これは、SQLServerの行モード並列プランの実行を開始する方法を深く掘り下げた5部構成のシリーズの最後の部分です。パート1は親タスクの実行コンテキストゼロを初期化し、パート2はクエリスキャンツリーを作成しました。パート3はクエリスキャンを開始し、初期段階を実行しました 処理を行い、ブランチCで最初の追加の並列タスクを開始しました。パート4では、交換の同期と、並列プランのブランチCおよびDの起動について説明しました。
この並行計画のブランチのリマインダー(クリックして拡大):
これは、実行シーケンスの4番目の段階です:
- ブランチA(親タスク)。
- ブランチC(追加の並列タスク)。
- ブランチD(追加の並列タスク)。
- ブランチB(追加の並列タスク)。
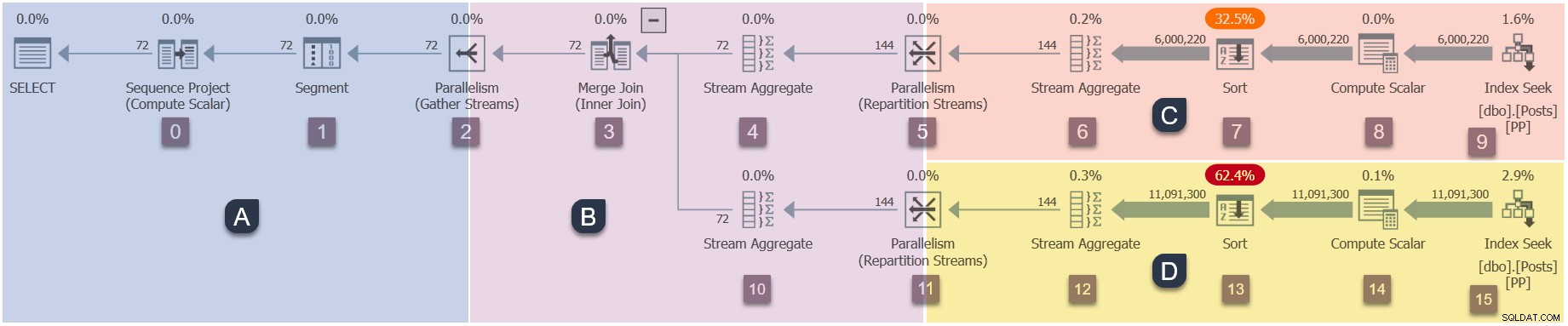
現在アクティブな唯一のスレッド(CXPACKETで中断されていません )は親タスクです 、ノード11での再パーティションストリーム交換のコンシューマ側にあります ブランチB:
親タスクは、ネストされた初期フェーズから戻るようになりました 呼び出し、プロファイラーでの経過時間とCPU時間を設定します。最初と最後のアクティブ時間はない 初期段階の処理中に更新されます。これらの数値は実行コンテキストゼロに対して記録されていることに注意してください—ブランチBの並列タスクはまだ存在していません。
親タスク 昇順 ノード11から、ノード10のストリームアグリゲートとノード3のマージ結合を経由して、ノード2のギャザーストリーム交換に戻るツリー。
初期段階の処理が完了しました 。
オリジナルのEarlyPhases ノード2で呼び出しますストリームを収集します 交換最後に 完了すると、親タスクはその交換を開くことに戻ります(このシリーズの最初からその呼び出しを覚えているかもしれません)。ノード2のopenメソッドは、CQScanExchangeNew::StartAllProducersを呼び出すようになりました。 並列タスクを作成する ブランチBの場合。
親タスク 今待っています CXPACKETで 消費者で ノード2の側ストリームを収集 両替。この待機は、新しく作成されたブランチBタスクがネストされたOpenを完了するまで続きます。 呼び出して戻って、ギャザーストリーム交換のプロデューサー側を完全に開きます。
ブランチBの2つの新しい並列タスクは、プロデューサーから始まります。 ノード2の側ストリームを収集 両替。通常の行モードの反復実行モデルに従って、次のように呼び出します。
-
CQScanXProducerNew::Open(ノード2プロデューサー側が開いています)。 -
CQScanProfileNew::Open(ノード3のプロファイラー)。 -
CQScanMergeJoinNew::Open(ノード3マージ結合)。 -
CQScanProfileNew::Open(ノード4のプロファイラー)。 -
CQScanStreamAggregateNew::Open(ノード4ストリームアグリゲート)。 -
CQScanProfileNew::Open(ノード5のプロファイラー)。 -
CQScanExchangeNew::Open(再パーティションストリーム交換)。
並列タスクは両方とも、初期フェーズの処理と同様に、マージ結合への外部(上部)入力に従います。
ブランチBのタスクがコンシューマーに到着したとき 再パーティションストリームのサイドはノード5で交換され、各タスクは次のようになります。
- 交換ポート(
CXPortに登録します 。 - パイプを作成します (
CXPipe)このタスクを1つ以上のプロデューサー側のタスクに接続します(交換のタイプによって異なります)。現在の交換は再パーティションストリームであるため、各コンシューマータスクには2つのパイプがあります(DOP 2)。各コンシューマーは、2つのプロデューサーのいずれかから行を受け取る場合があります。 -
CXPipeMergeを追加します マージする 複数のパイプからの行(これは順序を維持する交換であるため) - 行パケットを作成します (紛らわしい名前の
CXPacket)フロー制御と交換パイプ全体の行のバッファリングに使用されます。これらは、以前に付与されたクエリメモリから割り当てられます。
両方のコンシューマー側の並列タスクがその作業を完了すると、ノード5交換を実行する準備が整います。 2つのコンシューマー(ブランチB)と2つのプロデューサー(ブランチC)はすべて交換ポートを開いているため、ノード5 CXPACKET 終了を待つ 。
現状:
- ブランチAの親タスク 待っています
CXPACKETで ノード2のコンシューマー側でストリーム交換を収集します。この待機は、両方のノード2プロデューサーが戻って取引所を開くまで続きます。 - ブランチBの2つの並列タスク 実行可能 。彼らはノード5で再パーティションストリーム交換のコンシューマー側を開いたところです。
- ブランチCの2つの並列タスク
CXPACKETからリリースされました 待って、今は実行可能 。ノード6の2つのストリームアグリゲート(並列タスクごとに1つ)は、ノード7の2つのソートからの行のアグリゲーションを開始できます。ソートが入力フェーズを完了したときに、しばらく前に閉じられたノード9でのインデックスシークを思い出してください。 - ブランチDの2つの並列タスク 待っています
CXPACKETで 再パーティションストリームのプロデューサー側でノード11で交換します。ノード11のコンシューマー側がブランチBの2つの並列タスクによって開かれるのを待っています。インデックスシークが閉じられ、ソートはに移行する準備ができています。それらの出力フェーズ。
複数のブランチ(BとC)を同時にアクティブにするのはこれが初めてであり、議論するのは難しいかもしれません。幸いなことに、デモクエリの設計は、ブランチCのストリーム集約が数行のみを生成するようになっています。少数の狭い出力行は、行パケットのバッファに簡単に収まります。 ノード5で再パーティションストリーム交換。したがって、ブランチCのタスクは、ノード5の再パーティションストリームのコンシューマー側が行をフェッチするのを待たずに、作業を続行できます(最終的には終了します)。
便利なことに、これは、2つのブランチC並列タスクを心配することなくバックグラウンドで実行できることを意味します。 2つのブランチBの並列タスクが何をしているのかを気にするだけです。
ブランチBのリマインダー:
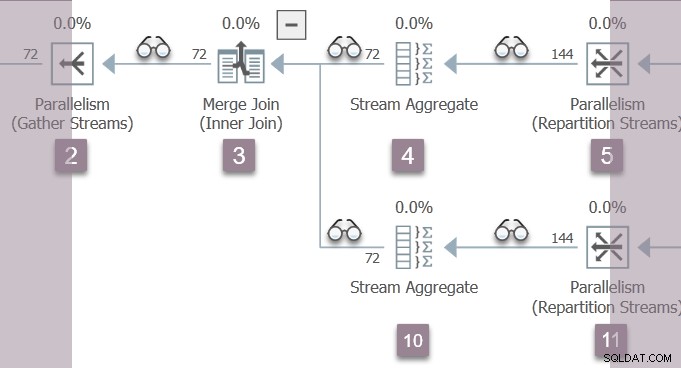
ブランチBの2人の並列ワーカーがOpenから戻ります ノード5の再パーティションストリーム交換での呼び出し。これにより、ノード4のストリームアグリゲートを介して、ノード3のマージ結合に戻ります。
昇順だから Openのツリー メソッドでは、ノード5とノード4の上のプロファイラーが最後のアクティブを記録しています 時間、および経過時間とCPU時間(タスクごと)の累積。現在、親タスクの初期フェーズを実行していないため、実行コンテキスト0に記録された数値は影響を受けません。
マージ結合時に、2つのブランチB並列タスクが降順を開始します。 内側(下側)の入力は、ノード10のストリームアグリゲート(およびいくつかのプロファイラー)を介して、ノード11の再パーティションストリーム交換のコンシューマー側に送られます。
ノード5でのブランチCイベントの繰り返しは、ノード11の再パーティションストリームで発生します。ノード11交換のコンシューマ側が完了し、開かれます。ブランチDの2つのプロデューサーは、CXPACKETを終了します 待って、実行可能になります また。ブランチDタスクをバックグラウンドで実行し、その結果を交換バッファーに配置します。
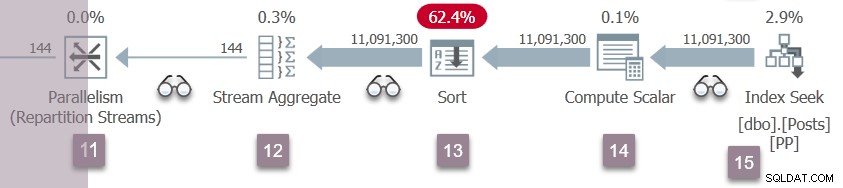
現在、6つの並列タスクがあります (ブランチB、C、およびDにそれぞれ2つ)このクエリで追加の並列タスクに割り当てられた2つのスケジューラーで時間を共同で共有します。
ブランチBの2つの並列タスクは、Openから戻ります。 ノード11の再パーティションストリーム交換での呼び出しは、ノード10のストリームアグリゲートを超えて、ノード3でのマージ結合を介して、ストリームの収集のプロデューサー側に戻ります。 ノード2で。プロファイラー最後にアクティブ ネストされたOpenでツリーを昇順すると、累積経過時間とCPU時間が更新されます。 メソッド。
プロデューサーで ストリーム交換の収集側では、2つのブランチB並列タスクが同期して交換ポートを開き、CXPACKETで待機します。 消費者側が開くために。
親タスク ギャザーストリームのコンシューマー側での待機がリリースされました そのCXPACKETから 待機します。これにより、コンシューマ側の交換ポートのオープンが完了します。これにより、プロデューサーは(簡単な)CXPACKETから解放されます。 待つ。これで、ノード2の収集ストリームがすべての所有者によって開かれました。
親タスク ストリームの収集交換からクエリスキャンツリーを昇格し、Openから戻ります。 取引所での電話、セグメント 、およびシーケンスプロジェクト ブランチAのオペレーター。
これでオープニングが完了します CQueryScan::StartupQueryの呼び出しによって以前に開始されたクエリスキャンツリー 。これで、並列プランのすべてのブランチの実行が開始されました。
実行プランは、GetRowに応答して行を返し始める準備ができています ルートでの呼び出し CQueryScan::GetRowの呼び出しによって開始されたクエリスキャンツリーの 。並列プランの開始方法に関する記事の範囲を厳密に超えているため、詳細については説明しません。 。
それでも、簡単なシーケンスは次のとおりです。
- 親タスクは
GetRowを呼び出しますGetRowを呼び出すシーケンスプロジェクトGetRowを呼び出すセグメント上 消費者 ギャザーストリーム交換の側。 - 取引所で利用可能な行がまだない場合、親タスクは待機します
CXCONSUMERで 。 - 一方、独立して実行されているブランチBの並列タスクは、
GetRowを再帰的に呼び出しています。 プロデューサーから開始 ギャザーストリーム交換の側。 - 行は、ノード5と12での再パーティションストリーム交換のコンシューマ側によってブランチBに提供されます。
- ブランチCとDは、それぞれのストリームアグリゲートを介してソートから行を処理しています。ブランチBのタスクは待機する必要がある場合があります
CXCONSUMERで 再パーティションストリームノード5および12で、行の完全なパケットが使用可能になります。 - ネストされた
GetRowから出現する行 ブランチBの呼び出しは、プロデューサーで行パケットにアセンブルされます ギャザーストリーム交換の側。 - 親タスクの
CXCONSUMERパケットが利用可能になると、ギャザーストリームのコンシューマ側での待機が終了します。 - 一度に1行ずつ、ブランチAの親演算子を介して処理され、最後にクライアントに送られます。
- 最終的に、行がなくなり、ネストされた
Closeコールは、エクスチェンジ全体でツリーを波及し、並列実行が終了します。
まず、この特定の並列実行プランの実行シーケンスの概要:
- 親タスク ブランチAを開きます 。 初期段階 処理は、ストリームの収集交換で開始されます。
- 親タスクの初期フェーズの呼び出しは、スキャンツリーをノード9のインデックスシークに下降し、次にノード5の再パーティション化交換に上昇します。
- 親タスクは、ブランチCの並列タスクを開始します 、次に、ノード7で使用可能なすべての行をブロッキングソート演算子に読み込むまで待機します。
- 初期フェーズの呼び出しはマージ結合に上昇し、次にノード11の交換への内部入力を下降します。
- ブランチDのタスク 親タスクがノード11で待機している間、ブランチCと同じように開始されます。
- 初期フェーズの呼び出しは、ギャザーストリームまでノード11から戻ります。 早期終了 ここ。
- 親タスクは、ブランチBの並列タスクを作成します 、ブランチBの開設が完了するまで待機します。
- ブランチBタスクはノード5の再パーティションストリームに到達し、同期して交換を完了し、ブランチCタスクを解放して、並べ替えから行の集約を開始します。
- ブランチBタスクがノード12の再パーティションストリームに到達すると、それらは同期して交換を完了し、ブランチDタスクを解放して、並べ替えから行の集約を開始します。
- ブランチBのタスクは、ストリームの交換と同期の収集に戻り、親タスクを待機から解放します。これで、親タスクは行をクライアントに返すプロセスを開始する準備が整いました。
Sentry OnePlanExplorerでこのプランの実行を確認することをお勧めします。実際のプランコレクションの[ライブクエリプロファイルあり]オプションを必ず有効にしてください。プランエクスプローラー内でクエリを直接実行することの良い点は、自分のペースで複数のキャプチャをステップ実行したり、巻き戻したりできることです。また、ライブクエリプロファイリングデータと同期されたI / O、CPU、および待機のグラフィカルな要約も表示されます。
初期段階の処理中にクエリスキャンツリーを昇順すると、親タスクの各プロファイリングイテレータで最初と最後のアクティブ時間が設定されますが、経過時間やCPU時間は累積されません。 Open中にツリーを昇順 およびGetRow 並列タスクの呼び出しは、最後のアクティブ時間を設定し、タスクごとに各プロファイリングイテレータで経過時間とCPU時間を累積します。
初期段階の処理は、行モードの並列プランに固有です。交換が正しい順序で初期化され、すべての並列機構が正しく機能することを確認する必要があります。
親タスクは、必ずしも初期段階の処理全体を実行するとは限りません。初期段階はルート交換から始まりますが、これらの呼び出しがツリーをナビゲートする方法は、遭遇したイテレーターによって異なります。このデモでは、両方の入力に対して初期段階の処理が必要になるため、マージ結合を選択しました。
(たとえば)並列ハッシュ結合の初期段階では、ビルド入力のみに伝播します。ハッシュ結合がプローブフェーズに移行すると、開きます 交換を含む、その入力のイテレータ。初期段階の処理の別のラウンドが開始され、(正確に)並列タスクの1つによって処理され、親タスクの役割を果たします。
初期フェーズの処理でブロッキングイテレーターを含む並列ブランチが検出されると、そのブランチの追加の並列タスクが開始され、それらのプロデューサーが開始フェーズを完了するのを待ちます。そのブランチには、同じ方法で再帰的に処理される子ブランチが含まれる場合もあります。
行モード並列プランの一部のブランチは、単一のスレッドで実行する必要がある場合があります(たとえば、グローバルアグリゲートまたはトップが原因)。これらの「シリアルゾーン」は、追加の「パラレル」タスクでも実行されます。唯一の違いは、そのブランチのタスク、実行コンテキスト、およびワーカーが1つしかないことです。初期段階の処理は、ブランチに割り当てられたタスクの数に関係なく同じように機能します。たとえば、「シリアルゾーン」は、親タスク(またはその役割を果たす並列タスク)と単一の追加タスクのタイミングを報告します。これは、「スレッド0」(初期フェーズ)および「スレッド1」(追加タスク)のデータとしてshowplanに表示されます。
これはすべて、確かに複雑さの追加の層を表しています。その投資の見返りは、実行時のリソース使用量(主にスレッドとメモリ)、同期待機の削減、スループットの向上、潜在的に正確なパフォーマンスメトリック、およびクエリ内の並列デッドロックの可能性の最小化です。
行モードの並列処理は、最新のバッチモードの並列実行エンジンによって大幅に隠されていますが、行モードの設計にはまだ一定の美しさがあります。ほとんどのイテレータは、同期、フロー制御、およびスケジューリングのほとんどすべてが交換によって処理され、シリアルプランで実行されているふりをします。初期段階の処理などの実装の詳細に明らかな注意と注意により、クエリ設計者が実際の問題についてあまり考えなくても、最大の並列計画を正常に実行できます。