先月、私は供給と需要を一致させるというペーテル・ラーションのパズルを取り上げました。 Peterの単純なカーソルベースのソリューションを示し、線形スケーリングがあることを説明しました。私があなたに残した課題は、その課題に対するセットベースの解決策を考え出すことです。そして、男の子、人々に挑戦に立ち向かわせてください! Luca、Kamil Kosno、Daniel Brown、Brian Walker、Joe Obbish、Rainer Hoffmann、Paul White、Charlie、そしてもちろん、PeterLarssonにソリューションを送ってくれてありがとう。いくつかのアイデアは素晴らしく、驚くべきものでした。
今月は、提出されたソリューションの調査を開始します。大まかに言って、パフォーマンスの悪いものからパフォーマンスの高いものへと変化します。なぜパフォーマンスの悪いものに悩まされるのですか?あなたはまだ彼らから多くを学ぶことができるからです。たとえば、アンチパターンを識別することによって。実際、私やピーターを含む多くの人々にとってこの課題を解決する最初の試みは、区間交差の概念に基づいています。間隔の交差を識別するための従来の述語ベースの手法は、それをサポートする適切な索引付けスキームがないため、パフォーマンスが低下することがあります。この記事は、このパフォーマンスの低いアプローチに焦点を当てています。パフォーマンスは劣りますが、ソリューションに取り組むことは興味深い演習です。セットベースの治療に役立つ方法で問題をモデル化するスキルを練習する必要があります。パフォーマンスが悪い理由を特定することも興味深いので、将来的にアンチパターンを回避しやすくなります。このソリューションは出発点にすぎないことに注意してください。
DDLとサンプルデータの小さなセット
このタスクには、「オークション」と呼ばれるテーブルのクエリが含まれます。次のコードを使用してテーブルを作成し、サンプルデータの小さなセットを入力します。
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
);
SET NOCOUNT ON;
DELETE FROM dbo.Auctions;
SET IDENTITY_INSERT dbo.Auctions ON;
INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES
(1, 'D', 5.0),
(2, 'D', 3.0),
(3, 'D', 8.0),
(5, 'D', 2.0),
(6, 'D', 8.0),
(7, 'D', 4.0),
(8, 'D', 2.0),
(1000, 'S', 8.0),
(2000, 'S', 6.0),
(3000, 'S', 2.0),
(4000, 'S', 2.0),
(5000, 'S', 4.0),
(6000, 'S', 3.0),
(7000, 'S', 2.0);
SET IDENTITY_INSERT dbo.Auctions OFF; あなたの仕事は、IDの順序に基づいて供給と需要のエントリを一致させるペアを作成し、それらを一時テーブルに書き込むことでした。少数のサンプルデータの望ましい結果は次のとおりです。
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
先月、Auctionsテーブルに大量のサンプルデータを入力し、需要と供給のエントリ数と数量の範囲を制御するために使用できるコードも提供しました。先月の記事のコードを使用して、ソリューションのパフォーマンスを確認してください。
データを間隔としてモデル化する
セットベースのソリューションをサポートするのに役立つ興味深いアイデアの1つは、データを間隔としてモデル化することです。つまり、各需要と供給のエントリを、同じ種類(需要または供給)の現在の合計数量から現在を除いたものまで、そしてもちろん現在のIDに基づいて現在を含む現在の合計で終わる間隔として表します。注文。たとえば、サンプルデータの小さなセットを見ると、最初の需要エントリ(ID 1)は数量5.0で、2番目(ID 2)は数量3.0です。最初の需要エントリは、間隔開始:0.0、終了:5.0で表し、2番目の需要エントリは間隔開始:5.0、終了:8.0などで表すことができます。
同様に、最初の供給エントリ(ID 1000)は数量8.0の場合で、2番目(ID 2000)は数量6.0の場合です。最初の供給エントリは、間隔開始:0.0、終了:8.0で表し、2番目の供給エントリは間隔開始:8.0、終了:14.0などで表すことができます。
作成する必要のある需給ペアは、2種類の交差する間隔の重なり合うセグメントです。
これは、図1に示すように、データの間隔ベースのモデリングと目的の結果を視覚的に表現することでおそらく最もよく理解できます。
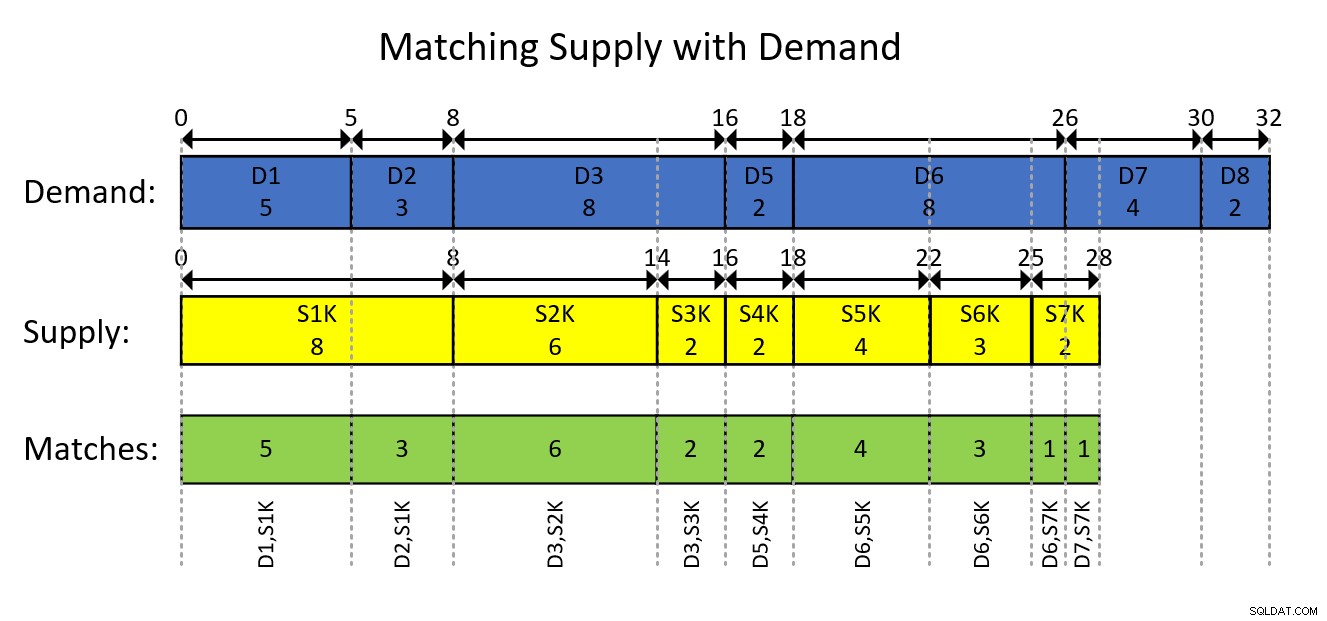 図1:データを間隔としてモデル化する
図1:データを間隔としてモデル化する
図1の視覚的な描写はかなり自明ですが、要するに…
青い長方形は需要エントリを間隔として表し、排他的な現在の合計数量を間隔の開始として示し、包括的な現在の合計を間隔の終了として示します。黄色の長方形は、供給エントリに対しても同じことを行います。次に、緑色の長方形で示されている2種類の交差する間隔の重なり合うセグメントが、生成する必要のある需要と供給の組み合わせであることに注目してください。たとえば、最初の結果のペアリングは、需要ID 1、供給ID 1000、数量5です。2番目の結果のペアリングは、需要ID 2、供給ID 1000、数量3などです。
CTEを使用したインターバル交差点
インターバルモデリングのアイデアに基づいたソリューションを使用してT-SQLコードを記述し始める前に、ここでどのインデックスが役立つ可能性が高いかを直感的に理解している必要があります。ウィンドウ関数を使用して現在の合計を計算する可能性が高いため、Code、ID列に基づいており、Quantity列を含むキーを使用して、カバーするインデックスを利用できます。このようなインデックスを作成するためのコードは次のとおりです。
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
これは、先月取り上げたカーソルベースのソリューションに推奨したものと同じインデックスです。
また、ここではバッチ処理の恩恵を受ける可能性があります。次のダミーの列ストアインデックスを作成することで、たとえばSQL Server 2019 Enterprise以降を使用して、行ストアでバッチモードを必要とせずに検討を有効にできます。
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
これで、ソリューションのT-SQLコードの作業を開始できます。
次のコードは、需要エントリを表す間隔を作成します。
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT *
FROM D; CTE D0を定義するクエリは、オークションテーブルからの需要エントリをフィルタリングし、需要間隔の終了区切り文字として現在の合計数量を計算します。次に、Dと呼ばれる2番目のCTEを定義するクエリがD0をクエリし、終了区切り文字から現在の数量を引くことによって、需要間隔の開始区切り文字を計算します。
このコードは次の出力を生成します:
ID Quantity StartDemand EndDemand ---- --------- ------------ ---------- 1 5.000000 0.000000 5.000000 2 3.000000 5.000000 8.000000 3 8.000000 8.000000 16.000000 5 2.000000 16.000000 18.000000 6 8.000000 18.000000 26.000000 7 4.000000 26.000000 30.000000 8 2.000000 30.000000 32.000000
次のコードを使用して、供給エントリに同じロジックを適用することにより、供給間隔が非常によく似て生成されます。
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT *
FROM S; このコードは次の出力を生成します:
ID Quantity StartSupply EndSupply ----- --------- ------------ ---------- 1000 8.000000 0.000000 8.000000 2000 6.000000 8.000000 14.000000 3000 2.000000 14.000000 16.000000 4000 2.000000 16.000000 18.000000 5000 4.000000 18.000000 22.000000 6000 3.000000 22.000000 25.000000 7000 2.000000 25.000000 27.000000
残っているのは、CTE DとSから交差する需要と供給の間隔を特定し、それらの交差する間隔の重複するセグメントを計算することです。結果のペアリングは一時テーブルに書き込む必要があることに注意してください。これは、次のコードを使用して実行できます。
-- Drop temp table if exists
DROP TABLE IF EXISTS #MyPairings;
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
),
S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
-- Outer query identifies trades as the overlapping segments of the intersecting intervals
-- In the intersecting demand and supply intervals the trade quantity is then
-- LEAST(EndDemand, EndSupply) - GREATEST(StartDemsnad, StartSupply)
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM D INNER JOIN S
ON D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply; すでに前に見た需要と供給の間隔を作成するコードに加えて、ここでの主な追加は、DとSの間の交差する間隔を識別し、重複するセグメントを計算する外部クエリです。交差する間隔を識別するために、外部クエリは次の結合述語を使用してDとSを結合します。
D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply
これは、区間の共通部分を識別するための古典的な述語です。後で説明するように、これはソリューションのパフォーマンス低下の主な原因でもあります。
外部クエリは、SELECTリストの取引数量も次のように計算します。
LEAST(EndDemand, EndSupply) - GREATEST(StartDemand, StartSupply)
Azure SQLを使用している場合は、この式を使用できます。 SQL Server 2019以前を使用している場合は、論理的に同等の次の代替手段を使用できます。
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
要件は結果を一時テーブルに書き込むことであったため、外部クエリはSELECTINTOステートメントを使用してこれを実現します。
データを間隔としてモデル化するというアイデアは、明らかに興味深くエレガントです。しかし、パフォーマンスはどうですか?残念ながら、この特定のソリューションには、区間の交差を識別する方法に関連する大きな問題があります。図2に示すこのソリューションの計画を検討します。
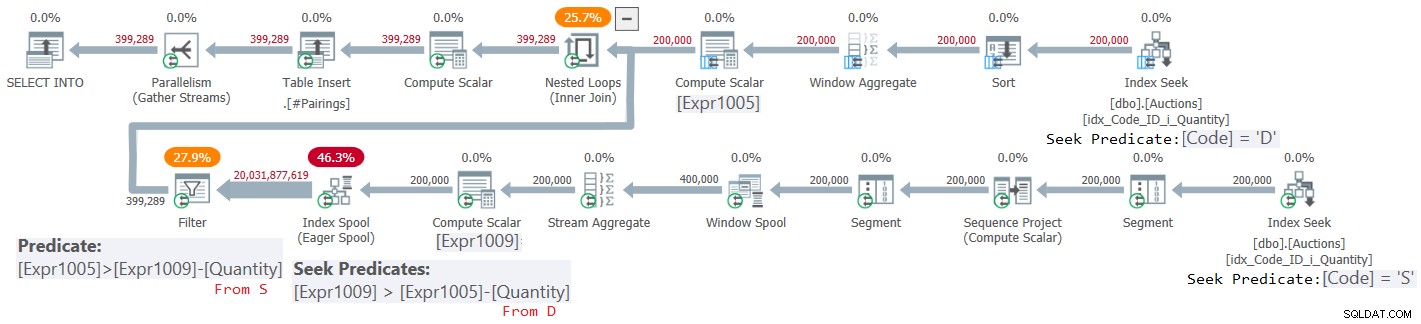 図2:CTEソリューションを使用した交差点のクエリプラン
図2:CTEソリューションを使用した交差点のクエリプラン
計画の安価な部分から始めましょう。
ネストされたループ結合の外部入力は、需要間隔を計算します。インデックスシーク演算子を使用して需要エントリを取得し、バッチモードのウィンドウ集計演算子を使用して需要間隔の終了区切り文字(このプランではExpr1005と呼ばれます)を計算します。その場合、需要間隔の開始区切り文字はExpr1005 –数量(Dから)です。
ちなみに、ここでは、バッチモードのWindow Aggregate演算子の前に明示的なSort演算子を使用していることに気付くかもしれません。これは、Index Seekから取得したデマンドエントリが、window関数で必要とされるように、すでにIDで並べ替えられているためです。これは、現在、SQL Serverが、並列バッチモードのWindowAggregate演算子の前に並列順序を保持するインデックス操作の効率的な組み合わせをサポートしていないという事実と関係があります。実験目的でシリアルプランを強制すると、並べ替え演算子が表示されなくなります。 SQL Serverは全体的に決定しました。明示的な並べ替えが追加されたにもかかわらず、ここでの並列処理の使用が優先されました。しかし、繰り返しになりますが、計画のこの部分は、物事の壮大な計画における作業のごく一部を表しています。
同様に、ネストされたループ結合の内部入力は、供給間隔を計算することから始まります。不思議なことに、SQLServerはこの部分を処理するために行モード演算子を使用することを選択しました。一方では、現在の合計を計算するために使用される行モードの演算子は、バッチモードのWindowAggregateの代替よりも多くのオーバーヘッドを伴います。一方、SQL Serverには、ウィンドウ関数の計算に続く順序保持インデックス操作の効率的な並列実装があり、この部分の明示的な並べ替えを回避します。オプティマイザーが需要間隔に1つの戦略を選択し、供給間隔に別の戦略を選択したのは不思議です。いずれにせよ、Index Seekオペレーターは供給エントリーを取得し、Compute Scalarオペレーターまでの後続のオペレーターのシーケンスは、供給間隔の終了区切り文字(このプランではExpr1009と呼ばれます)を計算します。その場合、供給間隔の開始区切り文字はExpr1009 –数量(Sから)です。
私がこれらの2つの部分を説明するために使用したテキストの量にもかかわらず、計画の作業の本当に高価な部分は次に来るものです。
次の部分は、次の述語を使用して需要間隔と供給間隔を結合する必要があります。
D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply
サポートインデックスがない場合、DI需要間隔とSI供給間隔を想定すると、これにはDI*SI行の処理が含まれます。図2の計画は、オークションテーブルに400,000行(200,000の需要エントリと200,000の供給エントリ)を入力した後に作成されました。したがって、サポートインデックスがない場合、プランは200,000 * 200,000=40,000,000,000行を処理する必要があります。このコストを軽減するために、オプティマイザーは、供給間隔の終了区切り文字(Expr1009)をキーとして使用して一時的な索引(索引スプール演算子を参照)を作成することを選択しました。それはそれができることのほとんど最高です。ただし、これは問題の一部のみを処理します。 2つの範囲述部を使用すると、インデックスシーク述部でサポートできるのは1つだけです。もう1つは、残差述語を使用して処理する必要があります。実際、プランでは、一時インデックスのシークがシーク述語Expr1009> Expr1005 – D.Quantityを使用し、その後に残りの述語Expr1005> Expr1009 –S.Quantityを処理するフィルター演算子が続くことがわかります。
平均すると、seek述語は、需要行ごとに供給行の半分をインデックスから分離すると仮定すると、Index Spoolオペレーターから発行され、Filterオペレーターによって処理される行の総数はDI * SI / 2になります。この場合、200,000です。需要行と200,000供給行の場合、これは20,000,000,000に相当します。実際、インデックススプール演算子からフィルター演算子に向かう行は、これに近い行数を報告します。
この計画には、先月のカーソルベースのソリューションの線形スケーリングと比較して、2次スケーリングがあります。図3に、2つのソリューションを比較したパフォーマンステストの結果を示します。セットベースのソリューションの形の良い放物線をはっきりと見ることができます。
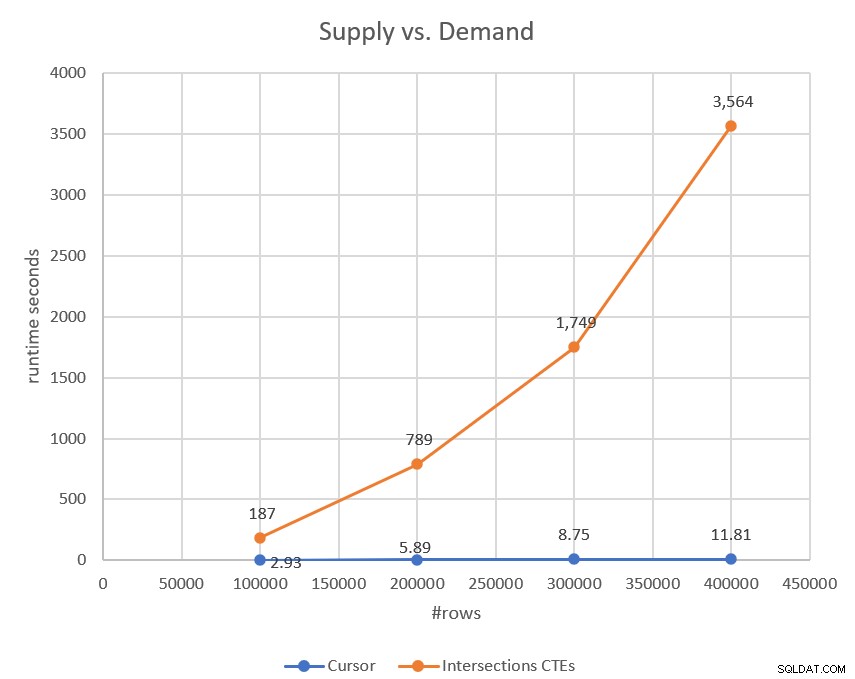 図3:CTEソリューションとカーソルベースのソリューションを使用した交差点のパフォーマンス
図3:CTEソリューションとカーソルベースのソリューションを使用した交差点のパフォーマンス
一時テーブルを使用したインターバル交差点
需要と供給の間隔にCTEを使用することを一時的なテーブルに置き換え、インデックススプールを回避して、終了区切り文字をキーとして供給間隔を保持する独自のインデックスを一時テーブルに作成することで、状況をいくらか改善できます。完全なソリューションのコードは次のとおりです。
-- Drop temp tables if exist
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID, Quantity,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID, Quantity,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
CREATE UNIQUE CLUSTERED INDEX idx_cl_ES_ID ON #Supply(EndSupply, ID);
-- Outer query identifies trades as the overlapping segments of the intersecting intervals
-- In the intersecting demand and supply intervals the trade quantity is then
-- LEAST(EndDemand, EndSupply) - GREATEST(StartDemsnad, StartSupply)
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S WITH (FORCESEEK)
ON D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply; このソリューションの計画を図4に示します。
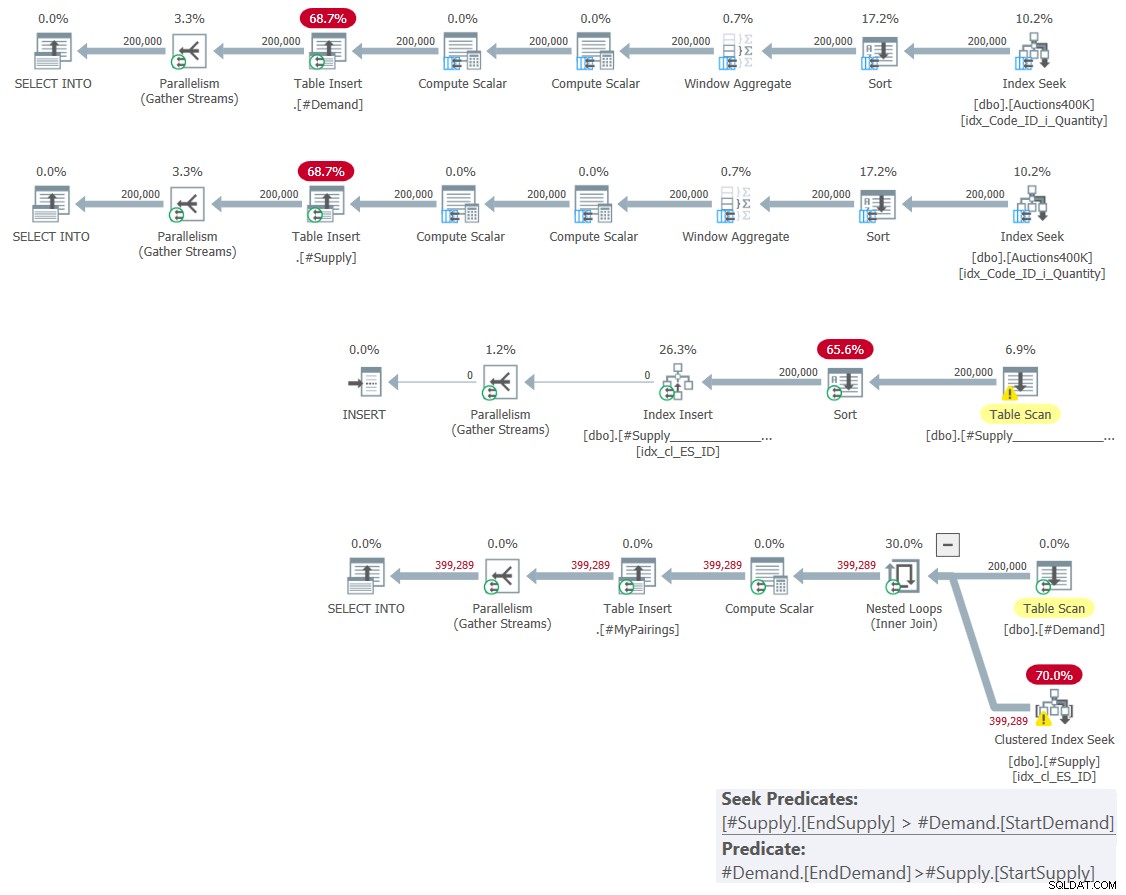 図4:一時テーブルソリューションを使用した交差点のクエリプラン
図4:一時テーブルソリューションを使用した交差点のクエリプラン
最初の2つのプランは、バッチモードのインデックスシーク+ソート+ウィンドウ集計演算子の組み合わせを使用して、需要と供給の間隔を計算し、それらを一時テーブルに書き込みます。 3番目のプランは、EndSupply区切り文字を先頭キーとして#Supplyテーブルでのインデックス作成を処理します。
4番目の計画は、作業の大部分を表しており、#Demandからの各間隔、#Supplyからの交差する間隔に一致するネストされたループの結合演算子が含まれています。ここでも、インデックスシーク演算子がシーク述語として述語#Supply.EndSupply>#Demand.StartDemandに依存し、残りの述語として#Demand.EndDemand>#Supply.StartSupplyに依存していることに注意してください。したがって、複雑さ/スケーリングに関しては、前のソリューションと同じ2次の複雑さが得られます。以前のプランで使用されていたインデックススプールの代わりに独自のインデックスを使用しているため、行ごとに支払う金額が少なくなります。このソリューションのパフォーマンスは、図5の前の2つと比較して確認できます。
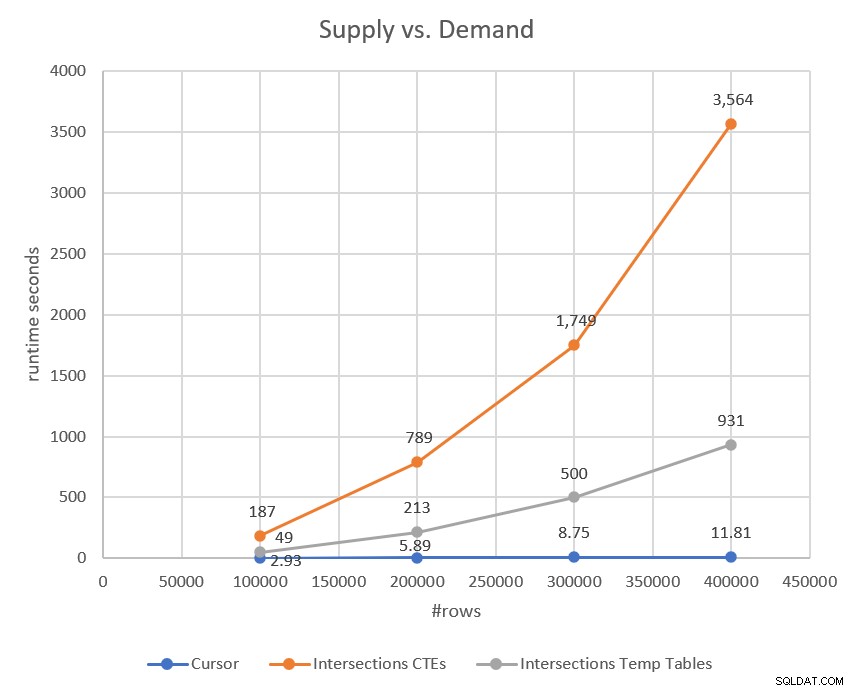 図5:他の2つのソリューションと比較した一時テーブルを使用した交差点のパフォーマンス
図5:他の2つのソリューションと比較した一時テーブルを使用した交差点のパフォーマンス
ご覧のとおり、一時テーブルを使用したソリューションは、CTEを使用したソリューションよりもパフォーマンスが優れていますが、それでも2次スケーリングがあり、カーソルに比べてパフォーマンスが非常に悪くなっています。
次は何ですか?
この記事では、セットベースのソリューションを使用して、従来のマッチング供給と需要タスクを処理する最初の試みについて説明しました。アイデアは、データを間隔としてモデル化し、交差する需要と供給の間隔を識別して供給と需要のエントリを一致させ、重複するセグメントのサイズに基づいて取引量を計算することでした。確かに興味深いアイデアです。これに関する主な問題は、2つの範囲述語を使用して区間交差を識別するという古典的な問題でもあります。最適なインデックスが設定されている場合でも、インデックスシークでサポートできる範囲述語は1つだけです。他の範囲述部は、残差述部を使用して処理する必要があります。これにより、2次の複雑さを持つ計画が作成されます。
では、この障害を克服するために何ができるでしょうか。いくつかの異なるアイデアがあります。素晴らしいアイデアの1つは、Joe Obbishのものです。これについては、彼のブログ投稿で詳しく読むことができます。他のアイデアについては、シリーズの今後の記事で取り上げます。
[ジャンプ先:元のチャレンジ|ソリューション:パート1 |パート2|パート3]