この記事は、名前付きテーブル式に関するシリーズの第7部です。第5部と第6部では、一般的なテーブル式(CTE)の概念的な側面について説明しました。今月と来月は、CTEの最適化に関する考慮事項に焦点を当てます。
まず、名前付きテーブル式のネストされていない概念を簡単に再検討し、CTEへの適用性を示します。次に、永続性の考慮事項に焦点を当てます。再帰的および非再帰的CTEの永続性の側面について説明します。 CTEに固執することが理にかなっている場合と、一時テーブルを操作する方が実際に理にかなっている場合について説明します。
私の例では、サンプルデータベースTSQLV5とPerformanceV5を引き続き使用します。 TSQLV5を作成してデータを取り込むスクリプトはここにあり、そのER図はここにあります。 PerformanceV5を作成して設定するスクリプトはここにあります。
代用/見知らぬ
派生テーブルの最適化に焦点を当てたシリーズのパート4では、テーブル式のネスト解除/置換のプロセスについて説明しました。 SQL Serverが派生テーブルを含むクエリを最適化すると、パーサーによって生成された論理演算子の初期ツリーに変換ルールが適用され、元々テーブル式の境界を越えて物事がシフトする可能性があることを説明しました。これは、派生テーブルを使用するクエリのプランを、ネスト解除ロジックを自分で適用した基になるベーステーブルと直接照合するクエリのプランと比較すると、同じように見える程度に発生します。また、非常に多くの行を入力として使用するTOPフィルターを使用してネストを解除しないようにする手法についても説明しました。この手法が非常に便利な2つのケースを示しました。1つはエラーを回避することであり、もう1つは最適化の理由です。
CTEの置換/ネスト解除のTL;DRバージョンでは、プロセスは派生テーブルの場合と同じです。この声明に満足している場合は、このセクションをスキップして、永続性に関する次のセクションに直接ジャンプしてください。これまで読んだことがない重要なことを見逃すことはありません。ただし、あなたが私のようであれば、それが実際に当てはまるという証拠が必要になるでしょう。次に、このセクションを読み続けて、以前に派生テーブルで示した主要なネスト解除の例を再検討し、CTEを使用するように変換するときに使用するコードをテストすることをお勧めします。
パート4では、次のクエリ(クエリ1と呼びます)を示しました。
USE TSQLV5;
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; クエリには、派生テーブルの3つのネストレベルと、外部クエリが含まれます。各レベルは、異なる範囲の注文日をフィルタリングします。クエリ1の計画を図1に示します。
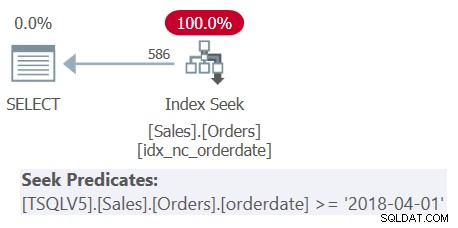 図1:クエリ1の実行プラン
図1:クエリ1の実行プラン
図1の計画は、すべてのフィルター述部が単一の包含フィルター述語にマージされたため、派生テーブルのネスト解除が行われたことを明確に示しています。
次のクエリが示すように、入力として非常に多数の行を持つ意味のあるTOPフィルター(TOP 100 PERCENTではなく)を使用することで、ネスト解除プロセスを防ぐことができると説明しました(クエリ2と呼びます):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; クエリ2の計画を図2に示します。
 図2:クエリ2の実行プラン
図2:クエリ2の実行プラン
この計画は、派生したテーブルの境界を効果的に確認できるため、ネスト解除が行われなかったことを明確に示しています。
CTEを使用して同じ例を試してみましょう。 CTEを使用するように変換されたクエリ1は次のとおりです。
WITH C1 AS
(
SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
),
C2 AS
(
SELECT *
FROM C1
WHERE orderdate >= '20180201'
),
C3 AS
(
SELECT *
FROM C2
WHERE orderdate >= '20180301'
)
SELECT orderid, orderdate
FROM C3
WHERE orderdate >= '20180401'; 図1で前に示したのとまったく同じ計画が得られ、ネストが解除されたことがわかります。
CTEを使用するように変換されたクエリ2は次のとおりです。
WITH C1 AS
(
SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101'
),
C2 AS
(
SELECT TOP (9223372036854775807) *
FROM C1
WHERE orderdate >= '20180201'
),
C3 AS
(
SELECT TOP (9223372036854775807) *
FROM C2
WHERE orderdate >= '20180301'
)
SELECT orderid, orderdate
FROM C3
WHERE orderdate >= '20180401'; 図2で前に示したのと同じ計画が得られ、ネストが解除されなかったことがわかります。
次に、ネスト解除を防ぐための手法の実用性を示すために使用した2つの例をもう一度見てみましょう。今回は、CTEを使用します。
間違ったクエリから始めましょう。次のクエリは、最小割引よりも大きい割引で、割引の逆数が10よりも大きい注文明細を返そうとします。
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
最小割引は負の値にすることはできず、ゼロ以上のいずれかです。したがって、行の割引がゼロの場合、最初の述語はfalseと評価され、短絡によって2番目の述語の評価が妨げられ、エラーが回避されると考えている可能性があります。ただし、このコードを実行すると、ゼロ除算エラーが発生します:
Msg 8134, Level 16, State 1, Line 99 Divide by zero error encountered.
問題は、SQL Serverが物理処理レベルで短絡の概念をサポートしていても、左から右に書かれた順序でフィルター述語を評価するという保証がないことです。このようなエラーを回避する一般的な試みは、最初に評価するフィルタリングロジックの部分を処理する名前付きテーブル式を使用し、次に評価するフィルタリングロジックを外部クエリで処理することです。 CTEを使用して試みられた解決策は次のとおりです。
WITH C AS
(
SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails)
)
SELECT orderid, productid, discount
FROM C
WHERE 1.0 / discount > 10.0; ただし、残念ながら、テーブル式のネストを解除すると、元のソリューションクエリと論理的に同等になり、このコードを実行しようとすると、ゼロ除算エラーが再度発生します。
Msg 8134, Level 16, State 1, Line 108 Divide by zero error encountered.
内部クエリでTOPフィルタを使用してトリックを使用すると、次のようにテーブル式のネストが解除されなくなります。
WITH C AS
(
SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails)
)
SELECT orderid, productid, discount
FROM C
WHERE 1.0 / discount > 10.0;> 今回は、コードはエラーなしで正常に実行されます。
最適化の理由でネストを解除しないようにする手法を使用する例に進みましょう。次のコードは、最大注文日が2018年1月1日以降の配送業者のみを返します。
USE PerformanceV5;
WITH C AS
(
SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S
)
SELECT shipperid, maxod
FROM C
WHERE maxod >= '20180101'; グループ化されたクエリとHAVINGフィルタを使用して、はるかに単純なソリューションを使用しないのはなぜか疑問に思われる場合は、shipperid列の密度と関係があります。 Ordersテーブルには1,000,000の注文があり、それらの注文の出荷は5人の荷送人によって処理されました。つまり、平均して、各荷送人は注文の20%を処理しました。荷送人ごとの最大注文日を計算するグループ化されたクエリの計画では、1,000,000行すべてがスキャンされ、数千のページ読み取りが発生します。実際、荷送人ごとの最大注文日を計算するCTEの内部クエリ(クエリ3と呼びます)だけを強調表示し、その実行プランを確認すると、図3に示すプランが得られます。
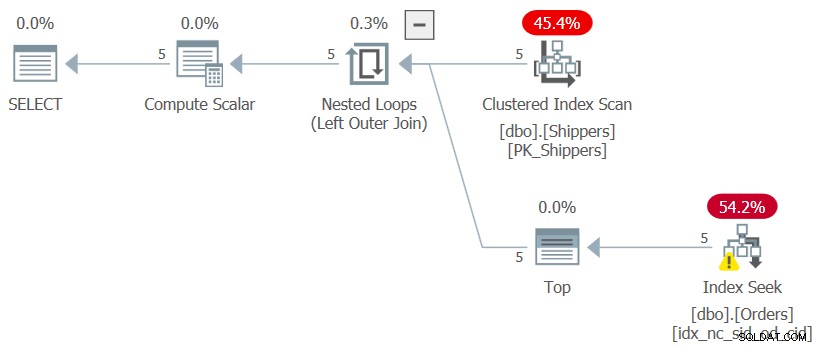 図3:クエリ3の実行プラン
図3:クエリ3の実行プラン
プランは、荷送人のクラスター化インデックスの5行をスキャンします。荷送人ごとに、プランは注文のカバーインデックスに対してシークを適用します。ここで、(shipperid、orderdate)はインデックスの先頭キーであり、リーフレベルで各荷送人セクションの最後の行に直接移動して、現在の最大注文日を取得します。荷送人。荷送人が5人しかないため、インデックスシーク操作が5つしかないため、非常に効率的な計画になります。 CTEの内部クエリを実行したときに得られたパフォーマンス測定値は次のとおりです。
duration: 0 ms, CPU: 0 ms, reads: 15
ただし、完全なソリューション(クエリ4と呼びます)を実行すると、図4に示すように、まったく異なる計画が得られます。
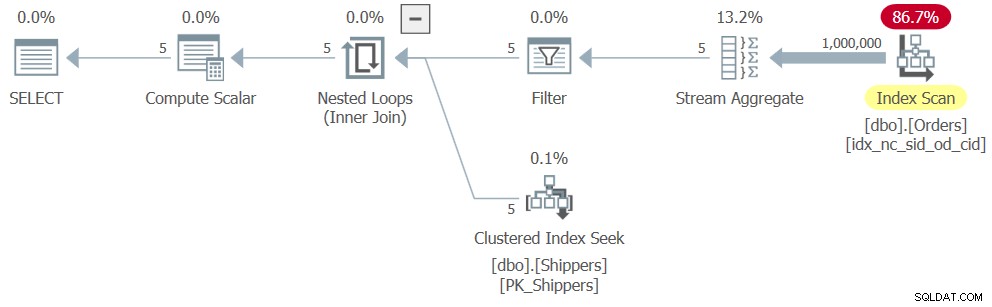 図4:クエリ4の実行プラン
図4:クエリ4の実行プラン
何が起こったのかというと、SQL Serverはテーブル式のネストを解除し、ソリューションをグループ化されたクエリの論理的等価物に変換し、その結果、Ordersのインデックスが完全にスキャンされました。このソリューションで得られたパフォーマンスの数値は次のとおりです。
duration: 316 ms, CPU: 281 ms, reads: 3854
ここで必要なのは、テーブル式のネストが解除されないようにすることです。これにより、内側のクエリがOrdersのインデックスに対するシークで最適化され、外側のクエリでフィルター演算子が追加されます。予定。これは、内部クエリにTOPフィルターを追加するというトリックを使用して実現します(このソリューションをクエリ5と呼びます):
WITH C AS
(
SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S
)
SELECT shipperid, maxod
FROM C
WHERE maxod >= '20180101'; このソリューションの計画を図5に示します。
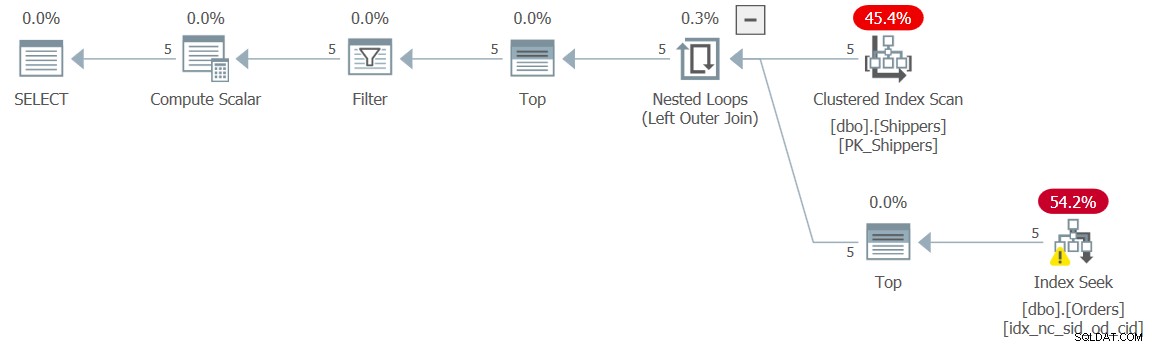 図5:クエリ5の実行プラン
図5:クエリ5の実行プラン
計画は、望ましい効果が達成されたことを示しており、したがって、パフォーマンスの数値はこれを確認しています:
duration: 0 ms, CPU: 0 ms, reads: 15
したがって、テストでは、SQLServerが派生テーブルの場合と同じようにCTEの置換/ネスト解除を処理することを確認しています。これは、パート5で説明したように、最適化の理由ではなく、重要な概念の違いのために、どちらか一方を優先するべきではないことを意味します。
永続性
CTEと名前付きテーブル式に関する一般的な誤解は、CTEが何らかの永続性の手段として機能するというものです。 SQL Serverは、内部クエリの結果セットを作業テーブルに保持し、外部クエリは実際にその作業テーブルと対話すると考える人もいます。実際には、通常の非再帰CTEと派生テーブルは永続化されません。テーブル式を含むクエリを最適化するときにSQLServerが適用するネスト解除ロジックについて説明しました。その結果、基になるベーステーブルと直接対話するプランが作成されます。オプティマイザーは、パフォーマンス上の理由、またはハロウィーンの保護などの他の理由でそうすることが理にかなっている場合、中間結果セットを永続化するために作業テーブルを使用することを選択する場合があることに注意してください。その場合、プランにスプールまたはインデックススプール演算子が表示されます。ただし、このような選択は、クエリでのテーブル式の使用とは関係ありません。
再帰的CTE
SQLServerがテーブル式のデータを永続化するいくつかの例外があります。 1つは、インデックス付きビューの使用です。ビューにクラスター化インデックスを作成すると、SQL Serverは、内部クエリの結果セットをビューのクラスター化インデックスに保持し、基になるベーステーブルの変更との同期を維持します。もう1つの例外は、再帰クエリを使用する場合です。 SQL Serverは、再帰メンバーが実行されるたびにCTE名への再帰参照によって表される最終ラウンドの結果セットにアクセスできるように、アンカークエリと再帰クエリの中間結果セットをスプールに保持する必要があります。
これを示すために、シリーズのパート6の再帰クエリの1つを使用します。
次のコードを使用して、tempdbデータベースにEmployeesテーブルを作成し、サンプルデータを入力して、サポートするインデックスを作成します。
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.Employees;
GO
CREATE TABLE dbo.Employees
(
empid INT NOT NULL
CONSTRAINT PK_Employees PRIMARY KEY,
mgrid INT NULL
CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.Employees(empid, mgrid, empname, salary)
VALUES(1, NULL, 'David' , $10000.00),
(2, 1, 'Eitan' , $7000.00),
(3, 1, 'Ina' , $7500.00),
(4, 2, 'Seraph' , $5000.00),
(5, 2, 'Jiru' , $5500.00),
(6, 2, 'Steve' , $4500.00),
(7, 3, 'Aaron' , $5000.00),
(8, 5, 'Lilach' , $3500.00),
(9, 7, 'Rita' , $3000.00),
(10, 5, 'Sean' , $3000.00),
(11, 7, 'Gabriel', $3000.00),
(12, 9, 'Emilia' , $2000.00),
(13, 9, 'Michael', $2000.00),
(14, 9, 'Didi' , $1500.00);
CREATE UNIQUE INDEX idx_unc_mgrid_empid
ON dbo.Employees(mgrid, empid)
INCLUDE(empname, salary);
GO 次の再帰CTEを使用して、入力サブツリールートマネージャーのすべての従属を返しました。この例では、従業員3を入力マネージャーとして使用しています。
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; このクエリの計画(これをクエリ6と呼びます)を図6に示します。
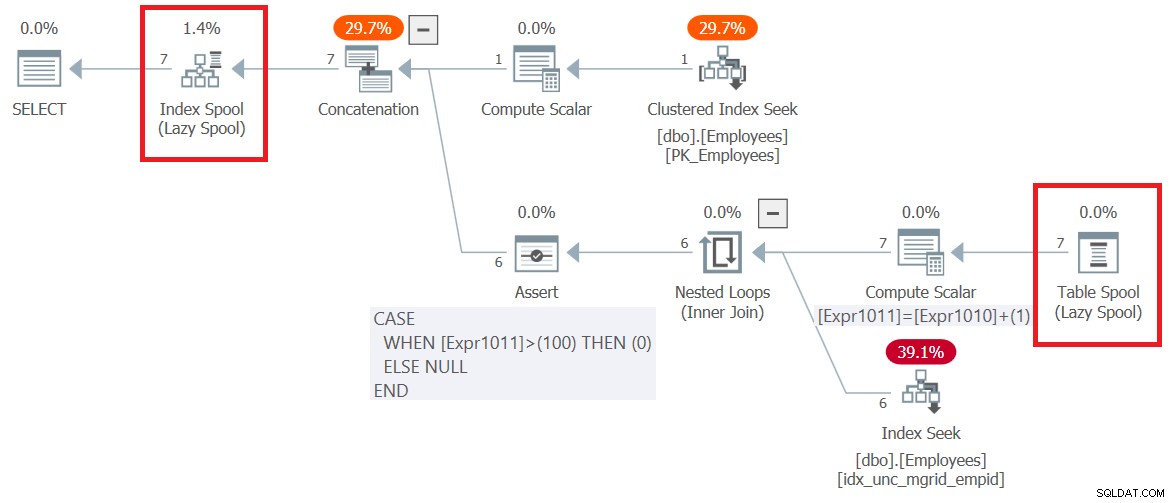 図6:クエリ6の実行プラン
図6:クエリ6の実行プラン
ルートSELECTノードの右側で、プランで最初に発生するのは、インデックススプール演算子で表されるBツリーベースの作業テーブルの作成であることに注意してください。計画の上部は、アンカーメンバーのロジックを処理します。 Employeesのクラスター化インデックスから入力されたemployee行をプルし、スプールに書き込みます。計画の下部は、再帰的なメンバーのロジックを表しています。空の結果セットが返されるまで、繰り返し実行されます。ネストされたループ演算子への外部入力は、スプールから前のラウンドのマネージャを取得します(テーブルスプール演算子)。内部入力は、Employees(mgrid、empid)で作成された非クラスター化インデックスに対してインデックスシーク演算子を使用して、前のラウンドからマネージャーの直接の部下を取得します。プランの下部の各実行の結果セットもインデックススプールに書き込まれます。全部で7行がスプールに書き込まれたことに注意してください。 1つはアンカーメンバーによって返され、さらに6つは再帰メンバーのすべての実行によって返されます。
余談ですが、プランがデフォルトの最大再帰制限である100をどのように処理するかに注目してください。下部のCompute Scalar演算子は、再帰メンバーが実行されるたびにExpr1011という内部カウンターを1ずつ増やし続けることに注意してください。次に、このカウンターが100を超えると、Assert演算子はフラグをゼロに設定します。これが発生すると、SQL Serverはクエリの実行を停止し、エラーを生成します。
持続しない場合
通常は永続化されない非再帰的CTEに戻ると、最適化の観点から、一時テーブルやテーブル変数などの実際の永続化ツールと比較して、CTEを使用するのが適切かどうかを判断する必要があります。それぞれのアプローチがより最適である場合を示すために、いくつかの例を見ていきます。
CTEが一時テーブルよりも優れている例から始めましょう。これは、同じCTEの複数の評価がない場合によくあります。むしろ、各CTEが1回だけ評価されるモジュラーソリューションにすぎない可能性があります。次のコード(これをクエリ7と呼びます)は、1,000,000行のパフォーマンスデータベースのOrdersテーブルにクエリを実行して、70を超える個別の顧客が注文した注文年を返します。
USE PerformanceV5;
WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM dbo.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70; このクエリは次の出力を生成します:
orderyear numcusts ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000
SQL Server 2019 Developer Editionを使用してこのコードを実行し、図7に示す計画を取得しました。
 図7:クエリ7の実行プラン
図7:クエリ7の実行プラン
CTEのネストを解除すると、Ordersテーブルのインデックスからデータを取得する計画が作成され、CTEの内部クエリ結果セットのスプーリングは含まれないことに注意してください。自分のマシンでこのクエリを実行すると、次のパフォーマンス数値が得られました。
duration: 265 ms, CPU: 828 ms, reads: 3970, writes: 0
次に、CTEの代わりに一時テーブルを使用するソリューション(ソリューション8と呼びます)を試してみましょう。
SELECT YEAR(orderdate) AS orderyear, custid INTO #T1 FROM dbo.Orders; SELECT orderyear, COUNT(DISTINCT custid) AS numcusts INTO #T2 FROM #T1 GROUP BY orderyear; SELECT orderyear, numcusts FROM #T2 WHERE numcusts > 70; DROP TABLE #T1, #T2;
このソリューションの計画を図8に示します。
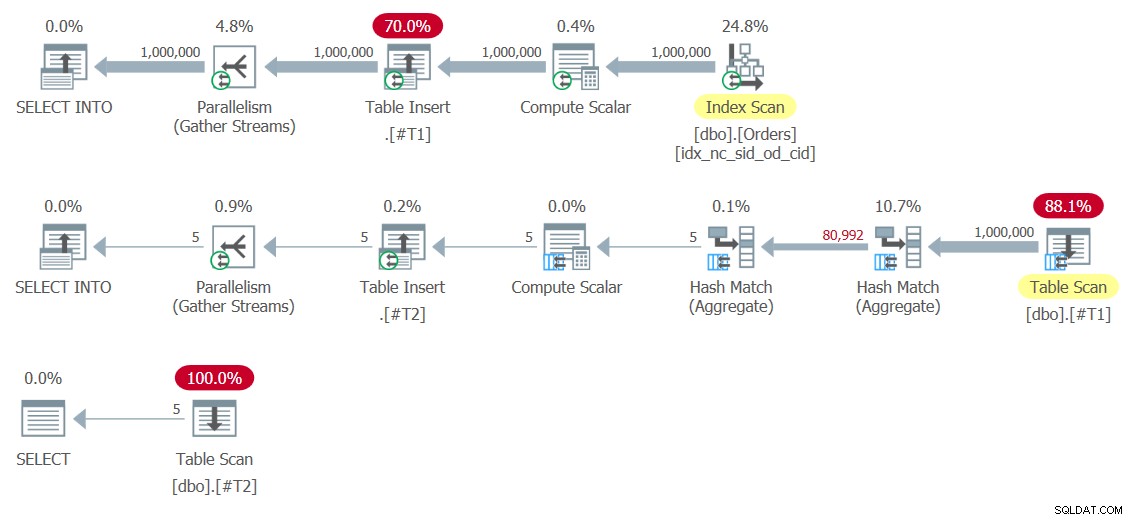 図8:ソリューション8の計画
図8:ソリューション8の計画
テーブル挿入演算子が結果セットを一時テーブル#T1および#T2に書き込んでいることに注意してください。最初のものは#T1に1,000,000行を書き込むため、特に高価です。この実行で得られたパフォーマンスの数値は次のとおりです。
duration: 454 ms, CPU: 1517 ms, reads: 14359, writes: 359
ご覧のとおり、CTEを使用したソリューションの方がはるかに最適です。
いつ持続するか
では、一時テーブルを使用するよりも、各CTEの評価を1回だけ行うモジュラーソリューションの方が常に好まれるというのは事実でしょうか。必ずしも。多くのステップを含み、オプティマイザが計画の多くの異なるポイントで多くのカーディナリティ推定を適用する必要がある複雑な計画をもたらすCTEベースのソリューションでは、結果として最適ではない選択をもたらす不正確さが蓄積される可能性があります。このような場合に取り組むための手法の1つは、中間結果セットを一時テーブルに保持し、必要に応じてそれらにインデックスを作成することです。これにより、オプティマイザーは新しい統計で新たなスタートを切り、より高品質のカーディナリティ推定の可能性が高まります。うまくいけば、より最適な選択につながるでしょう。これが一時テーブルを使用しないソリューションよりも優れているかどうかは、テストする必要があります。より高品質のカーディナリティ推定値を取得するために中間結果セットを永続化するための追加コストのトレードオフは、それだけの価値がある場合があります。
一時テーブルの使用が推奨されるもう1つの典型的なケースは、CTEベースのソリューションに同じCTEの複数の評価があり、CTEの内部クエリが非常に高価な場合です。次のCTEベースのソリューション(クエリ9と呼びます)を検討してください。これは、各注文年月に、最も近い注文数を持つ異なる注文年月に一致します。
WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth,
COUNT(*) AS numorders
FROM dbo.Orders
GROUP BY YEAR(orderdate), MONTH(orderdate)
)
SELECT O1.orderyear, O1.ordermonth, O1.numorders,
O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2,
O2.numorders AS numorders2
FROM OrdCount AS O1
CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders
FROM OrdCount AS O2
WHERE O2.orderyear <> O1.orderyear
OR O2.ordermonth <> O1.ordermonth
ORDER BY ABS(O1.numorders - O2.numorders),
O2.orderyear, O2.ordermonth ) AS O2; このクエリは次の出力を生成します:
orderyear ordermonth numorders orderyear2 ordermonth2 numorders2 ----------- ----------- ----------- ----------- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 4 20561 2016 9 20554 2018 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19844 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 2016 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 2016 3 21211 2019 12 20184 2018 9 20487 2017 1 21223 2016 10 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 rows affected)
クエリ9の計画を図9に示します。
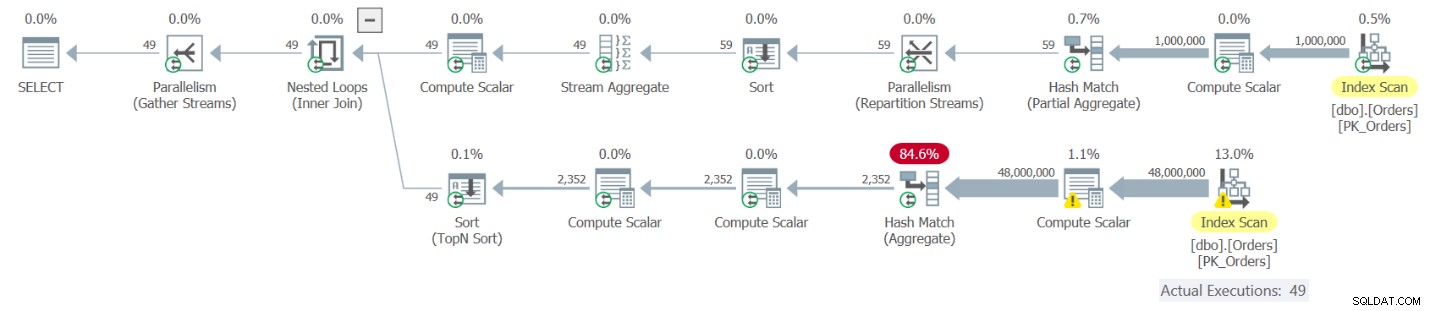 図9:クエリ9の実行プラン
図9:クエリ9の実行プラン
計画の上部は、O1としてエイリアス化されたOrdCountCTEのインスタンスに対応しています。この参照により、CTEOrdCountが1回評価されます。プランのこの部分は、Ordersテーブルのインデックスから行を取得し、それらを年と月でグループ化し、グループごとの注文数を集計して、49行になります。計画の下部は、O1から行ごとに適用される相関派生テーブルO2に対応しているため、49回実行されます。実行するたびにOrdCountCTEがクエリされるため、CTEの内部クエリが個別に評価されます。プランの下部が、注文のインデックスからすべての行をスキャンし、それらをグループ化して集計していることがわかります。基本的に、CTEの合計50の評価を取得します。その結果、注文から1,000,000行を50回スキャンし、それらをグループ化して集約します。あまり効率的な解決策のようには思えません。このソリューションを自分のマシンで実行したときに得られたパフォーマンス測定値は次のとおりです。
duration: 16 seconds, CPU: 56 seconds, reads: 130404, writes: 0
関係する月が数十か月しかないことを考えると、はるかに効率的なのは、一時テーブルを使用して、Ordersからの行をグループ化および集約する単一のアクティビティの結果を格納し、外部入力と内部入力の両方を取得することです。 APPLYオペレーターは、一時テーブルと対話します。 CTEの代わりに一時テーブルを使用するソリューション(これをソリューション10と呼びます)は次のとおりです。
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth,
COUNT(*) AS numorders
INTO #OrdCount
FROM dbo.Orders
GROUP BY YEAR(orderdate), MONTH(orderdate);
SELECT O1.orderyear, O1.ordermonth, O1.numorders,
O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2,
O2.numorders AS numorders2
FROM #OrdCount AS O1
CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders
FROM #OrdCount AS O2
WHERE O2.orderyear <> O1.orderyear
OR O2.ordermonth <> O1.ordermonth
ORDER BY ABS(O1.numorders - O2.numorders),
O2.orderyear, O2.ordermonth ) AS O2;
DROP TABLE #OrdCount; ここでは、TOPフィルターは順序指定の計算に基づいているため、一時テーブルのインデックスを作成する意味はあまりありません。したがって、並べ替えは避けられません。ただし、他の場合には、他のソリューションを使用して、一時テーブルのインデックス作成を検討することも適切である可能性があります。いずれにせよ、このソリューションの計画を図10に示します。
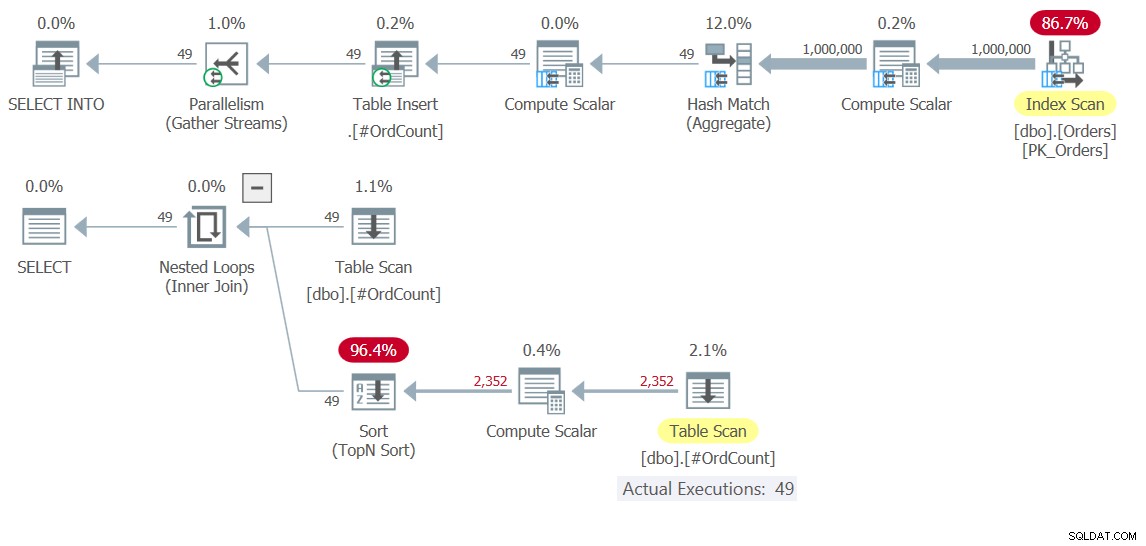 図10:ソリューション10の実行計画
図10:ソリューション10の実行計画
一番上の計画で、1,000,000行をスキャンし、それらをグループ化して集約するという手間のかかる作業が1回だけ発生することを確認してください。 49行が一時テーブル#OrdCountに書き込まれ、次に下部のプランが、APPLY演算子のロジックを処理するNestedLoops演算子の外部入力と内部入力の両方の一時テーブルと対話します。
このソリューションの実行で得られたパフォーマンスの数値は次のとおりです。
duration: 0.392 seconds, CPU: 0.5 seconds, reads: 3636, writes: 3
CTEベースのソリューションよりも桁違いに高速です。
次は?
この記事では、CTEに関連する最適化の考慮事項について説明しました。派生テーブルで行われるネスト解除/置換プロセスは、CTEでも同じように機能することを示しました。また、非再帰CTEが永続化されないという事実についても説明し、永続性がソリューションのパフォーマンスにとって重要な要素である場合は、一時テーブルやテーブル変数などのツールを使用して自分で処理する必要があることを説明しました。来月は、CTE最適化の追加の側面を取り上げて議論を続けます。