインであり、読み取り専用ではないことを確認する必要があります(現在読み取り専用に設定されているデータベースをヒットしたため、後でそのデータベースに戻る必要があります)。
> -
OUTER APPLY (...)
私たちは、AGのプライマリであるか、AGにまったく存在しないデータベースにアクションを制限したいと考えています(また、プライマリおよびローカルである可能性がありますが、書き込み可能ではない分散AGも考慮する必要があります) 。セカンダリでチェックを実行した場合、そこで問題を修正することはできませんが、それでも警告が表示されるはずです。このロジックを支援してくれたErikDarlingと、改善の動機付けをしてくれたTaylorMartellに感謝します。
- SQL Server 2008 R2のような古いバージョンを実行しているインスタンスがある場合(私はそれを見つけました!)、
target_recovery_time_in_secondsなので、これを少し調整する必要があります。 列はそこに存在しません。あるケースでは、これを回避するために動的SQLを使用する必要がありましたが、これらのインスタンスがCMS階層内のどこにあるかを一時的に移動または削除することもできます。また、私のように怠惰になることはできず、CMSクエリウィンドウの代わりにPowershellでコードを実行します。この場合、コンパイル時の問題が発生する前に、任意の数のプロパティを指定してデータベースを簡単に除外できます。
本番環境では、古い設定を使用して、102のインスタンス(約半分)と合計1,590のデータベースがありました。すべてがSQLServer2017にあったのに、なぜこの設定がそれほど普及したのでしょうか。これらは、SQLServer2016で間接チェックポイントがデフォルトになる前に作成されたためです。結果のサンプルを次に示します。
 CMSクエリの一部の結果。
CMSクエリの一部の結果。
次に、今回はsys.sp_executesqlを使用してCMSクエリを再度実行しました。 コメントなし。 1,590のデータベースすべてでこれを実行するのに約12分かかりました。 1時間以内に、忙しいインスタンスのいくつかでCPUの大幅な低下を観察している人々の報告をすでに受け取っていました。
まだやることがあります。たとえば、tempdbへの潜在的な影響をテストする必要があります 、そして私たちのユースケースに私が聞いたホラーストーリーに重みがあるかどうか。また、60秒の設定が自動化の一部であり、すべてのデータベース作成リクエスト、特にスクリプト化されたものやバックアップから復元されたものであることを確認する必要があります。