ゲスト作成者:Michael J Swart(@MJSwart)
ソフトウェア要件をスキーマとクエリに変換するのに多くの時間を費やしています。これらの要件は、実装が簡単な場合もありますが、多くの場合困難です。 SQLServerを使用して実装するのが難しいデータアクセスパターンにつながるUIデザインの選択についてお話ししたいと思います。
列で並べ替え
列による並べ替えは非常に馴染みのあるパターンであるため、当然のことと見なすことができます。テーブルを表示するソフトウェアを操作するたびに、次のように列を並べ替えることができます。
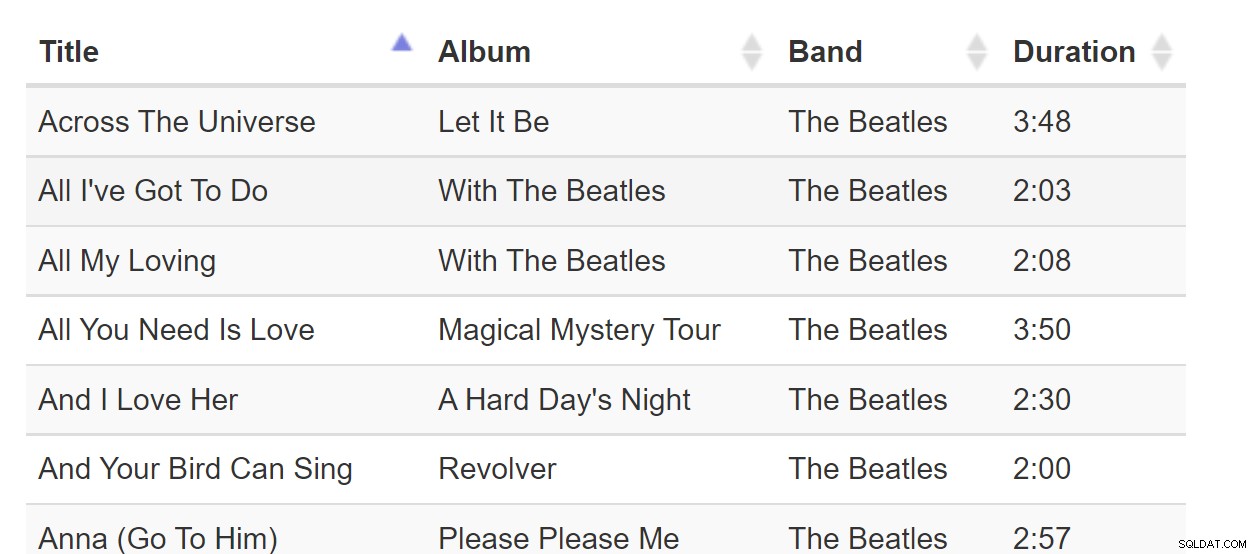
Sort-By-Colunnは、すべてのデータがブラウザーに収まる場合の優れたパターンです。しかし、データセットが数十億行の大きさである場合、Webページに1ページのデータしか必要としない場合でも、これは厄介になる可能性があります。この曲の表を考えてみましょう:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); そして、各列でソートされた次の4つのクエリについて考えてみます。
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
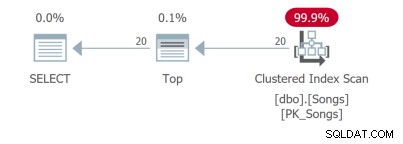
これほど単純なクエリでも、さまざまなクエリプランがあります。最初の2つのクエリは、カバーするインデックスを使用します:
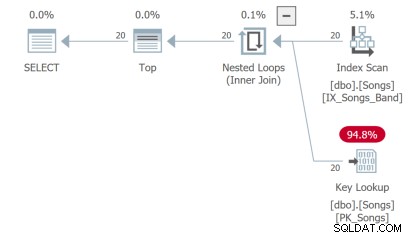
3番目のクエリは、理想的ではないキールックアップを実行する必要があります。
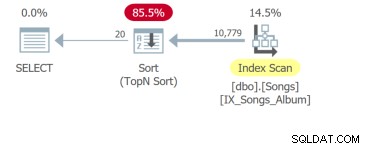
ただし、最悪の場合、最初の20行を返すためにテーブル全体をスキャンして並べ替えを行う必要がある4番目のクエリです。
重要なのは、唯一の違いはORDER BY句ですが、これらのクエリは個別に分析する必要があるということです。 SQLチューニングの基本単位はクエリです。したがって、10個の並べ替え可能な列を含むUI要件を表示する場合は、分析する10個のクエリを表示します。
これはいつ厄介になりますか?
列による並べ替え機能は優れたUIパターンですが、データが非常に多くの列を持つ巨大な成長テーブルからのものである場合、厄介になる可能性があります。すべての列にカバーインデックスを作成したくなるかもしれませんが、それ以外のトレードオフがあります。列ストアインデックスは状況によっては役立つ場合がありますが、それは別のレベルの厄介さをもたらします。必ずしも簡単な代替手段があるとは限りません。
ページ結果
ページ結果を使用することは、一度に多くの情報でユーザーを圧倒しないための良い方法です。これは、データベースサーバーを圧倒しないための良い方法でもあります…通常は。
この設計を検討してください:

この例の背後にあるデータでは、結果の数を報告するためにデータセット全体をカウントして処理する必要があります。この例のクエリでは、次のような構文を使用できます。
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
これは便利な構文であり、クエリは25行しか生成しません。ただし、結果セットが小さいからといって、必ずしも安いとは限りません。 [列で並べ替え]パターンで見たように、TOP演算子は、最初に大量のデータを並べ替える必要がない場合にのみ安価です。
非同期ページリクエスト
ユーザーが結果のあるページから次のページに移動すると、関連するWebリクエストを数秒または数分で区切ることができます。これにより、NOLOCKを使用したときに見られる落とし穴によく似た問題が発生します。例:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
2つのリクエストの間に行が追加されると、ユーザーには同じ行が2回表示される場合があります。また、行が削除されると、ユーザーはページをナビゲートするときに行を見逃す可能性があります。このPaged-Resultsパターンは、「Give merows26-50」と同等です。本当の質問は「次の25行をください」である必要がある場合。違いは微妙です。
より良いパターン
Paged-Resultsを使用すると、@Nが大きくなるにつれて「OFFSET@NROWS」にかかる時間が長くなる可能性があります。代わりに、Load-MoreボタンまたはInfinite-Scrollingを検討してください。 Load-Moreページングを使用すると、少なくともインデックスを効率的に使用できる可能性があります。クエリは次のようになります:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
非同期ページリクエストの落とし穴のいくつかにはまだ悩まされていますが、ブックマークがあるため、ユーザーは中断したところから再開します。
テキストで部分文字列を検索
検索はインターネットのいたるところにあります。しかし、バックエンドでどのソリューションを使用する必要がありますか?次のようなワイルドカードを使用してSQLServerのLIKEフィルターを使用して部分文字列を検索しないように警告したい:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
次のような厄介な結果につながる可能性があります:
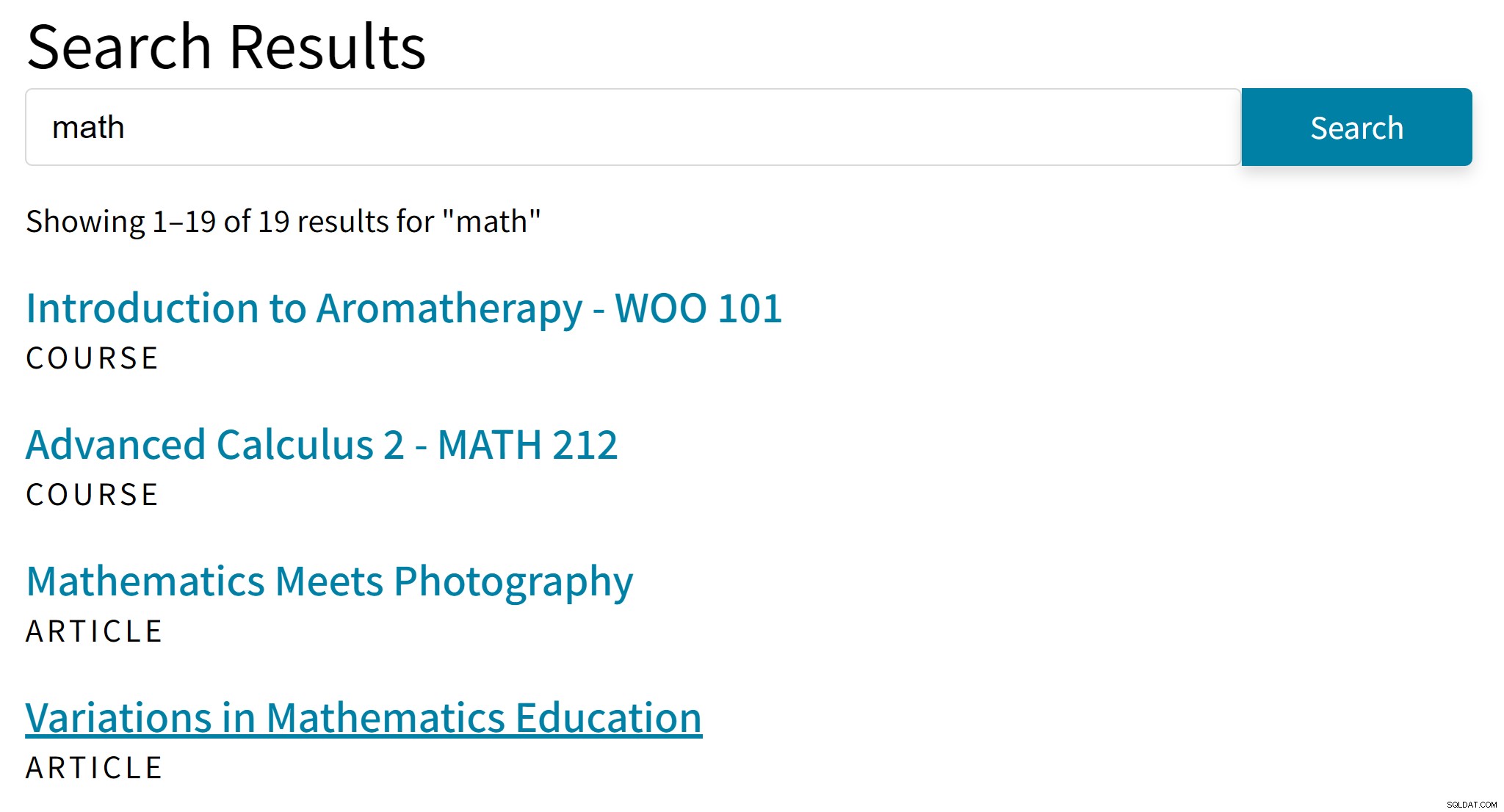
「アロマテラピー」は、「数学」という検索用語にはおそらく適していません。一方、検索結果には、代数または三角法のみに言及している記事がありません。
また、SQLServerを使用して効率的に実行することは非常に難しい場合があります。この種の検索をサポートする簡単なインデックスはありません。 Paul Whiteは、SQLServerのTrigramWildcardStringSearchで1つのトリッキーなソリューションを提供しました。照合とUnicodeで発生する可能性のある問題もあります。これは、あまり良くないユーザーエクスペリエンスのための高価なソリューションになる可能性があります。
代わりに使用するもの
SQL Serverの全文検索は役立つようですが、個人的には使用したことがありません。実際には、SQL Server以外のソリューション(Elasticsearchなど)でのみ成功を収めています。
結論
私の経験では、ソフトウェア設計者は、設計の実装が難しい場合があるというフィードバックを非常に受け入れやすいことがよくあります。そうでない場合は、落とし穴、コスト、納期を強調することが役立つと思います。この種のフィードバックは、保守可能でスケーラブルなソリューションを構築するために必要です。
作者について
 Michael J Swartは、データベース開発とソフトウェアアーキテクチャに焦点を当てた情熱的なデータベースの専門家およびブロガーです。彼は、コミュニティプロジェクトに貢献し、データに関連するあらゆることについて話すことを楽しんでいます。 Michaelは、michaeljswart.comで「DatabaseWhisperer」としてブログを書いています。
Michael J Swartは、データベース開発とソフトウェアアーキテクチャに焦点を当てた情熱的なデータベースの専門家およびブロガーです。彼は、コミュニティプロジェクトに貢献し、データに関連するあらゆることについて話すことを楽しんでいます。 Michaelは、michaeljswart.comで「DatabaseWhisperer」としてブログを書いています。