この記事では、実際の用のスクレーパーを作成します。 クライアントがPythonプログラムでStackOverflowからデータを取得して、新しい質問(質問のタイトルとURL)を取得することを希望するフリーランスのギグ。スクレイピングされたデータは、MongoDBに保存する必要があります。 StackOverflowにはAPIがあり、正確なにアクセスするために使用できることに注意してください。 同じデータ。しかし、クライアントはスクレーパーを望んでいたので、スクレーパーが彼が手に入れたものです。
無料ボーナス: ここをクリックして、PythonからMongoDBにアクセスする方法を示す完全なソースコードを含むPython+MongoDBプロジェクトスケルトンをダウンロードしてください。
更新:
- 2014年1月3日-スパイダーをリファクタリングしました。ありがとう、@kissgyorgy。
- 2015年2月18日-パート2を追加。
- 2015年9月6日-ScrapyとPyMongoの最新バージョンに更新-乾杯!
いつものように、サイトの利用規約/サービスを確認し、 robots.txtを尊重してください。 スクレイピングジョブを開始する前にファイルします。短期間に多数のリクエストでサイトを氾濫させないようにして、倫理的なスクレイピング慣行を遵守するようにしてください。 スクレイプしたサイトを自分のものであるかのように扱います 。
インストール
MongoDBにデータを保存するには、Scrapyライブラリ(v1.0.3)とPyMongo(v3.0.3)が必要です。 MongoDBもインストールする必要があります(カバーされていません)。
Scrapy
OSXまたはLinuxのフレーバーを実行している場合は、pipを使用してScrapyをインストールします(virtualenvをアクティブにします):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Windowsマシンを使用している場合は、いくつかの依存関係を手動でインストールする必要があります。詳細な手順と私が作成したこのYoutubeビデオについては、公式ドキュメントを参照してください。
Scrapyがセットアップされたら、Pythonシェルで次のコマンドを実行してインストールを確認します。
>>>>>> import scrapy
>>>
エラーが発生しない場合は、問題ありません。
PyMongo
次に、pipを使用してPyMongoをインストールします:
$ pip install pymongo
$ pip freeze > requirements.txt
これで、クローラーの作成を開始できます。
Scrapy Project
新しいScrapyプロジェクトを始めましょう:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
これにより、すばやく開始するための基本的な定型文を含む多数のファイルとフォルダーが作成されます。
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
データを指定
items.py ファイルは、スクレイピングする予定のデータのストレージ「コンテナ」を定義するために使用されます。
StackItem() クラスはItemから継承します (docs)、基本的にScrapyがすでに構築した定義済みのオブジェクトがいくつかあります:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
実際に収集したいアイテムをいくつか追加しましょう。質問ごとに、クライアントはタイトルとURLを必要とします。したがって、 items.pyを更新します そのように:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
スパイダーを作成する
stack_spider.pyというファイルを作成します 「spiders」ディレクトリにあります。ここで魔法が起こります。たとえば、Scrapyに正確なを見つける方法を説明します。 探しているデータ。ご想像のとおり、これは固有です。 スクレイプしたい個々のWebページに。
ScrapyのSpiderから継承するクラスを定義することから始めます 次に、必要に応じて属性を追加します:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
最初のいくつかの変数は自明です(ドキュメント):
名前 スパイダーの名前を定義します。-
allowed_domainsスパイダーがクロールできるドメインのベースURLが含まれています。 -
start_urlsスパイダーがクロールを開始するためのURLのリストです。以降のすべてのURLは、スパイダーがstart_urlsのURLからダウンロードしたデータから始まります。 。
XPathセレクター
次に、ScrapyはXPathセレクターを使用してWebサイトからデータを抽出します。つまり、特定のXPathに基づいてHTMLデータの特定の部分を選択できます。 Scrapyのドキュメントに記載されているように、「XPathはXMLドキュメント内のノードを選択するための言語であり、HTMLでも使用できます。」
Chromeのデベロッパーツールを使用して、特定のXpathを簡単に見つけることができます。特定のHTML要素を調べ、XPathをコピーしてから、(必要に応じて)微調整するだけです。
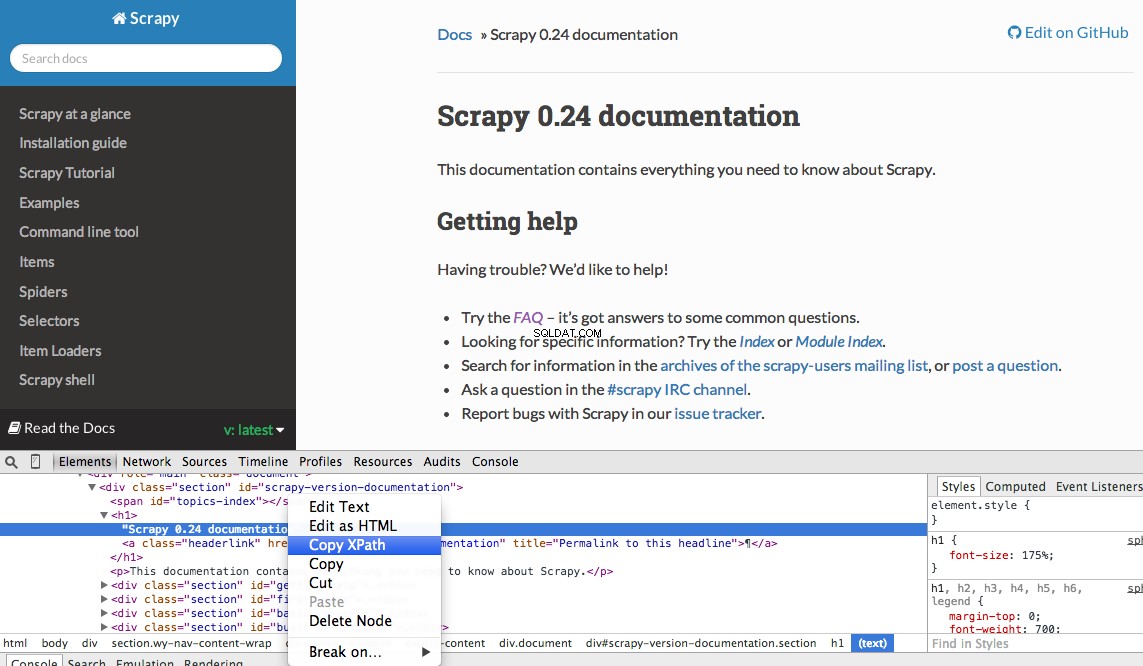
開発者ツールでは、 $ x を使用して、JavaScriptコンソールでXPathセレクターをテストすることもできます。 -つまり、 $ x( "// img") :
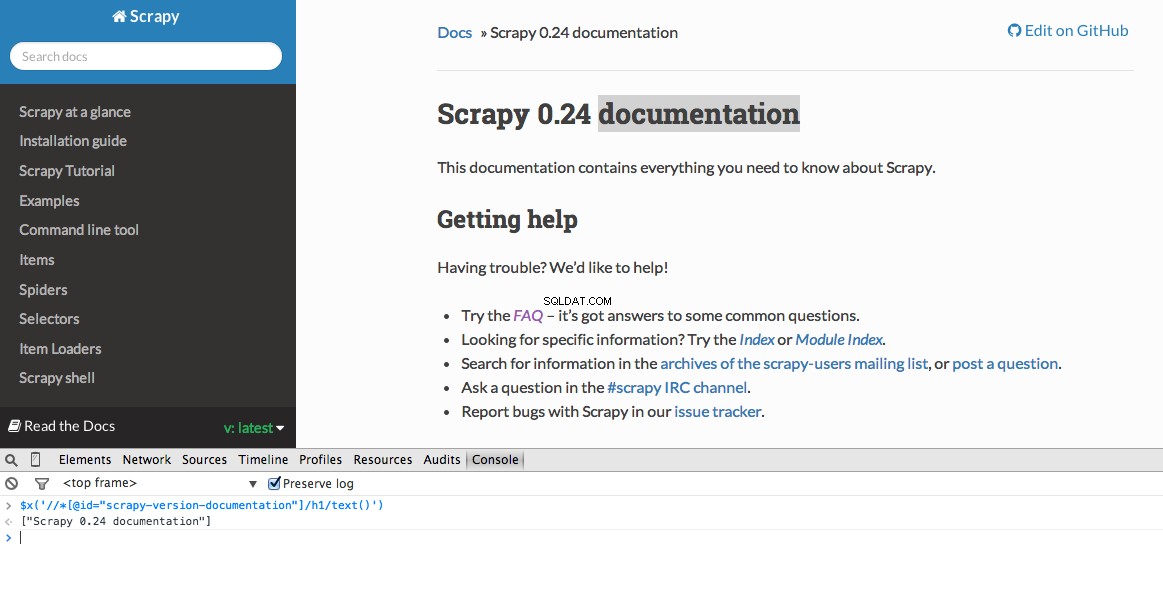
繰り返しになりますが、基本的に、定義されたXPathに基づいて情報の検索を開始する場所をScrapyに指示します。 ChromeのStackOverflowサイトに移動して、XPathセレクターを見つけましょう。
最初の質問を右クリックして、[要素の検査]を選択します:
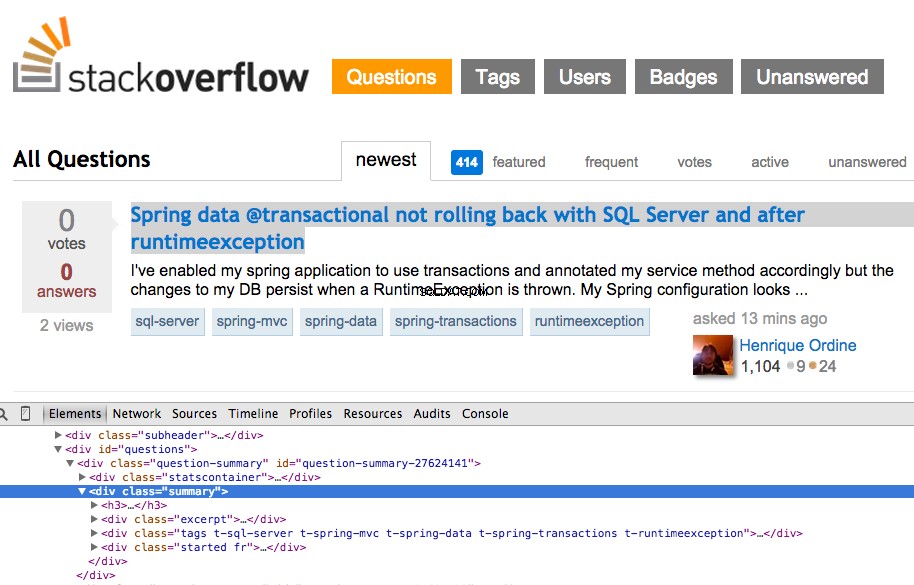
次に、
お分かりのように、1つを選択するだけです。 質問。したがって、XPathを変更してすべてを取得する必要があります。 質問。何か案は?簡単です:
ChromeDeveloperToolsからの実際のXPath出力を使用していないことに注意してください。ほとんどの場合、出力は脇に置いておくと便利です。これは通常、機能するXPathを見つけるための正しい方向を示します。
それでは、 stack_spider.pyを更新しましょう。 スクリプト:
Scrapyスタックトレースとともに、50の質問タイトルとURLが出力されているはずです。次の小さなコマンドを使用して、出力をJSONファイルにレンダリングできます。
探しているデータに基づいてスパイダーを実装しました。次に、スクレイピングされたデータをMongoDB内に保存する必要があります。
アイテムが返されるたびに、データを検証してから、Mongoコレクションに追加する必要があります。
最初のステップは、クロールされたすべてのデータを保存するために使用する予定のデータベースを作成することです。 settings.pyを開きます パイプラインを指定し、データベース設定を追加します:
HTMLをクロールして解析するようにスパイダーを設定し、データベース設定を設定しました。次に、 pipelines.pyのパイプラインを介して2つを接続する必要があります 。
データベースに接続
まず、実際にデータベースに接続する方法を定義しましょう。
ここでは、クラス
データを処理する
次に、解析されたデータを処理するメソッドを定義する必要があります。
データベースへの接続を確立し、データを解凍してから、データベースに保存します。これで、もう一度テストできます!
ここでも、「stack」ディレクトリ内で次のコマンドを実行します。
注 :Mongoデーモンがあることを確認してください-
やったー!クロールされたデータをデータベースに正常に保存しました:
これは、Scrapyを使用してWebページをクロールおよびスクレイプする非常に簡単な例です。実際のフリーランスプロジェクトでは、スクリプトがページネーションリンクをたどり、
助けが必要?ほぼ完成しているこのスクリプトから始めます。 次に、完全なソリューションについてパート2をご覧ください!
無料ボーナス: ここをクリックして、PythonからMongoDBにアクセスする方法を示す完全なソースコードを含むPython+MongoDBプロジェクトスケルトンをダウンロードしてください。
ソースコード全体をGithubリポジトリからダウンロードできます。以下に質問をコメントしてください。読んでくれてありがとう! // * [@ id ="question-summary-27624141"] / div [2] 、JavaScriptコンソールでテストします: 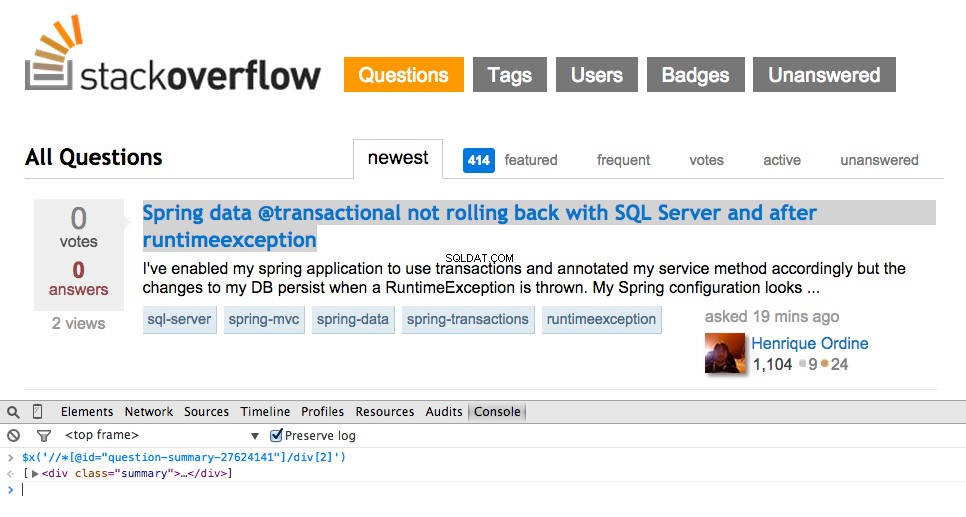
// div [@ class ="summary"] / h3 。これは何を意味するのでしょうか?基本的に、このXPathは次のように述べています。すべての を取得する summaryのクラスがあります 。このXPathをJavaScriptコンソールでテストします。
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
データを抽出する
に含まれる必要なデータを解析してスクレイピングする必要があります。 。繰り返しますが、 stack_spider.pyを更新します そのように:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
$ scrapy crawl stack -o items.json -t json
データをMongoDBに保存する
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
パイプライン管理
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
MongoDBPipeline()を作成します。 、Mongo設定を定義してからデータベースに接続することで、クラスを初期化するコンストラクター関数があります。import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
テスト
$ scrapy crawl stack
mongod -別のターミナルウィンドウで実行しています。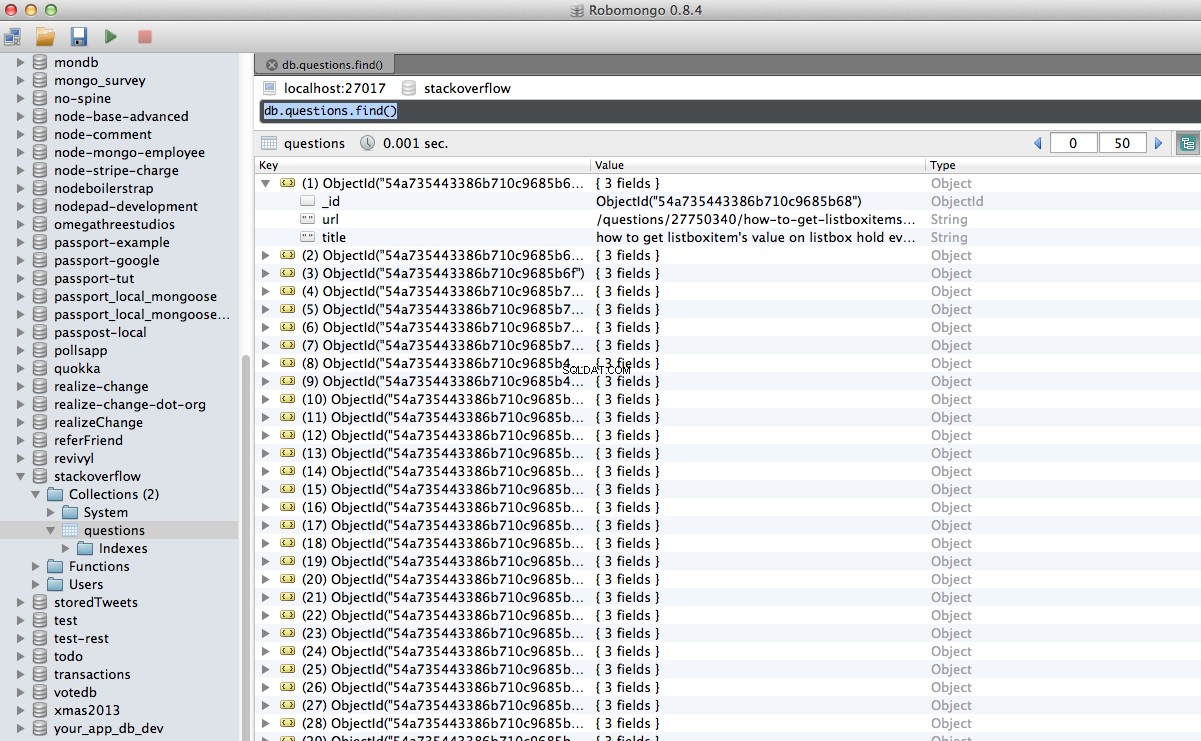
結論
CrawlSpiderを使用して各ページをスクレイプする必要がありました。 (docs)、これは実装が非常に簡単です。これを自分で実装してみてください。コードを簡単に確認できるように、Githubリポジトリへのリンクを下にコメントとして残してください。